JUC快速入门各个知识点汇总(下)

九、线程池(重点)
9.1、介绍线程池
线程池(知识点):三大方法、七大参数、4种策略模式
池化技术:如线程池、连接池、内存池、对象池…。对于原本创建、销毁线程是十分浪费资源的,通过使用线程池能够事先准备好一些资源可供使用,不用时关闭即可。
好处介绍:
- 降低资源的消耗。
- 提高响应的速度。
- 方便管理线程。
通过各个线程复用能够控制最大并发数,并且更有效的管理线程。
9.2、Executors创建线程池的三个方法
认识
Executors创建的三个ExecutorService实现类实例,实际上是四个方法,这里介绍三种。
Executors是一个工具类可提供创建线程池执行不同的执行服务,三个方法如下:
newSingleThreadExecutor():创建一个单线程化的线程池,保证所有的任务按照指定顺序执行。- 应用场景:一个任务一个任务执行的场景。
newFixedThreadPool(int nThreads):创建一个定长线程池,可控制线程的最大并发数,超出的线程会在队列中等待。- 应用场景:执行长期的任务,性能好很多
newCachedThreadPool():创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。- 应用场景:执行很多短期异步的小程序或者负载较轻的服务器。
实际上还有一个newScheduledThreadPool(),这里没有提及该方法。
示例:demo见demo5中的
ExecutorsThreeMethodTest。
目的:用于测试不同的线程池对于指定的任务数量分别会有多少个线程执行。
操作:创建三个不同的线程池,分别执行20次看其中都使用了多少线程。
/**
* @ClassName ExecutorsThreeMethodTest
* @Author ChangLu
* @Date 2021/3/31 22:43
* @Description Executors三大线程池方法的使用
*/
public class ExecutorsThreeMethodTest {
public static void main(String[] args) {
ExecutorService es1 = Executors.newSingleThreadExecutor();//单个线程
ExecutorService es2 = Executors.newFixedThreadPool(5);//创建一个固定线程的线程池
ExecutorService es3 = Executors.newCachedThreadPool();//创建一个可伸缩的线程池,可根据你的执行次数来分配
//测试es1
//testExecutors(es1);
//测试es2
//testExecutors(es2);
//测试es2
testExecutors(es3);
}
//传入一个通过Executors不同创建的方法所获取的ExecutorService
public static void testExecutors(ExecutorService es){
//执行20次方法来查看其中分别使用了多少个线程
try {
for (int i = 0; i < 20; i++) {
es.execute(()->{
System.out.println(Thread.currentThread().getName()+"执行!");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
es.shutdown();//开闭线程池
}
}
}
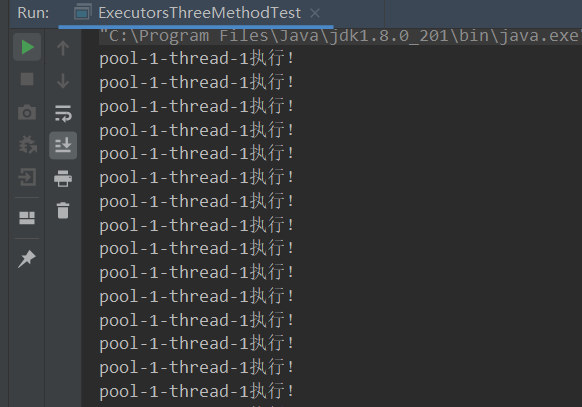
- es1测试,可以看到整个过程都是1个线程来执行。
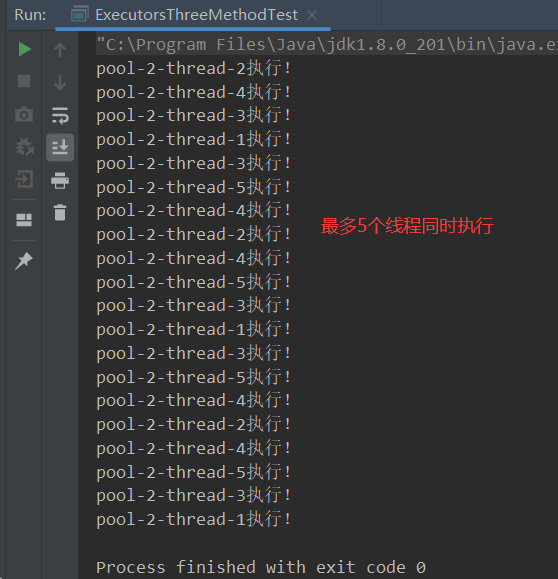
- es2测试
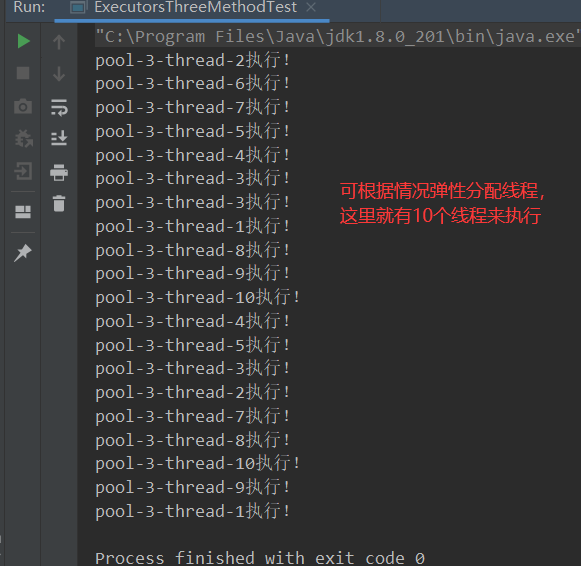
- es3测试
说明:可以看到通过Executors创建的不同线程池,对于执行任务效果也都是不同的,需要注意的是阿里巴巴官方手册上说尽量自己去创建线程池而不要使用Executors工具类来创建。

9.3、自定义线程池(七大属性)
本部分demo见demo6目录中的ThreadPoolExecutorTest.java。
认识ThreadPoolExecutor(详细介绍各个参数)
Executors创建的线程池源码分析
//可以看到使用工具类创建不同的线程池实际上都是创建的ThreadPoolExecutor实例,需要注意其中的参数
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
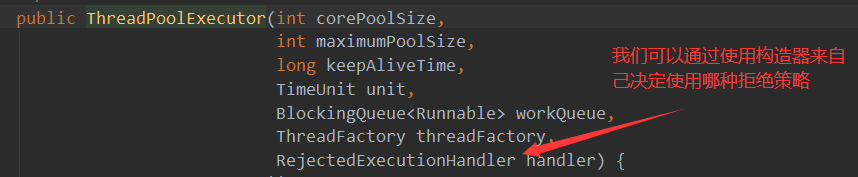
看下ThreadPoolExecutor构造器中的七大参数
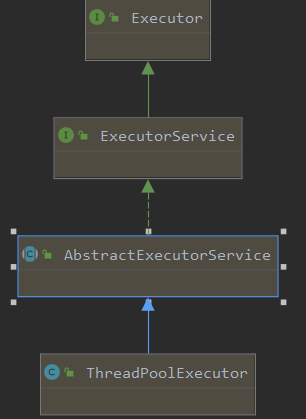

- 包含了四个构造方法,若是使用第一个构造器的话会给你默认最后两个参数(线程工厂和拒绝策略),分为为
Executors.defaultThreadFactory()和new AbortPolicy()。
//七个参数的构造器
public ThreadPoolExecutor(int corePoolSize,//池中核心线程数量(默认开启的)
int maximumPoolSize,//池中最大核心数量(当阻塞队列满时会开启)
long keepAliveTime,//没有任务时等待指定时长若是没有新的任务多余的空闲线程就会终止
TimeUnit unit,//keepAliveTime参数的时间单位
BlockingQueue<Runnable> workQueue,//可设置的阻塞队列
ThreadFactory threadFactory,//线程工厂,默认为Executors.DefaultThreadFactory
RejectedExecutionHandler handler){}//拒绝策略(四种),默认为AbortPolicy
//官方文档翻译介绍
corePoolSize –保留在池中的线程数(即使它们处于空闲状态),除非设置了allowCoreThreadTimeOut
maximumPoolSize –池中允许的最大线程数
keepAliveTime –当线程数大于内核数时,这是多余的空闲线程将在终止之前等待新任务的最长时间。
unit – keepAliveTime参数的时间单位
workQueue –用于在执行任务之前保留任务的队列。 此队列将仅保存execute方法提交的Runnable任务。
threadFactory –执行程序创建新线程时要使用的工厂
handler –因达到线程边界和队列容量而被阻止执行时使用的处理程序,包含四种不同拒绝策略
各个参数细致描述:这部分暂时不去探讨拒绝策略
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2,//核心线程数量
5,//最大线程数量
2,
TimeUnit.SECONDS,//配合上面的时间长度为2秒无任务时等待(针对于非核心线程开启情况)
new LinkedBlockingDeque<>(3),//阻塞队列容量为3
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardPolicy());
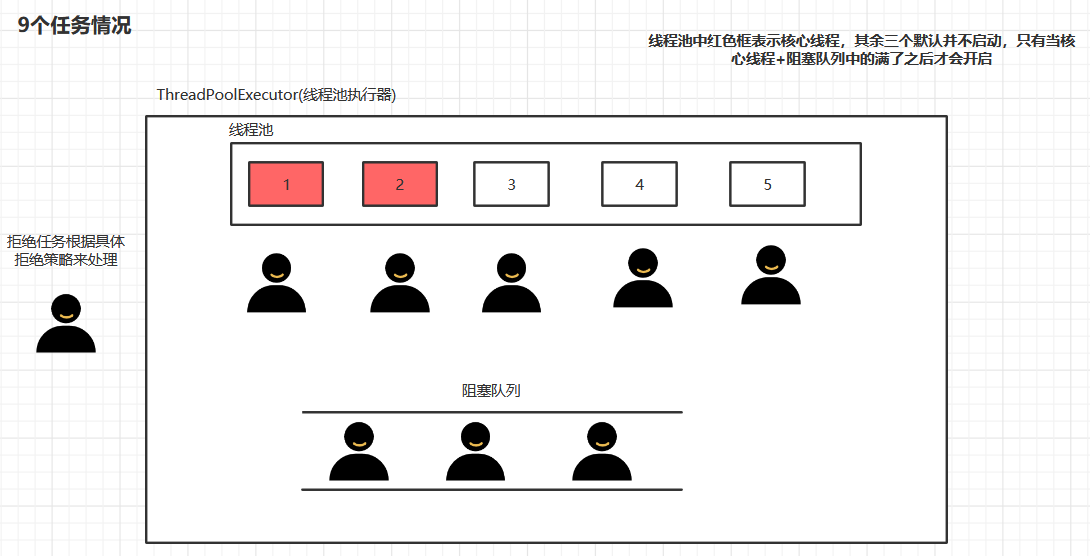
看下面这个图,各个参数对照下图描述:
- 核心线程为
2:就是默认在线程池中开启2个线程(下图红色框1、2),其为核心线程。 - 最大线程数量为
5:前面定义了2个核心线程,最大有5个,那么3个为非核心线程(3、4、5)。开启时间:核心线程(1、2)都有任务并且阻塞队列此时也满了,此时再进来一个任务就会去开启非核心线程(开启几个根据额外任务定)。 - 等待时间为
2秒(第3、4参数):针对于非核心线程,若是非核心线程任务执行完成后,会默认等待连接其他任务2秒,超时的话会默认关闭。 - 线程工厂:一般默认使用的
Executors.defaultThreadFactory()即可。 - 拒绝策略(
AbortPolicy()):对拒绝任务执行的拒绝策略。拒绝任务指的是线程池中所有的线程(核心+非核心)都有任务,并且阻塞队列都满了,此时来的线程都成为拒绝任务,会根据指定的拒绝策略来执行。

说明:对于上面ThreadPoolExecutor使用的参数,对应可能发生的大致情况如下:
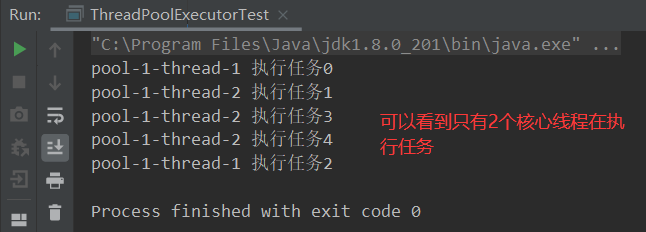
- ①当任务数为1-5时只会交由核心线程执行,其3个任务会放置在阻塞队列。
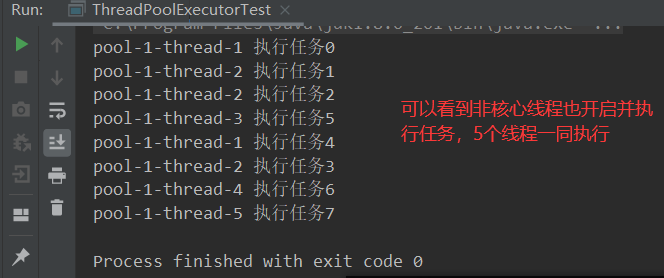
- ②当任务数为6-8时,就会开启非核心线程。
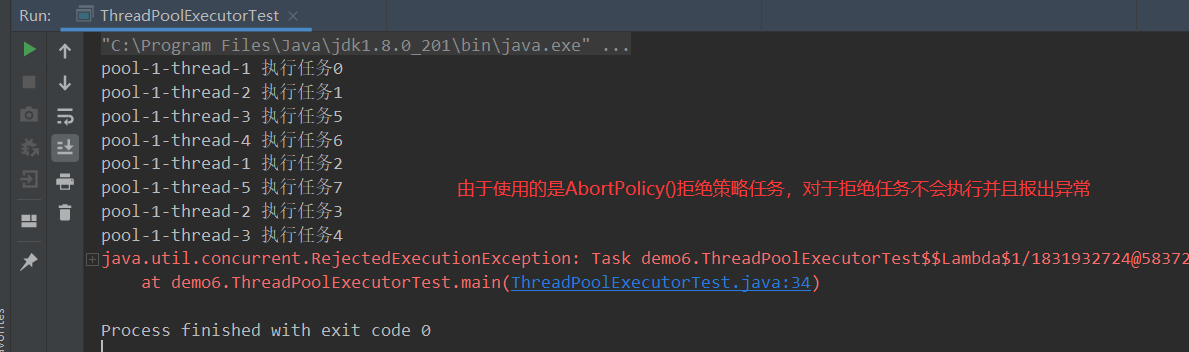
- ③当任务数为9时,即任务9为拒绝任务会根据指定的拒绝策略来处理该任务。
测试程序:主要测试不同数量的任务会使用多少个线程池中的线程
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2,//核心线程2个
5,//池中最多有5个线程
2,//保持连接2秒
TimeUnit.SECONDS,//2秒连接
new LinkedBlockingDeque<>(3));//链表阻塞队列,容量为3
try {
//测试不同数量的任务(更改5即可)情况有:5、8、9
for (int i = 0; i < 5; i++) {
int temp = i;
poolExecutor.execute(()->{
System.out.println(Thread.currentThread().getName()+" 执行任务"+temp);
});//执行线程
}
} catch (Exception e) {
e.printStackTrace();
} finally {
poolExecutor.shutdown();//关闭线程池
}
}
}
执行5个任务:
执行8个任务:
执行9个任务:
介绍四大拒绝策略
RejectedExecutionHandler是一个接口,其包含四个实现类,分别就对应着四种不同的拒绝策略(定义在ThreadPoolExecutor中),如下:
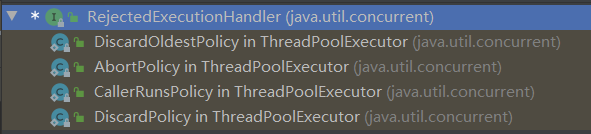
四种不同策略(针对于连接数一旦大于max线程+阻塞队列容量情况)
①new ThreadPoolExecutor.AbortPolicy():即抛出异常RejectedExecutionException,不执行超出边界的任务
②new ThreadPoolExecutor.CallerRunsPolicy():呼叫main线程执行任务
③new ThreadPoolExecutor.DiscardOldestPolicy():丢弃最旧的未处理请求,并且重试任务请求,除非执行器突然被关闭该任务才会被丢弃
④new ThreadPoolExecutor.DiscardPolicy():直接丢弃拒绝的任务
测试程序如下:主要测试四种不同策略,直接上9个任务
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2,//核心线程2个
5,//池中最多有5个线程
2,//保持连接2秒
TimeUnit.SECONDS,//2秒连接
new LinkedBlockingDeque<>(3),//链表阻塞队列,容量为3
Executors.defaultThreadFactory(),//默认的线程工厂
new ThreadPoolExecutor.DiscardPolicy());//分别来测试4种不同的拒绝策略
//测试线程
try {
for (int i = 0; i < 9; i++) {
int temp = i;
poolExecutor.execute(()->{
System.out.println(Thread.currentThread().getName()+" 执行任务"+temp);
});//执行线程
}
} catch (Exception e) {
e.printStackTrace();
} finally {
poolExecutor.shutdown();//关闭线程池
}
}
}
下面是四种不同策略的使用效果:
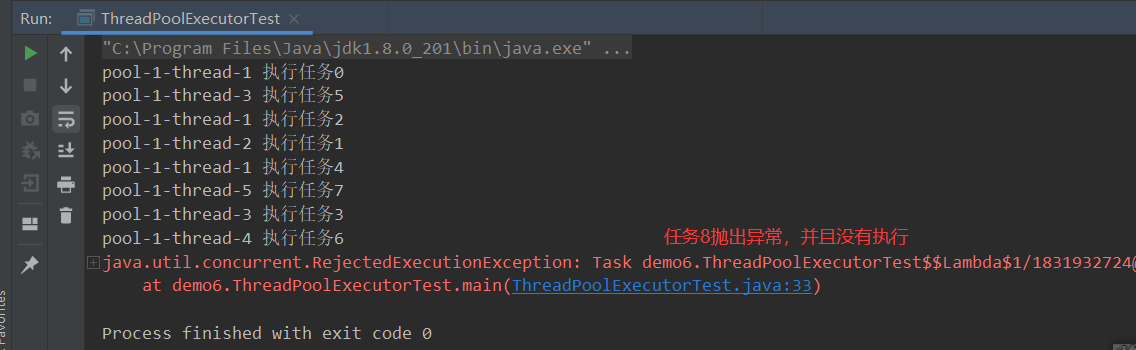
- 使用
new ThreadPoolExecutor.AbortPolicy()策略,抛出异常不执行任务。
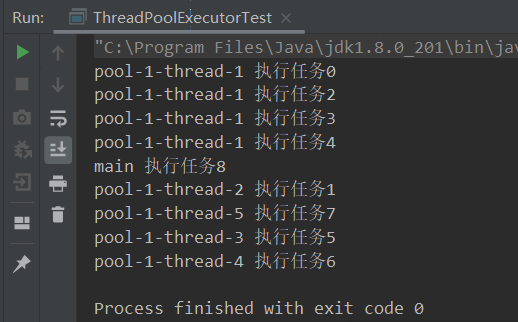
- 使用的
new ThreadPoolExecutor.CallerRunsPolicy()策略,可看到额外的任务让主线程执行。
- 使用
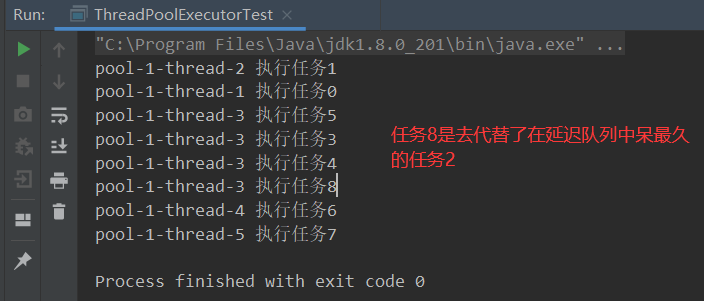
new ThreadPoolExecutor.DiscardOldestPolicy()策略,会丢弃在延迟队列中呆最旧的任务来执行拒绝策略的任务。
- 使用
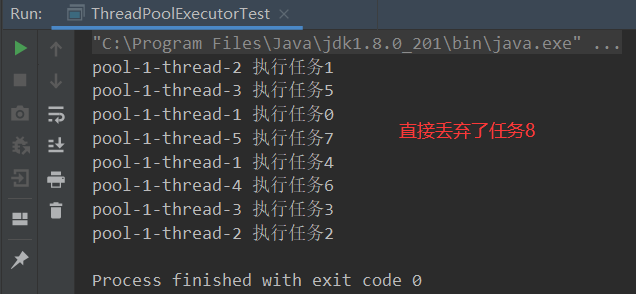
new ThreadPoolExecutor.DiscardPolicy()策略,会直接丢弃被拒绝的任务。
注意说明:有时候CPU执行的够快时对于上面9个任务的情况也不会出现拒绝任务。
十、异步操作
10.1、ForkJoin(并行计算)
认识ForkJoin
使用ForkJoin的目的:将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果。
- 与归并算法中的思想很相像,可以说是同样的思路吧。
特点:工作窃取,其中维护的是双端队列。
执行流程图:
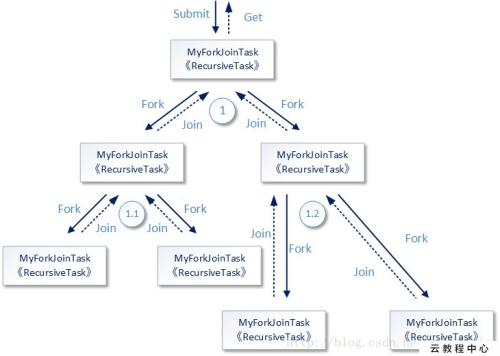
- 通过使用Fork()方法来调用其子任务,Join()方法来获取子任务运算的结果值。
- 最终使用get()来获取所有子任务运算值的合并。
下面需要使用的类:
ForkJoinPool:最终执行并行计算。RecursiveTask<v>:需要实现该抽象类,作为参数放置到ForkJoinPool的submit()中执行。ForkJoinTask:通过ForkJoinPool的get()获取最终的结果运算值。
源码分析思路
使用ForkJoin的思路:
①首先需要自定义一个类,该类继承RecursiveTask抽象类(递归任务)
public abstract class RecursiveTask<V> extends ForkJoinTask<V> {
private static final long serialVersionUID = 5232453952276485270L;
//需要去实现计算任务
protected abstract V compute();
....
}
- 该方法中可配合使用
fork()与join()核心方法来执行调用。fork():相当于递归调用计算任务。join():获取计算任务的返回值。
②接着创建ForkJoinPool实例,将之前自定义任务作为参数给到ForkJoinPool的submit()方法中,即会去执行任务。
@sun.misc.Contended
public class ForkJoinPool extends AbstractExecutorService {
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
//参数为ForkJoinTask,表示可丢入一个递归任务类,返回一个ForkJoinTask类
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task;
}
}
③通过ForkJoinPool的get()方法获取最终的值
public abstract class ForkJoinTask<V> implements Future<V>, Serializable {
//获取返回值
public final V get() throws InterruptedException, ExecutionException {
int s = (Thread.currentThread() instanceof ForkJoinWorkerThread) ?
doJoin() : externalInterruptibleAwaitDone();
Throwable ex;
if ((s &= DONE_MASK) == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL && (ex = getThrowableException()) != null)
throw new ExecutionException(ex);
return getRawResult();
}
}
获取的结果是之前自定义类时的泛型类型。
说明:大师就是大师真的设计的很精妙,暴露出一些接口方法直接让使用者把核心内容填充进去就可以提升性能高效完成任务。
示例(整数累加)
示例:demo见demo7中的
ForkJoinTest.java
通过使用ForkJoin来进行1-1000000000的相加:
- 其中的操作就是
递归+归并,与归并算法执行的过程一致只不过这里使用作求和,并且采用进行并行计算。
/**
* @ClassName ForkJoinTest
* @Author ChangLu
* @Date 2021/4/1 17:02
* @Description ForkJoin使用(工作窃取特性 , 并行处理)
*/
public class ForkJoinTest {
//继承递归任务抽象类
static class MyForkJoinTask extends RecursiveTask<Long> {
private Long start;
private Long end;
private Long temp = 10000L;
public MyForkJoinTask(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
//最终达到我们预期范围来去真正执行的操作
if (end - start < temp) {
Long sum = 0L;
for (Long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
Long middle = (start + end) / 2;
MyForkJoinTask task1 = new MyForkJoinTask(start, middle);
task1.fork();//拆解任务
MyForkJoinTask task2 = new MyForkJoinTask(middle + 1, end);
task2.fork();//拆解任务
return task1.join() + task2.join();//将拆解的两个任务相加获取返回值
}
}
}
//测试使用ForkJoin来并行归并处理任务
public static void main(String[] args) throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
//1、创建ForkJoin池
ForkJoinPool forkJoinPool = new ForkJoinPool();
//2、需要提交一个递归任务(自定义的递归任务),获取到ForkJoinTask实例
ForkJoinTask<Long> submit = forkJoinPool.submit(new MyForkJoinTask(1L, 1000000000L));
//3、获取运算结果(中途若是计算量会有阻塞情况)
Long sum = submit.get();
long end = System.currentTimeMillis();
System.out.println("时间为:" + (end - start) / 1000.0 + "秒");
System.out.println("sum=" + sum);
}
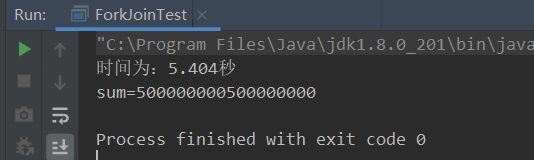
说明:forkjoin使用的是并行计算,其中实际上采用了递归+合并的内部操作,并且其中的一个线程一旦完成工作会直接帮另一个线程进行工作(工作窃取),提升性能。
我们来尝试其他两种方式来进行运算操作:
//方式一
//①普通计算(仅仅是主线程执行)
@Test
public void test01() {
long start = System.currentTimeMillis();
long sum = 0L;
for (long i = 1L; i <= 1000000000L; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println("时间为:" + (end - start) / 1000.0 + "秒");
System.out.println("sum=" + sum);
}
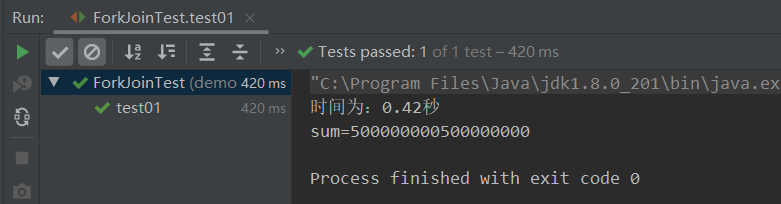
- 我去什么竟然还更快了,说明并不是什么场景都使用
Forkjoin来进行并行操作才是性能最佳的,因为使用并行操作还需要进行上下文切换,并且其中内部还有更多的细节封装,例如双端队列等等,对于一些场景能够使用并行计算会达到比较好的效果。
//方式二
//②流计算(LongStream)
@Test
public void test02(){
long start = System.currentTimeMillis();
//①获取操作(rangeClosed()):获取LongPipeline实现类。
//②中间操作(parallel()):设置该流为并行流
//③结果操作(reduce()):归约,合并操作。属性:起始值 函数式(相隔两个操作数执行的操作)
long sum = LongStream.rangeClosed(0L, 1000000000L).parallel().reduce(0, Long::sum);
long end = System.currentTimeMillis();
System.out.println("时间为:" + (end - start) / 1000.0 + "秒");
System.out.println("sum=" + sum);
}
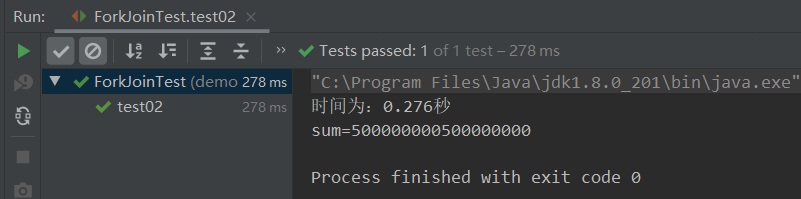
- 好家伙使用并行流计算更快了!!!一些CPU密集型流操作就适合使用流来操作。
总结:我们可以使用ForkJoin(并行计算)去优化一些实际场景,比如说优化归并排序,其好处是能够并行执行其中的一个个子任务达到提升性能的好处!千万不要什么场景都去使用ForkJoin,否则会适得其反。
10.2、CompletableFuture(异步回调)
介绍CompletableFuture
属于
java.util.concurrent并发包下的类
CompletableFuture:JDK1.8版本新引入的一个类,一个CompletableFuture就表示一个任务。其是接口Future的实现类,该类中的很多方法都使用到了JDK1.8出现的函数式接口,如Consumer、Suppiler、function、predicate。
优点介绍:首先看这名字"未来的完成"与它实际要做的事描述的很相近,使用该类能做executorService配合futures做不了,其能够获取到任务的返回值。该类执行任务可以不返回值也可以返回值可进行设置,并且可以使用then、when等等方法来预先设置碰到种种情况对应要做的事情,来防止一些事情的出现。
- 并且其中的很多方法都是返回的自己本身实例,能够进行链式方法调用!
获取无返回值或有返回值的实例方法:可以看到返回的是CompletableFuture实例
static CompletableFuture<Void> runAsync(Runnable runnable):使用runnable接口,无返回值,其泛型默认为Void,即返回值为空。static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier):使用Supplier供给型接口能够返回一个自定义类型的值.
其中的核心方法:
T get():执行初始设置的任务,并且获取返回值(该过程可能会有阻塞情况),若是无返回值默认为null。CompletableFuture<T> whenComplete(BiConsumer<? super T, ? super Throwable> action):当执行任务完成时做的操作,参数为BiConsumer接口,其中两个参数分别为返回值以及异常信息描述(若无为null)。CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn):当出现异常时执行的操作,其中参数为一个函数式接口,也是带有返回值的(你可以设置当出现异常时返回对应值)。
说明:只有get()方法调用时,任务才会去执行,上面列举的其他操作你都可以看做时做的提前准备如执行的任务、完成任务的操作、出现异常的操作,并且通过get()方法能够获取到对应任务的返回值。
示例(无返回值与有返回值)
无返回值
目的:执行任务(无返回值)并且测试其是否会让主线程进行阻塞。
程序说明:三条打印语句是用来测试其中的线程执行情况,runAsync()会创建一个带有无返回值的任务并创建一个CompletableFuture实例,get()方法被调用时会执行该实例中的方法,并获取返回值(这里为null)。
/**
* @ClassName CompletableFutureTest
* @Author ChangLu
* @Date 2021/4/3 16:54
* @Description CompletableFuture(未来完成):无返回值与有返回值示例
*/
public class CompletableFutureTest {
//无返回值示例:使用runAsync()静态方法
@Test
public void test01() throws ExecutionException, InterruptedException {
System.out.println("---1111---");
//1、调用runAsync()获取CompletableFuture实例,默认返回值为Void,即为空
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "执行....");
});
System.out.println("---2222---");
//2、get():调用时才执行其中任务,并获取到运行结果(可能出现阻塞)
future.get();//执行任务即可,无需返回值(该案例为null)
System.out.println("---3333---");
}
}
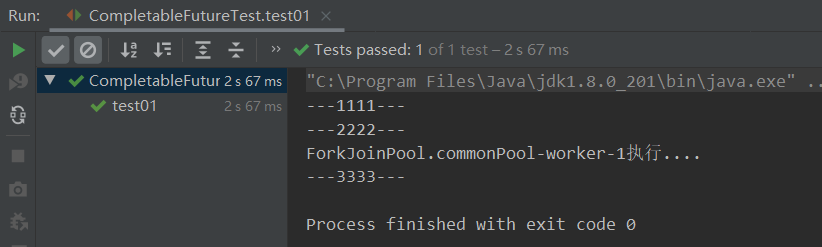
- 可以看到执行
CompletableFuture实例中的任务是由ForkJoinPool线程池中的一条线程来执行的,并且该线程执行时主线程会进行阻塞。
有返回值
目的:执行一个异步任务,当任务成功完成时返回200,任务出现异常返回404,出现异常打印异常信息。
程序说明:supplyAsync()创建一个带有返回值的任务的CompletableFuture实例,接着使用whenComplete()、exceptionally()设置在完成任务时、出现异常时做出的操作。
注意:其中13行,来模拟异常,本案例会测试两种情况。
//有返回值的异步回调CompletableFuture.supplyAsync()
@Test
public void test02() throws ExecutionException, InterruptedException {
System.out.println("---1111---");
//1、使用supplyAsync()方法可以有返回值,可自由设置范围
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"执行任务.....");
int num = 10/0;//模拟异常
return 200;//操作正常,返回200
});
System.out.println("---2222---");
//2、给执行的任务未来添加一系列的情况处理,如完成时操作,出现异常情况(可带返回值)
//①、whenComplete——当完成任务时的操作
Integer resultCode = future.whenComplete((u, v) -> {
System.out.println(u);//u:执行完成任务的返回值
System.out.println(v);//v:若无异常返回null,若有异常返回异常全限定类名+错误描述
}).exceptionally((e) -> {//②、exceptionally():抛出异常时的操作,应当有返回值
e.printStackTrace();
return 404;//表示执行有异常,返回错误码
}).get();//③、get()——执行任务,获取到最终返回值(若案例若是无异常返回200,有异常返回400)
System.out.println("获取返回值:"+resultCode);
System.out.println("---3333---");
}
情况1:无异常返回200
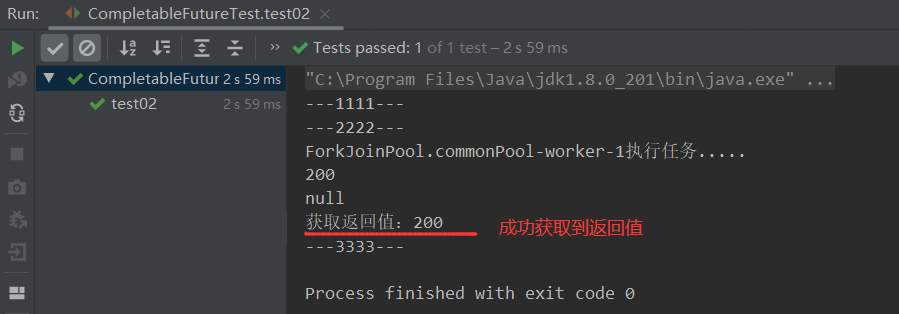
情况2:有异常返回404
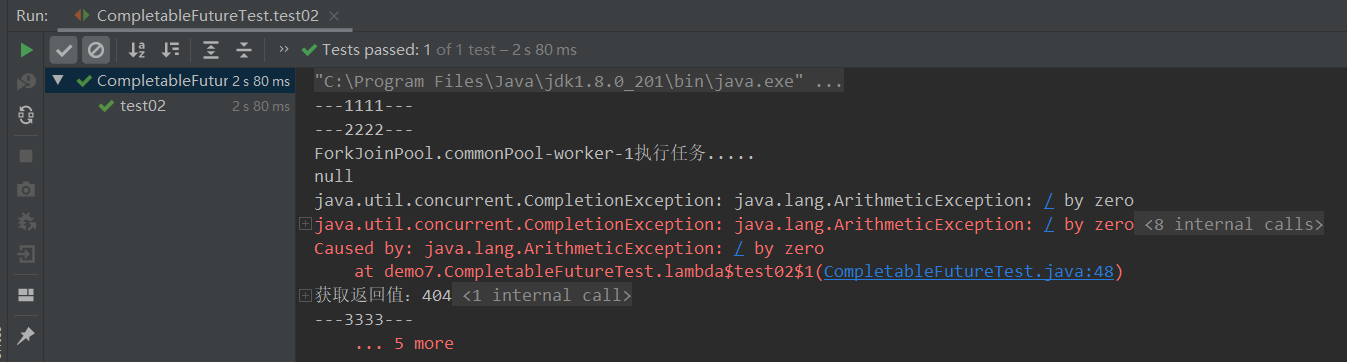
- 注意了注意了这个输出结果可以看出当执行任务时是阻塞的(主线程会进入阻塞等待),对于提前预估任务方法(如whenComplete、exceptionally)的执行线程(依旧是worker-1)与主线程能够进行互相切换执行(并不是同步)。
说明:使用CompletableFuture可以实现异步操作(执行指定任务过程是同步操作)并且可以有返回值以及可以设置一系列未来发生情况!!!
总结
1、ForkJoin用于并行计算,通过递归+合并的方式来将一个大问题分解成一个个子问题并且最终获取其值,其中使用到了fork()与join()方法来进行递归调用以及获取递归调用方法的值。针对于一些场景能够进行性能优化。
2、CompletableFuture是异步方法,通过使用runAsync()创建一个无返回值任务的实例,其实例调用get()方法时才会执行其中的任务,执行任务的线程是其他线程,并且该线程执行时主线程会进行阻塞等待。
十一、CAS
11.1、介绍与引出CAS
介绍CAS
CAS(Compare and swap,比较与交换):其是可以保证线程安全的一种较为高效的方法,要想使用CAS需要有三个数(内存地址V、旧的预期值A、更新的目标值B)。
- 当
CAS执行时,首先会获取到在内存地址V的值,接着会进行一个方法操作(若是内存地址V的值与预期值A相同,那么将内存地址V的值更改为B,否则就不做),整个过程是无限循环的。 - 注意:
比较与交换的方法操作是一个原子操作!
好处:实际调用的是native方法其调用操作系统平台的汇编指令,不用切换线程状态,提高性能,避免用锁造成的性能开销。
缺点:①循环时间开销长。②只能保证一个变量的原子操作。③ABA问题。
- 针对①:因为CAS中对于比较与交换方法通常是配合无限循环一起使用,若是CAS失败会不断进行尝试,长时间不成功会给CPU带来很大开销。
- 针对②:对于一个变量执行操作可以使用CAS来保证原子操作,若是对于多个变量则无法直接保证操作的原子性。解决方案1:使用互斥锁来保证原子性;解决方案2:将多个变量封装成对象,使用
AtomicReference保证原子性。
认识了CAS之后,我们来看看什么时候可以使用到CAS以及该如何使用?
引出CAS:demo见demo8中的
AtomicIntegerTest.java里的test01()方法
看下面的程序,创建了10个线程,分别对静态变量num执行10000次自增,预期的结果是100000:
/**
* @ClassName AtomicIntegerTest
* @Author ChangLu
* @Date 2021/4/5 16:18
* @Description TODO
*/
public class AtomicIntegerTest {
//案例一:通过i++自增复合操作来引出CAS,本案例是具有线程安全问题的
private volatile static int num = 0;
@Test
public void test01() throws InterruptedException {
Thread[] threads = new Thread[10];
//10个线程分别进行100次自增,预期结果为num=100000
for (int i = 0; i < 10; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
num++;
}
});
threads[i].start();
}
//让10个线程优先执行
for (int i = 0; i < 10; i++) {
threads[i].join();
}
System.out.println(num);//获取最终的num值
}
}
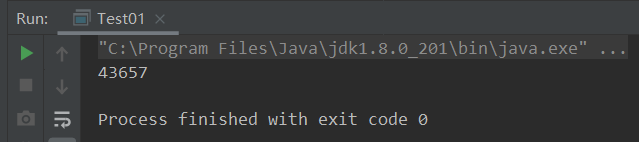
问题描述:由于num++其实是复合操作,volatile关键字修饰并不能够保证其原子性,在多线程情况下,由于这个复合操作并不原子性的,最终就会出现值与预期不符的结果!
第一种解决方法:使用synchronized或lock来对这个复合操作设置为同步,同一时间只能有一个线程来执行复合操作,但是由于线程的切换以及锁的获取即释放同样需要很大的性能开销,若是频繁使用则会降低性能!
第二种解决方法:使用CAS,本部分的主题,通过使用CAS来保证线程安全。在Java中提供了并发原子操作类java.util.concurrent.atomic,原本int的num更改为AtomicInteger的实例num1,将原本使用i++执行+1操作的改为实例num1调用getAndIncrement()方法。
11.4、原子类中的ABA问题
引出ABA问题
引出ABA问题
首先回顾一下CAS的使用流程(比较与交换):①首先从内存地址V中读出值S。②将值S与预期值A进行比对。③若是相同的话将内存地址V中的值更改为更新值B。
//Unsafe类中的CAS操作
public final class Unsafe {
//var1:原子类的实例 var2:偏移值 var4:预期值A var5:更新值B
//通过var1与var2能够获取到内存地址V中值S
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
}
而对于Unsafe类中需要set、add方法都进行了实现,中间都会有个do while循环操作
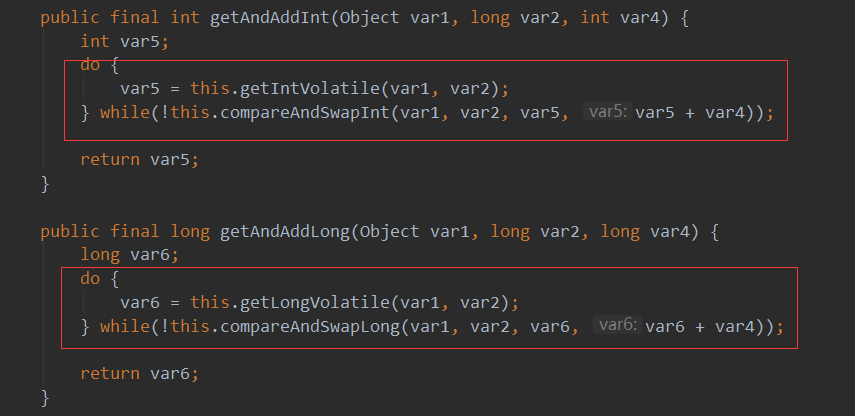
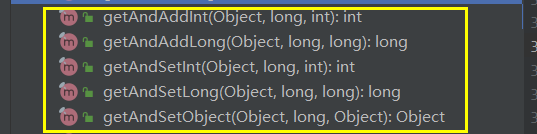
do代码体中是获取对应原子类实例中的值,获取到之后会不断的进行循环执行上面的CAS本地方法操作。- 注意注意:是先获取当前值,之后再CAS判断操作!!!
- 下面黄色框中都具有
do while循环体与上面实现类基本一致!
出现的问题描述:在执行获取了当前值之后,CPU调度到cas操作前,在这个过程中其他线程对其值进行更改接着再改回去,之后执行cas操作时会认为没有改变过。
- 这种情况除了
AtomicStampedReference类都会有这种问题,为啥这么说呢,因为Java是值传递,当出现上面这种情况,传递的引用值可能没变,但是引用对象变了(尤其是其中的值变了,我们会毫无察觉)!

解决方式:版本号机制,通过使用AtomicStampedReference,该类中会有一个Stamp作为版本号,使用该类的话每次进行更新值操作都需要手动增加版本号来防止上面的ABA问题。
问题模拟说明(问题源头)
demo见demo8中的
ABAProblemTest.java
实际模拟ABA问题的出现:

import sun.misc.Unsafe;
import java.lang.reflect.Field;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @ClassName ABAProblemTest
* @Author ChangLu
* @Date 2021/4/5 22:35
* @Description 模拟测试AtomicInteger(其他原子类)可能会出现的ABA问题
*/
public class ABAProblemTest {
//使用AtomicInteger来模拟出ABA问题
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(10);
//线程A模拟ABA问题情况
new Thread(()->{
//在线程B睡眠过程中执行交换操作
atomicInteger.compareAndSet(10,22);
atomicInteger.compareAndSet(22,10);
//ABA问题就出现在这里,当上面换完之后,引用依旧不会变,再执行下面41行时不会检测到其已经进行了更新操作
},"A").start();
//线程B进行主要核心替换操作
new Thread(()->{
do{
try {
//模拟Unsafe中的获取值
//报出异常:java.lang.SecurityException: Unsafe,无法通过自定义类来获取到该实例
Integer i = Unsafe.getUnsafe().getIntVolatile(atomicInteger,getUnsafeValueOffset());
System.out.println(i);
TimeUnit.SECONDS.sleep(4);
} catch (Exception e) {
e.printStackTrace();
}
}while (!atomicInteger.compareAndSet(10,66));//重要!经过上面的交换操作本句代码依旧会正常执行!替换为66
System.out.println(atomicInteger);
},"B").start();
}
//通过反射来获取到Unsafe类中的valueOffset值
public static long getUnsafeValueOffset() throws IllegalAccessException, NoSuchFieldException {
Field field = Unsafe.class.getDeclaredField("valueOffset");
field.setAccessible(true);
return (long) field.get(Unsafe.getUnsafe());
}
}

注意:上面代码不能够执行会报错主要理解想要表达的问题描述即可!!!
重点需要知道的一个点是:一般对应一些基本类型对应的原子包装类几乎不会产生啥影响改变不就不改变了嘛就是一个值,而对于引用类型的话就不一样了,由于Java是值传递,若是更改了其中引用对象的值,对应引用依旧不会变指的是同一个对象地址,问题来了,这时候若是直接进行cas操作会判断为同一个引用就会进行替换操作!!!
解决ABA问题(版本号机制,使用AtomicStampedReference)
前面说到对应原子引用类若是出现ABA问题的话可能会有不好的影响,如何解决呢?JDK中提供了AtomicStampedReference类,该类是一个原子标记引用类。
- 其中来通过一个标记来实时判断当前是否要进行更改操作,其为版本号机制。
demo见demo8中的
SolveABAProblemTest.java
程序描述:线程A来模拟出现ABA问题,线程B中最先获取到其中的版本号,接着睡眠来让线程A完成模拟操作,接着来测试通过使用AtomicStampedReference中的版本号来解决ABA问题:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicStampedReference;
/**
* @ClassName SolveABAProblemTest
* @Author ChangLu
* @Date 2021/4/5 23:14
* @Description 通过使用AtomicStampedReference(版本号机制),利用其标记机制来放置出现ABA问题!
*/
public class SolveABAProblemTest {
//设置泛型为Integer,参数设置初始值为1,标记为1
private static AtomicStampedReference<Integer> sr = new AtomicStampedReference<>(1,1);
public static void main(String[] args) {
//线程A模拟ABA问题
new Thread(()->{
try {
TimeUnit.SECONDS.sleep(1);//睡一秒保证线程B先获取到标记
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("标记为"+sr.getStamp());
//模拟ABA问题,从1->11 11->1
boolean b1 = sr.compareAndSet(1, 11, sr.getStamp(), sr.getStamp() + 1);
System.out.println(Thread.currentThread().getName()+"=>标记为"+sr.getStamp()+",当前值为"+sr.getReference()+","+b1);
boolean b2 = sr.compareAndSet(11, 1, sr.getStamp(), sr.getStamp() + 1);
System.out.println(Thread.currentThread().getName()+"=>标记为"+sr.getStamp()+",当前值为"+sr.getReference()+","+b1);
},"A").start();
//线程B,主要测试AtomicStampedReference通过标记是否有效解决ABA问题
new Thread(() -> {
//获取当前标记
int stamp = sr.getStamp();
//睡眠一会让线程A模拟ABA问题
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
//看一下是否能够预防ABA问题出现!注意这里的stamp使用的是之前获取到的标记号
//若是true则表示更改成功,false表示更改失败
System.out.println(sr.compareAndSet(1, 66, stamp, stamp + 1));
System.out.println(Thread.currentThread().getName()+"=>标记为"+sr.getStamp()+",值为"+sr.getReference());
}, "B").start();
}
}
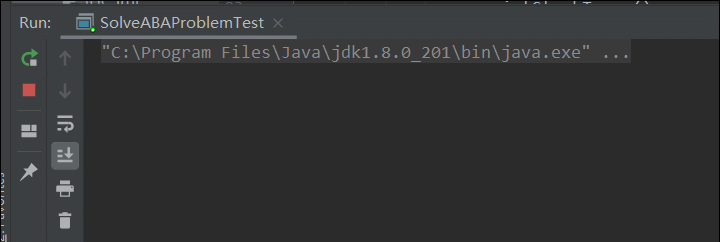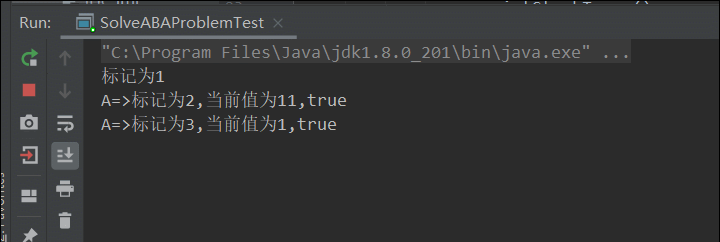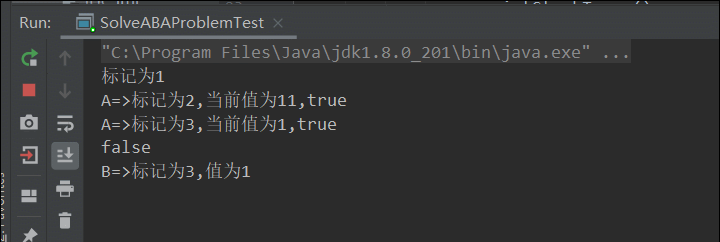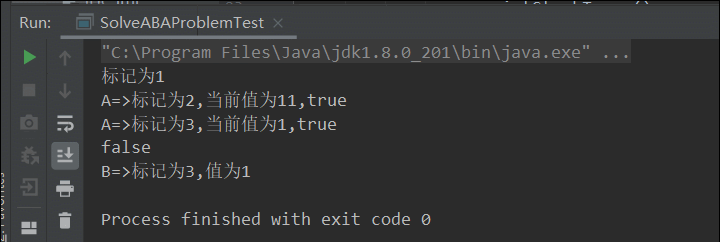
注意:一定要确保拿到版本号操作是在ABA操作之前(上面程序通过在线程A中加入睡眠保证线程B的操作),避免出现线程执行顺序的问题。
说明:我们可以通过使用AtomicStampedReference其中的版本号机制来防止ABA问题的出现!!!
总结
1、CAS的含义就是比较与交换,其是保证线程安全的一种高效方法比使用synchronzied、lock锁性能更高,因为CAS方法实际上调用的是本地C++代码,其中包含了汇编指令,主要就是保证CAS是一个原子性操作以及具有内存屏障效果(Volatile读、写的内存语义)。
2、对于一些基本类型进行自增(复合操作)对于在多线程下是不安全的,在Java中提供了一个原子包,其中包含了对应不同的原子包装类型及引用类型,将原本的自增操作更改为对应的调用方法如+1操作的getAndIncrement()方法。
- 一定要知道cas操作指定的是Unsafe类中的
compareAndSwapInt()本地方法,因为在对应的原子类中的部分方法并不是直接调的该cas方法,而是调用如下方法: 
- 这些实现方法都是先获取到对应原子类的实例,接着再进行cas操作,并且对于cas没有成功的操作会不断循环直至成功,因为其中有个do while操作,对于失败情况则会大大降低性能,也是它的一大缺点。
3、对于普通的原子类(包装类、引用类)都会有ABA问题,即在获取原子类实例后,CPU调度到cas操作前,其他线程将原子类值A改为B,B又改为A后,此时真正执行cas操作时会依旧认为是原本的引用从而进行比较与交换。
- 解决方式:使用版本号机制,即使用
AtomicStampedReference中的版本号判断,在每次进行更新操作时增加版本号值,将版本号值作为判断的依据看是否要进行比较与交换。

- 点赞
- 收藏
- 关注作者
评论(0)