MySQL学习笔记 02、MySQL基础(覆盖基本知识点)

@[toc]
前言
本篇博客是MySQL的学习笔记,若文章中出现相关问题,请指出!
所有博客文件目录索引:博客目录索引(持续更新)
一、Mysql介绍
1.1、了解Mysql
Mysql关系型数据库(开源、免费)、Oracle(收费,性能比Mysql高)
现在很多公司使用postgrepsql
物联网:时序数据库
Mysql是C/S架构的(分为服务端与客户端),服务器运行在某个电脑的指定端口,客户端在任意端口能够与服务端进行连接。连接之后即可发送数据(发送sql语句)。可以有很多客户端与服务端进行连接。
1.2、认识Socket
计算机与计算机之间就是使用socket连接的,可以将其认为是一种网路的管道。
一个计算机使用ip+端口,使用某种协议就能与另一台计算的ip+端口链接通信(TCP/UDP)
- qq发送端口使用的是TCP、直播看电视使用UDP。
1.3、查看设置变量(以及全局)
-- 1.1、查看全局变量(503)
show GLOBAL VARIABLES
-- 1.2、查看所有变量(517)
SHOW VARIABLES
-- 2.1、查看单个变量(两种方式,结果不同)
show GLOBAL VARIABLES like 'autocommit'; -- 结果:autocommit OFF
SELECT @@autocommit; -- 结果:1
-- 3.1、设置全局变量(两种方式,即其他会话连接都会修改该变量值,但是设置时其他原本就连接session的不会生效。本session要重新连接才会生效)
set @@GLOBAL.autocommit = 1
set GLOBAL autocommit = 0
-- 3.2、设置变量(只对本次session会话有效)
set autocommit = 1
注意点:设置全局变量时,其他已经进行连接的不会生效退出重新登录则会生效。若是出现还是不生效问题时,建议去修改my.ini配置文件,接着进行重启数据库。
二、SQL
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rSR6dn06-1651135172459)(https://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021-2/20210409154721.png)]
2.1、DCL(数据控制语言)
DCL(Database Control Language,数据控制语言):用来定义访问权限,能够创建用户,设置修改密码以及给用户设置权限。
修改密码:update mysql.user set authentication_string=password('root') where user='root';
查看所有的用户名与密码:select host,user,authentication_string from mysql.user;
创建用户
用户只能在指定ip地址上登陆mysql:create user 用户名@IP地址 identified by '密码'
用户只能在任意ip地址上登陆mysql:create user 用户名@'%' identified by '密码'
--示例1 创建用户名cl 密码为123456(所有ip地址都可登陆)
create user cl@'%' identified by '123456'
--示例1 创建用户名cl 密码为123456(指定ip地址:192.168.22.14)
create user cl@192.168.22.14 identified by '123456'
注意:可以创建用户名相同ip地址不同的用户。
给用户授权
语法:grant 权限1,权限2,...,权限n on 数据库.* to 用户名@ip地址。
- 若想设置全部权限可使用all代替。
-- 示例1: 给用户名cl在数据库mybatis中的所有表添加所有权限(默认为cl@'%')
grant all on mybatis.* to cl
-- 刷新MySQL的系统权限相关表,否则会出现拒绝访问或者重新启动mysql服务器,来使新设置生效
FLUSH PRIVILEGES;
撤销用户权限
语法:revoke 权限1,权限2,...,权限n on 数据库.* to 用户名@ip地址。
- 与授权仅仅只是第一个关键字不相同而已,需要注意的是撤销指定权限首先应该有该权限。
--示例1: 撤销用户名cl在数据库mybatis中的所有表所有权限(默认为cl@'%')
revoke all on mybatis.* to cl
查看指定用户的权限
语法:show grants for 用户名@ip地址,无ip地址限制的直接写用户名即可。
--示例1:查看用户cl的权限信息(默认为cl@'%')
show grants for cl
注意:若是查询出来有Useage则表示无任何权限,一般新创建的用户无任何权限!
查看所有用户
描述:所有用户信息存储在mysql数据库中的user表里;
--示例1:查询用户表中的所有用户,ip地址
use mysql;
select user,host from user;
删除指定用户
语法:DROP user 用户名@IP地址
--示例1:删除用户名为cl(ip地址为192.168.22.14)的用户
DROP user cl@192.168.22.14
--示例2:删除用户名为cl(任意ip地址)的用户
drop user cl@'%' -- 或 drop user cl
2.2、DDL(数据定义语言)重要
数据类型
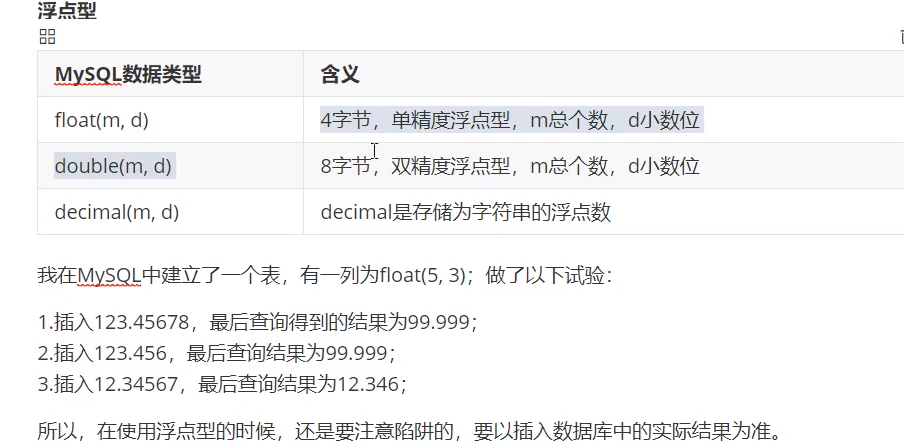
- decimal(2,1):小数会四舍五入,整数会补充小数点。
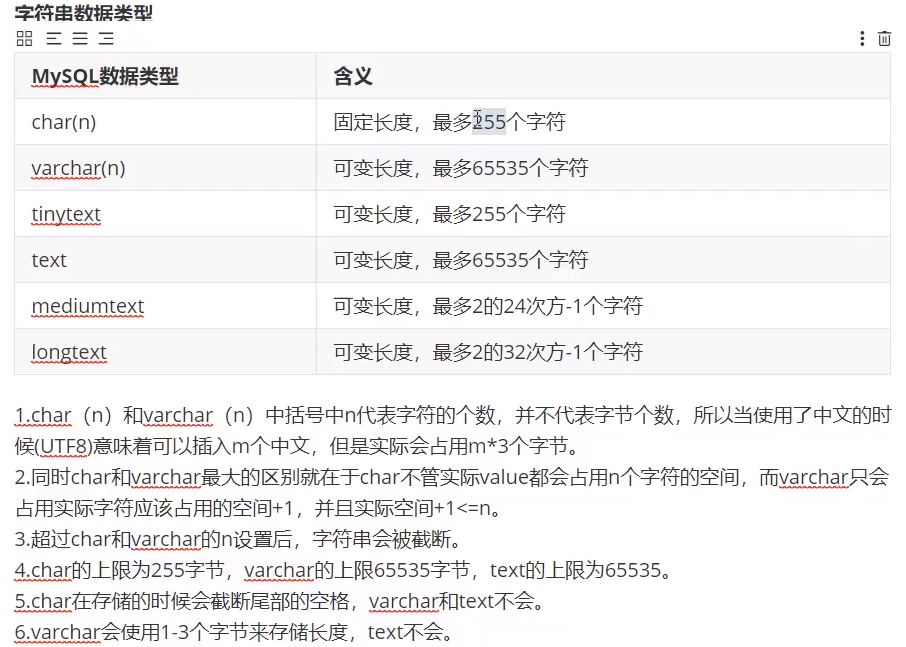
固定长度与可变长度区别:
- 例如char(200),varchar(200),你都插入15个字节,使用定长的话它依旧会给你开辟200字符空间,而使用varchar()的会根据你插入的字符来开辟指定空间。
- varchar相对于char会多存一个长度空间(1-3字节)!text不会!
- 有时候若是存储少量字符的话,由于varchar相对于char会多一个长度空间导致varchar占用空间更大。
整型最多:int、bigint
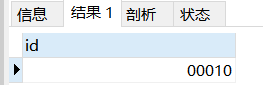
int(5)特殊用法:使用int默认为4个字节,若是在之后使用(5)表示其宽度为5,一般需要配合zerofill使用,案例如下:
create table test01(
id int(5) ZEROFILL -- 设置id字段宽度为5,并且配合0填充
);
insert into test01 values(10); -- 插入一个值10
SELECT * from test01; -- 查看结果可以看到为00010,会使用0来填充满5个宽度
字符
字符型使用最多:char、varchar、text
表的管理(增删改查)
查
查看所有数据库:show databases
使用指定数据库:use 数据库名
查看所有表(前提指定数据库):show tables
查看表结构:desc 表名
增
创建数据库(设置指定编码):create database 数据库名 default character set 编码格式。
- 编码格式如:
utf8
创建表:
-- 语法
create table 表名{
字段名1 类型(宽度) 约束条件,
字段名2 类型(宽度) 约束条件,
字段名3 类型(宽度) 约束条件,
....
}engine=引擎类型;
-- 示例(引擎默认在my.ini中设置为inndb)
CREATE TABLE IF NOT EXISTS stuinfo(
stuId INT,
stuName VARCHAR(20),
gender CHAR,
bornDate DATETIME
);
删
删除数据库:drop database 数据库名
删除表:drop table 表名;
- 若是加上判断语句为:
drop table if exists 表名;
改
修改表5个操作,前缀都为:alter table 表名 ....;
- 添加列:
alter table 表名 add (列名 列类型, .... ,列名 列类型); - 修改列类型:
alter table 表名 modify 列名 列的新类型; - 修改列名称及类型:
alter table 表名 change 原列名 新列名 列名类型; - 删除列:
alter table 表名 drop 列名 - 修改表名:
alter table 表名 rename to 新表名
建表约束
五类约束
| 约束名称 | 描述 |
|---|---|
| not null | 非空约束 |
| unique | 唯一约束,取值不允许重复 |
| primary key | 主键约束,自带(非空、唯一、索引)就是上面2个外加一个索引 |
| foreign key | 外键约束(外关键字) |
| default | 默认值(缺省值) |
| auto_increment | 自增,一般都是配合主键使用 |
实现方式:
not null:字段定义后施加。unique:①表定义最后施加,如()的最后unique(字段名1,字段名2),总体设置。②字段定义最后施加。default:字段定义后施加,如id int default 0。primary key:①表定义最后施加。②字段定义后施加。③多个字段为主键通过①方式。- 主键只能有一个,但是可以由多个字段构成联合主键。
foreign key实现:外键可以建立多个,多个外键接着写即可。
- 语法:
foreign key [column list] references [primary key table] ([column list]),可在表定义后施加。 - 产生效果:①删除表时,应当先删除引用外键的表(即其他主键表),否则被引用的表不能直接删除。②外键值必须来源于引用的表的主键字段。
举例子(遵守):test2的test1_id作为外键引用test1的id(主键)
- 插入一行数据到
test2时,这行数据中的test1_id值应当在test1中先存在才能再插入!(即插入具有外键的表时,确保对应外键值在对应主键表中有该值,否则无法插入) - 删除
test1表时,应当先删除外键引用test1变量的表test2。(删除主键表A前,应当先删除其他外键引用主键表A的表)
2.3、DML(数据操控语言)重要
说明:对表进行增删改。
增(添加记录)
插入数据:insert into 表名(列名1,列名2,列名3,...,列名4) values(列值1,列值2,列值3,...,列值4),(列值1,列值2,列值3,...,列值4)
- 插入多条数据时在第一条数据后+
,()
修改
修改某行指定列的数据:update 表名 set 列名1=列值1,列名2=列值2
删除
删除整行:delete from 表名 (where 条件)
- 一般对删除操作进行数据备份(触发器实现)
2.4、DQL(数据查询语言)
单表查询
查询表中所有数据:select * from 表名
查询表中的两个字段(取别名):select id,name as '姓名' from 表名
- 不加as也是可以设置别名的,直接加空格之后别名即可!
添加排序
升序:select id,name as '姓名' from 表名 order by id
- 默认带有asc;
降序:select id,name as '姓名' from 表名 order by id desc
多个字段进行升序或降序:select id,name as '姓名' from 表名 order by id desc,name asc,先对id进行升序,若是id有相同的情况按照name进行降序。
聚合函数:使用与select 后面的字段
count()、max()、min()、sum()、avg()
分组查询group by … having
纯分组语法:select 分组列名,聚合函数1,聚合函数2 from 表名 group by 分组列名
- 分组之后往往会根据不同组返回一条数据,比如说分数作为分组列名,30分为1组,60分为1组,select后你应当展示的是对应的分组列名或者是指定的聚合函数用于聚合对应分组的内容!
对于分组后的对应组内容可进行筛选,分组+筛选语法:select 分组列名,聚合函数1,聚合函数2 from 表名 group by 分组列名 having 聚合函数或条件
执行顺序:
select concat(year(date),':',month(date)) as ym
from date_time -- ①首先从date_time表中查询到对应所有字段
group by ym -- ②对于查询内容进行分组,可以看到这里可以使用对应字段的别名
分页语句limit:限定查询结果的起始行到指定行数
表中第一条记录从0开始
limit单个参数:select * from 表名 limit 3:从第1行开始查询3行,如123条记录。
limit两个参数:select * from 表名 limit 3,3,从第4行开始查询3行,如第456条记录。
多表查询
认识笛卡尔积
笛卡尔积:就是两个集合相乘的结果,集合A与集合B中的元素都结合在一起;

说明:通过上图我们就可以看出,若是简单的获取记录从两张表中就会有笛卡尔积的效果。表1有n1条数据,表2有n2条数据,笛卡尔积就会得到n1xn2条数据,列举出最坏的情况即所有的情况。
使用处:若是将分数表与学生表联结起来,查看对应学生的分数及学生信息,那么实际上在笛卡尔积的基础上添加一个筛选条件即可如:select * from score,student where stu_id = id;,stu_id是score表中的外键引用student表的主键id,id则表示对应的学生信息。
着重介绍下面的三个连接:内连接、外连接(左外连接、右外连接)、全连接。
额外补充:笛卡尔积来实现下面内连接的案例
建议下面几个连接案例学习完之后再回过来看,因为表与数据使用的是下面的表准备中的内容!
实际上对于笛卡尔积结果集添加筛选条件一样能够达到下面内连接案例的效果!如下:
-- 对笛卡尔积进行条件筛选
SELECT
*
FROM
student,
score
WHERE
student.id = score.stu_id;
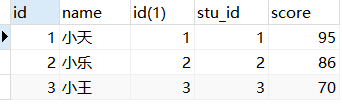
表准备(说明三种连接情况)
创建表与插入数据
/*
Navicat Premium Data Transfer
Source Server : 本地mysql5.7
Source Server Type : MySQL
Source Server Version : 50732
Source Host : localhost:3306
Source Schema : mybatis
Target Server Type : MySQL
Target Server Version : 50732
File Encoding : 65001
Date: 10/04/2021 12:07:45
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for score
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`id` int(11) NOT NULL,
`stu_id` int(11) NULL DEFAULT NULL,
`score` int(255) NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `stu_id`(`stu_id`) USING BTREE,
CONSTRAINT `stu_id` FOREIGN KEY (`stu_id`) REFERENCES `student` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of score
-- ----------------------------
INSERT INTO `score` VALUES (1, 1, 95);
INSERT INTO `score` VALUES (2, 2, 86);
INSERT INTO `score` VALUES (3, 3, 70);
INSERT INTO `score` VALUES (4, NULL, 80);
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`name` char(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '小天');
INSERT INTO `student` VALUES (2, '小乐');
INSERT INTO `student` VALUES (3, '小王');
INSERT INTO `student` VALUES (5, '小茅');
SET FOREIGN_KEY_CHECKS = 1;
表字段以及数据展示
为了更好的演示几种连接的关系(下面内连接、外连接、全连接),准备两张表来进行演示,学生表与分数表结构如下:
student表:
| 字段 | 字段类型 | 注释 |
|---|---|---|
| id | int | 学生id(主键) |
| name | char(10) | 学生姓名 |
score表:
| 字段 | 字段类型 | 注释 |
|---|---|---|
| id | int | 分数id |
| stu_id | int | 外键(引用student表的主键id) |
表数据内容如下:
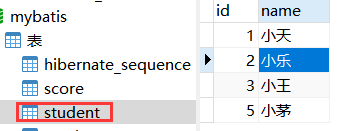
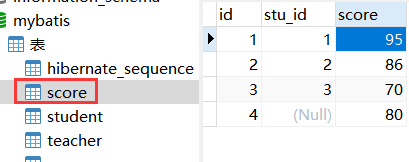
说明: 可以看到score表中的stu_id是设置了一个null,主要是等会用于展示使用不同连接的效果!
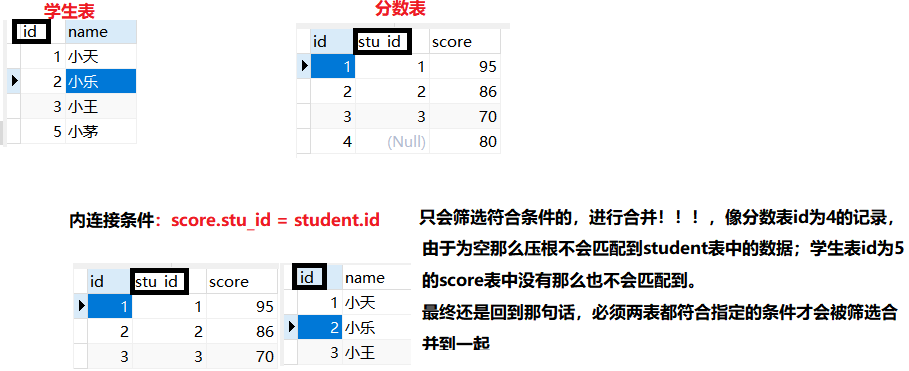
1、内连接
根据条件,找到表A和表B的数据交集。
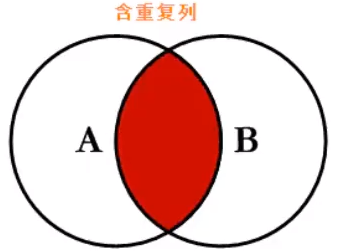
语法:select * from 表1 as 表1别名 inner join 表2 as 表2别名 on 表1.id = 表2.id
- inner join表示内连接,左右对应两张表,on表示连接的条件。
- 不同的表可以设置别名,放置后面连接条件字段相同!
案例与分析
案例:将学生表与分数表通过学生id连接起来。
-- 将student表与score表通过学生id来连接起来
SELECT
*
FROM
student stu
INNER JOIN score AS s ON stu.id = s.stu_id
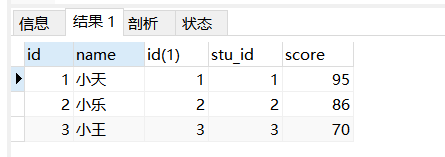
分析:
一定要抓住内连接的特点,两表的交集(根据指定条件,找出都符合的记录)。知道了要点过后我们来分析一下其中如何进行的内连接操作!
2、外连接(左外连接、右外连接)
实际上仅仅在语法上内、左、右仅仅就是一个关键字的不同分别对应inner join、left join、right join。
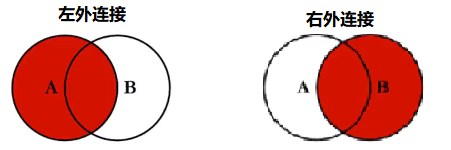
语法:
- 左外连接:
select * from 表1 as 表1别名 left join 表2 as 表2别名 on 表1.id = 表2.id - 右外连接:
select * from 表1 as 表1别名 right join 表2 as 表2别名 on 表1.id = 表2.id
案例及分析
目标:筛选student表与score表中字段相同的记录,通过左连接、右连接
左外连接示例:
-- 学生表在左,分数表在右,那么就取决于学生表进行左外连接
SELECT
*
FROM
student stu
left JOIN score AS s ON stu.id = s.stu_id
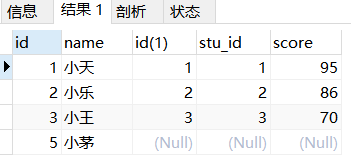
分析:啥是左外连接?就是先确定左边的表,确定筛选的字段,接着左边的所有记录都会去尝试匹配右边表的记录根据连接的字段。

问题:主表左连接其他表若是关联多条记录时,也会将额外匹配到的记录添加
user表:
zhong表:
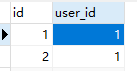
查询结果:匹配到的也会作为查询结果拿到
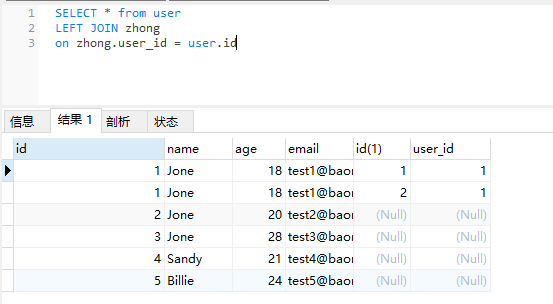
右外连接示例:
-- 右外连接的话,右边的为主表,左边的为次表,简单来说就是使用左连接将两个表换一下而已(主表是score表,右表是student表)
SELECT
*
FROM
student stu
right JOIN score AS s ON stu.id = s.stu_id
分析:经过上面左外连接的分析,右外连接也不在话下,无非不就是把右表(score表)的所有记录根据对应的筛选条件来去尝试匹配左表(student)的记录嘛,匹配不到使用null来填充!
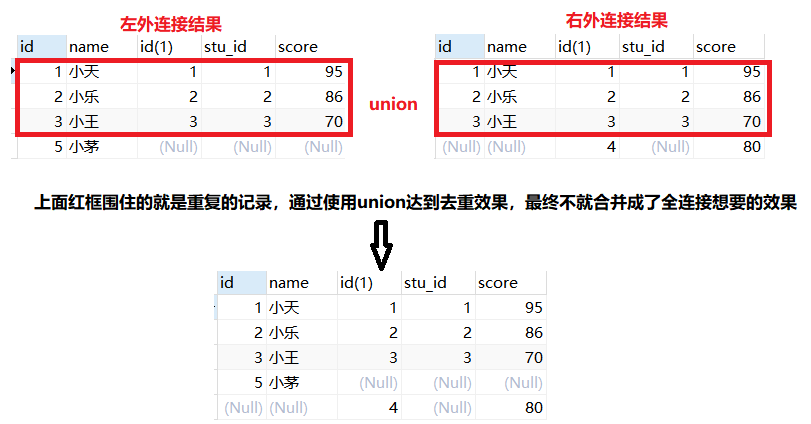
3、全连接(mysql不支持、oracle支持)
在mysql中没有对应的关键字full join,oracle数据库是支持全外连接的,啥是全外连接呢?看下图:
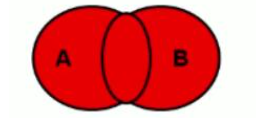
- 实际上就是可以看成左外连接添加了右外连接获得的null指定记录(即匹配不到左表);右外连接添加了左外连接获得的null指定记录(即匹配不到右表)
mysql中实现全连接:既然没有提供对应的关键字来实现全连接,那么如何手动实现呢,其实可以通过union关键字
-- 左外连接(student主表,score次表)
SELECT
*
FROM
student stu
left JOIN score AS s ON stu.id = s.stu_id
UNION
-- 右外连接(student次表,score主表)
SELECT
*
FROM
student stu
right JOIN score AS s ON stu.id = s.stu_id
思路:就是将左外连接的查询结果与右外连接的查询结果通过union联结起来。
union all:去自动去重(重复的记录会去除)union:不会过滤重复记录。
实际分析:
注意点
对于多表进行外连接操作时,
left join与on要成对出现:
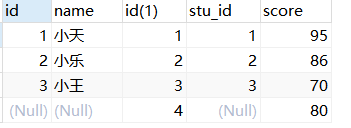
实例:查询1号学生的姓名、指定的成绩以及对应的课程名。
SELECT
stu.NAME '姓名',
s.score '分数',
c.`name` '课程名' -- ④对筛选之后的B表对应字段进行输出
FROM
student stu
LEFT JOIN score s ON stu.id = s.stu_id -- ①学生表左连接成绩表(形成A表)
LEFT JOIN course c ON s.cur_id = c.id -- ②A表左连接课程表(形成B表)
WHERE
stu.id = 1 -- ③对B表进行条件筛选操作
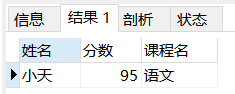
分析:①学生与对应成绩关联需要有学生表、成绩表(根据学生id),接着若想要知道对应课程名,②那就需要再关联一张课程表(根据筛选出的成绩表中的课程id)。
- 进行了两个外连接,注意其中的left join都是成对出现,每次进行外连接时都是拿之前连接好的表进行的!
组合查询(union或union all)
union与union all区别:union在合并时对于重复的行也会合并进来,而union all会将字段都相同的重复行去除掉。
规范:多个查询返回的结果列数应该一致,并且类型应该能够兼容。
子查询
子查询说明:将一个查询的结果作为条件给另一个查询语句使用则叫做子查询。
where型子查询
两种类型:
where 列=(内存sql):则该内层sql返回的必须是单行单列,单个值。where 列 in (内层sql):则内层sql返回的必须是单列,可以多行。
from型子查询
说明:查询结果集在结构上可以当成表看,其可以当成临时表对它进行再次查询。
语法:... from (包裹sql查询语句)
case…when…then(判断字段的值来显示指定的值)
语法:
# 更新
update table
set 字段1=case
when 条件1 then 值1
when 条件2 then 值2
else 值3
end
where ……
# 查询
select 字段1, 字段2,
case 字段3
when 值1 then 新值
when 值2 then 新值
end as 重新命名字段3的名字
from table
where ……
order by ……
实操:
准备语句:
CREATE TABLE `course` (
`id` int,
`sid` int ,
`course` char(10),
`score` int
)
# 字段解释:id, 学号, 课程, 成绩
INSERT INTO course VALUES (1, 1, 'yuwen', 43);
INSERT INTO course VALUES (2, 1, 'shuxue', 55);
INSERT INTO course VALUES (3, 2, 'yuwen', 77);
INSERT INTO course VALUES (4, 2, 'shuxue', 88);
INSERT INTO course VALUES (5, 3, 'yuwen', 98);
INSERT INTO course VALUES (6, 3, 'shuxue', 65);
实际案例:
# 字段名在when后进行判断
# 当id字段的值为1时,修改为666,并且别名设置为id1
SELECT *,case
when c.id = 1 then 666
end as id1
from course as c
# 字段名在case后
# 当id字段的值为1时,修改为766;为2时,修改为788,并且别名设置为id1
SELECT
TBL.*,
CASE
TBL.id
WHEN 1 THEN
766
WHEN 2 THEN
788
END AS id1;
FROM
course TBL
三、常用函数
使用函数返回的都是单行值!函数包含聚合函数、日期函数、字符串处理函数等。
一般用于select语句、条件表达式。
3.1、聚合函数
count(col):统计查询结果行数。
min(col):查询指定列的最小值。
max(col):查询指定列的最大值。
sum(col):返回指定列的总和。
avg(col):返回指定列的平均值。
3.2、数值型函数
数值型函数主要针对于数字、浮点型的函数,下面前四个
ceiling(x):返回大于x的最小整数值(浮点数),向上取整。
floor(x):返回小于x的最大整数值(浮点数),向下取整。
round(x):浮点型进行四舍五入为整数。
round(x,y):返回参数x(浮点型)的四舍五入为y位小数的值。
truncate(x,y):返回数字x截短为y位小数的结果,直接截断。
pi():返回pi的值(圆周率)。
rand():返回0-1内的随机值。(原理是通过提供的一个参数种子来随机生成一个指定的值)
3.3、字符串函数
字符串函数主要处理字符串
length(s):返回字符串的字节长度。
concat(s1,s2,...,sn):合并字符串,返回结果为连接参数产生的字符串,参数可为单个或多个。
lower(s):将字符串中字母转换为小写。
upper(s):将字符串中字母转换为大写。
left(s,x):返回字符串str最左边的x个字符。
right(s,x):返回字符串str最右边的x个字符。
trim(s):将字符串s两侧的空格去除。
ltrim与rtrim:一个是去除左边空格,另一个是去除右边空格。
replace(s,'_',''):第一个参数是想要进行操作的字符串s,将字符串s中的第二个参数全部调换为第三个参数。
- 实际案例:
replace(uuid(),'_','')将uuid自动生成的字符串中的_字符全部取消。- 默认
uuid()产生36位,如d40ea56d-99cc-11eb-a92a-9828a640b46f,将其中的_都替换为’'空字符串,就变为32位了。
- 默认
substring(s,from,to):截取字符串s中的第from个位置开始的to个。从第1位开始的。
- 例如:
SELECT SUBSTR('123456',2,2)取到值为23。
reverse(s):反转字符串s的结果。
3.4、日期与时间函数
默认数据库中存储的日期格式为:2021-04-10 15:38:02
在MySQL中使用where来进行判断日期并不严格其中可以自动格式转换,例如以下:
- 相等比较:
where '2021-04-10 15:38:02' = '2021:04:10 15:38:02',返回的是true。 - 大于比较:
where createdate = '2021:04:10 15:38:02',也都是可以进行比较的! - 还有相减也是可以的!
生成日期函数
返回系统的日期时间:
- 系统的日期值:
curdate()或current_date(),效果如:2021-04-10。 - 系统的时间值:
curtime()或current_time(),效果如:15:36:22。 - 系统的日期与时间值:
now()或sysdate(),效果如:2021-04-10 15:37:21。
获取时间戳以及日期转换:
-- 1、获取unix时间戳
select UNIX_TIMESTAMP() -- 1618040282
-- 2、①将unix时间戳转换为日期+时间
SELECT FROM_UNIXTIME(1618040282) -- 2021-04-10 15:38:02
-- 2、②将unix时间戳转换为指定格式的日期+时间
SELECT FROM_UNIXTIME(1618040282,'%Y:%m:%d %H:%i:%S') -- 2021:04:10 15:38:02
-- 3、将日期时间转换为unix时间戳
SELECT UNIX_TIMESTAMP('2021-04-10 15:38:02') -- 1618040282
- 对应转换格式参数可见:FROM_UNIXTIME 格式化MYSQL时间戳函数
对数据库中的日期进行处理获取
注意:对于指定的日志格式没有特殊要求,测试2021-04-10 15:38:02、2021:04:10 15:38:02都能使用
返回指定英文名:
monthname(d):返回指定日期月份的英文名。dayname(d):返回指定日期星期几的英文名。如:Saturday
返回日期中的指定内容(常用):
year(d):返回指定日期的年。month(d):返回指定日期的月份。day(d):返回指定日期在该月中的第几天。hour(d):返回指定日期在该月中的第几个小时。minute(d):返回指定日期在该月中的第几分钟。microsecond(d):返回指定日期在该月中的第几微秒。
返回日期中分别对应年、月、周的第几天以及第几周:
dayofyear():返回指定日期对应一年中的第几天。dayofmonth():返回指定日期对应一月中的第几天。dayofweek():返回指定日期对应一周的索引位置。week():返回指定日期是一年中第几周,范围为0-52或0-53。
添加、减去指定时间
增加指定时间:年月天分秒
- 语法:
DATE_ADD(date,INTERVAL expr unit)
-- 加1年
SELECT DATE_ADD('2021:04:10 15:38:02',INTERVAL 1 year) -- 2022-04-10 15:38:02
-- 加1月
SELECT DATE_ADD('2021:04:10 15:38:02',INTERVAL 1 month) -- 2021-05-10 15:38:02
-- 加1天
SELECT DATE_ADD('2021:04:10 15:38:02',INTERVAL 1 DAY) -- 2021-04-11 15:38:02
-- 加1分
SELECT DATE_ADD('2021:04:10 15:38:02',INTERVAL 1 MINUTE) -- 2021-04-10 15:39:02
-- 加1秒
SELECT DATE_ADD('2021:04:10 15:38:02',INTERVAL 1 SECOND) -- 2021-04-10 15:38:03
两个日期相减天数:SELECT DATEDIFF(now(),'2021-04-08 15:38:02')
- 参数1-参数2,返回值是相差的天数!
3.5、md5函数(哈希算法)
认识hash算法
hash算法(散列算法)的本质是将一个文件、字符、数字通过复杂的算法转换成一个定长的字符串。
- 只能加密,不能退回(不可逆),一般登陆密码放在数据库都是使用的md5加密。
- 说明:可能123、321都使用md5加密获得同一个哈希值,这叫哈希碰撞(取余算法碰撞几率很大)。优秀的哈希算法发生碰撞的概率极低,基本上不发生碰撞,但不是完全不可能。微小的变化就能使结果发生巨大变化
md5函数使用
使用md5函数能够生成一个定长32位的字符串
SELECT MD5(123) -- 202cb962ac59075b964b07152d234b70
提出疑问1:对于普通的账号将123、123456作为密码使用md5这种哈希算法得到的值由于是定长那不就很容易破解嘛,虽说是不可逆,但是别人将一些简单密码进行加密一下再一比对你数据库中的加密值不就能很容易破解了嘛:?
- 回答:对于上面的疑问,确实若是简单使用123作为密码进行哈希算法的话就很容易能够被破解,所以说一般注册账号就会让你将密码难度设置高一些尽量使用
数字+英文+特殊字符组成的密码!
提出疑问2:虽说是这么讲的,但若是用户还是设置123作为密码,通过怎样的方式能够提高一些安全防范呢?
-
回答:既然用户设置很简单的密码,那我们我们就要做出一些行动了,例如用户名为长路,密码是123,则在前端或后端,对于密码设置为
"用户名"+123+随机生成字符串组合进行md5加密,那么破解难度就会大幅度提升。此时就能够达到提升安全性的需求了,对于随机生成的字符串额外在表中设置一个salt字段用户保存(加盐加密)。 -
-- 列举组合加密(仅作演示) SELECT MD5('长路'+123+uuid()) -
登陆如何校验?前端对登陆密码与用户名发送到后台,后台取出对应用户salt字段值以及密码(加密后的),将传过来的组合密码与salt字段合并再进行md5加密与数据库中密码比对即可!
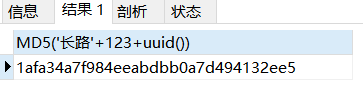
总结:实际上加密方式手段有很多,前端在传输密码过来时可以先进行md5加密,传输到后台实际上也可以再进行加密,根据对应的需求来定。
3.6、uuid函数
用途:也可以使用uuid()生成的字符串作为主键id。
uuid():实现生成唯一值的功能,得到的随机值由五个部分组成,且分隔符使用-分隔,定长36位。
- 前三组值是时间戳换算过来的;
- 第四组值是暂时性保持时间戳的唯一性。例如,使用夏令时;
- 第五组值是一个IEE 802的节点标识值,它是空间上唯一的。若后者不可用,则用一个随机数字替换。假如主机没有网卡,或者我们不知道如何在某系统下获得机器地址,则空间唯一性就不能得到保证,即使这杨,出现重复值的机率还是非常小的。
对比自增序列(约束字段)区别:UUID是随机+规则组合而成的(固定36个字符),而自增序列是控制一个值逐步增长(整数类型值,长度由字段属性决定)。
使用一下:
-- 1、获取完整的uuid(36位)
SELECT uuid() -- 9891c083-9a12-11eb-a92a-9828a640b46f
-- 2、通常将其中的-去除掉,则为32位了
SELECT REPLACE(uuid(),'-','') -- c190c71b9a1211eba92a9828a640b46f
额外说明:UUID()函数产生的值,并不适合作为InnoDB引擎表的主键。可见MySQL UUID函数的详解
3.7、group_concat
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
一般来说我们进行分组查询时,首个字段为指定分组的字段,之后的对应字段应该为单个值,若是我们想要根据name作为分组字段并且几种查询到对应name的id值呢?我们就可以使用到group_concat将对应name组的id进行拼接成字符串返回!
示例:我们根据name分组
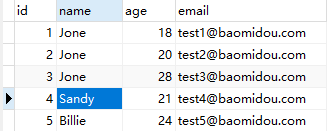
①若是不使用group_concat
SELECT name,id FROM `user` GROUP BY `name`
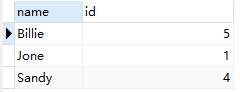
我们可以看到对应Jone的id只会返回第一个!
②使用group_concat
SELECT name,GROUP_CONCAT(id) FROM `user` GROUP BY `name`
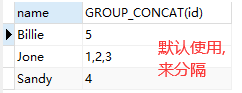
通过这种方式我们能够对应name的所有id,查询出来之后可以对字符串进行分割操作了。
-- 对id进行降序并且设置分割符号_
SELECT name,GROUP_CONCAT(id ORDER BY id DESC SEPARATOR '_') FROM `user` GROUP BY `name`
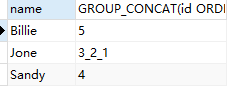
四、其他函数
普通判断语句
应用程序业务逻辑也可以转交给数据库后台。
1、if(test,t1,t2):如果test成立返回t1,不成立返回t2。
-
示例:查询成绩表中及格与不及格的学生。
-
-- 通过在字段中来使用if进行判断筛选 SELECT stu_id as 学号,if(score>=60,'及格','不及格') as 成绩 FROM score
-
2、ifnull(arg1,arg2):如果arg1为空,返回arg2;不为空返回arg1。
-
示例:从订单表中获取订单时间,若是订单时间为空返回当前时间。
-
-- 对创建时间进行使用 select id,create_date,ifnull(create_date,now()) from sale_order
-
-
应用场景:例如原本订单价格,没有填写就使用默认的,若是想要有促销直接填写即可!
3、nullif(arg1,arg2):如果arg1=arg2,则返回null;不等返回arg1。
- 使用场景也不多。
case…when…then(解决行转列问题)
简单case函数:CASE [col_name] WHEN [value1] THEN [result1]…ELSE [default] END
- col_name取到值可以给后面的语句字段使用,若是when成立返回result1,不成立返回default。
行转列问题提出与解决 示例:SQL语句 实现数据库表中的行转列查询
-- sql文件用于创建表与插入数据
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tb
-- ----------------------------
DROP TABLE IF EXISTS `tb`;
CREATE TABLE `tb` (
`name` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`sub` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`result` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of tb
-- ----------------------------
INSERT INTO `tb` VALUES ('张三', '语文', '98');
INSERT INTO `tb` VALUES ('张三', '数学', '114');
INSERT INTO `tb` VALUES ('李四', '语文', '102');
INSERT INTO `tb` VALUES ('李四', '数学', '108');
INSERT INTO `tb` VALUES ('王五', '语文', '112');
INSERT INTO `tb` VALUES ('王五', '数学', '118');
INSERT INTO `tb` VALUES ('张三', '物理', '101');
INSERT INTO `tb` VALUES ('李四', '物理', '98');
INSERT INTO `tb` VALUES ('王五', '物理', '88');
SET FOREIGN_KEY_CHECKS = 1;
问题描述:首先我们有一张成绩表,其中包含姓名、课程、成绩三个字段,如何将其每行中的字段内容转为列中字段内容。

实现方式:通过使用group by进行分组 ,接着对分组后的内容使用 case ... when ... then ...else ... end进行赋值最后使用聚合函数获取到对应想要的数值。
SELECT
name '姓名',
max(CASE sub WHEN sub='语文' THEN result ELSE -1 END) '语文',
max(CASE sub WHEN sub='数学' THEN result ELSE -1 END) '数学',
max(CASE sub WHEN sub='物理' THEN result ELSE -1 END) '物理'
from tb
GROUP BY name;
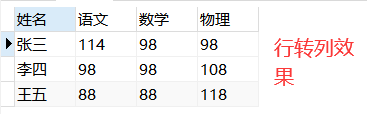
分析:
首先进行group by分组为如下:
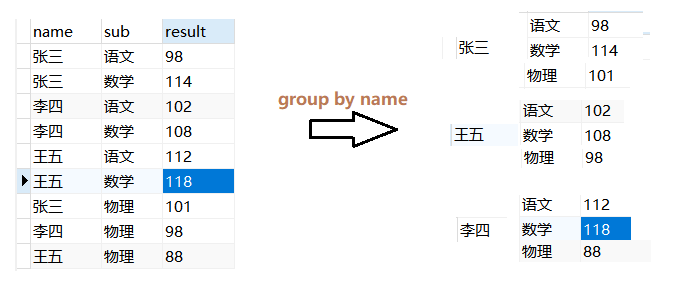
接下来来分析一下张三如何获取到最终结果一行,其他成员也就都能够知晓了:

下面是分析张三组语文分数行转列的过程:

其他对应科目也都是通过该种方式来进行行转列的!!!
五、mysql5新支持
5.1、视图
认识视图
视图描述
简而言之:将sql语句(视图)存储到磁盘上,能够直接使用该视图简化一些复杂的sql语句。
- 注意存储的只是sql语句,而不是对应查询数据。
- 视图是动态的,根据对应设置视图相关联的表的变化而变化。
应用场景:和其他公司合作,把一部分数据提供出去,一般不会直接把查看表的权限给它们,而是创建一个视图给它让他看某些信息而不是全部信息。
视图操作
1、创建视图(增)
语法:create view 视图名(字段1,字段2,...,字段n) as select语句,创建好之后就可以把其当做一个只读的表来进行查询了。
- 其中字段1,字段2就是使用后面select语句查询的后结果的列名!
示例:
-- 视图名为user_view,查询结果集列名为id号、用户名(注意不需要引号)
CREATE VIEW user_view(id号,用户名)
as
SELECT id,`username` FROM user;
注意:视图名后面()里的字段不需要’'号,否则会报错!
2、显示视图(查)
语法:show create view 视图名
显示信息如下:

3、删除视图(删)
语法:drop view 视图名
4、使用视图(查询)
语法:select * from 视图名,直接将对应视图当做表来使用。
实际案例
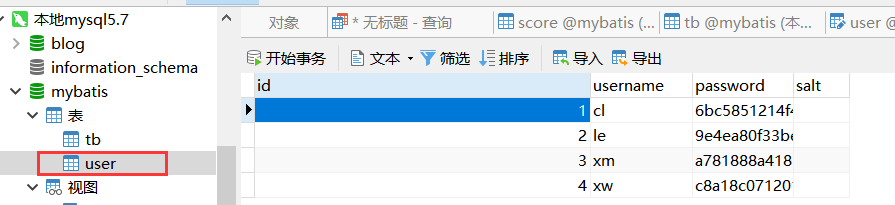
案例描述:你是部门A的,此时部门B与你们合作想要查看你们mybatis数据库中的user用户表信息,如何在保护数据库中信息的情况下将有效的信息给到部门B。
解决方案:通过使用root用户创建一个用户X(用于部门B登陆),接着在mybatis数据库针对于user表创建一个视图,给用户X赋予查看视图的权限。接着将该用户名与密码交由部门B即可进行登陆查看信息。
过程如下:
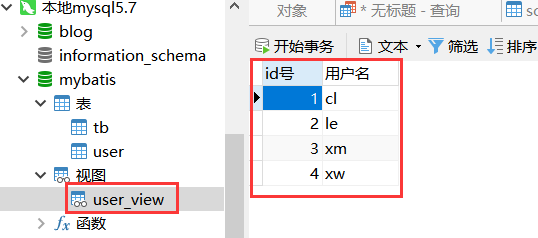
①首先创建一个视图user_view
-- 该视图仅有id号以及用户名信息
CREATE VIEW user_view(id号,用户名)
as
SELECT id,`username` FROM user;
②创建用户,赋予该视图查看权限
-- 创建一个用户名为cl(任意ip地址来连接服务器),密码是123
create user cl@'%' IDENTIFIED by '123'
-- 赋予权限(查看视图user_view)
GRANT all on mybatis.user_view to cl -- cl默认就是cl@'%'
有了权限之后,我们使用这个账号进行连接一下:
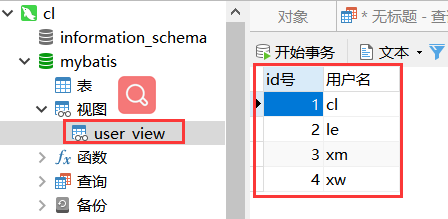
说明:可以看到cl账号在mybatis数据库中仅仅只有该视图!
六、原理分析
group by
学习文章:MySQL对group by原理和理解
分为两种情况:
①根据一个字段进行分组
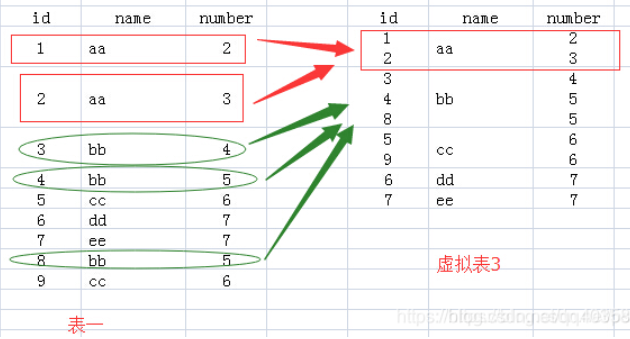
②根据两个字段(name与number)进行分组

说明:根据两个字段分组的话name、number对应一个组合为一组,例如aa 2、aa 3各为一组,与1个字段分组也是有差别的。
编写sql巧记
对应左连接可能会出现null的情况,去除null情况,可以使用:where 表别名.字段 is not null
不同案例
1、学生名、分数、课程相关联的使用三张表。(思路:对于关联三张表的通过使用多次左连接)
2、针对于学生中找指定课程成绩>多少的学生信息。(思路:从分数表中筛选出指定课程以及该课程成绩>多少的学生id,接着使用学生表使用in来找出对应学生)
查询语句与索引最重要!!!
企业里写的sql很长,一般都是存储过程,都有50-60行,存储过程暂时不是重点,一般到单位可以学习使用。
在阿里归约中,许多电商项目是不能够使用存储过程的,传统企业老项目许多逻辑都写在存储过程中。
1、count(0),count(1),count(*),count(字段)都是统计有多少行,count(*)性能还行。
2、group by分组之后 select后边的列必须是分组的条件,只能少不能多,一般使用聚合函数。having 是过滤分组之后每个组的信息,where是过滤初始查询表的条件。
3、子查询一般效率比连接低,能用左连接就不用子查询。
4、select 除了测试,正式环境不写*,一般将每个字段都写上。
5、企业的真实数据库一般比较大,1G以上很多,有些企业光数据库中都有几百张表,一张表中的数据可能上千上万条,像淘宝一晚上订单记录都有几百万、千万,可能后天表记录都有上亿、百亿。想想淘宝有多少人用。上亿条就要动用大数据了,而不使用数据库。mysql几百万、几千万条数据就顶不住了(5、6百万条数据还顶得住),oracle好一点。
6、主键一般采用自动递增,uuid()也可以,但是效率低,特别是让它当主键,不适合。
参考文章
[1]. MySQL对group by原理和理解 group by一个字段即两个字段原理都有比较好的解释说明
[2]. MySQL UUID函数的详解 包含uuid与自增约束的区别,以及对应uuid组成函数
up by
学习文章:MySQL对group by原理和理解
分为两种情况:
①根据一个字段进行分组
[外链图片转存中…(img-8sE9V61y-1651135172471)]
②根据两个字段(name与number)进行分组
[外链图片转存中…(img-Fkx3KMCX-1651135172472)]
说明:根据两个字段分组的话name、number对应一个组合为一组,例如aa 2、aa 3各为一组,与1个字段分组也是有差别的。
编写sql巧记
对应左连接可能会出现null的情况,去除null情况,可以使用:where 表别名.字段 is not null
不同案例
1、学生名、分数、课程相关联的使用三张表。(思路:对于关联三张表的通过使用多次左连接)
2、针对于学生中找指定课程成绩>多少的学生信息。(思路:从分数表中筛选出指定课程以及该课程成绩>多少的学生id,接着使用学生表使用in来找出对应学生)
查询语句与索引最重要!!!
企业里写的sql很长,一般都是存储过程,都有50-60行,存储过程暂时不是重点,一般到单位可以学习使用。
在阿里归约中,许多电商项目是不能够使用存储过程的,传统企业老项目许多逻辑都写在存储过程中。
1、count(0),count(1),count(*),count(字段)都是统计有多少行,count(*)性能还行。
2、group by分组之后 select后边的列必须是分组的条件,只能少不能多,一般使用聚合函数。having 是过滤分组之后每个组的信息,where是过滤初始查询表的条件。
3、子查询一般效率比连接低,能用左连接就不用子查询。
4、select 除了测试,正式环境不写*,一般将每个字段都写上。
5、企业的真实数据库一般比较大,1G以上很多,有些企业光数据库中都有几百张表,一张表中的数据可能上千上万条,像淘宝一晚上订单记录都有几百万、千万,可能后天表记录都有上亿、百亿。想想淘宝有多少人用。上亿条就要动用大数据了,而不使用数据库。mysql几百万、几千万条数据就顶不住了(5、6百万条数据还顶得住),oracle好一点。
6、主键一般采用自动递增,uuid()也可以,但是效率低,特别是让它当主键,不适合。
参考文章
[1]. MySQL对group by原理和理解 group by一个字段即两个字段原理都有比较好的解释说明
[2]. MySQL UUID函数的详解 包含uuid与自增约束的区别,以及对应uuid组成函数
[3]. SQL语句 实现数据库表中的行转列查询

- 点赞
- 收藏
- 关注作者
评论(0)