【Datawhale动手学数据分析笔记】第三章 数据重构

【摘要】 数据重构我们学习了数据的清洗,这一部分十分重要,只有数据变得相对干净,我们之后对数据的分析才可以更有力。而这一节,我们要做的是数据重构,数据重构依旧属于数据理解(准备)的范围。 载入数据# 载入data文件中的:train-left-up.csvtext = pd.read_csv('data/train-left-up.csv')text.head()结果: 数据的合并 将data文件夹...
数据重构
我们学习了数据的清洗,这一部分十分重要,只有数据变得相对干净,我们之后对数据的分析才可以更有力。而这一节,我们要做的是数据重构,数据重构依旧属于数据理解(准备)的范围。
载入数据
# 载入data文件中的:train-left-up.csv
text = pd.read_csv('data/train-left-up.csv')
text.head()
结果:

数据的合并
将data文件夹里面的所有数据都载入,与之前的原始数据相比,观察他们的之间的关系
text_left_up = pd.read_csv("data/train-left-up.csv")
text_left_down = pd.read_csv("data/train-left-down.csv")
text_right_up = pd.read_csv("data/train-right-up.csv")
text_right_down = pd.read_csv("data/train-right-down.csv")
查看每个表的信息
text_left_up.head()
结果:
text_left_down.head()
结果:
text_right_up.head()
结果:
text_right_down.head()
结果:
使用concat方法:将数据train-left-up.csv和train-right-up.csv横向合并为一张表,并保存这张表为result_up
list_up = [text_left_up,text_right_up]
result_up = pd.concat(list_up,axis=1)
result_up.head()
运行结果:

使用concat方法:将train-left-down和train-right-down横向合并为一张表,并保存这张表为result_down。然后将上边的result_up和result_down纵向合并为result。
list_down=[text_left_down,text_right_down]
result_down = pd.concat(list_down,axis=1)
result = pd.concat([result_up,result_down])
result.head()
运行结果:

使用DataFrame自带的方法join方法和append:完成任务二和任务三的任务
resul_up = text_left_up.join(text_right_up)
result_down = text_left_down.join(text_right_down)
result = result_up.append(result_down)
result.head()
运行结果:

使用Panads的merge方法和DataFrame的append方法:完成任务二和任务三的任务
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result = resul_up.append(result_down)
result.head()
运行结果:

完成的数据保存为result.csv
result.to_csv('result.csv')
换一种角度看数据
任务一:将我们的数据变为Series类型的数据
# 将完整的数据加载出来
text = pd.read_csv('result.csv')
text.head()
# 代码写在这里
unit_result=text.stack().head(20)
unit_result.head()
运行结果:
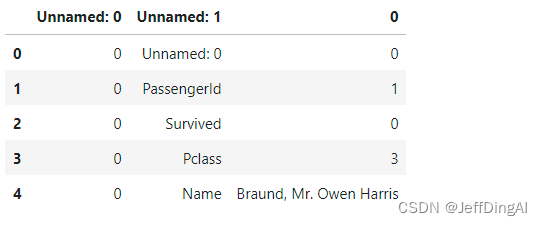
0 Unnamed: 0 0
PassengerId 1
Survived 0
Pclass 3
Name Braund, Mr. Owen Harris
dtype: object
#将代码保存为unit_result,csv
unit_result.to_csv('unit_result.csv')
test = pd.read_csv('unit_result.csv')
test.head()
载入Result数据
# 载入data文件中的:result.csv
text = pd.read_csv('result.csv')
text.head()
结果:

数据聚合与运算
数据运用
GroupBy机制
Hadley Wickham创造了一个用于表示分组运算的术语"split-apply-combine"(拆分-应用-合并)。第一个阶段,pandas对象(无论是Series、DataFrame还是其他的)中的数据会根据你所提供的一 个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。 例如,DataFrame可以在其行(axis=0)或列(axis=1)上进行分组。然 后,将一个函数应用(apply)到各个分组并产生一个新值。最后,所有这些 函数的执行结果会被合并(combine)到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。下图大致说明了一个简单的分组聚合过程。
分组键可以有多种形式,且类型不必相同:
列表或数组,其长度与待分组的轴一样。
表示DataFrame某个列名的值。
字典或Series,给出待分组轴上的值与分组名之间的对应关系
函数,用于处理轴索引或索引中的各个标签。
计算泰坦尼克号男性与女性的平均票价
df = text['Fare'].groupby(text['Sex'])
means = df.mean()
means
运行结果:
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64
统计泰坦尼克号中男女的存活人数
survived_sex = text['Survived'].groupby(text['Sex']).sum()
survived_sex.head()
运行结果:
Sex
female 233
male 109
Name: Survived, dtype: int64
计算客舱不同等级的存活人数
survived_pclass = text['Survived'].groupby(text['Pclass'])
survived_pclass.sum()
运行结果:
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
表中的存活那一栏,可以发现如果还活着记为1,死亡记为0
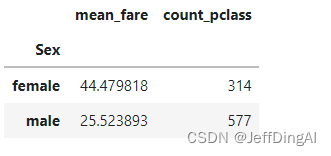
从任务二到任务三中,这些运算可以通过agg()函数来同时计算。并且可以使用rename函数修改列名
text.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns=
{'Fare': 'mean_fare', 'Pclass': 'count_pclass'})
运行结果:
统计在不同等级的票中的不同年龄的船票花费的平均值
text.groupby(['Pclass','Age'])['Fare'].mean().head()
运行结果:
Pclass Age
1 0.92 151.5500
2.00 151.5500
4.00 81.8583
11.00 120.0000
14.00 120.0000
Name: Fare, dtype: float64
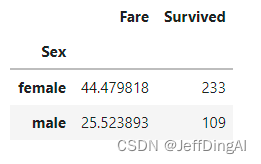
任务二和任务三的数据合并
result = pd.merge(means,survived_sex,on='Sex')
result
运行结果:
得出不同年龄的总的存活人数,然后找出存活人数最多的年龄段,最后计算存活人数最高的存活率(存活人数/总人数)
#不同年龄的存活人数
survived_age = text['Survived'].groupby(text['Age']).sum()
survived_age.head()
运行结果:
Age
0.42 1
0.67 1
0.75 2
0.83 2
0.92 1
Name: Survived, dtype: int64
#找出最大值的年龄段
survived_age[survived_age.values==survived_age.max()]
运行结果:
Age
24.0 15
Name: Survived, dtype: int64
_sum = text['Survived'].sum()
print(_sum)
运行结果:342
#首先计算总人数
_sum = text['Survived'].sum()
print("sum of person:"+str(_sum))
precetn =survived_age.max()/_sum
print("最大存活率:"+str(precetn))
运行结果:
sum of person:342
最大存活率:0.043859649122807015

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)