第五届中国法研杯 LAIC2022 司法人工智能挑战赛 【犯罪事实实体识别】

一、第五届中国法研杯 LAIC2022 司法人工智能挑战赛 【犯罪事实实体识别】
比赛地址: http://data.court.gov.cn/pages/laic.html
1.任务介绍
本赛道由中国司法大数据研究院承办。
犯罪事实实体识别是司法NLP应用中的一项核心基础任务,能为多种下游场景所复用,是案件特征提取、类案推荐等众多NLP任务的重要基础工具。本赛题要求选手使用模型抽取出犯罪事实中相关预定义实体。
与传统的实体抽取不同,犯罪事实中的实体具有领域性强、分布不均衡等特性。
数据集下载请访问比赛主页。该数据只可用于该比赛,未经允许禁止在其他领域中使用。
2.数据介绍
- (1) 本赛题数据来源于危险驾驶罪的犯罪事实,分为有标注样本和无标注样本,供选手选择使用;
- (2) 数据格式:训练集数据每一行表示为一个样本,context表示犯罪事实,entities表示实体对应的标签(label)及其位置信息(span);entities_text表示每个标签label对应的实体内容;
- (3) 两条标注样本之间以换行符为分割;
- (4) 训练集:有标注训练样本:200条(分初赛、复赛两次提供,数据集包括验证集,不再单独提供验证集,由选手自己切分);无标注样本10000条;
- (5) 标注样本示例:
{"datasetid": "2552", "id": "813087", "context": "经审理查明,2014年4月12日下午,被告人郑某某酒后驾驶二轮摩托车由永定县凤城镇往仙师乡方向行驶过程中,与郑某甲驾驶的小轿车相碰刮,造成交通事故。经福建南方司法鉴定中心司法鉴定,事发时被告人郑某某血样中检出乙醇,乙醇含量为193.27mg/100ml血。经永定县公安局交通管理大队责任认定,被告人郑某某及被害人郑某甲均负事故的同等责任。案发后,被告人郑某某与被害人郑某甲已达成民事赔偿协议并已履行,被告人郑某某的行为已得到被害人郑某甲的谅解。另查明,被告人郑某某的机动车驾驶证E证已于2014年2月6日到期,且未在合理期限内办理相应续期手续。", "entities": [{"label": "11341", "span": ["25;27"]}, {"label": "11339", "span": ["29;34"]}, {"label": "11344", "span": ["54;57", "156;159", "183;186", "215;218"]}, {"label": "11345", "span": ["60;63"]}, {"label": "11342", "span": ["34;47"]}, {"label": "11348", "span": ["164;168"]}], "entities_text": {"11341": ["酒后"], "11339": ["二轮摩托车"], "11344": ["郑某甲", "郑某甲", "郑某甲", "郑某甲"], "11345": ["小轿车"], "11342": ["由永定县凤城镇往仙师乡方向"], "11348": ["同等责任"]}}
3.数据说明
针对本次任务,我们会提供包含案件情节描述的陈述文本,选手需要识别出文本中的关键信息实体,并按照规定格式返回结果。
提供的文件为json格式,字典包含字段为:
id:案例中句子的唯一标识符。context:句子内容,抽取文书中事实描述部分。entities:句子所包含的实体列表。label:实体标签名称。span:实体在context中的起止位置。- text: 标签匹配的内容。
其中label的十种实体类型分别为:
| label | 含义 |
|---|---|
| 11339 | 被告人交通工具 |
| 11340 | 被告人交通工具情况及行驶情况 |
| 11341 | 被告人违规情况 |
| 11342 | 行为地点 |
| 11343 | 搭载人姓名 |
| 11344 | 其他事件参与人 |
| 11345 | 参与人交通工具 |
| 11346 | 参与人交通工具情况及行驶情况 |
| 11347 | 参与人违规情况 |
| 11348 | 被告人责任认定 |
| 11349 | 参与人责任认定 |
| 11350 | 被告人行为总结 |
4.评价方式
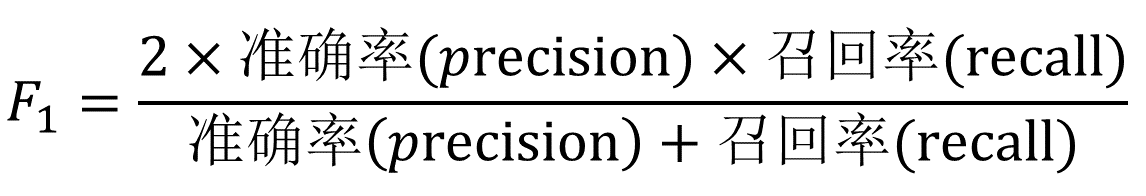
其中:精确率(precision):识别出正确的实体数/识别出的实体数,召回率(recall):识别出正确的实体数 / 样本的实体数
二、数据处理
1.解压缩数据
!unzip -qoa data/data172937/1666064694810.zip
2.查看无标注数据
# 查看无标注数据
!head 无标注数据集/危险驾驶罪-样本标签集-2000
# 查看无标注数据
!head 无标注数据集/危险驾驶罪-样本标签集-8000
3.查看标注数据
!head 选手数据集/train.json
4.数据读取
# 升级paddlenlp
!pip -q install -U paddlenlp
[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
parl 1.4.1 requires pyzmq==18.1.1, but you have pyzmq 23.2.1 which is incompatible.[0m[31m
[0m
5.实体类型
aa={'11339': '被告人交通工具',
'11340': '被告人行驶情况',
'11341': '被告人违规情况',
'11342': '行为地点',
'11343': '搭载人姓名',
'11344': '其他事件参与人',
'11345': '参与人交通工具',
'11346': '参与人行驶情况',
'11347': '参与人违规情况',
'11348': '被告人责任认定',
'11349': '参与人责任认定',
'11350': '被告人行为总结',
}
print(aa.keys())
dict_keys(['11339', '11340', '11341', '11342', '11343', '11344', '11345', '11346', '11347', '11348', '11349', '11350'])
print(aa)
{'11339': '被告人交通工具', '11340': '被告人行驶情况', '11341': '被告人违规情况', '11342': '行为地点', '11343': '搭载人姓名', '11344': '其他事件参与人', '11345': '参与人交通工具', '11346': '参与人行驶情况', '11347': '参与人违规情况', '11348': '被告人责任认定', '11349': '参与人责任认定', '11350': '被告人行为总结'}
print(aa['11339'])
被告人交通工具
values = list(aa.values())
keys=list(aa.keys())
idx = values.index("被告人交通工具")
# print(idx)
# print(keys)
key = keys[idx]
print(key)
11339
6.数据集格式转换
参考: [https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie#45-定制模型一键预测[(https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie#45-定制模型一键预测)
推荐使用数据标注平台doccano 进行数据标注,本示例也打通了从标注到训练的通道,即doccano导出数据后可通过doccano.py脚本轻松将数据转换为输入模型时需要的形式,实现无缝衔接。标注方法的详细介绍请参考doccano数据标注指南。
python doccano.py \
--doccano_file ./data/doccano_ext.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0
可配置参数说明:
doccano_file: 从doccano导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为[“正向”, “负向”]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为"##"。
备注:
- 默认情况下 doccano.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过
negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。 - 对于从doccano导出的文件,默认文件中的每条数据都是经过人工正确标注的。
# 转换train数据格式为doccano数据标注
# https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
import json
def convert_record(source):
target = {}
target["id"] = int(source["id"])
target["text"] = source["context"]
target["relations"] = []
target["entities"] = []
id = 0
for item in source["entities"]:
for i in range(len((item['span']))):
tmp = {}
tmp['id'] = id
id = id + 1
tmp['start_offset'] = int(item['span'][i].split(';')[0])
tmp['end_offset'] = int(item['span'][i].split(';')[1])
tmp['label'] = aa[item['label']]
target["entities"].append(tmp)
return target
if __name__ == '__main__':
train_file = '选手数据集/train.json'
json_data = []
content_len=[]
for line in open(train_file, 'r',encoding='utf-8'):
json_data.append(json.loads(line))
content_len.append(len(json.loads(line)["context"]))
ff = open('选手数据集/train_format.txt', 'w')
for item in json_data:
target = convert_record(item)
ff.write(json.dumps(target, ensure_ascii=False ) + '\n')
ff.close()
print(content_len)
[272, 369, 234, 273, 335, 282, 257, 279, 201, 586, 241, 459, 205, 418, 350, 230, 329, 191, 300, 653, 497, 446, 349, 304, 269, 299, 323, 299, 615, 296, 303, 256, 571, 574, 256, 333, 317, 341, 212, 411, 433, 271, 129, 366, 303, 306, 1293, 307, 477, 125, 373, 266, 364, 354, 252, 300, 349, 249, 419, 282, 270, 195, 179, 423, 290, 281, 241, 396, 349, 328, 323, 987, 615, 244, 629, 217, 270, 257, 228, 515, 318, 264, 513, 373, 293, 275, 323, 220, 227, 463, 287, 307, 304, 328, 320, 452, 346, 311, 250, 230]
print(max( content_len))
1293
!unzip -qoa data/data173002/PaddleNLP-develop.zip
三、模型Finetune
1.PaddleNLP下载安装
!unzip -qoa data/data173002/PaddleNLP-develop.zip
2.数据集划分
按照 8:2划分训练集、测试集
!python PaddleNLP-develop/model_zoo/uie/doccano.py \
--doccano_file 选手数据集/train_format.txt\
--task_type ext \
--save_dir 选手数据集/ \
--splits 0.8 0.2 0
[32m[2022-10-19 21:13:30,499] [ INFO][0m - Converting doccano data...[0m
100%|████████████████████████████████████████| 80/80 [00:00<00:00, 15371.49it/s]
[32m[2022-10-19 21:13:30,507] [ INFO][0m - Adding negative samples for first stage prompt...[0m
100%|████████████████████████████████████████| 80/80 [00:00<00:00, 63214.83it/s]
[32m[2022-10-19 21:13:30,509] [ INFO][0m - Converting doccano data...[0m
100%|████████████████████████████████████████| 20/20 [00:00<00:00, 19086.71it/s]
[32m[2022-10-19 21:13:30,510] [ INFO][0m - Adding negative samples for first stage prompt...[0m
100%|████████████████████████████████████████| 20/20 [00:00<00:00, 86569.74it/s]
[32m[2022-10-19 21:13:30,511] [ INFO][0m - Converting doccano data...[0m
0it [00:00, ?it/s]
[32m[2022-10-19 21:13:30,511] [ INFO][0m - Adding negative samples for first stage prompt...[0m
0it [00:00, ?it/s]
[32m[2022-10-19 21:13:30,522] [ INFO][0m - Save 960 examples to 选手数据集/train.txt.[0m
[32m[2022-10-19 21:13:30,524] [ INFO][0m - Save 240 examples to 选手数据集/dev.txt.[0m
[32m[2022-10-19 21:13:30,525] [ INFO][0m - Save 0 examples to 选手数据集/test.txt.[0m
[32m[2022-10-19 21:13:30,525] [ INFO][0m - Finished! It takes 0.03 seconds[0m
[0m
!head -n3 选手数据集/train.txt
{"content": "经审理查明:被告人张某2于2019年12月20日20时30分许,在本市滨湖区落霞苑271号202室租住处饮酒后,驾驶其牌号为豫R的小型轿车从上述小区出发,后在沿本市滨湖区大通路由东向西行驶至瑞景道路口左转弯时,追尾碰撞同向在前等候红绿灯的刘某驾驶的牌号为浙J小型驾车,致两车不同程度毁损。经某政府1认定,被告人张某2负事故全部责任。经某政府2司法鉴定所鉴定,被告人张某2的血液中乙醇含量为172mg/100mL。肇事后,被告人张某2明知他人报警,仍留在现场等候处理,归案后如实供述了上述犯罪事实,并已赔偿被害人刘某全部经济损失,并取得刘某的谅解。", "result_list": [], "prompt": "搭载人姓名"}
{"content": "查明事实2019年7月10日5时44分许,被告人吴某帆饮酒后驾驶粤BXXXXX号牌汽车在深圳市龙华区龙华街道富联二区60栋路段倒车时,该车车尾碰撞到被害人甄某停放在路边的电动自行车。吴某帆随后下车查看情况,并与甄某进行协商。因粤BXXXXX号牌汽车堵在道路中间,5时47分许,吴某帆再次驾驶该车准备把车停好,其朋友则上前阻止其开车,双方在拉扯过程中车辆急速往后倒退,再次撞到甄某的电动自行车,造成甄某电动自行车部分损坏的道路交通事故。经交警部门认定,吴某帆饮酒后驾驶机动车未按规定倒车,负事故的全部责任。因双方协商不成,甄某于是报警。吴某帆则在现场等待民警过来处理。民警到达现场后对被告人吴某帆进行呼气式酒精检测,结果为147mg/100ml,随后民警将其带至医院抽取血样。经检验:被告人吴某帆血液中检出乙醇,含量为155.16mg/100ml。", "result_list": [{"text": "电动自行车", "start": 85, "end": 90}], "prompt": "参与人交通工具"}
{"content": "经审理查明,2016年9月24日19时20分许,被告人陈某某酒后驾驶蒙L80783号比亚迪牌小型轿车由东向西行驶至内蒙古自治区鄂尔多斯市准格尔旗薛家湾镇鑫凯盛小区“金娃娃拉面馆”门前道路处时,与由西向东行驶至此处的驾驶人范某某驾驶的蒙ANB577号丰田牌小型越野客车相撞,造成两车不同程度受损的道路交通事故。被告人陈某某在该起事故中承担同等责任。经某政府1鉴定,被告人陈某某血液酒精含量检验结果为259.598mg/100ml,属醉酒状态。被告人陈某某明知他人报警而在现场等候。2016年9月29日被告人陈某某的妻子冯某某与驾驶人范某某就车损赔偿达成了私了协议书。", "result_list": [], "prompt": "参与人违规情况"}
3.模型训练
可配置参数说明:
train_path: 训练集文件路径。dev_path: 验证集文件路径。save_dir: 模型存储路径,默认为./checkpoint。learning_rate: 学习率,默认为1e-5。batch_size: 批处理大小,请结合机器情况进行调整,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。num_epochs: 训练轮数,默认为100。model: 选择模型,程序会基于选择的模型进行模型微调,可选有uie-base,uie-medium,uie-mini,uie-micro和uie-nano,默认为uie-base。seed: 随机种子,默认为1000.logging_steps: 日志打印的间隔steps数,默认10。valid_steps: evaluate的间隔steps数,默认100。device: 选用什么设备进行训练,可选cpu或gpu。
!python PaddleNLP-develop/model_zoo/uie/finetune.py \
--train_path 选手数据集/train.txt \
--dev_path 选手数据集/dev.txt \
--save_dir ./checkpoint \
--learning_rate 5e-6 \
--model uie-base \
--batch_size 40 \
--logging_steps 10 \
--valid_steps 20 \
--device gpu
[32m[2022-10-19 21:13:51,576] [ INFO][0m - Downloading resource files...[0m
[32m[2022-10-19 21:13:51,578] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'uie-base'.[0m
W1019 21:13:51.606197 460 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1019 21:13:51.610246 460 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[32m[2022-10-19 21:14:10,096] [ INFO][0m - global step 10, epoch: 1, loss: 0.00685, speed: 0.66 step/s[0m
训练日志
[2022-10-19 01:44:30,594] [ INFO] - global step 1080, epoch: 39, loss: 0.00137, speed: 0.73 step/s
[2022-10-19 01:44:43,267] [ INFO] - global step 1090, epoch: 39, loss: 0.00136, speed: 0.79 step/s
[2022-10-19 01:44:56,827] [ INFO] - global step 1100, epoch: 40, loss: 0.00135, speed: 0.74 step/s
[2022-10-19 01:45:02,527] [ INFO] - Evaluation precision: 0.78968, recall: 0.81893, F1: 0.80404
[2022-10-19 01:45:02,528] [ INFO] - best F1 performence has been updated: 0.79592 --> 0.80404
4 模型评估
通过运行以下命令进行模型评估:
!python PaddleNLP-develop/model_zoo/uie/evaluate.py \
--model_path ./checkpoint/model_best \
--test_path 选手数据集/dev.txt \
--batch_size 32 \
--max_seq_len 512
[32m[2022-10-19 14:50:04,155] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.[0m
W1019 14:50:04.205535 16179 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1019 14:50:04.210335 16179 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[32m[2022-10-19 14:50:11,956] [ INFO][0m - -----------------------------[0m
[32m[2022-10-19 14:50:11,956] [ INFO][0m - Class Name: all_classes[0m
[32m[2022-10-19 14:50:11,956] [ INFO][0m - Evaluation Precision: 0.79757 | Recall: 0.81070 | F1: 0.80408[0m
[0m
四、TaskFlow预测
1.单个预测
from pprint import pprint
from paddlenlp import Taskflow
schema = aa.values()
print(schema)
# 设定抽取目标和定制化模型权重路径
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best')
dict_values(['被告人交通工具', '被告人行驶情况', '被告人违规情况', '行为地点', '搭载人姓名', '其他事件参与人', '参与人交通工具', '参与人行驶情况', '参与人违规情况', '被告人责任认定', '参与人责任认定', '被告人行为总结'])
[2022-10-19 14:50:26,428] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
my_ie("经审理查明:2017年8月30日凌晨,被告人谢某2饮酒后驾驶一辆车牌号为粤U号小型轿车沿潮州市潮安区彩庵线自南往北方向行驶,当车行驶至彩塘镇新联路段处时,因被告人谢某2疏忽大意,没有按照操作规范安全驾驶,致使车辆失控碰撞到由被害人郑某1驾驶并停放于道路东侧停车线内的粤U号轻型普通货车,后又碰撞到被害人谢某1、林某1停放在该处人行道上的二辆无号牌二轮摩托车,致摩托车在倒地过程中再次碰撞到正在该处路边吃宵夜的被害人谢某1、许某1、杨某,造成被告人谢某2及被害人谢某1、许某1、杨某受伤及四车不同程度受损的交通事故。事故发生后,谢某2、谢某1、许某1、杨某被送往医院治疗,后民警委托医护人员提取被告人谢某2的血样送检。经某政府2鉴定:送检的谢某2的血液中检出乙醇(Ethanol)成分,含量为215")
[{'被告人交通工具': [{'text': '小型轿车',
'start': 39,
'end': 43,
'probability': 0.999961972578177}],
'被告人违规情况': [{'text': '没有按照操作规范安全驾驶',
'start': 89,
'end': 101,
'probability': 0.7432192783614511}],
'行为地点': [{'text': '彩塘镇新联路段处',
'start': 67,
'end': 75,
'probability': 0.9992214588212356}],
'搭载人姓名': [{'text': '郑某1',
'start': 115,
'end': 118,
'probability': 0.3178452688557911}],
'参与人交通工具': [{'text': '小型轿车',
'start': 39,
'end': 43,
'probability': 0.9937464297200052}],
'被告人行为总结': [{'text': '疏忽大意',
'start': 84,
'end': 88,
'probability': 0.9534919902137879}]}]
mystr="经审理查明,2016年3月12日15时50分许,被告人王某酒后驾驶无牌普通两轮摩托车由东向西行驶至本市凉州区黄羊镇二坝小学路段时,与同向行驶的被害人蒋某某驾驶的甘HB0622小轿车发生碰撞,致王某受伤、车辆受损的一般交通事故。2016年3月15日,甘肃申证司法医学鉴定所以甘申司法毒物鉴字(2016)第179号关于王某酒精含量司法鉴定检验报告书鉴定:送检的王某字样试管血液样中检测出酒精成份,含量为118.18mg/100m1。2016年4月11日,某政府以武公交凉认字第622301XXXXXXXXXX号道路交通事故责任认定书认定:王某负此次事故的全部责任,蒋某某在事故中无责任。案发后,被告人王某与受害人蒋某某就民事赔偿已某某了和解协议,双方已履行了协议。"
# 查找重复出现的字符串
def str_all_index(str_, a):
'''
Parameters
----------
str_ : string.
a : str_中的子串
Returns
-------
index_list : list
首先输入变量2个,输出list,然后中间构造每次find的起始位置start,start每次都在找到的索引+1,后面还得有终止循环的条件
'''
index_list=[]
start=0
while True:
x=str_.find(a,start)
if x>-1:
start=x+1
index_list.append(x)
else:
break
return index_list
a=str_all_index(mystr,'蒋某某')
print(a)
import numpy as np
b=np.ones(len(a)).astype(int)
c=a+b*len('蒋某某')
print(c)
[74, 280, 304]
[ 77 283 307]
2.批量预测并保存
# 预测
# https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
import json
from paddlenlp import Taskflow
def predict(ie, result_item):
result = ie(result_item['context'])[0]
print(result)
sub_list = []
for item in result:
sub_tmp = {}
sub_tmp["label"] = str(keys[values.index(str(item))])
all_search=str_all_index(result_item['context'], result[item][0]["text"])
txt_list=[]
sub_span=[]
if len(result[item])==1:
for i in range(len(all_search)):
txt_list.append(result[item][0]["text"])
sub_span.append([all_search[i], all_search[i] +len(result[item][0]["text"])])
else:
for i in range(len(result[item])):
txt_list.append(result[item][i]["text"])
sub_span.append([result[item][i]["start"], result[item][i]["end"]])
sub_tmp["text"]=txt_list
sub_tmp["span"]=sub_span
sub_list.append(sub_tmp)
result_item["entities"] = sub_list
return result_item
if __name__ == '__main__':
test_file = '选手数据集/test.json'
aa={'11339': '被告人交通工具',
'11340': '被告人行驶情况',
'11341': '被告人违规情况',
'11342': '行为地点',
'11343': '搭载人姓名',
'11344': '其他事件参与人',
'11345': '参与人交通工具',
'11346': '参与人行驶情况',
'11347': '参与人违规情况',
'11348': '被告人责任认定',
'11349': '参与人责任认定',
'11350': '被告人行为总结',
}
values = list(aa.values())
keys=list(aa.keys())
# idx = values.index("被告人交通工具")
# print(idx)
# print(keys)
# key = keys[idx]
# print(key)
schema = aa.values()
# 设定抽取目标和定制化模型权重路径
ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best')
ff = open('result.txt', 'w')
for line in open(test_file, 'r',encoding='utf-8'):
result_item=json.loads(line)
target = predict(ie, result_item)
ff.write(json.dumps(target, ensure_ascii=False) + '\n')
ff.close()
[2022-10-19 23:39:52,614] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
{'被告人交通工具': [{'text': '普通两轮摩托车', 'start': 35, 'end': 42, 'probability': 0.9999290709754405}], '被告人行驶情况': [{'text': '无牌', 'start': 33, 'end': 35, 'probability': 0.9998779317016755}, {'text': '由东向西行驶', 'start': 42, 'end': 48, 'probability': 0.9995682605337066}], '被告人违规情况': [{'text': '酒后', 'start': 29, 'end': 31, 'probability': 0.9999209653944092}], '行为地点': [{'text': '本市凉州区黄羊镇二坝小学路段', 'start': 49, 'end': 63, 'probability': 0.9996988997986733}], '其他事件参与人': [{'text': '蒋某某', 'start': 74, 'end': 77, 'probability': 0.9999301437981813}, {'text': '蒋某某', 'start': 304, 'end': 307, 'probability': 0.9998673231699229}, {'text': '蒋某某', 'start': 280, 'end': 283, 'probability': 0.9998629136562158}], '参与人交通工具': [{'text': '小轿车', 'start': 87, 'end': 90, 'probability': 0.9999316937169453}], '参与人行驶情况': [{'text': '同向行驶', 'start': 66, 'end': 70, 'probability': 0.9998941446452676}], '被告人责任认定': [{'text': '全部责任', 'start': 275, 'end': 279, 'probability': 0.9999642375282747}], '参与人责任认定': [{'text': '无责任', 'start': 287, 'end': 290, 'probability': 0.9995731568913193}]}
{'被告人交通工具': [{'text': '小型轿车', 'start': 32, 'end': 36, 'probability': 0.9998674413551356}], '被告人违规情况': [{'text': '饮酒后', 'start': 25, 'end': 28, 'probability': 0.9999556544576649}], '行为地点': [{'text': '九高路金鱼镇成绵高速桥洞路段处', 'start': 66, 'end': 81, 'probability': 0.9995057567736296}], '其他事件参与人': [{'text': '黄某2', 'start': 92, 'end': 95, 'probability': 0.9997937784053192}, {'text': '黄某2', 'start': 187, 'end': 190, 'probability': 0.9997843620063804}], '参与人交通工具': [{'text': '小型轿车', 'start': 100, 'end': 104, 'probability': 0.9994159591370746}, {'text': '轿车', 'start': 109, 'end': 111, 'probability': 0.6167306329585287}], '被告人行为总结': [{'text': '醉酒驾驶', 'start': 168, 'end': 172, 'probability': 0.9998359736538163}]}
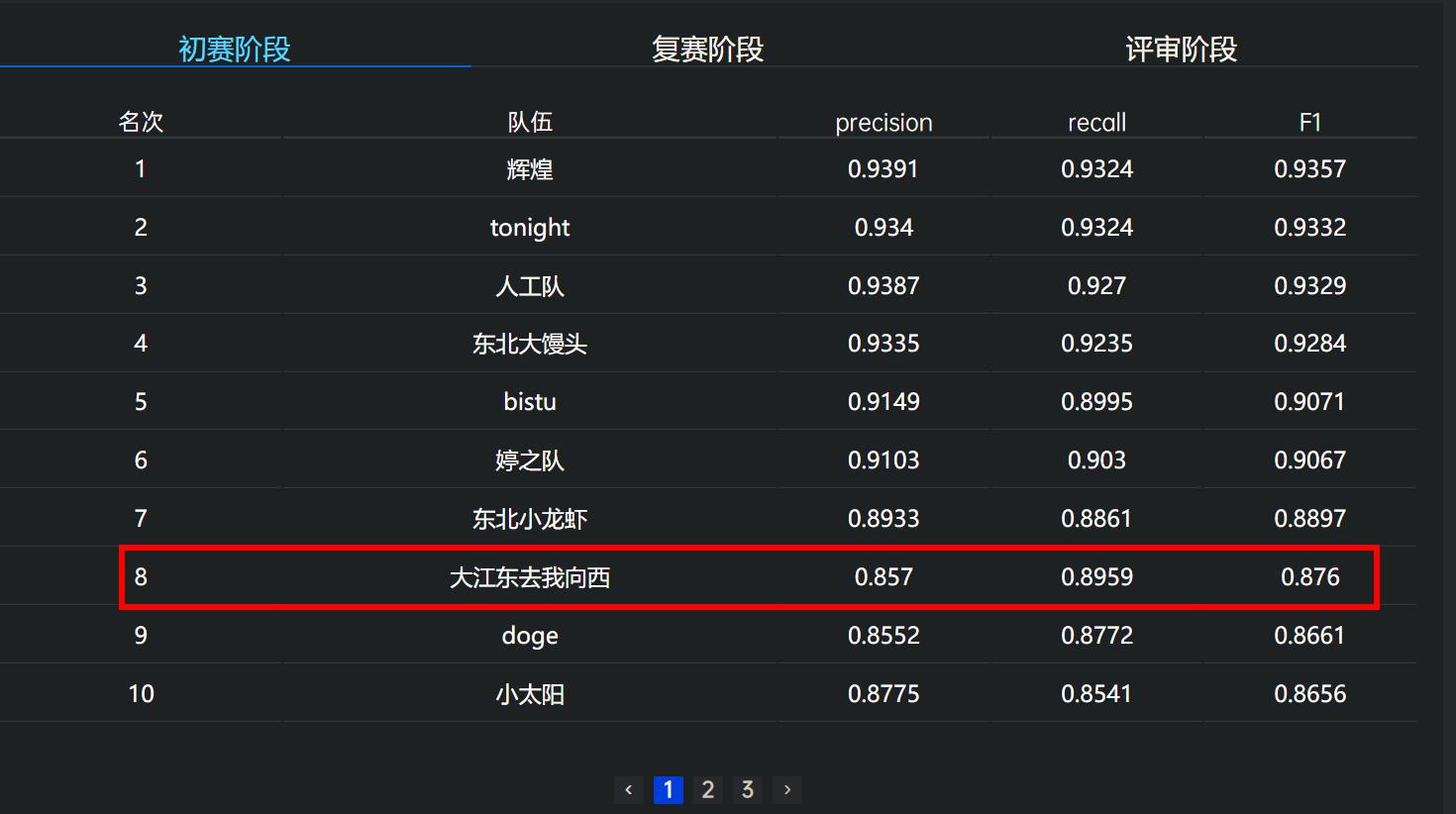
五、提交结果
提交后为第8名,初步分析使用200条记录结果较差,计划下一步使用未标注的10000条数据进行预测。
欢迎fork,欢迎支持。

- 点赞
- 收藏
- 关注作者
评论(0)