PGL图学习之图神经网络GNN模型GCN、GAT[系列六]

PGL图学习之图神经网络GNN模型GCN、GAT[系列六]
项目链接:一键fork直接跑程序 https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=1
0.前言-学术界业界论文发表情况
ICLR2023评审情况:
ICLR2023的评审结果已经正式发布!今年的ICLR2023共计提交6300份初始摘要和4922份经过审查的提交,其中经过审查提交相比上一年增加了32.2%。在4922份提交内容中,99%的内容至少有3个评论,总共有超过18500个评论。按照Open Review评审制度,目前ICLR已经进入讨论阶段。
官网链接:https://openreview.net/group?id=ICLR.cc/2022/Conference
在4922份提交内容中,主要涉及13个研究方向,具体有:
1、AI应用应用,例如:语音处理、计算机视觉、自然语言处理等
2、深度学习和表示学习
3、通用机器学习
4、生成模型
5、基础设施,例如:数据集、竞赛、实现、库等
6、科学领域的机器学习,例如:生物学、物理学、健康科学、社会科学、气候/可持续性等
7、神经科学与认知科学,例如:神经编码、脑机接口等
8、优化,例如:凸优化、非凸优化等
9、概率方法,例如:变分推理、因果推理、高斯过程等
10、强化学习,例如:决策和控制,计划,分层RL,机器人等
11、机器学习的社会方面,例如:人工智能安全、公平、隐私、可解释性、人与人工智能交互、伦理等
12、理论,例如:如控制理论、学习理论、算法博弈论。
13、无监督学习和自监督学习
ICLR详细介绍:
ICLR,全称为「International Conference on Learning Representations」(国际学习表征会议),2013 年5月2日至5月4日在美国亚利桑那州斯科茨代尔顺利举办了第一届ICLR会议。该会议是一年一度的会议,截止到2022年它已经举办了10届,而今年的(2023年)5月1日至5日,将在基加利会议中心完成ICLR的第十一届会议。
该会议被学术研究者们广泛认可,被认为是「深度学习的顶级会议」。为什么ICLR为什么会成为深度学习领域的顶会呢? 首先该会议由深度学习三大巨头之二的Yoshua Bengio和Yann LeCun 牵头创办。其中Yoshua Bengio 是蒙特利尔大学教授,深度学习三巨头之一,他领导蒙特利尔大学的人工智能实验室MILA进行 AI 技术的学术研究。MILA 是世界上最大的人工智能研究中心之一,与谷歌也有着密切的合作。 Yann LeCun同为深度学习三巨头之一的他现任 Facebook 人工智能研究院FAIR院长、纽约大学教授。作为卷积神经网络之父,他为深度学习的发展和创新作出了重要贡献。
Keywords Frequency 排名前 50 的常用关键字(不区分大小写)及其出现频率:
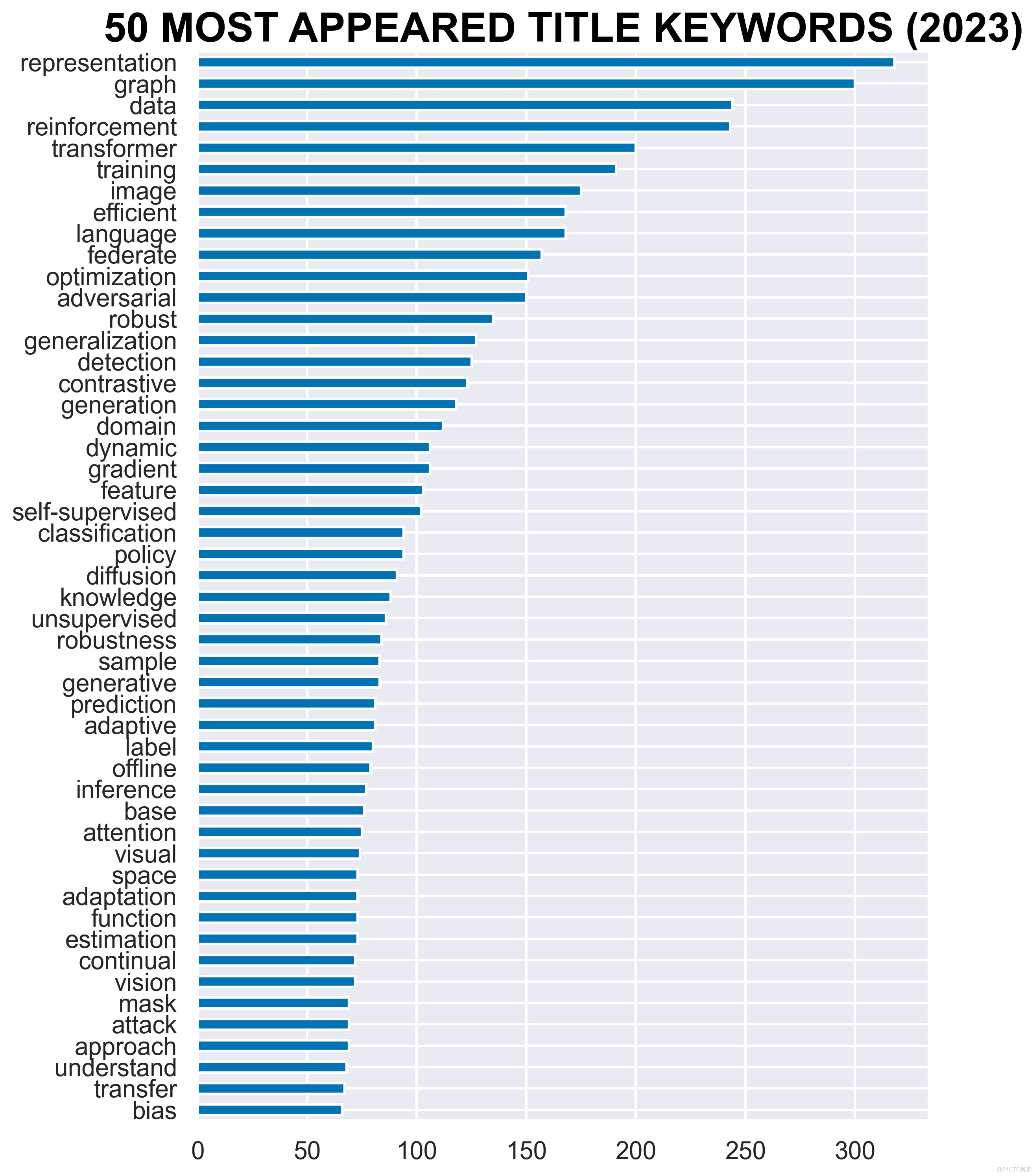
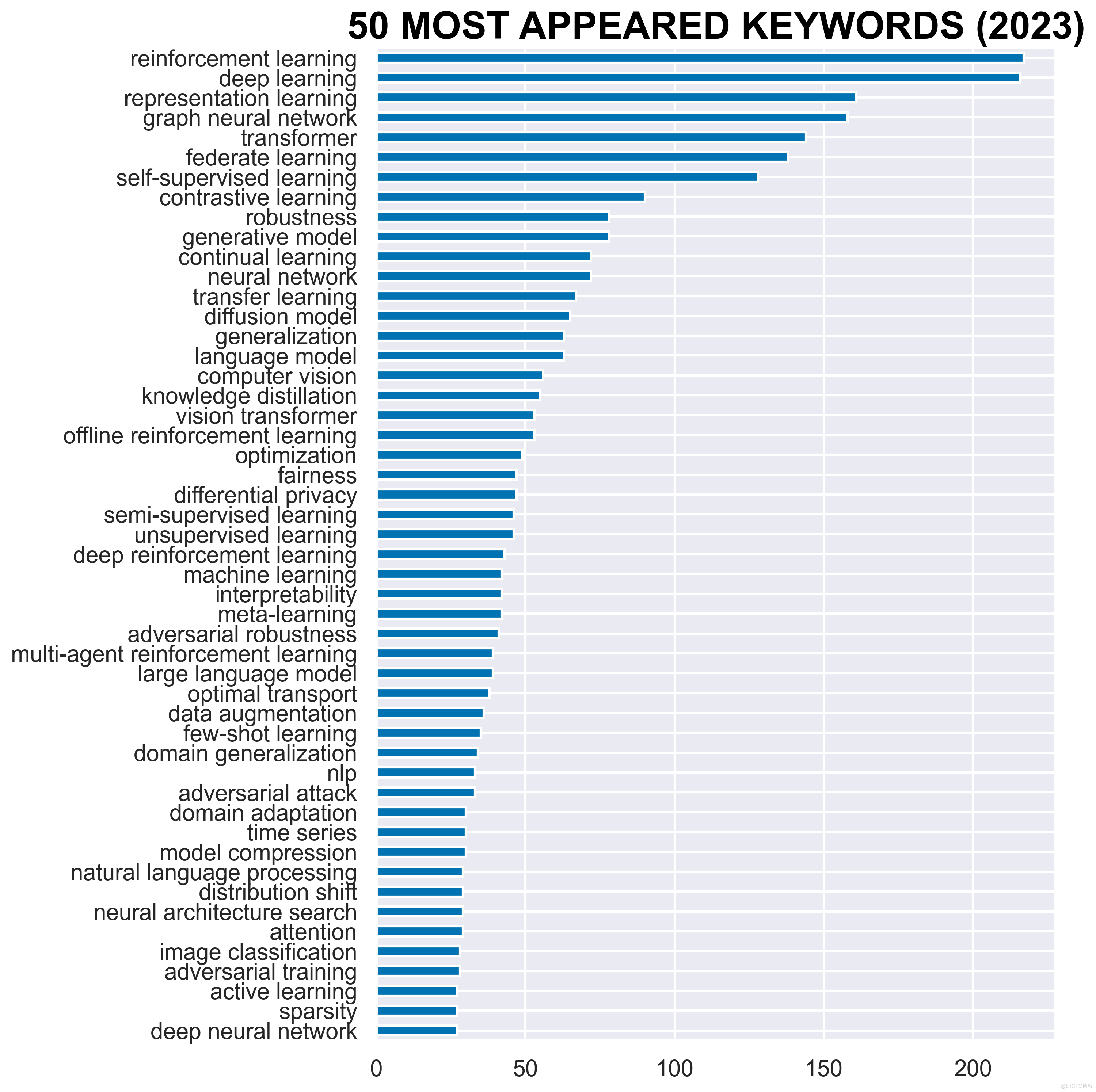
可有看到图、图神经网络分别排在2、4。
1.Graph Convolutional Networks(GCN,图卷积神经网络)
GCN的概念首次提出于ICLR2017(成文于2016年):
Semi-Supervised Classification with Graph Convolutional Networks:https://arxiv.org/abs/1609.02907
图数据中的空间特征具有以下特点:
1) 节点特征:每个节点有自己的特征;(体现在点上)
2) 结构特征:图数据中的每个节点具有结构特征,即节点与节点存在一定的联系。(体现在边上)
总地来说,图数据既要考虑节点信息,也要考虑结构信息,图卷积神经网络就可以自动化地既学习节点特征,又能学习节点与节点之间的关联信息。
综上所述,GCN是要为除CV、NLP之外的任务提供一种处理、研究的模型。
图卷积的核心思想是利用『边的信息』对『节点信息』进行『聚合』从而生成新的『节点表示』。
1.1原理简介
-
假如我们希望做节点相关的任务,就可以通过 Graph Encoder,在图上学习到节点特征,再利用学习到的节点特征做一些相关的任务,比如节点分类、关系预测等等;
-
而同时,我们也可以在得到的节点特征的基础上,做 Graph Pooling 的操作,比如加权求和、取平均等等操作,从而得到整张图的特征,再利用得到的图特征做图相关的任务,比如图匹配、图分类等。
图游走类算法主要的目的是在训练得到节点 embedding 之后,再利用其做下游任务,也就是说区分为了两个阶段。
对于图卷积网络而言,则可以进行一个端到端的训练,不需要对这个过程进行区分,那么这样其实可以更加针对性地根据具体任务来进行图上的学习和训练。

回顾卷积神经网络在图像及文本上的发展
在图像上的二维卷积,其实质就是卷积核在二维图像上平移,将卷积核的每个元素与被卷积图像对应位置相乘,再求和,得到一个新的结果。其实它有点类似于将当前像素点和周围的像素点进行某种程度的转换,再得到当前像素点更新后的一个值。
它的本质是利用了一维卷积,因为文本是一维数据,在我们已知文本的词表示之后,就在词级别上做一维的卷积。其本质其实和图像上的卷积没有什么差别。
(注:卷积核维度和红框维度相同,2 * 6就是2 * 6)
图像卷积的本质其实非常简单,就是将一个像素点周围的像素,按照不同的权重叠加起来,当然这个权重就是我们通常说的卷积核。
其实可以把当前像素点类比做图的节点,而这个节点周围的像素则类比为节点的邻居,从而可以得到图结构卷积的简单的概念:
将一个节点周围的邻居按照不同的权重叠加起来
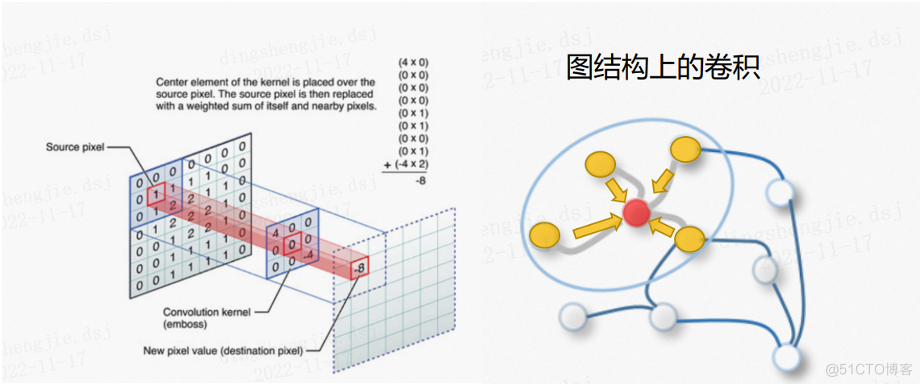
而图像上的卷积操作,与图结构上的卷积操作,最大的一个区别就在于:
- 对于图像的像素点来说,它的周围像素点数量其实是固定的;
- 但是对于图而言,节点的邻居数量是不固定的。
1.2图卷积网络的两种理解方式
GCN的本质目的就是用来提取拓扑图的空间特征。 而图卷积神经网络主要有两类,一类是基于空间域或顶点域vertex domain(spatial domain)的,另一类则是基于频域或谱域spectral domain的。通俗点解释,空域可以类比到直接在图片的像素点上进行卷积,而频域可以类比到对图片进行傅里叶变换后,再进行卷积。
所谓的两类其实就是从两个不同的角度理解,关于从空间角度的理解可以看本文的从空间角度理解GCN
vertex domain(spatial domain):顶点域(空间域)
基于空域卷积的方法直接将卷积操作定义在每个结点的连接关系上,它跟传统的卷积神经网络中的卷积更相似一些。在这个类别中比较有代表性的方法有 Message Passing Neural Networks(MPNN)[1], GraphSage[2], Diffusion Convolution Neural Networks(DCNN)[3], PATCHY-SAN[4]等。
spectral domain:频域方法(谱方法
这就是谱域图卷积网络的理论基础了。这种思路就是希望借助图谱的理论来实现拓扑图上的卷积操作。从整个研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的Fourier Transformation,进而定义了graph上的convolution,最后与深度学习结合提出了Graph Convolutional Network。
基于频域卷积的方法则从图信号处理起家,包括 Spectral CNN[5], Cheybyshev Spectral CNN(ChebNet)[6], 和 First order of ChebNet(1stChebNet)[7] 等
论文Semi-Supervised Classification with Graph Convolutional Networks就是一阶邻居的ChebNet
认真读到这里,脑海中应该会浮现出一系列问题:
Q1 什么是Spectral graph theory?
Spectral graph theory请参考维基百科的介绍,简单的概括就是借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质
Q2 GCN为什么要利用Spectral graph theory?
这是论文(Semi-Supervised Classification with Graph Convolutional Networks)中的重点和难点,要理解这个问题需要大量的数学定义及推导
过程:
- (1)定义graph上的Fourier Transformation傅里叶变换(利用Spectral graph theory,借助图的拉普拉斯矩阵的特征值和特征向量研究图的性质)
- (2)定义graph上的convolution卷积
1.3 图卷积网络的计算公式
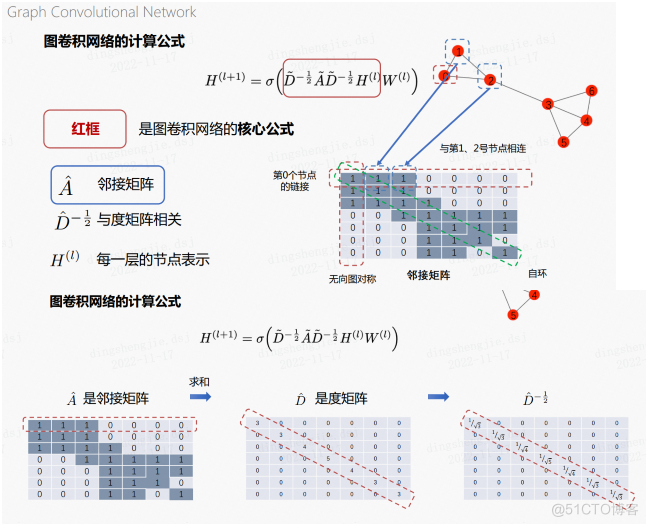
- H代表每一层的节点表示,第0层即为最开始的节点表示
- A表示邻接矩阵,如下图所示,两个节点存在邻居关系就将值设为1,对角线默认为1
- D表示度矩阵,该矩阵除对角线外均为0,对角线的值表示每个节点的度,等价于邻接矩阵对行求和
- W表示可学习的权重
邻接矩阵的对角线上都为1,这是因为添加了自环边,这也是这个公式中使用的定义,其他情况下邻接矩阵是可以不包含自环的。(包含了自环边的邻接矩阵)
度矩阵就是将邻接矩阵上的每一行进行求和,作为对角线上的值。而由于我们是要取其-1/2的度矩阵,因此还需要对对角线上求和后的值做一个求倒数和开根号的操作,因此最后可以得到右边的一个矩阵运算结果。
为了方便理解,我们可以暂时性地把度矩阵在公式中去掉:
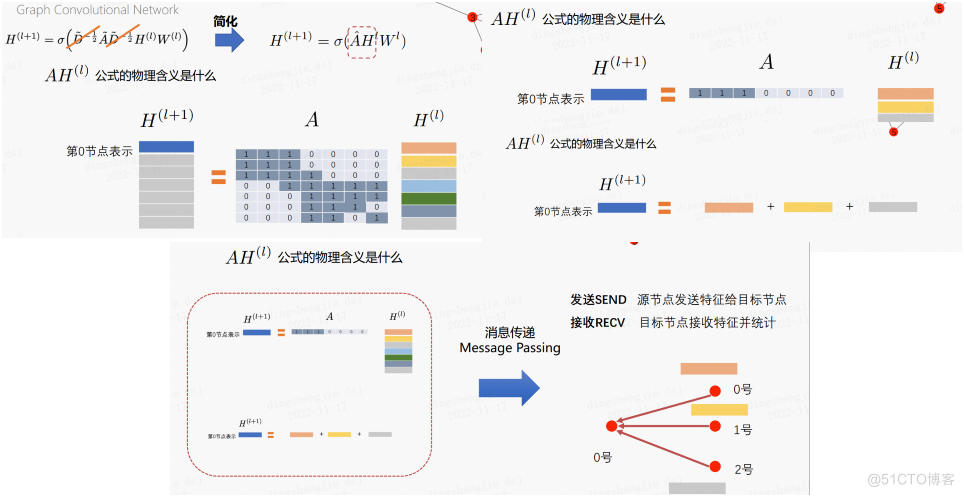
- 为了得到 H^{(l+1)}的第0行,我们需要拿出A的第0行与 H^{(l)}相乘,这是矩阵乘法的概念。
- 接下来就是把计算结果相乘再相加的过程。
- 这个过程其实就是消息传递的过程:对于0号节点来说,将邻居节点的信息传给自身
将上式进行拆分,A*H可以理解成将上一层每个节点的节点表示进行聚合,如图,0号节点就是对上一层与其相邻的1号、2号节点和它本身进行聚合。而度矩阵D存在的意义是每个节点的邻居的重要性不同,根据该节点的度来对这些相邻节点的节点表示进行加权,d越大,说明信息量越小。
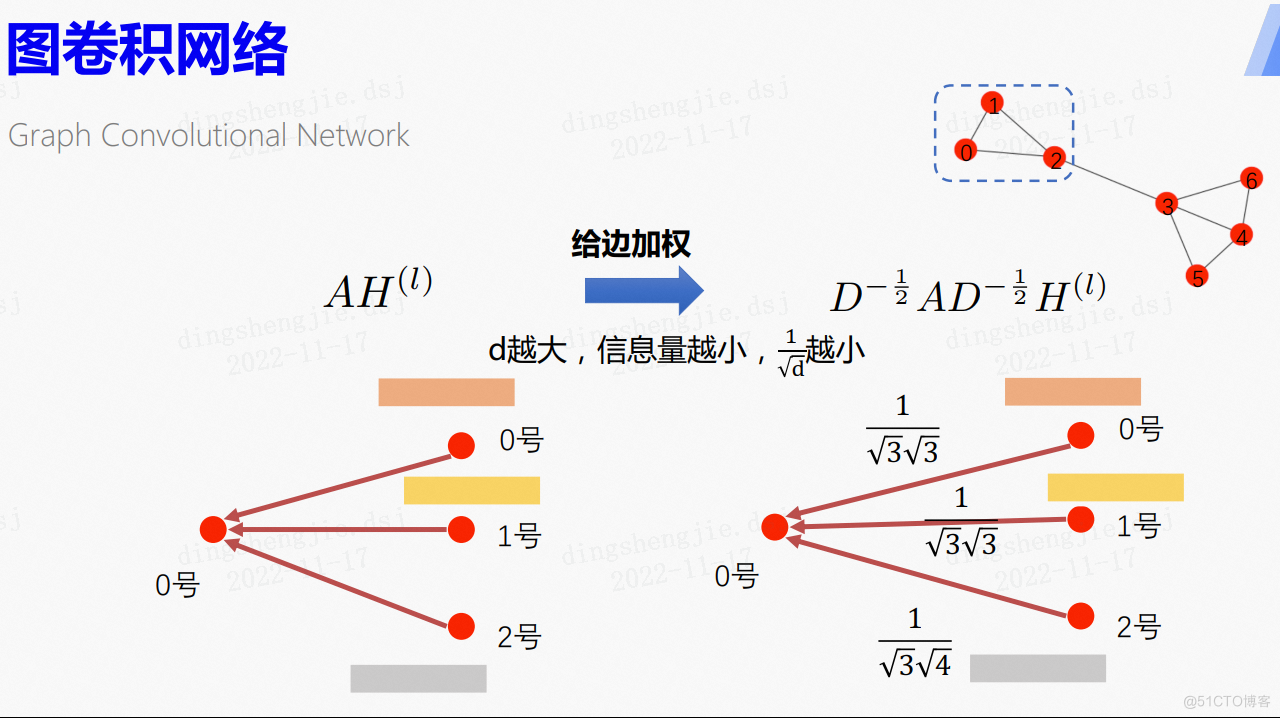
实际情况中,每个节点发送的信息所带的信息量应该是不同的。
图卷积网络将邻接矩阵的两边分别乘上了度矩阵,相当于给这个边加了权重。其实就是利用节点度的不同来调整信息量的大小。
这个公式其实体现了:
一个节点的度越大,那么它所包含的信息量就越小,从而对应的权值也就越小。
怎么理解这样的一句话呢,我们可以设想这样的一个场景。假如说在一个社交网络里,一个人认识了几乎所有的人,那么这个人能够给我们的信息量是比较小的。
也就是说,每个节点通过边对外发送相同量的信息, 边越多的节点,每条边发送出去的信息量就越小。
1.4用多层图网络完成节点分类任务
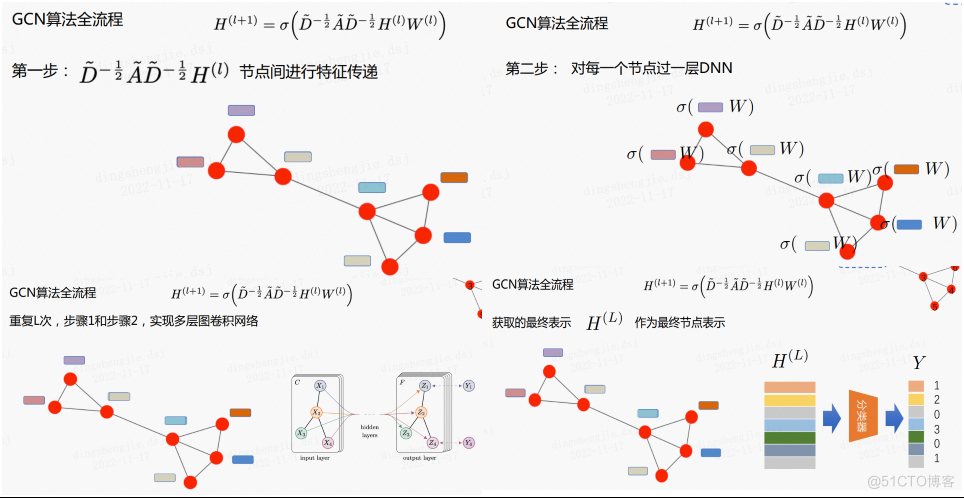
GCN算法主要包括以下几步:
- 第一步是利用上面的核心公式进行节点间特征传递
- 第二步对每个节点过一层DNN
- 重复以上两步得到L层的GCN
- 获得的最终节点表示H送入分类器进行分类
更详细的资料参考:图卷积网络 GCN Graph Convolutional Network(谱域GCN)的理解和详细推导
1.5 GCN参数解释
主要是帮助大家理解消息传递机制的一些参数类型。
这里给出一个简化版本的 GCN 模型,帮助理解PGL框架实现消息传递的流程。
def gcn_layer(gw, feature, hidden_size, activation, name, norm=None):
"""
描述:通过GCN层计算新的节点表示
输入:gw - GraphWrapper对象
feature - 节点表示 (num_nodes, feature_size)
hidden_size - GCN层的隐藏层维度 int
activation - 激活函数 str
name - GCN层名称 str
norm - 标准化tensor float32 (num_nodes,),None表示不标准化
输出:新的节点表示 (num_nodes, hidden_size)
"""
# send函数
def send_func(src_feat, dst_feat, edge_feat):
"""
描述:用于send节点信息。函数名可自定义,参数列表固定
输入:src_feat - 源节点的表示字典 {name:(num_edges, feature_size)}
dst_feat - 目标节点表示字典 {name:(num_edges, feature_size)}
edge_feat - 与边(src, dst)相关的特征字典 {name:(num_edges, feature_size)}
输出:存储发送信息的张量或字典 (num_edges, feature_size) or {name:(num_edges, feature_size)}
"""
return src_feat["h"] # 直接返回源节点表示作为信息
# send和recv函数是搭配实现的,send的输出就是recv函数的输入
# recv函数
def recv_func(msg):
"""
描述:对接收到的msg进行聚合。函数名可自定义,参数列表固定
输出:新的节点表示张量 (num_nodes, feature_size)
"""
return L.sequence_pool(msg, pool_type='sum') # 对接收到的消息求和
### 消息传递机制执行过程
# gw.send函数
msg = gw.send(send_func, nfeat_list=[("h", feature)])
"""
描述:触发message函数,发送消息并将消息返回
输入:message_func - 自定义的消息函数
nfeat_list - list [name] or tuple (name, tensor)
efeat_list - list [name] or tuple (name, tensor)
输出:消息字典 {name:(num_edges, feature_size)}
"""
# gw.recv函数
output = gw.recv(msg, recv_func)
"""
描述:触发reduce函数,接收并处理消息
输入:msg - gw.send输出的消息字典
reduce_function - "sum"或自定义的reduce函数
输出:新的节点特征 (num_nodes, feature_size)
如果reduce函数是对消息求和,可以直接用"sum"作为参数,使用内置函数加速训练,上述语句等价于 \
output = gw.recv(msg, "sum")
"""
# 通过以activation为激活函数的全连接输出层
output = L.fc(output, size=hidden_size, bias_attr=False, act=activation, name=name)
return output
2.Graph Attention Networks(GAT,图注意力机制网络)
Graph Attention Networks:https://arxiv.org/abs/1710.10903
GCN网络中的一个缺点是边的权重与节点的度度相关而且不可学习,因此有了图注意力算法。在GAT中,边的权重变成节点间的可学习的函数并且与两个节点之间的相关性有关。
2.1.计算方法
注意力机制的计算方法如下:

首先将目标节点和源节点的表示拼接到一起,通过网络计算相关性,之后通过LeakyReLu激活函数和softmax归一化得到注意力分数,最后用得到的α进行聚合,后续步骤和GCN一致。
以及多头Attention公式
2.2 空间GNN
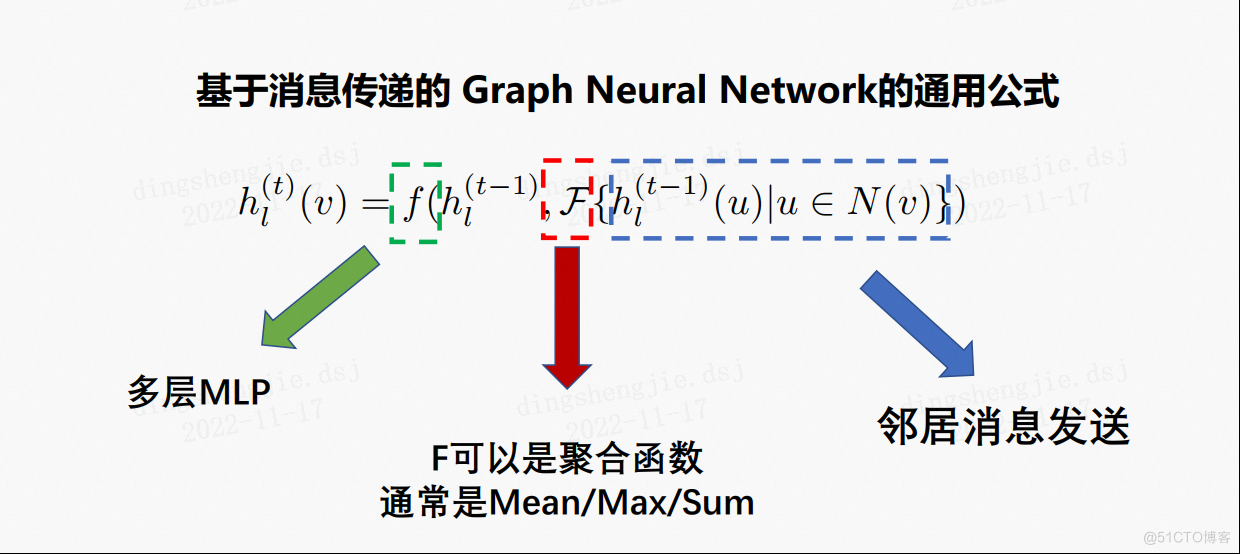
空间GNN(Spatial GNN):基于邻居聚合的图模型称为空间GNN,例如GCN、GAT等等。大部分的空间GNN都可以用消息传递实现,消息传递包括消息的发送和消息的接受。
基于消息传递的图神经网络的通用公式:
2.3 消息传递demo例子

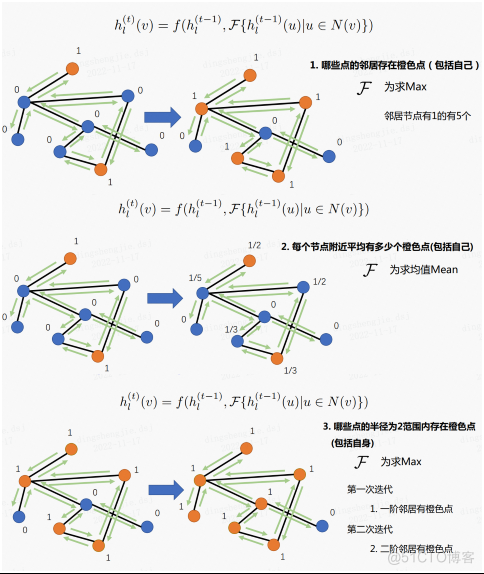
2.4 GAT参数解释
其中:
- 在 send 函数中完成 LeakyReLU部分的计算;
- 在 recv 函数中,对接受到的 logits 信息进行 softmax 操作,形成归一化的分数(公式当中的 alpha),再与结果进行加权求和。
def single_head_gat(graph_wrapper, node_feature, hidden_size, name):
# 实现单头GAT
def send_func(src_feat, dst_feat, edge_feat):
##################################
# 按照提示一步步理解代码吧,你只需要填###的地方
# 1. 将源节点特征与目标节点特征concat 起来,对应公式当中的 concat 符号,可能用到的 API: fluid.layers.concat
Wh = fluid.layers.concat(input=[src_feat["Wh"], dst_feat["Wh"]], axis=1)
# 2. 将上述 Wh 结果通过全连接层,也就对应公式中的a^T
alpha = fluid.layers.fc(Wh,
size=1,
name=name + "_alpha",
bias_attr=False)
# 3. 将计算好的 alpha 利用 LeakyReLU 函数激活,可能用到的 API: fluid.layers.leaky_relu
alpha = fluid.layers.leaky_relu(alpha, 0.2)
##################################
return {"alpha": alpha, "Wh": src_feat["Wh"]}
def recv_func(msg):
##################################
# 按照提示一步步理解代码吧,你只需要填###的地方
# 1. 对接收到的 logits 信息进行 softmax 操作,形成归一化分数,可能用到的 API: paddle_helper.sequence_softmax
alpha = msg["alpha"]
norm_alpha = paddle_helper.sequence_softmax(alpha)
# 2. 对 msg["Wh"],也就是节点特征,用上述结果进行加权
output = norm_alpha * msg["Wh"]
# 3. 对加权后的结果进行相加的邻居聚合,可能用到的API: fluid.layers.sequence_pool
output = fluid.layers.sequence_pool(output, pool_type="sum")
##################################
return output
# 这一步,其实对应了求解公式当中的Whi, Whj,相当于对node feature加了一个全连接层
Wh = fluid.layers.fc(node_feature, hidden_size, bias_attr=False, name=name + "_hidden")
# 消息传递机制执行过程
message = graph_wrapper.send(send_func, nfeat_list=[("Wh", Wh)])
output = graph_wrapper.recv(message, recv_func)
output = fluid.layers.elu(output)
return output
def gat(graph_wrapper, node_feature, hidden_size):
# 完整多头GAT
# 这里配置多个头,每个头的输出concat在一起,构成多头GAT
heads_output = []
# 可以调整头数 (8 head x 8 hidden_size)的效果较好
n_heads = 8
for head_no in range(n_heads):
# 请完成单头的GAT的代码
single_output = single_head_gat(graph_wrapper,
node_feature,
hidden_size,
name="head_%s" % (head_no) )
heads_output.append(single_output)
output = fluid.layers.concat(heads_output, -1)
return output
3.数据集介绍
3个常用的图学习数据集,CORA, PUBMED, CITESEER。可以在论文中找到数据集的相关介绍。
今天我们来了解一下这几个数据集
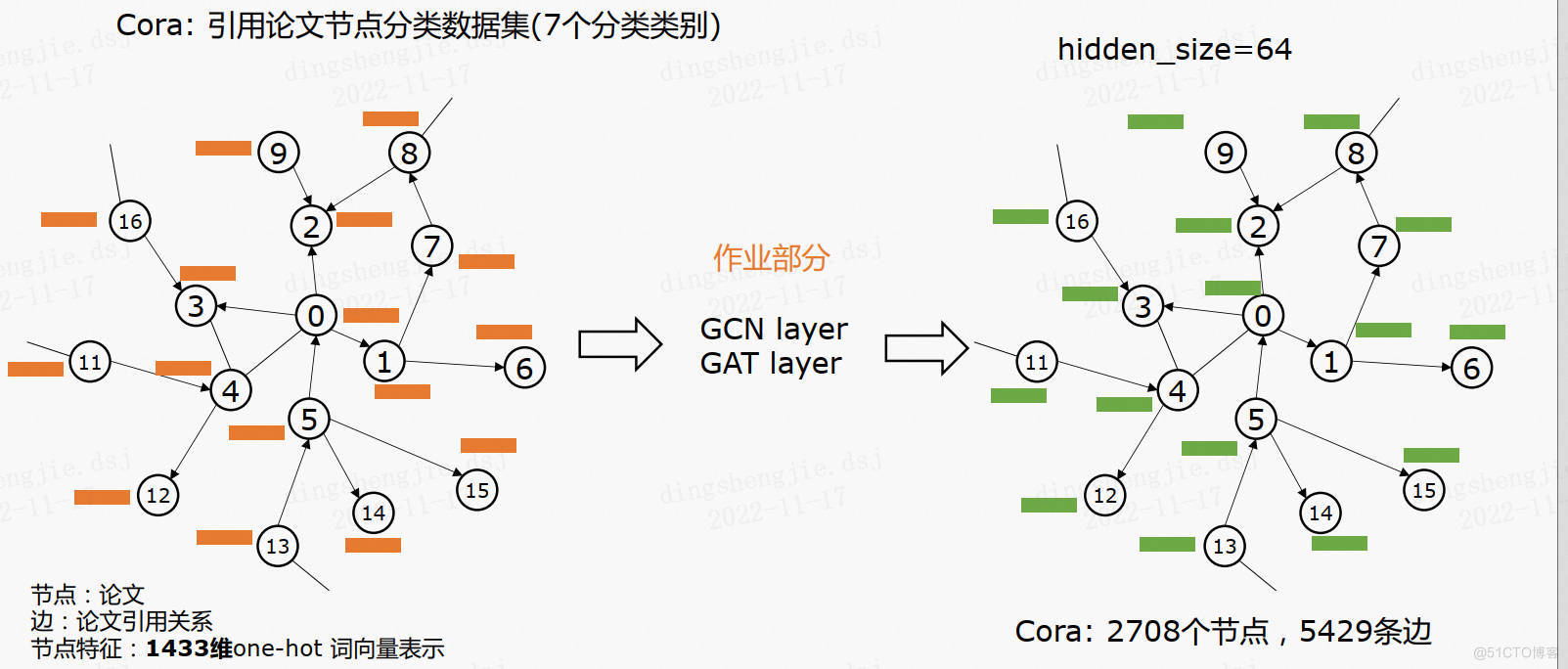
3.1Cora数据集
Cora数据集由机器学习论文组成,是近年来图深度学习很喜欢使用的数据集。
在整个语料库中包含2708篇论文,并分为以下七类:
- 基于案例
- 遗传算法
- 神经网络
- 概率方法
- 强化学习
- 规则学习
- 理论
论文之间互相引用,在该数据集中,每篇论文都至少引用了一篇其他论文,或者被其他论文引用,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点。这样形成的网络有5429条边。
在消除停词以及除去文档频率小于10的词汇,最终词汇表中有1433个词汇。每篇论文都由一个1433维的词向量表示,所以,每个样本点具有1433个特征。词向量的每个元素都对应一个词,且该元素只有0或1两个取值。取0表示该元素对应的词不在论文中,取1表示在论文中。
数据集有包含两个文件:
- .content文件包含以下格式的论文描述:
<paper_id> <word_attributes>+ <class_label>
每行的第一个条目包含纸张的唯一字符串标识,后跟二进制值,指示词汇中的每个单词在文章中是存在(由1表示)还是不存在(由0表示)。
最后,该行的最后一个条目包含纸张的类别标签。因此数据集的
应该为
维度。
第一行为
,最后一行为
。
- 那个.cites文件包含语料库的引用’图’。每行以以下格式描述一个链接:
<被引论文编号> <引论文编号>
每行包含两个纸质id。第一个条目是被引用论文的标识,第二个标识代表包含引用的论文。链接的方向是从右向左。
如果一行由“论文1 论文2”表示,则链接是“论文2 - >论文1”。可以通过论文之间的索引关系建立邻接矩阵adj
下载链接:
https://aistudio.baidu.com/aistudio/datasetdetail/177587
相关论文:
- Qing Lu, and Lise Getoor. “Link-based classification.” ICML, 2003.
- Prithviraj Sen, et al. “Collective classification in network data.” AI Magazine, 2008.
3.2PubMed数据集
PubMed 是一个提供生物医学方面的论文搜寻以及摘要,并且免费搜寻的数据库。它的数据库来源为MEDLINE。其核心主题为医学,但亦包括其他与医学相关的领域,像是护理学或者其他健康学科。
PUBMED数据集是基于PubMed 文献数据库生成的。它包含了19717篇糖尿病相关的科学出版物,这些出版物被分成三个类别。
这些出版物的互相引用网络包含了44338条边。在消除停词以及除去低频词汇,最终词汇表中有500个词汇。这些出版物用一个TF/IDF加权的词向量来描述是否包含词汇表中的词汇。
下载链接:
https://aistudio.baidu.com/aistudio/datasetdetail/177591
相关论文:
3.3CiteSeer数据集
CiteSeer(又名ResearchIndex),是NEC研究院在自动引文索引(Autonomous Citation Indexing, ACI)机制的基础上建设的一个学术论文数字图书馆。这个引文索引系统提供了一种通过引文链接的检索文献的方式,目标是从多个方面促进学术文献的传播和反馈。
在整个语料库中包含3312篇论文,并分为以下六类:
- Agents
- AI
- DB
- IR
- ML
- HCI
论文之间互相引用,在该数据集中,每篇论文都至少引用了一篇其他论文,或者被其他论文引用,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点。这样形成的网络有4732条边。
在消除停词以及除去文档频率小于10的词汇,最终词汇表中有3703个词汇。每篇论文都由一个3703维的词向量表示,所以,每个样本点具有3703个特征。词向量的每个元素都对应一个词,且该元素只有0或1两个取值。取0表示该元素对应的词不在论文中,取1表示在论文中。
下载链接:
https://aistudio.baidu.com/aistudio/datasetdetail/177589
相关论文
- Qing Lu, and Lise Getoor. “Link-based classification.” ICML, 2003.
- Prithviraj Sen, et al. “Collective classification in network data.” AI Magazine, 2008.
3.4 小结
| 数据集 | 图数 | 节点数 | 边数 | 特征维度 | 标签数 |
|---|---|---|---|---|---|
| Cora | 1 | 2708 | 5429 | 1433 | 7 |
| Citeseer | 1 | 3327 | 4732 | 3703 | 6 |
| Pubmed | 1 | 19717 | 44338 | 500 | 3 |
更多图数据集:
https://linqs.org/datasets/
GCN常用数据集
KarateClub:数据为无向图,来源于论文An Information Flow Model for Conflict and Fission in Small Groups
TUDataset:包括58个基础的分类数据集集合,数据都为无向图,如”IMDB-BINARY”,”PROTEINS”等,来源于TU Dortmund University
Planetoid:引用网络数据集,包括“Cora”, “CiteSeer” and “PubMed”,数据都为无向图,来源于论文Revisiting Semi-Supervised Learning with Graph Embeddings。节点代表文档,边代表引用关系。
CoraFull:完整的”Cora”引用网络数据集,数据为无向图,来源于论文Deep Gaussian Embedding of Graphs: Unsupervised Inductive Learning via Ranking。节点代表文档,边代表引用关系。
Coauthor:共同作者网络数据集,包括”CS”和”Physics”,数据都为无向图,来源于论文Pitfalls of Graph Neural Network Evaluation。节点代表作者,若是共同作者则被边相连。学习任务是将作者映射到各自的研究领域中。
Amazon:亚马逊网络数据集,包括”Computers”和”Photo”,数据都为无向图,来源于论文Pitfalls of Graph Neural Network Evaluation。节点代表货物i,边代表两种货物经常被同时购买。学习任务是将货物映射到各自的种类里。
PPI:蛋白质-蛋白质反应网络,数据为无向图,来源于论文Predicting multicellular function through multi-layer tissue networks
Entities:关系实体网络,包括“AIFB”, “MUTAG”, “BGS” 和“AM”,数据都为无向图,来源于论文Modeling Relational Data with Graph Convolutional Networks
BitcoinOTC:数据为有向图,包括138个”who-trusts-whom”网络,来源于论文EvolveGCN: Evolving Graph Convolutional Networks for Dynamic Graphs,数据链接为Bitcoin OTC trust weighted signed network
4.基于PGL的GNN算法实践
4.1 GCN
图卷积网络 (GCN)是一种功能强大的神经网络,专为图上的机器学习而设计。基于PGL复现了GCN算法,在引文网络基准测试中达到了与论文同等水平的指标。
搭建GCN的简单例子:要构建一个 gcn 层,可以使用我们预定义的pgl.nn.GCNConv或者只编写一个带有消息传递接口的 gcn 层。
!CUDA_VISIBLE_DEVICES=0 python train.py --dataset cora
仿真结果:
| Dataset | Accuracy |
|---|---|
| Cora | 81.16% |
| Pubmed | 79.34% |
| Citeseer | 70.91% |
4.2 GAT
图注意力网络 (GAT)是一种对图结构数据进行操作的新型架构,它利用掩蔽的自注意层来解决基于图卷积或其近似的先前方法的缺点。基于PGL,我们复现了GAT算法,在引文网络基准测试中达到了与论文同等水平的指标。
搭建单头GAT的简单例子:
要构建一个 gat 层,可以使用我们的预定义pgl.nn.GATConv或只编写一个带有消息传递接口的 gat 层。
GAT仿真结果:
| Dataset | Accuracy |
|---|---|
| Cora | 82.97% |
| Pubmed | 77.99% |
| Citeseer | 70.91% |
项目链接:一键fork直接跑程序 https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=1
5.总结
本次项目讲解了图神经网络的原理并对GCN、GAT实现方式进行讲解,最后基于PGL实现了两个算法在数据集Cora、Pubmed、Citeseer的表现,在引文网络基准测试中达到了与论文同等水平的指标。
目前的数据集样本节点和边都不是很大,下个项目将会讲解面对亿级别图应该如何去做。
参考链接:感兴趣可以看看详细的推到以及涉及有趣的问题

- 点赞
- 收藏
- 关注作者
评论(0)