Java学习笔记 09、IO流—对象序列化

@[toc]
前言
去年四月份大一下半学期正式开始学习Java,一路从java基础、数据库、jdbc、javaweb、ssm以及Springboot,其中也学习了一段时间数据结构。
在javaweb期间做了图书商城项目、ssm阶段做了权限管理项目,springboot学了之后手痒去b站看视频做了个个人博客项目(已部署到服务器,正在备案中)。期间也不断进行做笔记,总结,但是越学到后面越感觉有点虚,觉得自己基础还有欠缺。
之后一段时间我会重新回顾java基础、学习一些设计模式,学习多线程并发之类,以及接触一些jvm的相关知识,越学到后面越会感觉到基础的重要性,之后也会以博客形式输出学习的内容。
现在整理的java知识基础点是在之前学习尚硅谷java课程的笔记基础之上加工汇总,部分图片会引用尚硅谷或网络上搜集或自己画,在重新回顾的过程中也在不断进行查漏补缺,尽可能将之前困惑的点都解决,让自己更上一层楼吧。
博客目录索引:博客目录索引(持续更新)
一、认识序列化
保存程序中的数据方式有哪些呢?
保存当前状态及信息方式:
- 展开方式:若是程序需要存储状态,可以将每个对象的单个变量写入到特定格式的文件中,之后再读取文件读取其中变量值并还原。
- 序列化:使用面对对象方式来做,将对象本身"冻干、碾平、保存、脱水",之后再"重组、展开、恢复、泡开"。
使用方式根据情境来选择:
- 若是只有自己写的java程序会用到这些数据:那么选择
序列化方式,注意序列化文件正常打开内容是无意义的。- 好处:程序更容易恢复,一般人不知道如何更改其中内容,比较安全;但是很难让人阅读。
- 若是数据还需要其他程序引用:
将数据按格式保存到纯文本文件,例如tab字符分割写到文件中去,方便其他程序或电子表格或数据库应用程序能够应用。- 好处:方便阅读;但这种存储肯定是按一定规则顺序,很容易被修改,不太安全。
介绍序列化
介绍序列化:
Java的输入、输出API中带有连接类型的串流,它表示将来源与目的地之间的连接,连接串流将其他串流连接起来。初始连接的串流是很低层的,用来读取写入字节,例如FileOutputStream为例,若我们想要将对对象以串流的形式保存那么就需要高级一点的流例如ObjectOutputStreatm,
- Java中提供了各种形式的流,方便开发人员进行选择传输。
二、实现序列化
1、实现序列化要求及说明
实现Serializable接口,并且定义一个private的serialVersionUID。
Serializable接口目的是让声明实现它的类是可以被序列化的,实现序列化的类其子类也可以自动进行序列化。- ①若是不实现该接口是不能被序列化的,执行期一定会出问题;②若是实现该接口而不定义
serialVersionUID,那么很有可能在序列化回来时出现问题。你不定义serialVersionUID系统会自动给你一个默认生成的UID,但是可能会因编译器不同而不同的类会出现问题,也有可能你修改了类的部分结构之后解序列化也会有问题。 - 默认情况下,基本数据类型可序列化。
- 序列化对象中的实例对象(也就是属性)也应该是实现序列化的,否则会有问题!!!
static静态变量不会被序列化,当对象还原时,静态变量会维持类中原来的样子,而不是存储的样子。
2、实例程序
自定义类准备
首先准备好一些自定义类方便等会进行对象序列化存储与恢复
class Dog{
}
class Cat implements Serializable{
private static final long serialVersionUID = -6848894470770667710L;
private String name = "喵喵";
@Override
public String toString() {
return "Cat{" +
"name='" + name + '\'' +
'}';
}
}
class Person implements Serializable {
//Dog类无序列化 可设置transient修饰符在序列化时跳过
private transient Dog dog = new Dog();
private Cat cat = new Cat();
//
private static String str = "123456";
@Override
public String toString() {
return "Person{" +
"dog=" + dog +
", cat=" + cat +
", str='" + str + '\'' +
'}';
}
}
- 9行的
serialVersionUID:可去其他实现Serializable的类中去拿到修改其中一点值即可。 transient:在进行序列化的时候会跳过此变量,解序列化时基本数据类型为默认值,对象实例为null。- 30行
static:静态变量不会被序列化,在类中独此一份,解序列化时还是原值。
①序列化对象
其中new的类是上面声明的
import org.junit.Test;
import java.io.*;
public class Main {
//序列化对象到文件
@Test
public void test01(){
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream("changlu.data"));
//将对象序列化写入
oos.writeObject(new Person());
oos.writeObject(new Cat());
} catch (IOException e) {
e.printStackTrace();
}finally {
if(oos != null){
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
执行之后,工程下会自动生成changlu.data文件!
②解序列化
import org.junit.Test;
import java.io.*;
public class Main {
//读取序列化对象
@Test
public void test02(){
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream("changlu.data"));
//读取序列化对象时应当与存储顺序相同
Person person = (Person) ois.readObject();
Cat cat = (Cat) ois.readObject();
System.out.println(person);
System.out.println(cat);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}finally {
if(ois != null){
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
这里唯一需要注意的是在解序列化过程中拿对象顺序应该与当时存储的顺序相同!!!
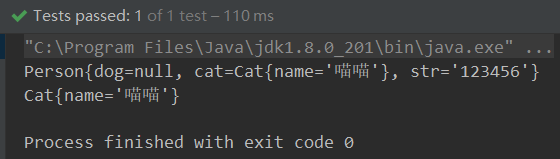
三、深入了解序列化
序列化过程
序列化对象的状态以及要保存什么?
若是对象被序列化时,不仅仅是该对象引用的实例变量、被对象的实例变量引用的对象都会被实例化,这些操作都是自动执行的。
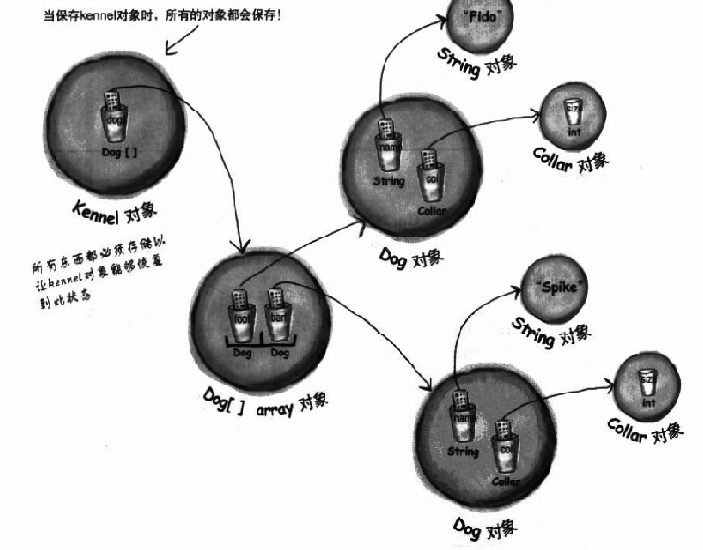
具体过程如下:
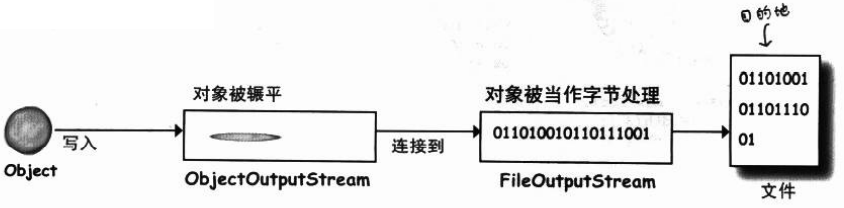
对象被序列化发生事情:①在堆上的对象②被序列化的对象
- 堆上对象:有状态并包含实例变量的值,这些值让同一类的不同实例有不同的意义。
- 序列化对象:保存了实例变量的值,因此之后可以在堆上带回一模一样的实例。
解序列化过程
过程如下:
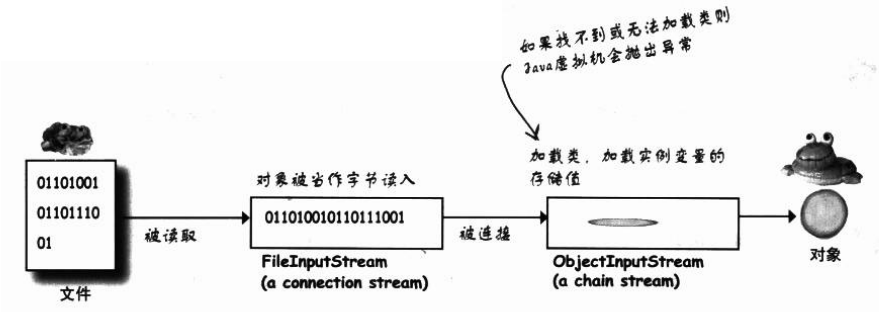
- 首先对象从stream中读出来
- Java虚拟机通过存储的信息判断对象的class类型。
- Java虚拟机尝试寻找和加载对象的类。如果Java虚拟机找不到或无法加载该类,Java虚拟机会抛出异常
- 新的对象会配置到堆上,其构造函数不会执行!设想一下如果执行对象状态会抹去,我们需要的是对象回到存储时的状态!!!
- 若对象的继承树上有无可序列化的祖先类,则该不可序列化类及以上类都会执行构造函数(以上若是实现序列化也没用),也就是说从上的第一个不可序列化父类开始全都会回到初始状态。
transient修饰的对象引用会变为null,基本数据类型会变为默认值如0,false等;不被transient修饰的回复到默认值。
四、序列化相关问题
共有四个相关问题
1.若是我要序列化自定义类,其是序列化的,但其类中的实例类并没有被序列化,那还可以序列化成功吗?
import java.io.*;
class Person implements Serializable {
//Dog类无序列化
private Dog dog = new Dog();
}
class Dog{
}
public class Main {
public static void main(String[] args) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("changlu.ser"));
oos.writeObject(new Person());
}
}

很明显若是将序列化对象其实例类若不是被序列化,执行期间会出现异常!
- 针对于上面例子,若是我存储的序列化类中,我想让某些变量不进行序列化,如何做到?
使用transient(瞬时)修饰符来表示在序列化程序中跳过该变量。无论该实例是否是序列化的都跳过,不进行序列化存储。在恢复对象时,transient修饰的对象会以null返回。
import java.io.*;
class Dog{
}
class Person implements Serializable {
//Dog类无序列化 跳过无序列化的Dog实例
private transient Dog dog = new Dog();
//跳过支持序列化的String
private transient String str = "123456";
}
那么问题来了,为什么有些变量不能被序列化呢?
- ①可能是设计者忘记实现
Serializable接口。 - ②或者是对于一些动态数据只有在执行期创建才有意义。
针对于transient修饰的变量在回复时的状态,如上第10行str本身是赋予值的,但由于使用transient的引用实例变量会以null返回,不会管存储当时它的值是什么!那么我们针对这种情况如何解决这个恢复为null呢?
- 方案1:序列化返回时,可以重新赋予其变量值,因为既然打上了
transient修饰,说明这个值并无是很重要,重新赋值也无关紧要。 - 方案2:若是其
transient修饰的值真的很重要,那么在进行序列化保存前先保存下来,之后回复时重新赋值。
- 若是两个对象都有引用实例变量指向相同的对象会怎么样,例如两个Cat指向同一个Owner,Owner会被序列化存储两次吗?
序列化聪明得足以分辨两个对象是否相同,别担心这种情况下也只有一个对象会被存储,其他引用会复原成指向该对象。
- 序列化过程中为什么类不会存储成对象的一部分,这样就不会出现找不到类的问题了?
这样设计会非常浪费空间并有很多额外的工作,针对于对象序列化本机硬盘上并不是困难的事情,但序列化也有将对象送到网络联机上的用途,这样会造成带宽的消耗大。
网络传输序列化:有一种机制可以让类使用URL来指定位置,该机制使用在Java的Remote Method Invocation(RMI,远程程序调用机制),可以把序列化对象当做参数来传递,即使接收此调用的java虚拟机没有这个类的话,也可以自动使用URL来取回并加载该类。
参考资料
[1]. 书籍《head first java 2.0》
[2]. 尚硅谷Java基础教程-宋红康主讲-IO流之序列化
[3]. JAVA中流的flush()方法

- 点赞
- 收藏
- 关注作者
评论(0)