【每日一读】On Power Law Distributions in Large-scale Taxonomies

@TOC

简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
本文仅记录自己感兴趣的内容
ABSTRACT
在许多大规模的物理和社会复杂系统中,都会出现胖尾分布现象,并提出了不同的生成机制。在本文中,我们研究了大型分类法(如Open)演化过程中的发电规律分布模型
目录项目,由分配给数万个类别之一的网站组成。这种分类法中的类别以树或DAG结构配置排列,它们之间具有父子关系。我们首先定量分析了这类分类的形成过程,这导致幂律分布作为平稳分布。在为大规模分类法设计分类器的背景下,自动将看不见的文档分配到叶级类别,我们强调了如何利用这些分布的胖尾特性来分析研究此类分类器的空间复杂性。对公共可用数据集空间复杂性的经验评估证明了我们方法的适用性
1. INTRODUCTION
随着来自社交网络、在线商业服务和新闻网络等各种来源的网络数据的巨大增长,将数据结构化为概念分类法将带来更好的可扩展性、可解释性和可视化。雅虎!目录、开放目录项目(ODP)和维基百科是此类网络规模分类法的突出例子。国家医学图书馆的医学主题分类体系是生命科学领域中大规模分类的另一个实例。这些分类法由以层次结构排列的类组成,它们之间有父子关系,可以是有根树或有向无环图的形式。例如,ODP以植根树的形式列出了分布在近100万个类别中的500多万个网站,由近10万名编辑维护。另一方面,维基百科代表了一个更复杂的有向图分类结构,由一百多万个类别组成。在这种情况下,大规模分级分类处理的任务是自动将标签分配给来自一组目标类的看不见的文档,这些目标类由分级中的叶级节点表示。
在这项工作中,我们研究了数据的分布和-大型分类法中的层次树,目的是模拟它们的进化过程。这是通过基于Yule[33]提出的著名模型,使用优惠依附模型对大规模税收经济的演化进行定量研究来实现的,该模型表明,在整个增长过程中,分类学呈现出胖尾分布。我们将这种推理应用于简单联合模型中的类别大小和树连通性。
形式上,随机变量x被定义为遵循幂律分布,如果对于某个正常数a,完全累积分布如下所示:
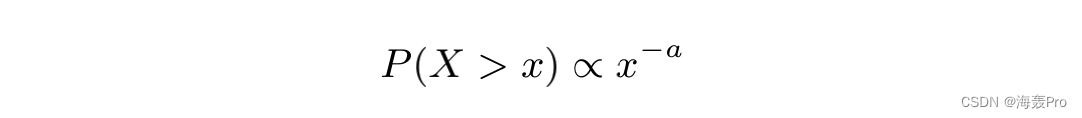
幂律分布,或更普遍的比高斯分布衰减慢的胖尾分布,存在于各种各样的物理和社会复杂系统中,从城市人口、,财富在科学文章引用中的分布[23.这也见于网络连接,在网络连接中,互联网和维基百科是显著的免试工具[27;7.我们在大规模网络分类的背景下进行的分析有助于更好地理解此类大规模数据,同时也有助于对分层分类方案的空间复杂性进行具体分析经过训练的分类器对分类系统在许多实际应用中的适用性起着至关重要的作用。
本文提出的空间复杂度分析提供了分层和平面分类的训练模型的分析比较,该模型可用于为当前的分类问题先验选择合适的模型,而无需实际训练任何模型。利用分类法的幂律性质来研究分层支持向量机的训练时间复杂性,已在[32;19.其中的作者仅从经验上证明了幂律假设,与我们在第3节中的分析不同,我们在其他模型中研究的类似过程的背景下,更准确地描述了大规模网络分类的生成过程。
2. RELATED WORK
幂律分布在各种物理和社会复杂系统中都有报道[22,例如在网络间拓扑中。例如,11;7表明,互联网拓扑在节点的程度方面表现出幂律。此外,网站类别的大小分布(以网站数量衡量)表现出了胖尾分布,如开放目录项目(ODP)的32;19中的经验所示发电功率定律分布提出了各种模型,这一现象在复杂系统中可能被视为统计学中的正态分布
25.然而,与通过中心极限定理直接推导正态分布相反,解释幂律形成的模型都依赖于近似。一些解释基于乘性噪声或重整化群形式28;30;16.对于大规模分类法的生长过程,基于优先附着的模型是最合适的,本文使用了这些模型。这些模型基于Yule[33的种子模型,最初是为生物物种分类制定的,详见第3节。它适用于系统中的元素被分类的系统,并且系统在类的数量和元素的总数(这里是文档或网站)上都有所增长。在其原始形式中,Yule的模型可以解释任何分类法中的幂律形成,而不考虑类别之间的最终层次。类似的动力学已被应用于解释网络连接中的缩放,其通过优先附着2在节点和边缘方面生长。最近的进一步概括将相同的生长过程应用于树木[17;14;29。
在本文中,通过Klemm等人17的模型描述了儿童与父母类别关系中的近似幂律。此外,我们以简单的方式将这一形成过程与原始Yule模型相结合,以解释类别大小中的幂律,i、 e.我们为大规模网络分类法(如DMOZ)的形成过程提供了全面的解释。从第二步开始,我们推断了每个类别的特征数量的第三个比例分布。这是通过经验堆定律10实现的,该定律描述了文本长度与其词汇表大小之间的比例关系。
早期关于利用tar之间的层次结构的一些工作-[18;6和[8中已经研究了用于文本分类的get类,其中目标类的数量限制在几百个。然而[19是分层分类领域的先驱研究之一,旨在解决网络规模的目录,如由超过100000个目标类组成的雅虎目录。研究人员分析了脂肪和分层分类的准确性和训练时间复杂性方面的性能。最近,大规模分层文本分类的其他技术已经en提议。[4]中提出了通过应用在验证集上训练的精化专家来防止错误传播的方法。在这种方法中,通过利用较低级别分类器的输出来执行自下而上的信息传播,以提高顶层的分类。(31]中提出的深度分类方法首先应用层次修剪来识别目标类的更小子集。然后,通过在第一步确定的目标类子集上重新训练朴素贝叶斯分类器来执行测试实例的预测。最近,[15中提出了大规模层次分类的贝叶斯建模,其中通过将子节点的先验集中在其父节点的参数值来建模父子节点之间的层次依赖关系。
除了预测精度,其他性能指标,如预测和训练速度以及模型的空间复杂度也变得越来越重要。这在大数据领域的问题所带来的挑战的背景下尤其如此,其中需要在这些指标之间进行最佳权衡。预测速度在这种情况下的重要性在最近的研究中得到了强调,如[3];13;24;5.预测速度与训练模型的空间复杂度直接相关,因为由于尺寸太大,可能无法将大型训练模型加载到主存储器中。尽管它对预测速度有直接影响,但早期的工作还没有集中于分层分类器的空间复杂程度。
此外,虽然在[32;19中出于分析目的使用了幂律分布的存在,但没有对这种现象的存在给出充分的理由。
我们在第3节中的分析试图以定量的方式解决这个问题。最后,幂律语义已被用于大规模分级分类系统的模型选择和评估[1.与经典机器学习意义上研究的问题不同,这些问题涉及有限数量的目标类,该应用程序形成了提取大数据中隐藏信息的蓝图。
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正


- 点赞
- 收藏
- 关注作者
评论(0)