【Datawhale IntelVINO学习笔记】OpenVINO核心组件资源和开发流程

安装VINO
下载地址:https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/download.html
安装VINO:
cd l_openvino_toolkit_p_2021.4.752/
sudo ./install_openvino_dependencies.sh
sudo ./install.sh
安装python依赖包
pip install openvino-dev[onnx,pytorch,mxnet,caffe,tensorflow2]==2021.4.2
编译 OpenVINO的 Python API
sudo apt-get install build-essential
sudo apt-get install cmake
export OV=/opt/intel/openvino_2021/
source $OV/inference_engine/demos/build_demos.sh -DENABLE_PYTHON=ON
环境准备
设定OpenVINO的路径:
export OV=/opt/intel/openvino_2021/
设定当前实验的路径:
export WD=~/OV-300/01/3D_Human_pose/
运行初始化OpenVINO的脚本
source $OV/bin/setupvars.sh
当你看到:[setupvars.sh] OpenVINO environment initialized 表示OpenVINO环境已经成功初始化。
运行OpenVINO依赖脚本的安装
进入脚本目录:
cd $OV/deployment_tools/model_optimizer/install_prerequisites/
安装OpenVINO需要的依赖:
sudo ./install_prerequisites.sh
安装OpenVINO模型下载器的依赖文件
进入到模型下载器的文件夹:
cd $OV/deployment_tools/tools/model_downloader/
安装模型下载器的依赖:
python3 -mpip install --user -r ./requirements.in
安装下载转换pytorch模型的依赖:
sudo python3 -mpip install --user -r ./requirements-pytorch.in
安装下载转换caffe2模型的依赖:
sudo python3 -mpip install --user -r ./requirements-caffe2.in
开始实验
通过模型下载器下载人体姿势识别模型
正式进入实验目录:
cd $WD
查看human_pose_estimation_3d_demo需要的模型列表:
cat /opt/intel/openvino_2021//deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst
通过模型下载器下载模型:
python3 $OV/deployment_tools/tools/model_downloader/downloader.py --list $OV/deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst -o $WD
使用模型转换器把模型转换成IR格式
python3 $OV/deployment_tools/tools/model_downloader/converter.py --list $OV/deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst
播放待识别的实验视频
ffplay -autoexit 3d_dancing.mp4
运行人体姿势识别Demo
python3 $OV/inference_engine/demos/human_pose_estimation_3d_demo/python/human_pose_estimation_3d_demo.py -m $WD/public/human-pose-estimation-3d-0001/FP16/human-pose-estimation-3d-0001.xml -i 3d_dancing.mp4
运行结果:
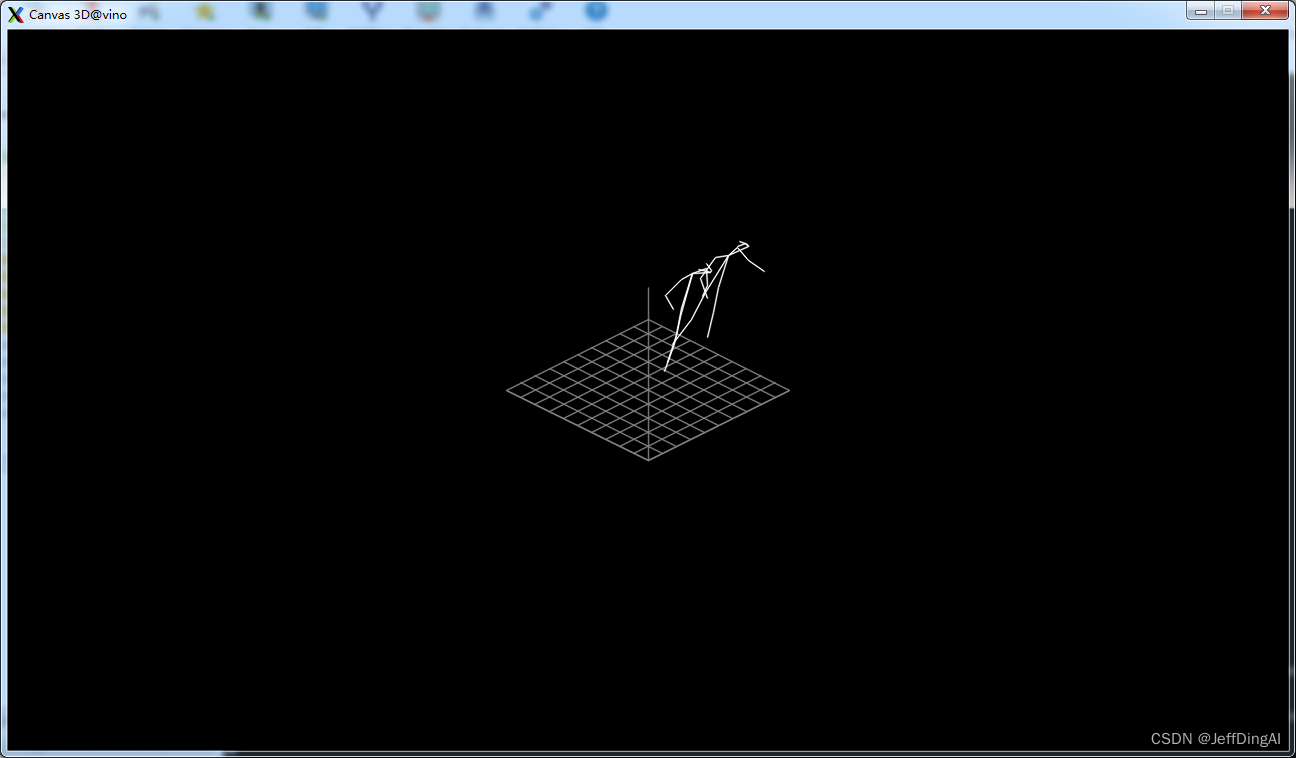
图像着色示例
设置实验路径
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Colorization/
初始化OpenVINO
source $OV/bin/setupvars.sh
运行着色Demo
python3 $OV/inference_engine/demos/colorization_demo/python/colorization_demo.py -m $WD/public/colorization-siggraph/FP16/colorization-siggraph.xml -i butterfly.mp4
任务3:音频检测示例
进入OpenVINO中自带的音频检测示例:
cd $OV/data_processing/dl_streamer/samples/gst_launch/audio_detect
#你可以查看检测的标签文件
vi ./model_proc/aclnet.json
运行示例
bash audio_event_detection.sh
分析音频检测结果
bash audio_event_detection.sh | grep "label\":" |sed 's/.*label"//' | sed 's/"label_id.*start_timestamp"://' | sed 's/}].*//'
公式识别
初始化环境
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Formula_recognition/
source $OV/bin/setupvars.sh
查看可识别的字符
vi hand.json
打印字符
vi latex.json
查看待识别的公式
#进入材料目录
cd $WD/../Materials/
#查看打印公式
show Latex-formula.png
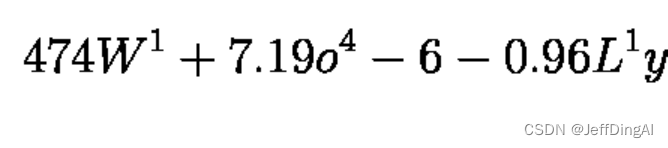
#查看手写公式
show Hand-formula.png

运行公式识别
$WD
#识别打印公式
python3 $OV/inference_engine/demos/formula_recognition_demo/python/formula_recognition_demo.py -m_encoder $WD/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-encoder/FP16/formula-recognition-medium-scan-0001-im2latex-encoder.xml -m_decoder $WD/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-decoder/FP16/formula-recognition-medium-scan-0001-im2latex-decoder.xml --vocab_pathlatex.json -i $WD/../Materials/Latex-formula.png -no_show
识别手写公式
python3 $OV/inference_engine/demos/formula_recognition_demo/python/formula_recognition_demo.py -m_encoder $WD/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-encoder/FP16/formula-recognition-polynomials-handwritten-0001-encoder.xml -m_decoder $WD/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-decoder/FP16/formula-recognition-polynomials-handwritten-0001-decoder.xml --vocab_path hand.json -i $WD/../Materials/Hand-formula.png -no_show
环境深度识别
初始化环境
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/MonoDepth_Python/
#初始化OpenVINO
source $OV/bin/setupvars.sh
转换原始模型文件为IR文件
#下载好的模型为TensorFlow格式,使用converter准换为IR格式:
python3 $OV/deployment_tools/tools/model_downloader/converter.py --list $OV/deployment_tools/inference_engine/demos/monodepth_demo/python/models.lst
运行深度识别示例
cd $WD
#运行示例,该示例的作用是自动分离图片中景深不同的地方:
python3 $OV/inference_engine/demos/monodepth_demo/python/monodepth_demo.py -m $WD/public/midasnet/FP32/midasnet.xml -i tree.jpeg
运行结果:

任务6:目标识别示例
初始化环境
export OV=/opt/intel/openvino_2021/
#定义工作目录
export WD=~/OV-300/01/Object_Detection/
#初始化OpenVINO
source $OV/bin/setupvars.sh
#进入工作目录
cd $WD
选择适合你的模型
#由于支持目标检测的模型较多,你可以在不同拓扑网络下选择适合模型:
vi $OV/inference_engine/demos/object_detection_demo/python/models.lst
转换模型至IR格式
python3 $OV/deployment_tools/tools/model_downloader/converter.py --name yolo-v3-tf
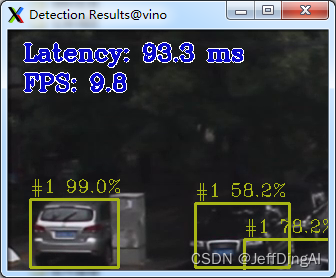
使用SSD模型运行目标检测示例
cd $WD
#运行 OMZ (ssd) model
python3 $OV/inference_engine/demos/object_detection_demo/python/object_detection_demo.py -m $WD/intel/pedestrian-and-vehicle-detector-adas-0001/FP16/pedestrian-and-vehicle-detector-adas-0001.xml --architecture_type ssd -i $WD/../Materials/Road.mp4
运行结果:
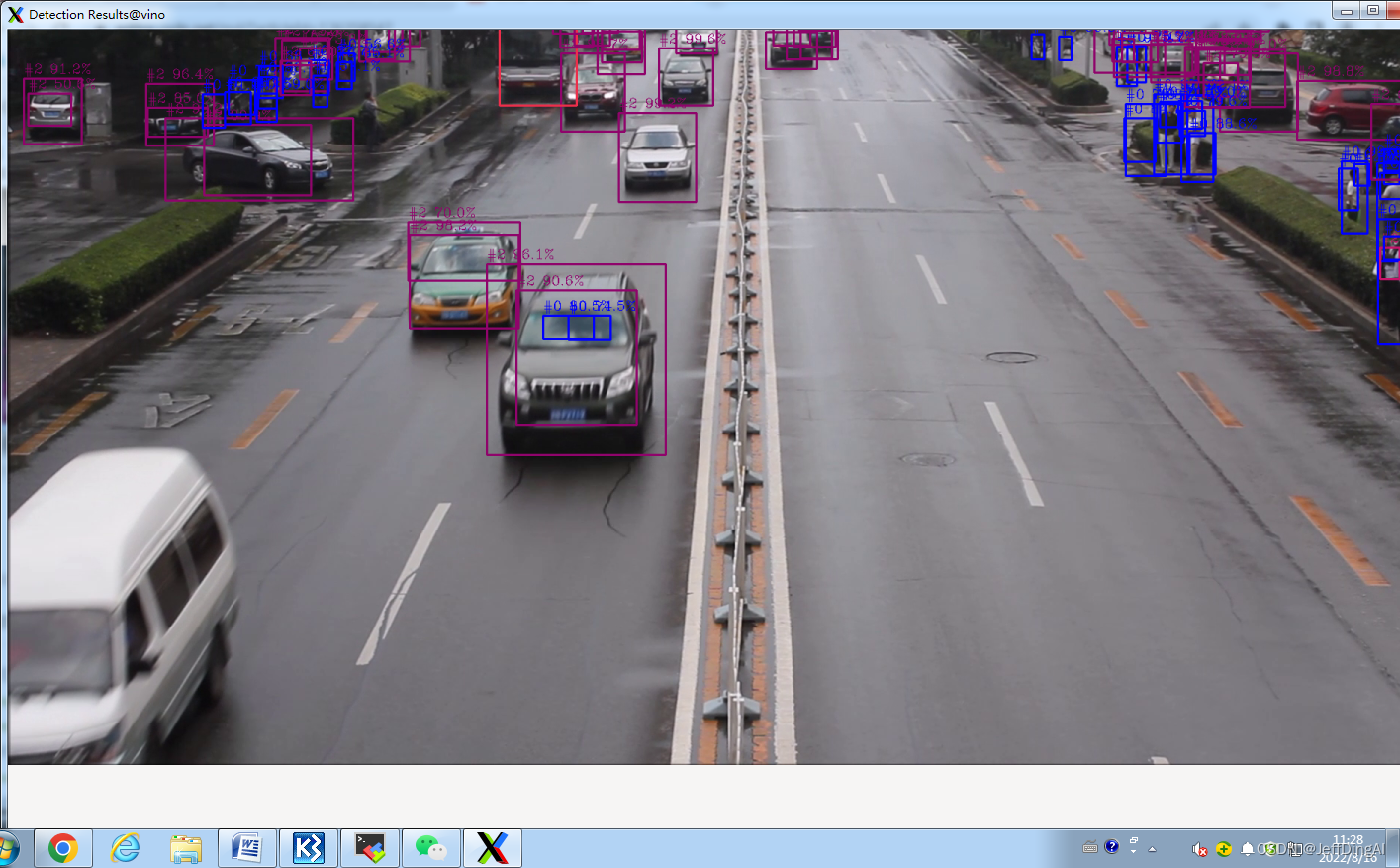
运行Yolo-V3下的目标检测示例
# 运行 the Yolo V3 model
python3 $OV/inference_engine/demos/object_detection_demo/python/object_detection_demo.py -m $WD/public/yolo-v3-tf/FP16/yolo-v3-tf.xml -i $WD/../Materials/Road.mp4 --architecture_type yolo
运行结果:
任务7:自然语言处理示例(NLP)——自动回答问题示例
初始化环境
#定义工作目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/NLP-Bert/
#初始化OpenVINO
source $OV/bin/setupvars.sh
#进入目录
cd $WD
查看支持的模型列表
#可用列表:
cat $OV/deployment_tools/inference_engine/demos/bert_question_answering_demo/python/models.lst
注:在OpenVINO中的deployment_tools/inference_engine/demos/的各个demo文件夹中都有model.lst列出了该demo支持的可直接通过downloader下载使用的模型,且我们已经事先下载好全部模型为IR格式。
打开待识别的网址
#使用浏览器打开一个英文网址进行浏览,例如Intel官网:https://www.intel.com/content/www/us/en/homepage.html
运行NLP示例
python3 $OV/inference_engine/demos/bert_question_answering_demo/python/bert_question_answering_demo.py -m $WD/intel/bert-small-uncased-whole-word-masking-squad-0001/FP16/bert-small-uncased-whole-word-masking-squad-0001.xml -v $OV/deployment_tools/open_model_zoo/models/intel/bert-small-uncased-whole-word-masking-squad-0001/vocab.txt --input=https://www.intel.com/content/www/us/en/homepage.html --input_names=input_ids,attention_mask,token_type_ids --output_names=output_s,output_e

- 点赞
- 收藏
- 关注作者
评论(0)