你真的会用Redis做消息队列吗

前言
说到消息队列,大家首先想到的是rabitmq, rocketmq,kafka等。这些消息队列在生产中都很成熟,但它们相对来说比较重量级。
而Redis大家通常用来当缓存使用,不过在某些场景下,redis也可作用消息队列,但我们需要了解对消息队列的要求,同时也得清楚redis作为消息队列的优缺点。下面让我们来看看如何用redis做消息队列吧。
我们对消息队列的要求
作为一个专业的消息队列,除了保证本身生产消费的速度,还应该做到以下2点:
-
消息不丢失
-
消息可堆积
一个消息队列,可拆分为3部分:生产者、队列中间件、消费者。

在消息是否丢失上,从图中我们很好分析,会出现消息丢失的地方有:
-
生产者是否会丢失;
-
队列是否会丢失;
-
消费者是否会丢失。
对于消息可堆积来说,就是因某些原因,队列中积压了大量消息,是否会影响消息队列的正常运行。
带着这些要求,我们来看看Redis能否满足吧。
redis有哪些实现队列的方式
这里总结一下,主要有3种实现方式:
-
List队列(最简单)
-
Pub/Sub模型(发布/订阅)
-
Stream(更成熟的方式)
List队列
list是我们用来实现队列最简单的方式,生产者用LPUSH发布消息,消费者通过RPOP拉取消息。
因为list底层是通过链表实现的,因此时间复杂度为O(1),在数据写入和读取速度上都能达到要求。
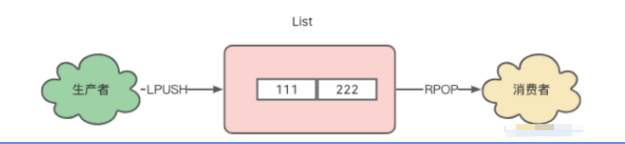
消费者在拉取消息时,需要不停的从队列拉取,伪代码如下:
while True:
data = redis_cli.rpop('queue')
if not data:
continue
# 消费数据
consume_func(data)
....
这种方式有个最大的问题,当队列为空的时候,消费者也得不停的去获取消息,会造成cpu资源的浪费。当然我们可以在队列为空的时候休眠一点时间,这样能解决cpu的浪费问题。但是在休眠过程中,如果有新消息产生,消息的消费就会延迟。
redis有想到这个问题,所以有阻塞的拉取消息的方式:BRPOP / BLPOP。这种方式可阻塞拉取消息,使用时可传入【超时时间】,若设置为0,表示不设置超时,直到有新消息才返回。设置大于0时,会在超时时间到后返回null。
while True:
# 没有消息就阻塞,0是表示不设置超时时间
data = redis.brpop('queue', 0)
if not data:
continue
# 有数据就消费
consume_func(data)
这种方式可解决cpu空转的浪费问题,也能解决消息处理延迟的问题。但是也得看到它的缺点:
-
不支持重复消费:数据pop之后就删除了,不能被其他消费者再次消费;
-
消息丢失的问题:消费者拉取消息后,如果还没被处理消费者就宕机了,消息就会丢失无法找回。
Pub/Sub模型(发布/订阅)
这是Redis为发布/订阅模式设计出来的,它解决了list不能重复消费的问题。
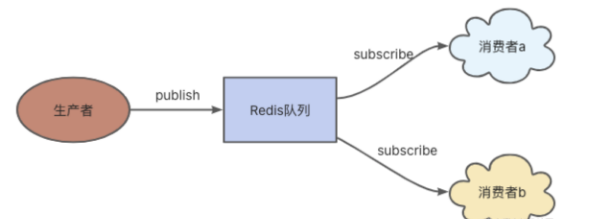
生产者通过publish命令发布消息, 消费者通过subscribe订阅生产者的数据。并且支持多个消费者订阅同一个生产者,这就能满足重复消费的问题了。
我们来总结一下这种模式的优缺点,优点就是支持多组生产者、消费者处理消息。缺点就是容易丢失数据。主要体现以下几个情况:
-
消费者下线
-
redis宕机
-
大量消息的堆积
Pub/Sub的实现不基于任何数据类型,没有做数据存储。它为生产者和消费者建立一个数据的通道,这个过程都是实时转发。如果消费者异常了,等它恢复后,只能接收新消息,异常期间的消息就丢失了。
再看看消息堆积的问题,当消费者处理消息的速度跟不上生产者时,就容易导致数据堆积的情况。Pub/Sub在消息堆积时,可能会直接导致消息丢失和消费失败。
每个消费者订阅一个队列时,Redis 都会在 Server 上给这个消费者在分配一个「缓冲区」,这个缓冲区其实就是一块内存。当数据超过了缓冲区的上限,redis就会丢失数据。
Stream队列
Stream是通过XADD和XREAD完成生产和消费动作。发布消息(【*】表示自动生成唯一的消息ID):
127.0.0.1:6379> XADD queue * city shenzhen
"1663923811780-0"
127.0.0.1:6379> XADD queue * city shanghai
"1663923819051-0"
消费者拉取数据
# 从头拉取10条信息, 0-0意思是从头开始取
127.0.0.1:6379> XREAD COUNT 10 STREAMS queue 0-0
1) 1) "queue"
2) 1) 1) "1663924206724-0"
2) 1) "city"
2) "shenzhen"
2) 1) "1663924209183-0"
2) 1) "city"
2) "shanghai"
如果想继续拉取消息,传入上一条消息的ID。没有消息就返回nil。
127.0.0.1:6379> XREAD COUNT 10 STREAMS queue 1663924209183-0
(nil)
Stream解决队列问题的方式:
-
阻塞式拉取消息
在拉取消息时,增加BLOCK参数
# BLOCK 0 表示阻塞直到有消息才返回。
127.0.0.1:6379> XREAD COUNT 10 BLOCK 0 STREAMS queue 1663924209183-0
-
发布/订阅模式
-
XGROUP:创建消费者组
-
XREADGROUP:在指定消费组下,开启消费者拉取消息
示例: 生产者发布消息
127.0.0.1:6379> XADD queue * city shenzhen
"1663924206724-0"
127.0.0.1:6379> XADD queue * city shanghai
"1663924209183-0"
假设有2组消费者要处理这批数据,创建2个消费者组:
127.0.0.1:6379> XGROUP CREATE queue group1 0-0
OK
127.0.0.1:6379> XGROUP CREATE queue group2 0-0
OK
消费者组创建好之后,我们可以给每个「消费者组」下面挂一个「消费者」,让它们分别处理同一批数据。
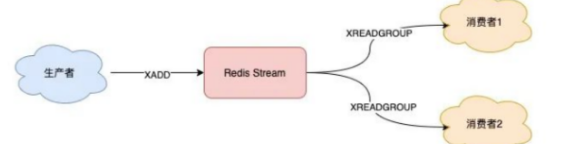
-
消息异常的情况,保证数据不丢失,支持重新消费。当一组消费者处理完消息后,需要执行 XACK 命令告知 Redis,这时 Redis 就会把这条消息标记为「处理完成」。如果故障就不会发出XACK命令,队列还是会保留信息,等重新上线后,消费者就会重新消费这些信息。
-
stream会将数据写入到redis日志Stream 是新增加的数据类型,它与其它数据类型一样,每个写操作,也都会写入到 RDB 和 AOF 中。
-
消息堆积的处理在发布消息时,你可以指定队列的最大长度,防止队列积压导致内存爆炸。
# MAXLEN设置队列的最大长度
127.0.0.1:6379> XADD queue MAXLEN 50000 * city shenzhen
"1663925399841-0"
当消息积压超过MAXLEN时,数据还是有可能丢失。
小结
redis有3种方式实现消息队列,list是最简单常用的方式,但不支持重复消费;Pub/Sub模式是发布/订阅模型,支持重复消费,但是容易丢数据;而Stream是一种新的队列实现方式,它支持消费订阅,也有数据持久化的做法,但是解决消息积压问题时,还是会丢数据。
我们在选择消息队列时,要根据自身的需要去选择。如果允许少部分的数据丢失,redis是符合选型要求的。但如果对消息的可靠性要求很高,建议使用专业的消息队列如kafka。

- 点赞
- 收藏
- 关注作者
评论(0)