Text to image论文精读 DM-GAN: Dynamic Memory Generative Adversarial

这篇文章提出了动态记忆生成对抗网络(DM-GAN)来生成高质量的图像。该方法可以在初始图像生成不好时,引入动态存储模块来细化模糊图像内容,从而能够从文本描述中更加准确地生成图像。
文章被2019年CVPR(IEEE Conference on Computer Vision and Pattern Recognition)会议收录。
论文地址: https://arxiv.org/abs/1904.01310?context=cs
代码地址: https://github.com/MinfengZhu/DM-GAN
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
在本文中,我们着重于从文本描述生成真实的图像。现有的方法首先生成形状和颜色粗糙的初始图像,然后将初始图像细化为高分辨率图像。大多数现有的文本图像合成方法都存在两个主要问题。(1) 这些方法在很大程度上取决于初始图像的质量。如果初始图像没有很好地初始化,以下过程很难将图像细化到令人满意的质量。(2) 当描述不同的图像内容时,每个单词都具有不同的重要性,但是,在现有的图像细化过程中使用不变的文本表示。在本文中,我们提出了动态记忆生成对抗网络(DM-GAN)来生成高质量的图像。该方法在初始图像生成不好时,引入动态存储模块来细化模糊图像内容。设计了一个记忆写入门,根据初始图像内容选择重要的文本信息,使我们的方法能够从文本描述中准确地生成图像。我们还利用响应门自适应地融合从存储器读取的信息和图像特征。我们在加州理工大学UCSD Birds 200数据集和Microsoft Common Objects in Context数据集上评估DM-GAN模型。实验结果表明,我们的DM-GAN模型与最先进的方法相比具有良好的性能。
二、关键词
Text-to-Image Synthesis, Generative Adversarial Nets, Computer Vision
三、为什么提出DM-GAN?
在DM-GAN之前的多阶段图像生成的方法(StackGAN、StackGAN++、AttnGAN)存在两个问题。
1、生成结果在很大程度上取决于最初合成的图像(即第一阶段的图像)的质量。如果初始图像生成不好,则图像细化过程无法生成高质量图像。
2、每个单词在描述图片内容上都有不同等级的信息,而之前的方法仅仅使用相同的单词影响度。
就是说每个单词对图片的内容的作用都不一样,重要性也不一样,怎样将单词与要生成的图像的不同内容很好的关联。
本文对以上问题提出了解决方案:
对于第一个问题,引入一个记忆机制来处理生成的初始图像。
在GAN里添加一个键值存储结构。将初始图像的粗略特征送入键值存储结构来查询特征,利用查询到的结果来对初始图像进行修正
对于第二个问题,引入了一个记忆写入门来动态选择与生成的图像相关的单词。利用图像信息确定每个单词的重要性,进行细化,这使得生成的图像很好地依赖于文本描述。
响应门用于自适应地接收来自图像和存储器的信息,在每个图像细化过程中,根据初始图像和文本信息动态地写入和读取存储器组件。
比如:AttnGAN对所有单词都一视同仁,它使用了一个相同的注意模块来表示单词。但DM-GAN提出的存储模块能够发现图像生成的这种差异,因为它基于初始图像内容动态地选择重要的单词信息。
四、模型结构
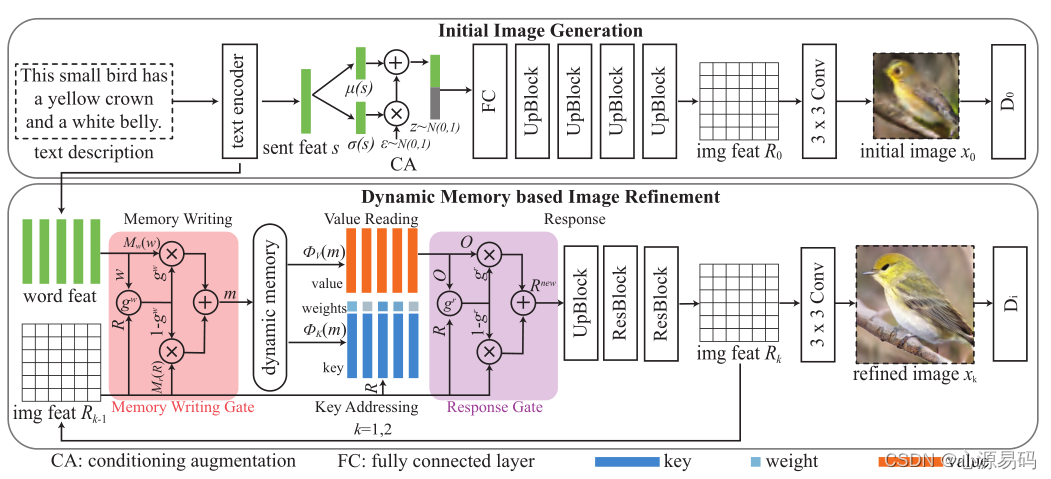
4.1、模型组成
模型由两个阶段组成:初始图像生成和基于动态记忆的图像细化。
初始图像生成阶段:与之前的模型相似,首先通过文本编码器将输入文本描述转换为一些特征向量(如句子特征向量和单词特征向量),然后句子特征通过CA模块(流形插值+加入随机噪声)、生成器部分(全连接层+上采样+卷积)生成具有粗糙形状和少量细节的初始图像。
动态记忆生成阶段:将更多细粒度的视觉内容添加到模糊初始图像中,以生成照片逼真图像 , ,其中 是上一阶段的图像特征,即细化阶段可以重复多次。
动态记忆的图像细化阶段由四个部分组成:记忆写入、键寻址,键值读出,响应(Memory Writing, Key Addressing, Value Reading, and Response ),利用记忆写入门来突出重要单词信息,利用响应门自适应地融合从存储器读取的信息和图像特征。
Memory Writing:将文本信息存储到key-value结构化记忆中以供进一步检索
Key Addressing和Value Reading:从记忆模块读取特征,以改善和细化低质量图像的视觉特征。
Response:控制图像特征和记忆的读取的融合
4.2、动态记忆机制
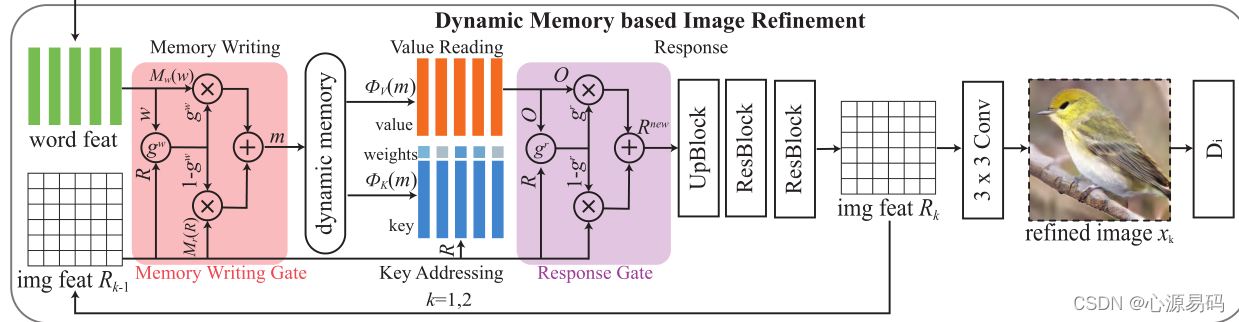
记忆网络使用显式的存储和注意力的观念,可以更有效地推理记忆中的答案。它首先,将信息写入外部存储,然后根据关联概率从记忆插槽(memory slot)中读取信息。
首先定义 W为输入的单词特征,x为图像,
为图像特征,T为单词的数量,
是单词特征的维数,N为图像像素数,图像像素特征是
维向量 。动态记忆通过键和值之间的非平凡变换,使用更有效的方式融合文本和图像信息,从而优化图像。
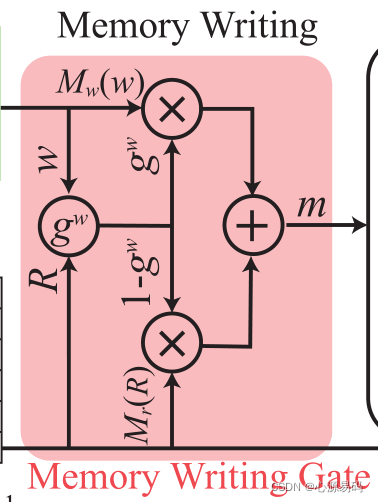
4.2.1、Memory Writing
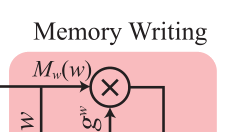
其中,M(·)表示1×1卷积运算.
记忆写入就是编码先验知识,记忆写入将文本特征经过一次1*1卷积运算嵌入到n维的记忆特征空间中。
4.2.2、Key Addressing
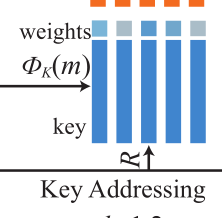
其中exp(x)是高等数学里以自然常数e为底的指数函数:
是将键(key)特征映射到相应维度上的1*1卷积核。
表示第i个记忆和第j个图像特征之间的相似概率、相似度
键寻址就是使用key memory取得相关的记忆, 计算每个记忆位置的权重
4.2.3、Value Reading
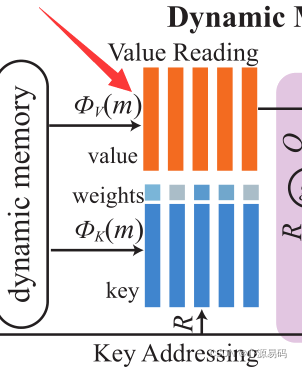
表示值(value)特征映射到相应维度上的1*1卷积核。
记忆表达形式定义为根据相似概率对值记忆进行加权求和。
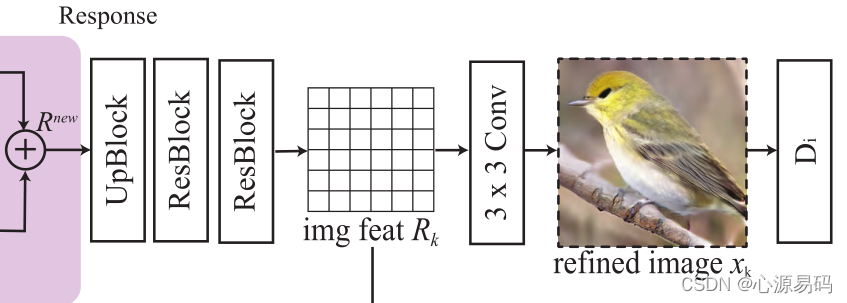
4.2.4、Response
在接收到输出后,将当前图像和输出表示结合起来,以形成新的图像特征,新的图像特征为:
得到
后,通过上采样、残差块将新的图像特征放大为高分辨率图像,最后通过3*3的卷积得到细化图像。
4.3 记忆写入门
首先将图像特征和单词特征变换成同维度,相结合,形成记忆写入门:
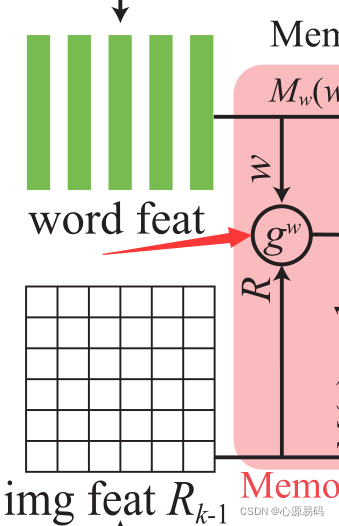
其中,
是内存写入门,σ是sigmoid函数,A是1*
的矩阵,B是1*
的矩阵。
然后结合图像和文字特征编写记忆slot(插槽):
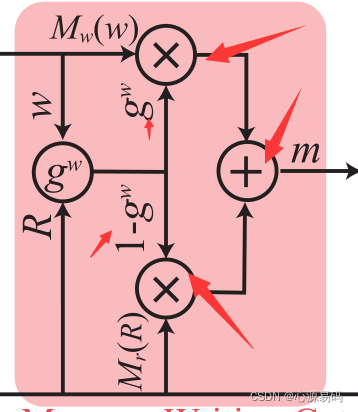
其中,
是记忆slot(插槽),
和
表示1*1的卷积运算。
4.4 响应门
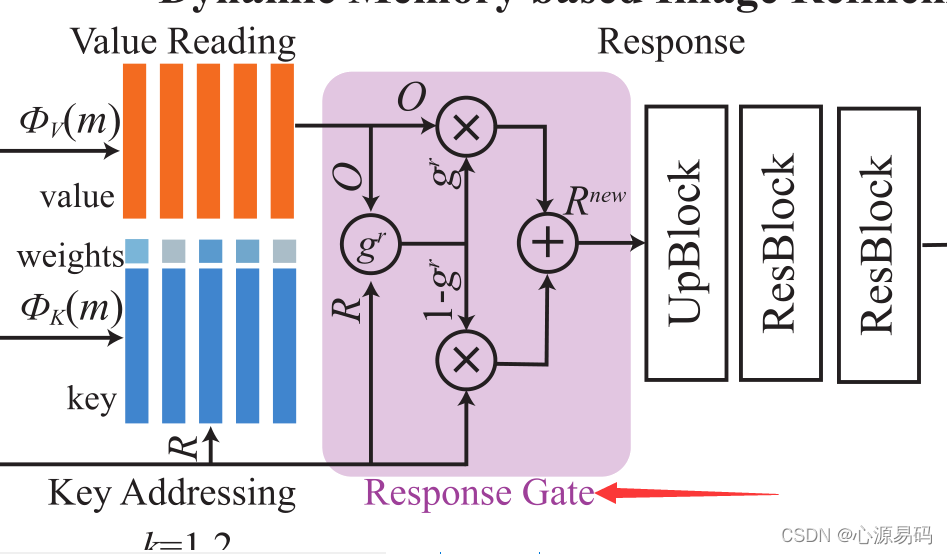
利用自适应选通机制,来动态控制信息流和更新图像特征
其中,
是信息融合的响应门,σ是sigmoid函数 ,W是参数矩阵,b是偏移量。
4.5、损失函数
总的损失函数为:
其有三项,第一项为对抗损失(各个生成器的损失),第二项为CA(条件反射增强 )损失,第三项为DAMSM(深层注意多模态相似模型)损失,λ1和λ2为权重。
4.5.1、对抗损失
对抗损失就是生成器的损失,相关介绍可看:StackGAN++博文,损失函数为:
与之前相同,第一项是使生成的图像尽可能真实的无条件损失,第二项是使图像与输入句子匹配的条件损失。
其中的D:
4.5.2、CA损失
其中µ(s)和∑(s)是句子特征的均值和对角协方差矩阵。
4.5.3、DAMSM损失
利用DAMSM损失来衡量图像和文本描述之间的匹配程度。DAMSM损失使得生成的图像更好地基于文本描述。损失函数可见:AttnGAN博文介绍。
五、实验
数据集:COCO、CUB
评价标准:Inception Score (IS), Fréchet Inception Distance (FID), R-precision
评价结果:实验结果表明,DM-GAN模型生成的图像质量高于其他方法,DM-GAN学习了更好的数据分布,且DM-GAN生成的图像更好地适应给定的文本描述,这进一步证明了所采用的动态记忆的有效性。
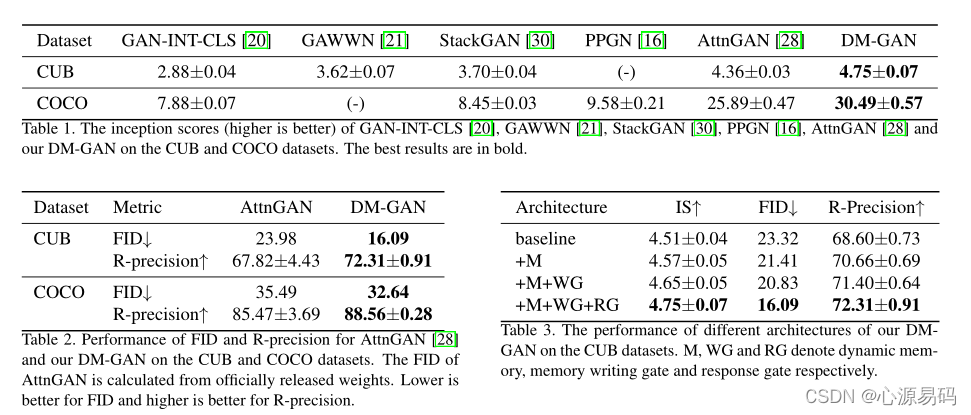
实验效果:



六、注意力与动态记忆

如上图,可视化了AttnGAN和DM-GAN选择的最相关的单词。注意到,当初始图像没有很好地生成时,注意机制无法准确地选择相关单词。
而本方法基于全局图像特征的动态存储模块来选择最相关的单词。如图6(a)所示,尽管生成了具有不正确红色胸脯的鸟,但动态存储器模块选择单词,即“白色”来校正图像。
DM-GAN在两个步骤中选择并组合单词信息和图像特征(参见图6(b))。memory writing步骤首先粗略地选择与图像相关的单词并将它们写入记忆。然后,key addressing步骤进一步从记忆中读取更多相关单词。
扩展阅读
下一篇:CogView: Mastering Text-to-Image Generation via Transformers(通过Transformer控制文本生成图像)

- 点赞
- 收藏
- 关注作者
评论(0)