第 2 章 马尔可夫决策过程
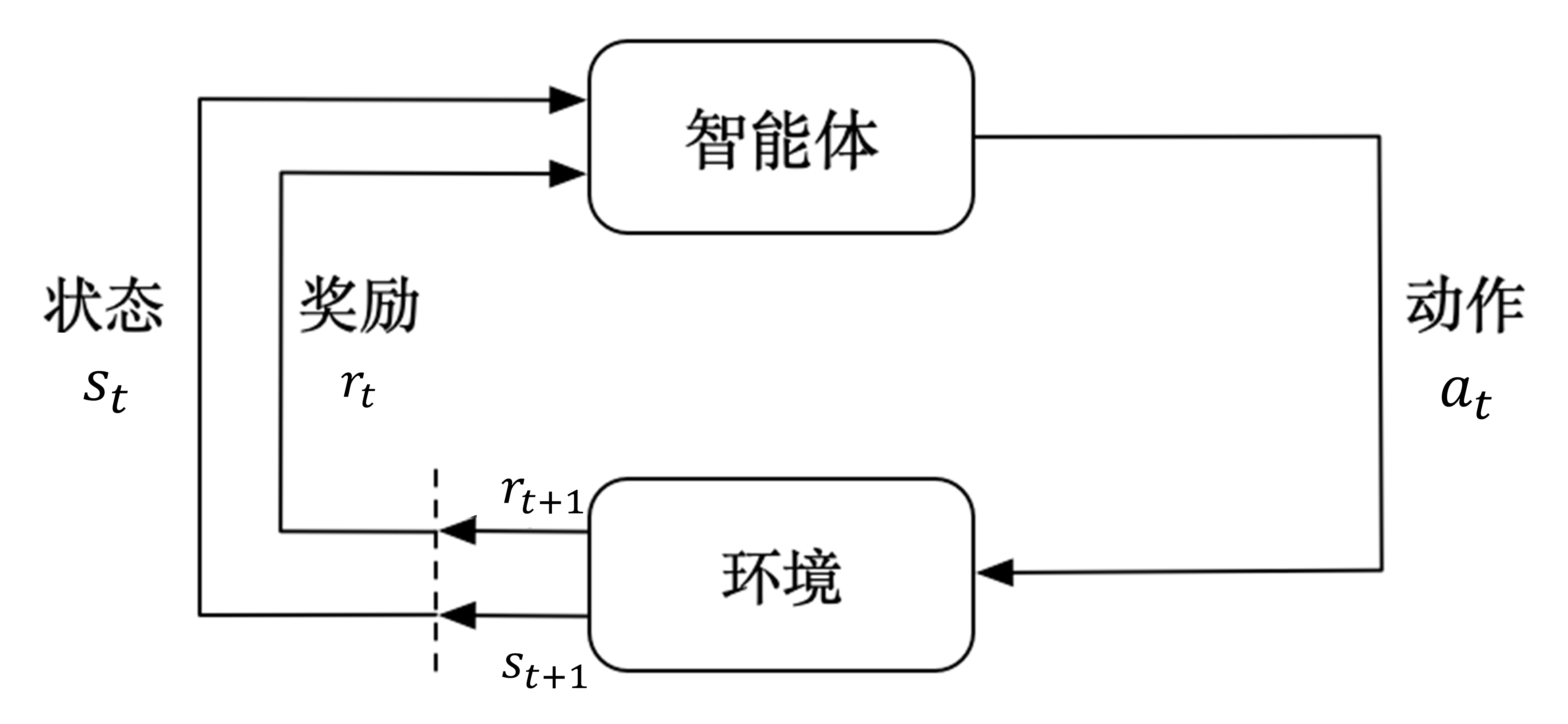
图 2.1 介绍了强化学习里面智能体与环境之间的交互,智能体得到环境的状态后,它会采取动作,并把这个采取的动作返还给环境。环境得到智能体的动作后,它会进入下一个状态,把下一个状态传给智能体。在强化学习中,智能体与环境就是这样进行交互的,这个交互过程可以通过马尔可夫决策过程来表示,所以马尔可夫决策过程是强化学习的基本框架。
图 2.1 智能体与环境之间的交互
本章将介绍马尔可夫决策过程。在介绍马尔可夫决策过程之前,我们先介绍它的简化版本:马尔可夫过程(Markov process,MP)以及马尔可夫奖励过程(Markov reward process,MRP)。通过与这两种过程的比较,我们可以更容易理解马尔可夫决策过程。其次,我们会介绍马尔可夫决策过程中的策略评估(policy evaluation),就是当给定决策后,我们怎么去计算它的价值函数。最后,我们会介绍马尔可夫决策过程的控制,具体有策略迭代(policy iteration) 和 价值迭代(value iteration) 两种算法。在马尔可夫决策过程中,它的环境是全部可观测的。但是很多时候环境里面有些量是不可观测的,但是这个部分观测的问题也可以转换成马尔可夫决策过程的问题。
2.1 马尔可夫过程
2.1.1 马尔可夫性质
在随机过程中,马尔可夫性质(Markov property) 是指一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。以离散随机过程为例,假设随机变量
X0,X1,⋯,XT构成一个随机过程。这些随机变量的所有可能取值的集合被称为状态空间(state space)。如果
Xt+1 对于过去状态的条件概率分布仅是
Xt 的一个函数,则
p(Xt+1=xt+1∣X0:t=x0:t)=p(Xt+1=xt+1∣Xt=xt)
其中,
X0:t 表示变量集合
X0,X1,⋯,Xt,
x0:t 为在状态空间中的状态序列
x0,x1,⋯,xt。马尔可夫性质也可以描述为给定当前状态时,将来的状态与过去状态是条件独立的。如果某一个过程满足马尔可夫性质,那么未来的转移与过去的是独立的,它只取决于现在。马尔可夫性质是所有马尔可夫过程的基础。
2.1.2 马尔可夫链
马尔可夫过程是一组具有马尔可夫性质的随机变量序列
s1,⋯,st,其中下一个时刻的状态
st+1只取决于当前状态
st。我们设状态的历史为
ht={s1,s2,s3,…,st}(
ht 包含了之前的所有状态),则马尔可夫过程满足条件:
p(st+1∣st)=p(st+1∣ht)(2.1)
从当前
st 转移到
st+1,它是直接就等于它之前所有的状态转移到
st+1。
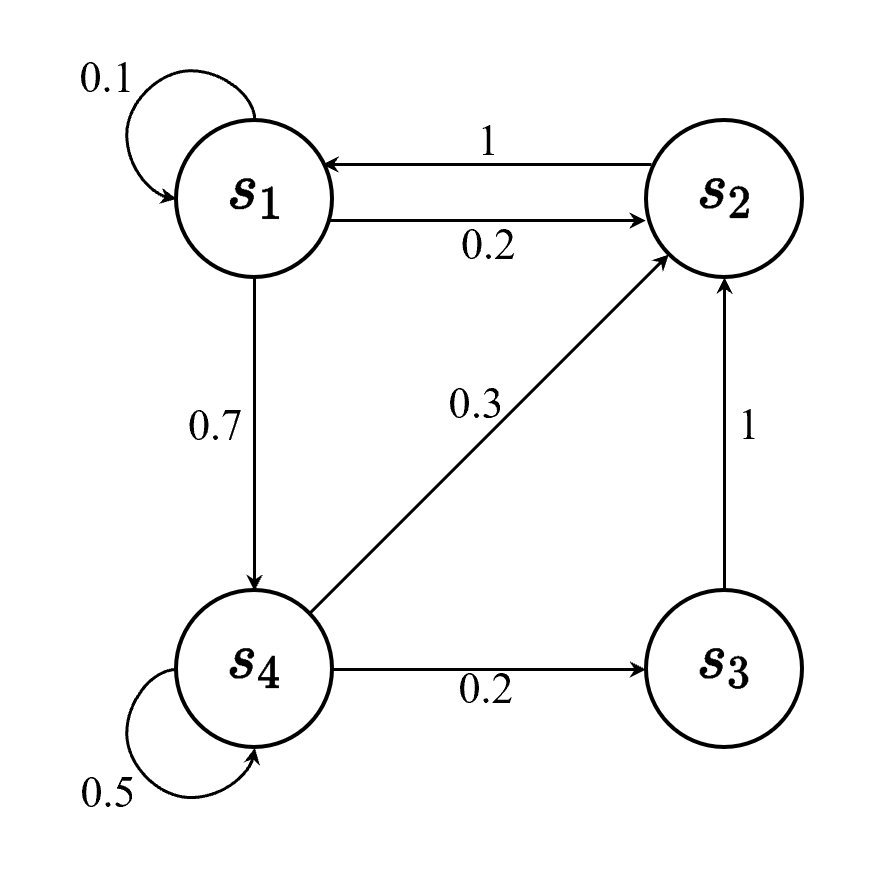
离散时间的马尔可夫过程也称为马尔可夫链(Markov chain)。马尔可夫链是最简单的马尔可夫过程,其状态是有限的。例如,图 2.2 里面有4个状态,这4个状态在
s1,s2,s3,s4 之间互相转移。比如从
s1 开始,
s1 有 0.1 的概率继续存留在
s1 状态,有 0.2 的概率转移到
s2,有 0.7 的概率转移到
s4 。如果
s4 是我们的当前状态,它有 0.3 的概率转移到
s2,有 0.2 的概率转移到
s3,有 0.5 的概率留在当前状态。
图 2.2 马尔可夫链示例
我们可以用状态转移矩阵(state transition matrix)
P 来描述状态转移
p(st+1=s′∣st=s):
P=⎝⎜⎜⎜⎜⎛p(s1∣s1)p(s1∣s2)⋮p(s1∣sN)p(s2∣s1)p(s2∣s2)⋮p(s2∣sN)……⋱…p(sN∣s1)p(sN∣s2)⋮p(sN∣sN)⎠⎟⎟⎟⎟⎞
状态转移矩阵类似于条件概率(conditional probability),它表示当我们知道当前我们在状态
st 时,到达下面所有状态的概率。所以它的每一行描述的是从一个节点到达所有其他节点的概率。
2.1.3 马尔可夫过程的例子
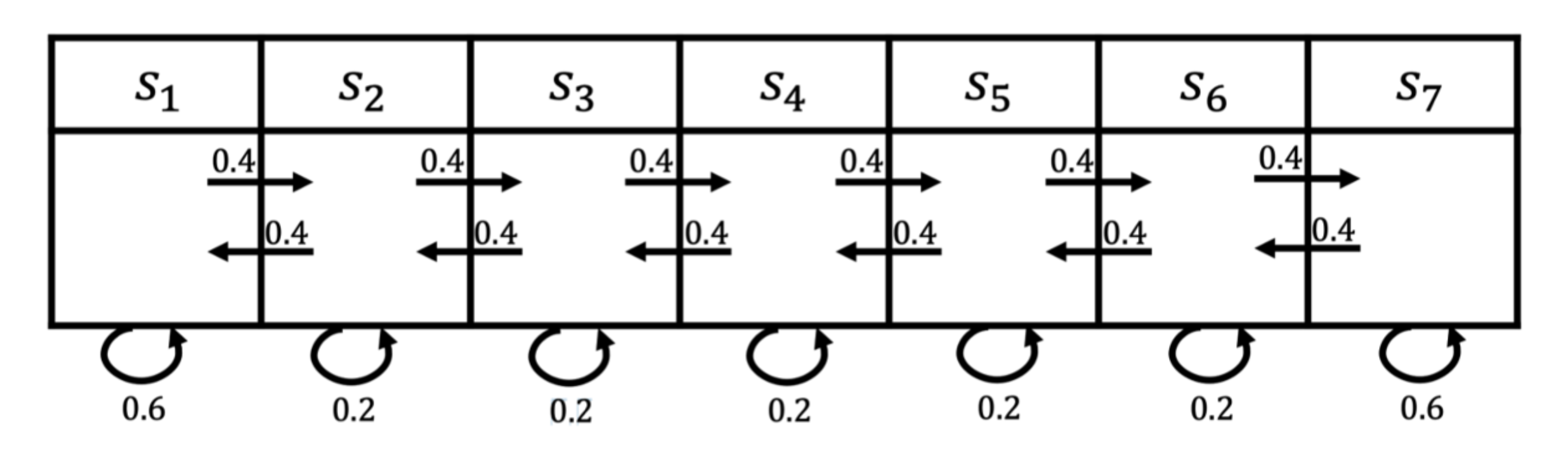
图 2.2 所示为一个马尔可夫过程的例子,这里有七个状态。比如从
s1 开始,它有0.4的概率到
s2 ,有 0.6 的概率留在当前的状态。
s2 有 0.4 的概率到
s1,有 0.4 的概率到
s3 ,另外有 0.2 的概率留在当前状态。所以给定状态转移的马尔可夫链后,我们可以对这个链进行采样,这样就会得到一串轨迹。例如,假设我们从状态
s3 开始,可以得到3个轨迹:
-
s3,s4,s5,s6,s6;
-
s3,s2,s3,s2,s1;
-
s3,s4,s4,s5,s5。
通过对状态的采样,我们可以生成很多这样的轨迹。
图 2.3 马尔可夫过程的例子
2.2 马尔可夫奖励过程
马尔可夫奖励过程(Markov reward process, MRP)是马尔可夫链加上奖励函数。在马尔可夫奖励过程中,状态转移矩阵和状态都与马尔可夫链一样,只是多了奖励函数(reward function)。奖励函数
R 是一个期望,表示当我们到达某一个状态的时候,可以获得多大的奖励。这里另外定义了折扣因子
γ 。如果状态数是有限的,那么
R 可以是一个向量。


评论(0)