哈夫曼树原理及Java编码实现

@[toc]
前言
所有博客文件目录索引:博客目录索引(持续更新)
源代码:Gitee—Huffman.java、Github—Huffman.java
一、哈夫曼树原理
对于哈夫曼树的构造以及权值计算原理知识点推荐看这个视频:哈夫曼树和哈夫曼编码—bilibili
哈夫曼编码有两个特点:
- 带权路径长度WPL最短且唯一;【核心减少编码的操作】
- 编码互不为前缀(一个编码不是另一个编码的开头)【可进行还原用途】。
应用场景:压缩文件。
公式:路径长度:WPL = l1× w1+l2× w2 +…+ ln × wn,w表示权值,n表示叶子节点个数。
哈夫曼编码是如何进行应用的呢,有什么具体的示例呢?
哈夫曼树是一颗二叉树,其是根据元素的权重来进行构成的一棵树,在树上的每个节点val都使用0或1来进行表示。
- 这个权重指的是该元素出现的次数频率,频率越高的就在越上层。
就像下面一样,可以说每个元素值所对应的路径都是唯一的:

3:00000
5:00001
11:0001
前者是值,后者即为路径,就是从上到下的路径合并。
问题来了为什么要构成构造成一个哈夫曼树?尤其是为什么要根据权重来进行排列分布呢?
首先解决后面一个问题:若是在一组数据中,有10个不同的字符,字符a出现了1000次,其他字符出现的数量很少,我们是否可以根据出现的次数来对这些字符来进行编码,a用1表示,b字符用01…d字符使用0003表示,那么1000次a仅仅只需要1000个字符即可,是不是大大减少了存储空间?这也就是我们为什么要根据权重进行排列分布。
此时可以来说明前面一个问题:因为哈夫曼树是带权路径长度最短的树,权值较大的节点离根节点较近。而带权路径长度是指:树中所有的叶子节点的权值乘上其到根节点的路径长度,这与最终的哈夫曼编码总长度成正比关系的。
核心操作:一旦哈夫曼树构建出来之后,我们可以得到每个字符与其路径,那么我们根据这个hash表即可进行字符串编码,而由于每个路径都是唯一的,我们同样也可依靠hash表来进行解码!
二、哈夫曼编码(Java题解)
编码思路过程:
encode编码:构造哈夫曼树 -> 获取字符及路径map -> 根据map去构建指定编码
1、构造哈夫曼树:
准备条件:自定义树节点(字符、val、权重,其中val为之后路径组成的值)
过程:①准备一个map来统计所有字符出现次数即权重。②根据权重进行排序。③遍历map来构建树节点,接着根据权重排序,存储到一个链表节点中。④遍历链表节点每次取出两个构成一个虚拟节点,之后再找前缀最小的进行重复合并,视角是从底之上进行合并构建。
2、获取字符及路径map:递归过程,核心路径重点就是叶子节点,在哈夫曼树里有效字符节点都是叶子节点。
3、根据map中的字符与对应匹配的路径来进行对所有源字符遍历编码。
decode解码:根据map来进行前缀匹配(由于每个字符的路径唯一),即可进行还原字符
Java题解:
package com.changlu.tree;
import java.util.Collections;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.Map;
/**
* @Description: 哈夫曼树
* @Author: changlu
* @Date: 8:09 PM
*/
//哈夫曼树节点
class TreeNode {
public Character ch;
public int val;
public int freq;
public TreeNode left;
public TreeNode right;
public TreeNode(){}
public TreeNode(Character ch, int val, int freq, TreeNode left, TreeNode right) {
this.ch = ch;
this.val = val;
this.freq = freq;
this.left = left;
this.right = right;
}
}
public class Huffman {
/**
* 解码
* @param encodeStr 已编码字符串
* @param encodeMap 编码map集合
* @return
*/
public static String decode (String encodeStr, Map<Character, String> encodeMap) {
StringBuilder decodeStr = new StringBuilder();
while (encodeStr.length() > 0) {
//遍历所有编码map对应的value(也就是编码路径)
for (Map.Entry<Character, String> entry : encodeMap.entrySet()) {
String charEncode = entry.getValue();
//匹配路径前缀
if (encodeStr.startsWith(charEncode)) {
decodeStr.append(entry.getKey());
//删除该前缀
encodeStr = encodeStr.substring(charEncode.length());
break;
}
}
}
return decodeStr.toString();
}
//编码
//0:编码后的字符串
//1:对应哈弗曼树中字符的路径表示
public static Object[] encode(String s) {
Object[] res = new Object[2];
//编码字符串
//1、构建哈夫曼树
TreeNode rootNode = constructTree(s);
//2、根据哈夫曼树找到所有的路径并存储到map中
Map<Character, String> encodeMap = new HashMap<>();
findPath(rootNode, encodeMap, new StringBuilder());//存储所有字符、编码路径到map中
//此时 字符:路径编码 已经再encodeMap中存储了,我们即可来进行编码
StringBuilder sb = new StringBuilder();
for (int i = 0; i < s.length(); i++) {
sb.append(encodeMap.get(s.charAt(i)));
}
res[0] = sb.toString();
res[1] = encodeMap;
return res;
}
/**
* 寻找到哈夫曼树中所有字符的路径,并存储到map中
* @param root 哈夫曼树的根节点
* @param encodeMap 编码map
* @param path 存储路径
*/
private static void findPath(TreeNode root, Map<Character, String> encodeMap, StringBuilder path) {
//每个元素的终点就是n0节点
if (root.left == null || root.right == null) {
path.append(root.val);
//为什么要从第1位开始呢?因为完全可以再少一位0,这样也能减少不少字符
encodeMap.put(root.ch, path.substring(1));
path.deleteCharAt(path.length() - 1);
return;
}
path.append(root.val);
//递归左右
if (root.left != null) findPath(root.left, encodeMap, path);
if (root.right != null) findPath(root.right, encodeMap, path);
//删除所有最后一个字符
path.deleteCharAt(path.length() - 1);
}
/**
* 构造哈夫曼树
* @param s
* @return
*/
private static TreeNode constructTree(String s) {
//1、统计每个字符出现的权重
Map<Character, Integer> cntMap = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
cntMap.put(s.charAt(i), cntMap.getOrDefault(s.charAt(i), 1));
}
//2、将所有的字符构建成TreeNode节点存储到LinkedList中
LinkedList<TreeNode> nodelist = new LinkedList<>();
for (Map.Entry<Character, Integer> entry : cntMap.entrySet()) {
Character ch = entry.getKey();//字符
Integer freq = entry.getValue();//频率
int val = 0;//节点值
nodelist.add(new TreeNode(ch, val, freq, null, null));
}
//3、根据频率来进行排序
Collections.sort(nodelist, (node1, node2)->node1.freq - node2.freq);
//4、构建哈夫曼树
//处理只有一个节点的情况
if (nodelist.size() == 1) {
//1个节点也要有父节点
TreeNode treeNode = nodelist.get(0);
return new TreeNode(null, 0, treeNode.freq, treeNode, null);
}
//开始构建哈夫曼树
TreeNode root = null;
while (nodelist.size() > 0) {
//取出头部两个节点
TreeNode t1 = nodelist.removeFirst();
TreeNode t2 = nodelist.removeFirst();
//左右子树节点来进行分别赋值0,1
t1.val = 0;
t2.val = 1;
//若是当前节点中没有节点了
if (nodelist.size() == 0) {
root = new TreeNode(null, 0, t1.freq + t2.freq, t1, t2);
}else {
//首先构建成一个虚拟节点
TreeNode combineNode = new TreeNode(null, 0, t1.freq + t2.freq, t1, t2);
//将虚拟节点插入到链表中,同样需要维护其有序性
//暴力法【实际这里可用二分来进行】
if (combineNode.freq > nodelist.getLast().freq) {
nodelist.addLast(combineNode);
}else {
//遍历找到权重>该合并节点的权重
for (int i = 0; i < nodelist.size(); i++) {
if (nodelist.get(i).freq >= combineNode.freq) {
nodelist.add(i, combineNode);
break;
}
}
}
}
}
return root;
}
}
测试代码:
public class Huffman {
public static void main(String[] args) {
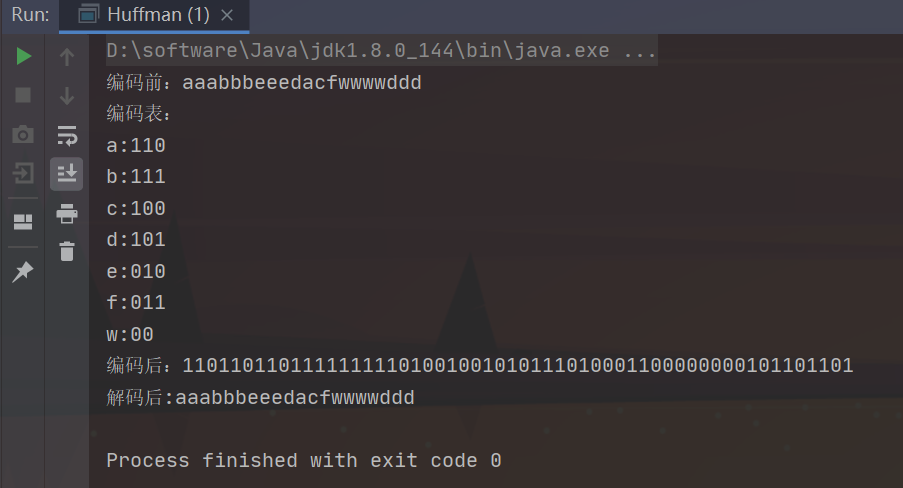
String s = "aaabbbeeedacfwwwwddd";
System.out.println("编码前:" + s);
//编码API
Object[] encodeRes = encode(s);
String encodeStr = (String) encodeRes[0];
Map<Character, String> encodeMap = (Map<Character, String>) encodeRes[1];
System.out.println("编码表:");
for (Map.Entry<Character, String> e : encodeMap.entrySet()) {
System.out.println(e.getKey() + ":" + e.getValue());
}
System.out.println("编码后:" + encodeStr);
//解码API
String decodeStr = decode(encodeStr, encodeMap);
System.out.println("解码后:" + decodeStr);
}
}
参考资料
[2]. 哈夫曼编码细解& Java 实现
[3]. 视频:哈夫曼树和哈夫曼编码
[4]. 【JAVA】KMP算法保姆级教程

- 点赞
- 收藏
- 关注作者
评论(0)