快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化

相关文章:
1.快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化
2.快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型
3.快递单信息抽取【三】–五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务
1)PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练
2)PaddleNLP–UIE(二)–小样本快速提升性能(含doccona标注)
!强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录
本项目连接:
https://aistudio.baidu.com/aistudio/projectdetail/4156802?contributionType=1
快递单中抽取关键信息
数据集链接:https://download.csdn.net/download/sinat_39620217/85521580
主要介绍:
- PaddleNLP中的网络层BiGRU、CRF、ViterbiDecoder。
- 通过
paddlenlp.embedding的功能,热启动加载中文词向量,提升效果 - 评价指标
paddlenlp.metrics.ChunkEvaluator
PART A. 背景介绍
A.1 快递单信息抽取任务
如何从物流信息中抽取想要的关键信息呢?我们首先要定义好需要抽取哪些字段。
比如现在拿到一个快递单,可以作为我们的模型输入,例如“张三18625584663广东省深圳市南山区学府路东百度国际大厦”,那么序列标注模型的目的就是识别出其中的“张三”为人名(用符号 P 表示),“18625584663”为电话名(用符号 T 表示),“广东省深圳市南山区百度国际大厦”分别是 1-4 级的地址(分别用 A1~A4 表示,可以释义为省、市、区、街道)。
这是一个典型的命名实体识别(Named Entity Recognition,NER)场景,各实体类型及相应符号表示见下表:
| 抽取实体/字段 | 符号 | 抽取结果 |
|---|---|---|
| 姓名 | P | 张三 |
| 电话 | T | 18625584663 |
| 省 | A1 | 广东省 |
| 市 | A2 | 深圳市 |
| 区 | A3 | 南山区 |
| 详细地址 | A4 | 百度国际大厦 |
A.2 序列标注模型
我们可以用序列标注模型来解决快递单的信息抽取任务,下面具体介绍一下序列标注模型。
在序列标注任务中,一般会定义一个标签集合,来表示所以可能取到的预测结果。在本案例中,针对需要被抽取的“姓名、电话、省、市、区、详细地址”等实体,标签集合可以定义为:
label = {P-B, P-I, T-B, T-I, A1-B, A1-I, A2-B, A2-I, A3-B, A3-I, A4-B, A4-I, O}
每个标签的定义分别为:
| 标签 | 定义 |
|---|---|
| P-B | 姓名起始位置 |
| P-I | 姓名中间位置或结束位置 |
| T-B | 电话起始位置 |
| T-I | 电话中间位置或结束位置 |
| A1-B | 省份起始位置 |
| A1-I | 省份中间位置或结束位置 |
| A2-B | 城市起始位置 |
| A2-I | 城市中间位置或结束位置 |
| A3-B | 县区起始位置 |
| A3-I | 县区中间位置或结束位置 |
| A4-B | 详细地址起始位置 |
| A4-I | 详细地址中间位置或结束位置 |
| O | 无关字符 |
注意每个标签的结果只有 B、I、O 三种,这种标签的定义方式叫做 BIO 体系,也有稍麻烦一点的 BIESO 体系,这里不做展开。其中 B 表示一个标签类别的开头,比如 P-B 指的是姓名的开头;相应的,I 表示一个标签的延续。
对于句子“张三18625584663广东省深圳市南山区百度国际大厦”,每个汉字及对应标签为:

注意到“张“,”三”在这里表示成了“P-B” 和 “P-I”,“P-B”和“P-I”合并成“P” 这个标签。这样重新组合后可以得到以下信息抽取结果:
| 张三 | 18625584663 | 广东省 | 深圳市 | 南山区 | 百度国际大厦 |
|---|---|---|---|---|---|
| P | T | A1 | A2 | A3 | A4 |
PART B. 相关算法简介
B.1 门控循环单元GRU(Gate Recurrent Unit)
BIGRU是一种经典的循环神经网络(RNN,Recurrent Neural Network),前面一些步骤基本是把该模型当做是黑盒子来用,这里我们重点解释下其概念和相关原理。一个 RNN 的示意图如下所示,
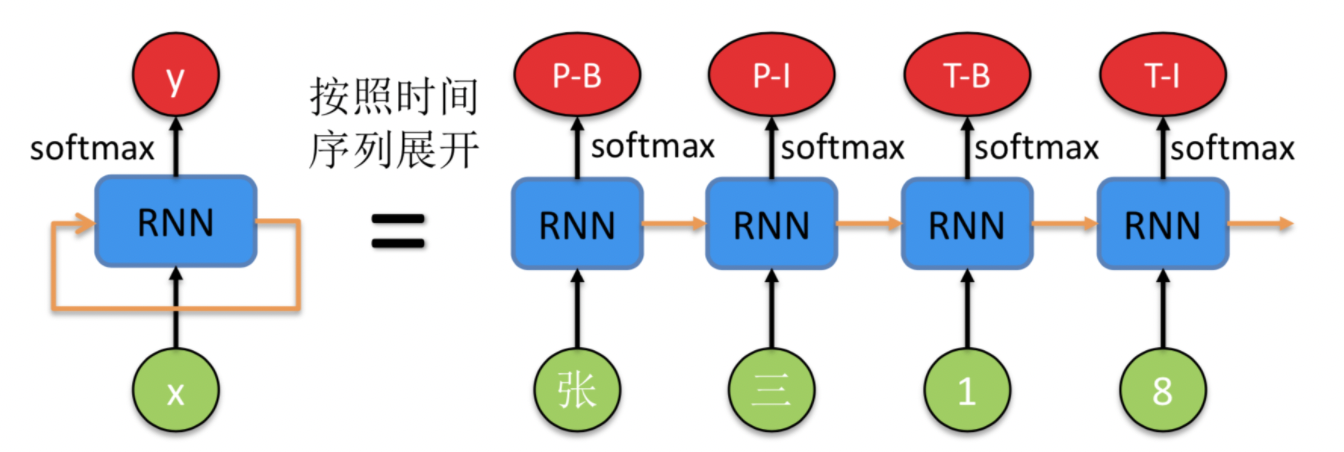
左边是原始的 RNN,可以看到绿色的点代码输入 x,红色的点代表输出 y,中间的蓝色是 RNN 模型部分。橙色的箭头由自身指向自身,表示 RNN 的输入来自于上时刻的输出,这也是为什么名字中带有循环(Recurrent)这个词。
右边是按照时间序列展开的示意图,注意到蓝色的 RNN 模块是同一个,只不过在不同的时刻复用了。这时候能够清晰地表示序列标注模型的输入输出。
GRU为了解决长期记忆和反向传播中梯度问题而提出来的,和LSTM一样能够有效对长序列建模,且GRU训练效率更高。
B.2 条件随机场CRF(Conditional Random Fields)
长句子的问题解决了,序列标注任务的另外一个问题也亟待解决,即标签之间的依赖性。举个例子,我们预测的标签一般不会出现 P-B,T-I 并列的情况,因为这样的标签不合理,也无法解析。无论是 RNN 还是 LSTM 都只能尽量不出现,却无法从原理上避免这个问题。下面要提到的条件随机场(CRF,Conditional Random Field)却很好的解决了这个问题。
条件随机场这个模型属于概率图模型中的无向图模型,这里我们不做展开,只直观解释下该模型背后考量的思想。一个经典的链式 CRF 如下图所示,
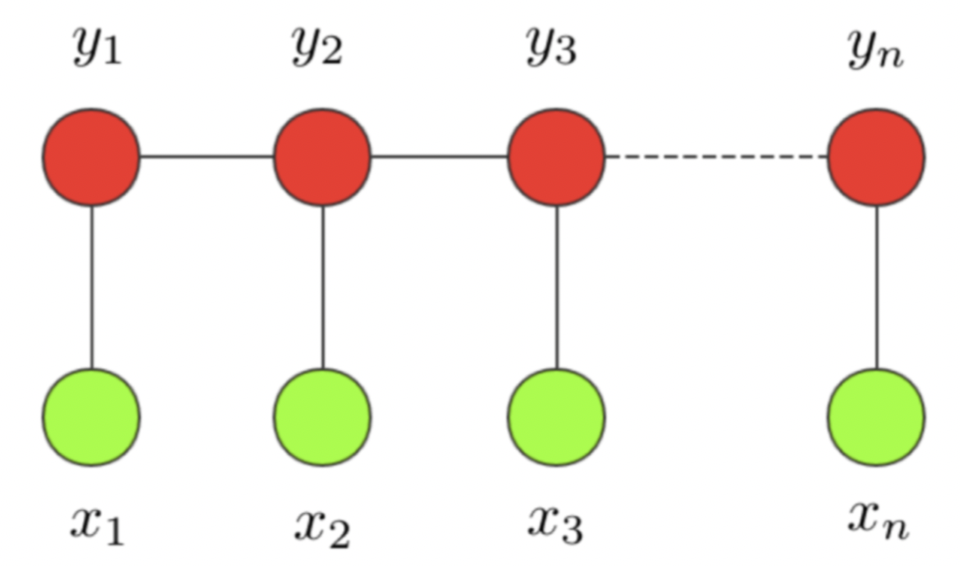
CRF 本质是一个无向图,其中绿色点表示输入,红色点表示输出。点与点之间的边可以分成两类,一类是 与 之间的连线,表示其相关性;另一类是相邻时刻的 之间的相关性。也就是说,在预测某时刻 时,同时要考虑相邻的标签解决。当 CRF 模型收敛时,就会学到类似 P-B 和 T-I 作为相邻标签的概率非常低。
PART C. 代码实践
!pip install --upgrade paddlenlp
import paddle
import paddle.nn as nn
import paddlenlp
from paddlenlp.datasets import MapDataset
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.layers import LinearChainCrf, ViterbiDecoder, LinearChainCrfLoss
from paddlenlp.metrics import ChunkEvaluator
C.1 数据准备
为了训练序列标注模型,一般需要准备三个数据集:训练集train.txt、验证集dev.txt、测试集test.txt。数据集存放在data目录中。
- 训练集,用来训练模型参数的数据集,模型直接根据训练集来调整自身参数以获得更好的分类效果。
- 验证集,用于在训练过程中检验模型的状态,收敛情况。验证集通常用于调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。
- 测试集,用来计算模型的各项评估指标,验证模型泛化能力。
此外,序列标注模型还依赖以下词典数据,词典数据存放在conf目录中。
- 输入文本词典word.dic
- 对输入文本中特殊字符进行转换的词典q2b.dic
- 标记标签的词典tag.dic
这里我们提供一份已标注的快递单关键信息数据集。训练使用的数据也可以由大家自己组织数据。数据格式除了第一行是 text_a\tlabel 固定的开头,后面的每行数据都是由两列组成,以制表符分隔,第一列是 utf-8 编码的中文文本,以 \002 分割,第二列是对应每个字的标注,以 \002 分割。
数据集及词典数据的目录结构如下:
在训练和预测阶段,我们都需要进行原始数据的预处理,具体处理工作包括:
- 从原始数据文件中抽取出句子和标签,构造句子序列和标签序列
- 将句子序列中的特殊字符进行转换
- 依据词典获取词对应的id索引
看一下训练集
训练集中除第一行是 text_a\tlabel,后面的每行数据都是由两列组成,以制表符分隔,第一列是 utf-8 编码的中文文本,以 \002 分割,第二列是对应序列标注的结果,以 \002 分割。
1.1下载并解压数据集
from paddle.utils.download import get_path_from_url
URL = "https://paddlenlp.bj.bcebos.com/paddlenlp/datasets/waybill.tar.gz"
get_path_from_url(URL,"./")
for i, line in enumerate(open('data/train.txt')):
if 0 < i < 5:
print ('%d: ' % i, line.split()[0])
print (' ', line.split()[1])
1: 16620200077宣荣嗣甘肃省白银市会宁县河畔镇十字街金海超市西行50米
T-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IP-BP-IP-IA1-BA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-IA4-I
2: 13552664307姜骏炜云南省德宏傣族景颇族自治州盈江县平原镇蜜回路下段
T-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IP-BP-IP-IA1-BA1-IA1-IA2-BA2-IA2-IA2-IA2-IA2-IA2-IA2-IA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IA4-IA4-I
3: 内蒙古自治区赤峰市阿鲁科尔沁旗汉林西街路南13701085390那峥
A1-BA1-IA1-IA1-IA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA3-IA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IT-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IP-BP-I
4: 广东省梅州市大埔县茶阳镇胜利路13601328173张铱
A1-BA1-IA1-IA2-BA2-IA2-IA3-BA3-IA3-IA4-BA4-IA4-IA4-IA4-IA4-IT-BT-IT-IT-IT-IT-IT-IT-IT-IT-IT-IP-BP-I
继承paddle.io.Dataset自定义数据集
def convert_tokens_to_ids(tokens, vocab, oov_token=None):
token_ids = []
oov_id = vocab.get(oov_token) if oov_token else None
for token in tokens:
token_id = vocab.get(token, oov_id)
token_ids.append(token_id)
return token_ids
def load_dict(dict_path):
vocab = {}
i = 0
for line in open(dict_path, 'r', encoding='utf-8'):
key = line.strip('\n')
vocab[key] = i
i += 1
return vocab
def load_dataset(datafiles):
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as fp:
next(fp)
for line in fp.readlines():
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
yield words, labels
if isinstance(datafiles, str):
return MapDataset(list(read(datafiles)))
elif isinstance(datafiles, list) or isinstance(datafiles, tuple):
return [MapDataset(list(read(datafile))) for datafile in datafiles]
train_ds, dev_ds, test_ds = load_dataset(datafiles=('data/train.txt', 'data/dev.txt', 'data/test.txt'))
label_vocab = load_dict('./data/tag.dic')
word_vocab = load_dict('./data/word.dic')
def convert_example(example):
tokens, labels = example
token_ids = convert_tokens_to_ids(tokens, word_vocab, 'OOV')
label_ids = convert_tokens_to_ids(labels, label_vocab, 'O')
return token_ids, len(token_ids), label_ids
train_ds.map(convert_example)
dev_ds.map(convert_example)
test_ds.map(convert_example)
1.2构造数据加载器–dataloder
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=word_vocab.get('OOV')), # token_ids
Stack(), # seq_len
Pad(axis=0, pad_val=label_vocab.get('O')) # label_ids
): fn(samples)
train_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_size=32,
shuffle=True,
drop_last=True,
return_list=True,
collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_size=32,
drop_last=True,
return_list=True,
collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_size=32,
drop_last=True,
return_list=True,
collate_fn=batchify_fn)
C.2 网络构建
随着深度学习的发展,目前主流的序列化标注任务基于词向量(word embedding)进行表示学习。下面介绍模型的整体训练流程如下,
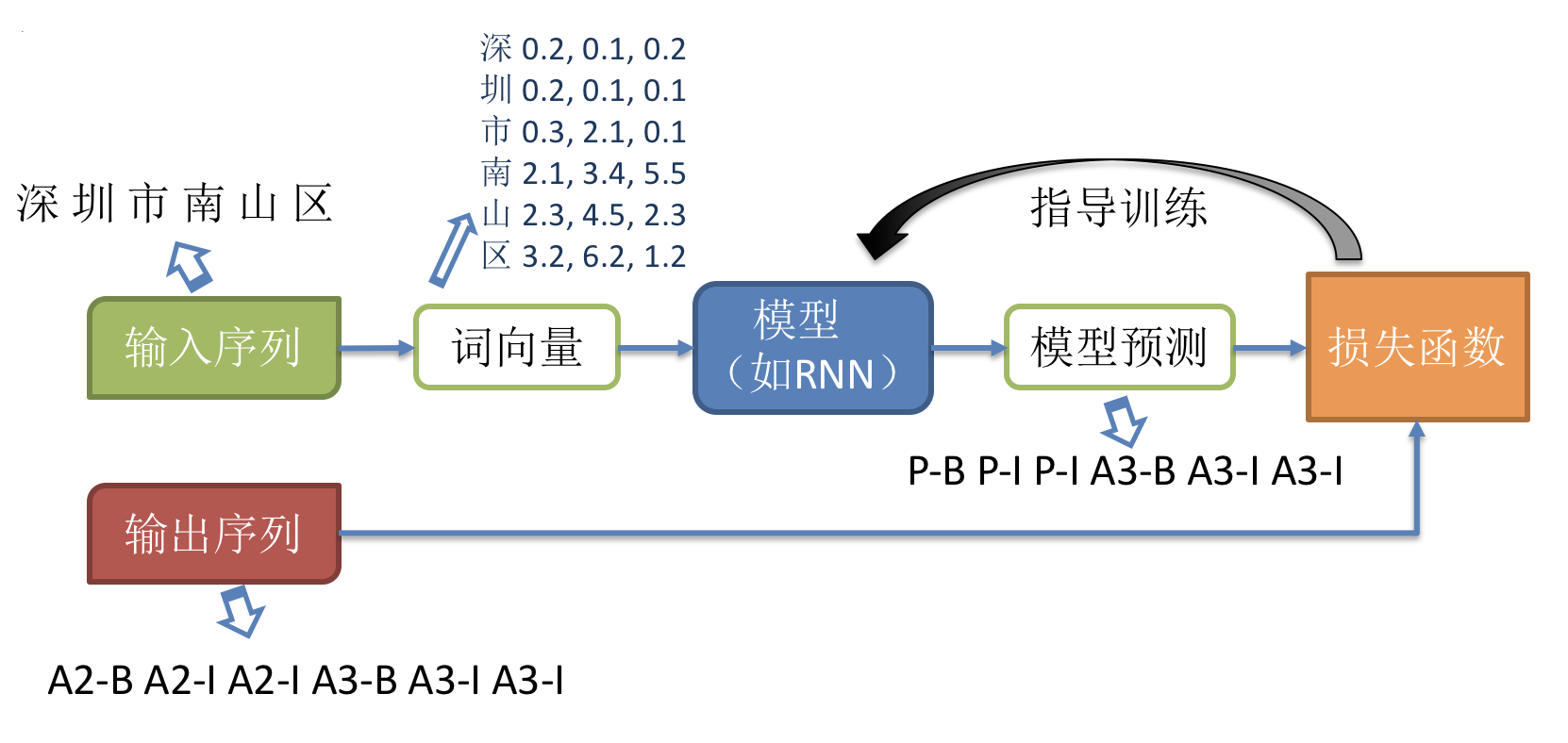
序列标注任务常用的模型是RNN+CRF。GRU和LSTM都是常用的RNN单元。这里我们以Bi-GRU+CRF模型为例,介绍如何使用 PaddlePaddle 定义序列化标注任务的网络结构。如下图所示,GRU的输出可以作为 CRF 的输入,最后 CRF 的输出作为模型整体的预测结果。
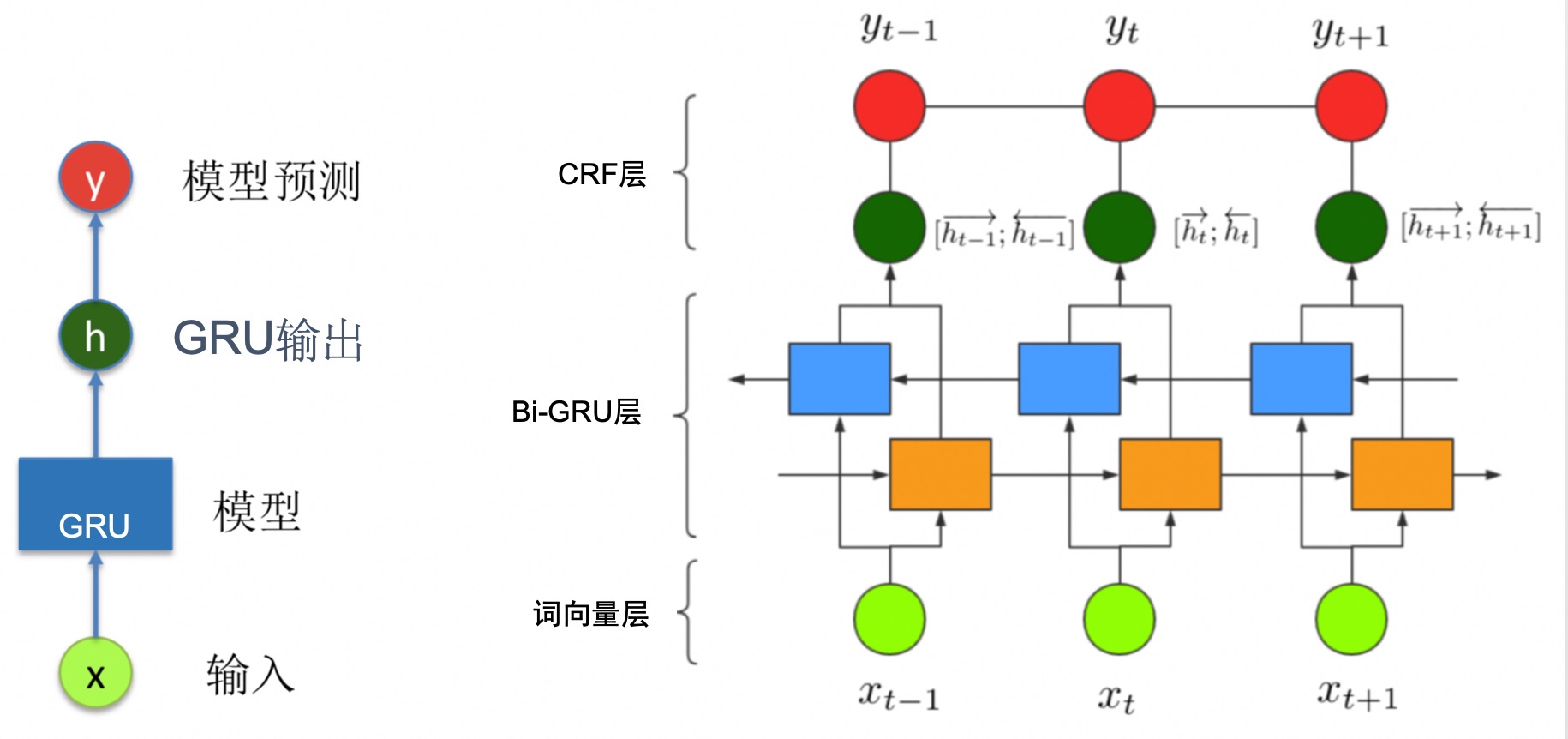
class BiGRUWithCRF(nn.Layer):
def __init__(self,
emb_size,
hidden_size,
word_num,
label_num,
use_w2v_emb=False):
super(BiGRUWithCRF, self).__init__()
if use_w2v_emb:
self.word_emb = TokenEmbedding(
extended_vocab_path='./conf/word.dic', unknown_token='OOV')
else:
self.word_emb = nn.Embedding(word_num, emb_size)
self.gru = nn.GRU(emb_size,
hidden_size,
num_layers=2,
direction='bidirectional')
self.fc = nn.Linear(hidden_size * 2, label_num + 2) # BOS EOS
self.crf = LinearChainCrf(label_num)
self.decoder = ViterbiDecoder(self.crf.transitions)
def forward(self, x, lens):
embs = self.word_emb(x)
output, _ = self.gru(embs)
output = self.fc(output)
_, pred = self.decoder(output, lens)
return output, lens, pred
# Define the model netword and its loss
network = BiGRUWithCRF(300, 300, len(word_vocab), len(label_vocab))
model = paddle.Model(network)
C.3 网络配置
定义网络结构后,需要配置优化器、损失函数、评价指标。
3.1 评价指标
针对每条序列样本的预测结果,序列标注任务将预测结果按照语块(chunk)进行结合并进行评价。评价指标通常有 Precision、Recall 和 F1。
- Precision,精确率,也叫查准率,由模型预测正确的个数除以模型总的预测的个数得到,关注模型预测出来的结果准不准
- Recall,召回率,又叫查全率, 由模型预测正确的个数除以真实标签的个数得到,关注模型漏了哪些东西
- F1,综合评价指标,计算公式如下, ,同时考虑 Precision 和 Recall ,是 Precision 和 Recall 的折中。
paddlenlp.metrics中集成了ChunkEvaluator评价指标,并逐步丰富中,
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
crf_loss = LinearChainCrfLoss(network.crf)
chunk_evaluator = ChunkEvaluator(label_list=label_vocab.keys(), suffix=True)
model.prepare(optimizer, crf_loss, chunk_evaluator)
C.4 模型训练
model.fit(train_data=train_loader,
eval_data=dev_loader,
epochs=1,
save_dir='./results',
log_freq=1)
step 1/50 - loss: 93.9603 - precision: 0.0000e+00 - recall: 0.0000e+00 - f1: 0.0000e+00 - 20s/step
step 2/50 - loss: 67.9459 - precision: 0.0000e+00 - recall: 0.0000e+00 - f1: 0.0000e+00 - 29s/step
step 3/50 - loss: 75.6676 - precision: 0.0000e+00 - recall: 0.0000e+00 - f1: 0.0000e+00 - 30s/step
step 4/50 - loss: 68.9331 - precision: 0.0000e+00 - recall: 0.0000e+00 - f1: 0.0000e+00 - 30s/step
step 5/50 - loss: 71.4498 - precision: 0.0000e+00 - recall: 0.0000e+00 - f1: 0.0000e+00 - 29s/step
step 6/50 - loss: 70.4924 - precision: 0.0000e+00 - recall: 0.0000e+00 - f1: 0.0000e+00 - 28s/step
step 7/50 - loss: 64.0684 - precision: 0.0145 - recall: 0.0172 - f1: 0.0157 - 27s/step
step 8/50 - loss: 59.8829 - precision: 0.0253 - recall: 0.0287 - f1: 0.0269 - 27s/step
step 9/50 - loss: 81.7906 - precision: 0.0368 - recall: 0.0400 - f1: 0.0383 - 27s/step
step 10/50 - loss: 57.3128 - precision: 0.0462 - recall: 0.0480 - f1: 0.0471 - 26s/step
step 11/50 - loss: 58.4151 - precision: 0.0521 - recall: 0.0517 - f1: 0.0519 - 27s/step
step 12/50 - loss: 53.0237 - precision: 0.0522 - recall: 0.0496 - f1: 0.0508 - 27s/step
step 13/50 - loss: 50.7157 - precision: 0.0535 - recall: 0.0486 - f1: 0.0509 - 27s/step
step 14/50 - loss: 74.4160 - precision: 0.0550 - recall: 0.0477 - f1: 0.0511 - 27s/step
step 15/50 - loss: 53.2660 - precision: 0.0550 - recall: 0.0459 - f1: 0.0501 - 28s/step
step 16/50 - loss: 53.1404 - precision: 0.0542 - recall: 0.0440 - f1: 0.0486 - 28s/step
step 17/50 - loss: 42.8168 - precision: 0.0512 - recall: 0.0421 - f1: 0.0462 - 28s/step
step 18/50 - loss: 41.4843 - precision: 0.0489 - recall: 0.0418 - f1: 0.0451 - 28s/step
step 19/50 - loss: 33.4017 - precision: 0.0520 - recall: 0.0462 - f1: 0.0489 - 27s/step
step 20/50 - loss: 49.4797 - precision: 0.0556 - recall: 0.0512 - f1: 0.0533 - 28s/step
step 21/50 - loss: 32.3158 - precision: 0.0579 - recall: 0.0547 - f1: 0.0563 - 28s/step
step 22/50 - loss: 27.5900 - precision: 0.0588 - recall: 0.0570 - f1: 0.0579 - 28s/step
step 23/50 - loss: 49.3031 - precision: 0.0605 - recall: 0.0593 - f1: 0.0599 - 28s/step
step 24/50 - loss: 26.1740 - precision: 0.0626 - recall: 0.0618 - f1: 0.0622 - 28s/step
step 25/50 - loss: 20.6553 - precision: 0.0639 - recall: 0.0640 - f1: 0.0639 - 28s/step
step 26/50 - loss: 23.3890 - precision: 0.0632 - recall: 0.0646 - f1: 0.0639 - 28s/step
step 27/50 - loss: 35.1492 - precision: 0.0661 - recall: 0.0688 - f1: 0.0674 - 28s/step
step 28/50 - loss: 21.9309 - precision: 0.0696 - recall: 0.0734 - f1: 0.0714 - 29s/step
step 29/50 - loss: 31.2896 - precision: 0.0719 - recall: 0.0766 - f1: 0.0742 - 29s/step
step 30/50 - loss: 27.9382 - precision: 0.0776 - recall: 0.0833 - f1: 0.0803 - 29s/step
step 31/50 - loss: 16.3336 - precision: 0.0837 - recall: 0.0902 - f1: 0.0868 - 29s/step
step 32/50 - loss: 19.7823 - precision: 0.0920 - recall: 0.0993 - f1: 0.0955 - 29s/step
step 33/50 - loss: 18.2621 - precision: 0.0978 - recall: 0.1055 - f1: 0.1015 - 29s/step
step 34/50 - loss: 13.6537 - precision: 0.1074 - recall: 0.1158 - f1: 0.1114 - 30s/step
step 35/50 - loss: 13.4816 - precision: 0.1142 - recall: 0.1229 - f1: 0.1184 - 30s/step
step 36/50 - loss: 13.9093 - precision: 0.1216 - recall: 0.1309 - f1: 0.1261 - 30s/step
step 37/50 - loss: 13.3039 - precision: 0.1296 - recall: 0.1394 - f1: 0.1343 - 30s/step
step 38/50 - loss: 15.2145 - precision: 0.1367 - recall: 0.1470 - f1: 0.1417 - 30s/step
step 39/50 - loss: 21.4867 - precision: 0.1389 - recall: 0.1493 - f1: 0.1439 - 30s/step
step 40/50 - loss: 9.0086 - precision: 0.1424 - recall: 0.1531 - f1: 0.1476 - 30s/step
step 41/50 - loss: 19.1487 - precision: 0.1506 - recall: 0.1619 - f1: 0.1560 - 29s/step
step 42/50 - loss: 10.9948 - precision: 0.1602 - recall: 0.1721 - f1: 0.1660 - 29s/step
step 43/50 - loss: 7.8162 - precision: 0.1690 - recall: 0.1816 - f1: 0.1751 - 29s/step
step 44/50 - loss: 7.6951 - precision: 0.1747 - recall: 0.1882 - f1: 0.1812 - 29s/step
step 45/50 - loss: 10.1926 - precision: 0.1795 - recall: 0.1934 - f1: 0.1862 - 29s/step
step 46/50 - loss: 10.8787 - precision: 0.1842 - recall: 0.1986 - f1: 0.1911 - 29s/step
step 47/50 - loss: 17.8871 - precision: 0.1899 - recall: 0.2047 - f1: 0.1970 - 29s/step
step 48/50 - loss: 6.0537 - precision: 0.1985 - recall: 0.2139 - f1: 0.2059 - 29s/step
step 49/50 - loss: 13.4652 - precision: 0.2067 - recall: 0.2224 - f1: 0.2143 - 29s/step
step 50/50 - loss: 4.7774 - precision: 0.2127 - recall: 0.2292 - f1: 0.2206 - 29s/step
save checkpoint at /home/aistudio/results/0
Eval begin...
step 1/6 - loss: 9.7892 - precision: 0.5659 - recall: 0.6170 - f1: 0.5903 - 22s/step
step 2/6 - loss: 9.2197 - precision: 0.5596 - recall: 0.6053 - f1: 0.5815 - 21s/step
step 3/6 - loss: 3.7284 - precision: 0.5744 - recall: 0.6217 - f1: 0.5971 - 22s/step
step 4/6 - loss: 6.9872 - precision: 0.5669 - recall: 0.6115 - f1: 0.5884 - 21s/step
step 5/6 - loss: 12.2052 - precision: 0.5749 - recall: 0.6195 - f1: 0.5964 - 21s/step
step 6/6 - loss: 20.2966 - precision: 0.5668 - recall: 0.6114 - f1: 0.5882 - 21s/step
Eval samples: 192
save checkpoint at /home/aistudio/results/final
B.5 模型评估
调用model.evaluate,查看序列化标注模型在测试集(test.txt)上的评测结果。
model.evaluate(eval_data=test_loader, log_freq=1)
{'loss': [11.092163],
'precision': 0.5285481239804242,
'recall': 0.5654450261780105,
'f1': 0.5463743676222597}
B.6 预测
利用已有模型,可在未知label的数据集(此处复用测试集test.txt)上进行预测,得到模型预测结果及各label的概率。
def parse_decodes(ds, decodes, lens, label_vocab):
decodes = [x for batch in decodes for x in batch]
lens = [x for batch in lens for x in batch]
id_label = dict(zip(label_vocab.values(), label_vocab.keys()))
outputs = []
for idx, end in enumerate(lens):
sent = ds.data[idx][0][:end]
tags = [id_label[x] for x in decodes[idx][:end]]
sent_out = []
tags_out = []
words = ""
for s, t in zip(sent, tags):
if t.endswith('-B') or t == 'O':
if len(words):
sent_out.append(words)
tags_out.append(t.split('-')[0])
words = s
else:
words += s
if len(sent_out) < len(tags_out):
sent_out.append(words)
outputs.append(''.join(
[str((s, t)) for s, t in zip(sent_out, tags_out)]))
return outputs
outputs, lens, decodes = model.predict(test_data=test_loader)
preds = parse_decodes(test_ds, decodes, lens, label_vocab)
print('\n'.join(preds[:5]))
Predict begin...
step 6/6 [==============================] - ETA: 39s - 10s/ste - ETA: 20s - 10s/ste - 10s/step
Predict samples: 192
('黑龙江省双鸭山市尖山', 'A1')('区八马路与东平行路交叉口北40米韦业涛', 'A4')('18600009172', 'T')
('广', 'A1')('西壮族自治区桂林市', 'A3')('雁山区', 'A4')('雁山镇西龙村老年活动中心', 'T')('17610348888', 'P')
('15652864561', 'T')('河南省开封市', 'A1')('顺', 'A3')('河回族区', 'A3')('顺河区公园路32号赵本山', 'A4')
('河', 'A1')('北省唐山市', 'A1')('玉田县', 'A3')('无终大街159号', 'A4')('18614253058', 'T')('尚汉生', 'P')
('台湾台中市', 'A1')('北区北', 'A3')('区锦新街18号', 'A4')('18511226708', 'T')('蓟丽', 'P')
PART D 优化进阶-使用预训练的词向量优化模型效果
在Baseline版本中,我们调用了paddle.nn.Embedding获取词的向量表示,有如下特点…
这里,我们调用paddlenlp.embeddings中内置的向量表示TokenEmbedding,有如下特点…
from paddlenlp.embeddings import TokenEmbedding # EMB
del model
del preds
del network
class BiGRUWithCRF2(nn.Layer):
def __init__(self,
emb_size,
hidden_size,
word_num,
label_num,
use_w2v_emb=True):
super(BiGRUWithCRF2, self).__init__()
if use_w2v_emb:
self.word_emb = TokenEmbedding(
extended_vocab_path='./data/word.dic', unknown_token='OOV')
else:
self.word_emb = nn.Embedding(word_num, emb_size)
self.gru = nn.GRU(emb_size,
hidden_size,
num_layers=2,
direction='bidirectional')
self.fc = nn.Linear(hidden_size * 2, label_num + 2) # BOS EOS
self.crf = LinearChainCrf(label_num)
self.decoder = ViterbiDecoder(self.crf.transitions)
def forward(self, x, lens):
embs = self.word_emb(x)
output, _ = self.gru(embs)
output = self.fc(output)
_, pred = self.decoder(output, lens)
return output, lens, pred
network = BiGRUWithCRF2(300, 300, len(word_vocab), len(label_vocab))
model = paddle.Model(network)
optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
crf_loss = LinearChainCrfLoss(network.crf)
chunk_evaluator = ChunkEvaluator(label_list=label_vocab.keys(), suffix=True)
model.prepare(optimizer, crf_loss, chunk_evaluator)
model.fit(train_data=train_loader,
eval_data=dev_loader,
epochs=2,
save_dir='./results',
log_freq=1)
model.evaluate(eval_data=test_loader)
outputs, lens, decodes = model.predict(test_data=test_loader)
preds = parse_decodes(test_ds, decodes, lens, label_vocab)
print('\n'.join(preds[:5]))
结果展示:
step 1/50 - loss: 106.8512 - precision: 0.0000e+00 - recall: 0.0000e+00 -
Eval samples: 192
save checkpoint at /home/aistudio/results/final
Eval begin...
step 6/6 - loss: 0.0000e+00 - precision: 0.9463 - recall: 0.9686 - f1: 0.9573 - 26s/step
Eval samples: 192
{'loss': [0.0],
'precision': 0.9462915601023018,
'recall': 0.9685863874345549,
'f1': 0.9573091849935316}
模型在验证集上的f1 score较之前有明显提升。
Predict begin...
step 6/6 [==============================] - ETA: 53s - 13s/ste - ETA: 27s - 14s/ste - 14s/step
Predict samples: 192
('黑龙江省', 'A1')('双鸭山市', 'A2')('尖山区', 'A3')('八马路与东平行路交叉口北40米', 'A4')('韦业涛', 'P')('18600009172', 'T')
('广西壮族自治区', 'A1')('桂林市', 'A2')('雁山区', 'A3')('雁山镇西龙村老年活动中心', 'A4')('17610348888', 'T')('羊卓卫', 'P')
('15652864561', 'T')('河南省', 'A1')('开封市', 'A2')('顺河回族区', 'A3')('顺河区公园路32号', 'A4')('赵本山', 'P')
('河北省', 'A1')('唐山市', 'A2')('玉田县', 'A3')('无终大街159号', 'A4')('18614253058', 'T')('尚汉生', 'P')
('台湾', 'A1')('台中市', 'A2')('北区', 'A3')('北区锦新街18号', 'A4')('18511226708', 'T')('蓟丽', 'P')

- 点赞
- 收藏
- 关注作者
评论(0)