A16Z现代企业数据与AI架构,数字化转型建议

在聊AI和大数据的存储基础之前,先插播一个a16z更新的数据与AI基础设施参考架构。最近a16z的数据初创公司排名还是比较火的,可以和本篇结合起来理解,希望本文可以帮助企业数据基础设施架构师洞察未来架构基础、帮助风险投资资本识别标的的生态位置、帮助数据算法工程师系统理解业务场景中的架构配合。
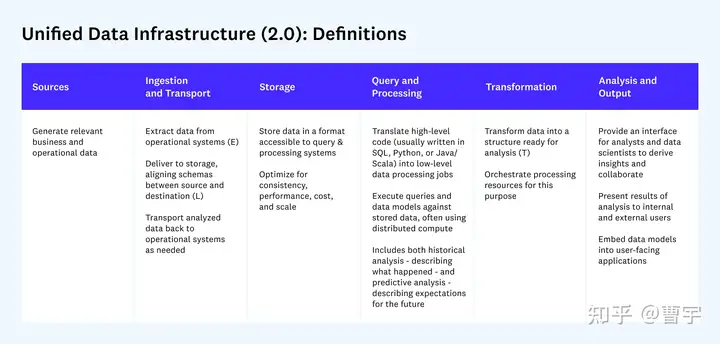
先来看看统一数据架构的流程定义,基本上都是plain English,贯彻了a16z future的务实风格,整体非常好理解。关注两点,第一个是传统的ETL流程被分成了三个部分,其中Extract和Load被放到了Ingestion&Transport部分,对比传统的ETL系统:
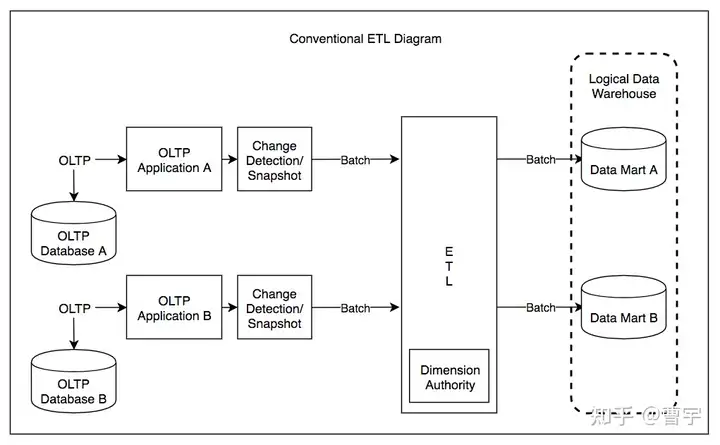
其实不难发现,传统的批量ETL概念在现代数据架构中已经被打散了。其原因既有单体ETL造成的性能瓶颈问题难以追赶数据的增长,同时也有数据驱动的AI算法对于数据处理流程的变革。整体体现了数据驱动基础设施在现代企业中的职能逐渐从记账先生转化成决策顾问,越来越多的数据应用驱动着业务反向推动架构变革。
第二点则是Query和Processing阶段中的high level语言,SQL,Python,Java/Scala,其实整体上也在反应这个领域中的用户使用习惯和相对比例。SQL毫无疑问仍然扮演者重要的角色,而Python通过庞大的ML和AI生态也逐渐超越了Java和Scala,逐渐站稳了领域地位。Java和Scala则提供了对于传统IT用户更友好的体验,借助Apache大数据ecosystem的雄厚家底继续发光发热。这也对于我们设计一个统一数据和AI基础设施提供了一个思路,从用户的使用视角来看应该如何处理好多种语言下的复杂请求,同时保持团队之间的敏捷性是一个AI架构师要考虑的问题。从程序员的角度来看,选择哪门语言入门AI大数据也可以略窥一二。
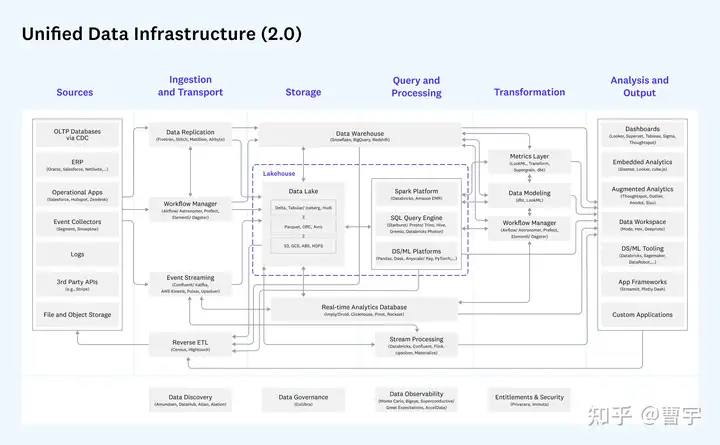
来了这么多铺垫,其实是为了更好地展示这张全景图。居于最中心的,是现在口水仗打得最多的湖、仓领域,a16z的视野中心是lakehouse,在此之上是数仓。那么看到这里,很多架构师都会开始盘算了,我到底是选哪一个呢?其实在a16z的版图里,大量的组建都是开源的,同时这些开源组件往往都会有其背后的商业公司提供其全托管的版本。国内很多云产商,供应商也提供机遇这些开源组件的商业化解决方案。如果把这些林林总总的方案加上自建方案放在一起,很可能每个组件都会有五种以上的备选项。
此时就要求架构师不能只看PPT,而是通过售前试用甚至付费PoC的方式验证这些备选方案的组合能力。通常来说,直接选择背后母公司的方案会获得最优的单体组件使用体验,不过这并不代表整体基础设施的整体体验。而使用开源组件自己拼凑,则适合拥有较大运维团队的公司,保证可以在多个开源组件快速迭代的过程中追赶上其发展速度。
在这整个版图里,大多数的组件其实是从大数据时代慢慢演进过来的,这保证了整体架构的稳定性。企业级数据基础设施架构,往往需要时间的沉淀。其中workflow起到了一头一尾串联ETL的作用,对于workflow选型感兴趣的朋友可以参阅专栏里的相关内容。另外一个很新颖组件是反向ETL,在湖仓数仓需要更多数据的情况下,反向朝数据源索取新的数据。可以理解这个组件,在功能上代替了传统在企业内网IM中找IT工程师取数的工作,交由数仓或者数据湖的使用者反向构建数据请求,提升数据共享和流转效率。
再看下Machine Learning的2.0参考架构,较最初版也做了更新,加入了feature store,query engine等内容。这里的Machine Learning其实理解成Artificial Intelligence比较合适,因为其包含的内容既有传统ML,DL也有RL等范式。AI发展到今日,除了个别惊为天人的算法横空出世,总体上要解决任何现实问题都需要用系统工程system engineering的思维去建设基础设施。
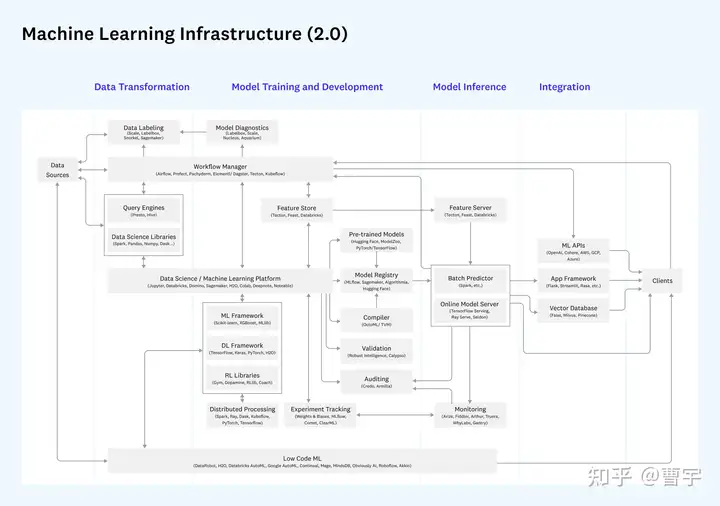
大多数已有的AI infra建设,在这个版图的一头一尾都比较弱,我们先来看一下a16z对于这两个环节的讨论,再分散展开讨论。

Data Transformation的含义是将原始数据(包括监督式学习中的标注)转换成可供模型训练的形式。时至今日的很多系统,只是将括号里的内容做了(原文后半部分)而忽视了前面的内容。对于90%以上企业都会收集的结构化和半结构化数据,处理能力非常弱,甚至需要csv喂到嘴边才可以开展后面几部分的工作。这就为算法工程师,业务工程团队,系统架构工程师都提出了挑战:是要建立两套独立的AI和大数据系统,还是在某些层面寻求这两个领域的融合呢?
融合的另外一个方面是集成,诸多AI系统等集成是高门槛与高成本的。一个昂贵的AI模型,如果离开数据,最终性能都会漂移,而这个昂贵的AI模型,如果没法被部署到当今以Java作为绝对主力的企业应用体系中,那么基础设施的实施者和算法团队都会承受很大的压力。
按照系统解耦,业务分层,资源共享的设计思路,a16z将我提到的这些问题,继续往业务目标牵引。在宏观层面,设计出两个使用场景:分析型系统(完成数据驱动决策),以及运营型系统(构建数据支持产品)可以理解在AI加入了之后,传统数据OLAP和OLTP会完成何种转身和变革。也可以理解成传统的AI以小作坊式地生产各种模型模式,如何真正融入到企业数据驱动变革中,可以想象:如果你的系统连与企业数据库都无法连接,那么模型就是一个孤零零的模型,算法也就是无尽的调包与调参。
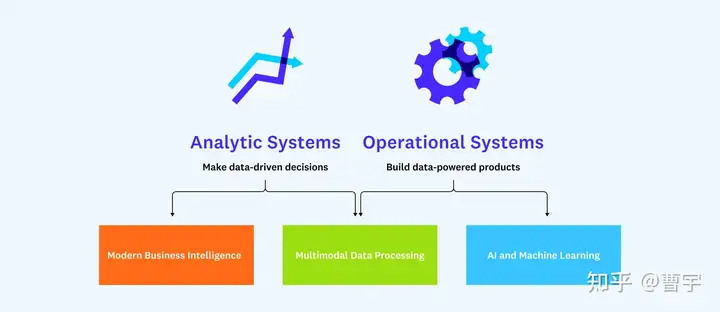
按照这两个业务模型,有三个基础设施蓝图:现代企业智能蓝图,多模态数据处理蓝图以及AI和机器学习蓝图。
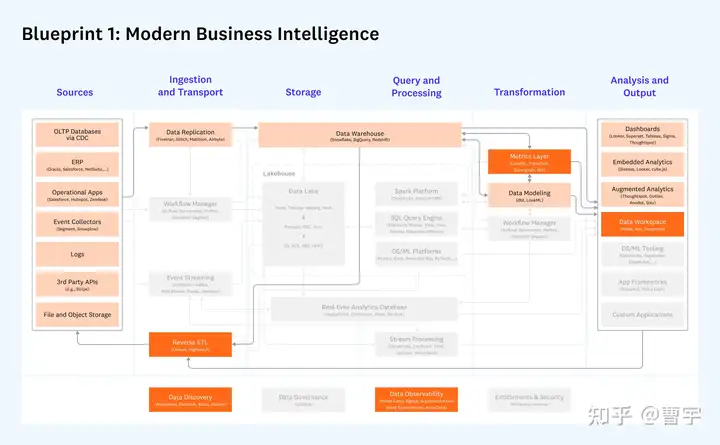
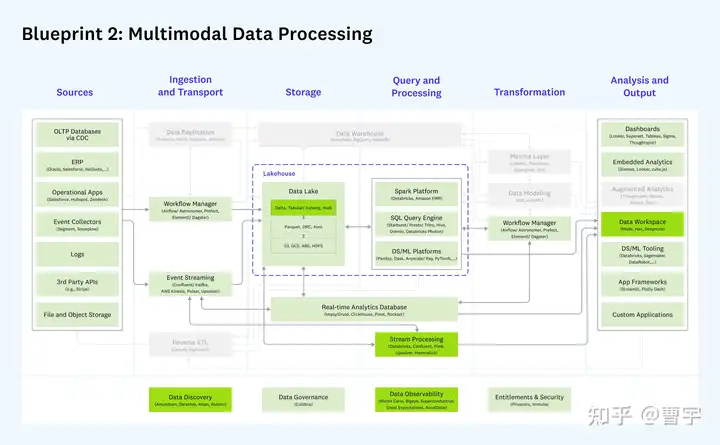
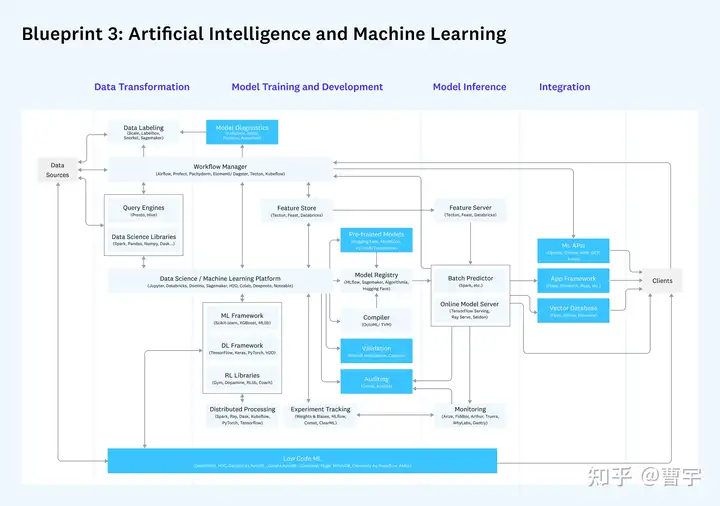
目前我主要探索的重点先是1 + 3 这种模式,可以理解成企业级数据基础设施平台加AI能力协同。企业空间市场巨大,业务直接推动能力强,但生态建设困难。主要难点在于如何在传统企业数仓的背景下,弥合python用户心智鸿沟,让CIO,CTO,算法团队,IT团队都能感受到数据推动的AI变革力,是这个方案成功的关键。而可以感受到的技术变量是:越来越多的生态软件,快速填充了原有的技术空白,企业级SaaS的日益普及让用户渐渐有了使用平台的习惯。
当然1+2的领域也会持续吸引投资,各种诸如湖仓一体,批流一体,在线离线一致等等销售名词和概念,反映出的是,实际上这个领域的用户体验其实并不好,系统维护成本奇高,应用长的千奇百怪,历史包袱沉重。解决这些问题,最好的方式还是上云,如果不能上云也要按照云化的思维去构建。
有没有1+2+3的天降神人系统?我理解这在很多超高信息化领域,如金融投资,广告推荐,智能搜索。这些系统已经通过专有系统的方案被造出来很多遍了,如果你要解决的是领域问题,最好的选择还是直接抄作业,甚至直接买服务都可以。

- 点赞
- 收藏
- 关注作者
评论(0)