AI workflow 指南,MLops看这一篇就够啦

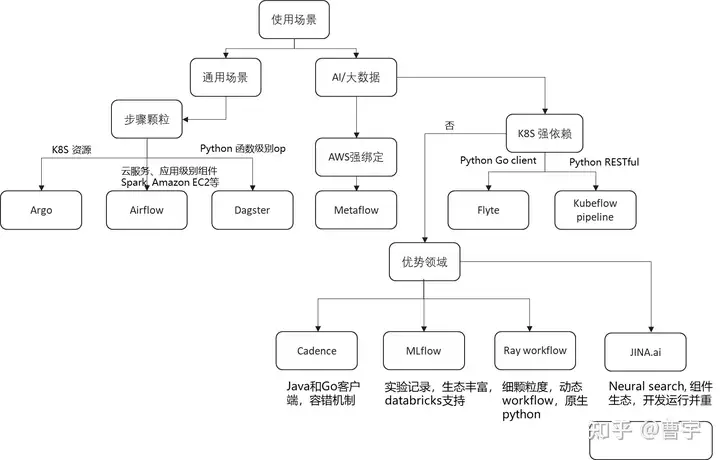
AI应用落地的过程中,越来越多的公司和组织都意识到了一个AI算法的落地,在很多场景中都是一个工程化的问题。为了将数据,算法,应用这三个AI领域的流程打通,工程师们选择了多种集成的手段,其中以workflow作为AI工程实践方法的思路上就有了图中所示的八九种workflow方案。
什么是AI workflow呢,它本质上是通过编排(orchestration)的方式,将散落的函数,微服务,数据库等组件构成的业务逻辑持久化(duration function)的过程。AI workflow既有高效编排、便捷开发、生态丰富的基础需求,同时也有直接对接业务请求的现实压力。
这些workflow既有来自于工程团队孵化的项目,如Uber的Cadence,Lyft的Flyte,Netflix的Metaflow,也有以开源社区作为主导的Apache Airflow,Argo等方案,同时按照领域细分出发的MLflow和Ray workflow分别代表了以实验记录,实验控制,细粒度控制作为主要卖点的方案,同时类似Dagster的专注编排的工具也在努力获得更多的关注。如此多的workflow产品与解决方案,给了AI工程师们的是甜蜜的烦恼:我到底应该选择使用workflow工具么,我又应该选择何种工具呢。
本文尝试了按照决策树的模式,按照2022年的workflow工具的发展现状,为各位读者做了一个梳理,希望可以帮助各位做出一个粗略的选择。本文的后半部分会对于这些workflow的设计思路以及简要使用体验做一个逐项的梳理,读者可以结合这些去在自己AI工程化的过程中做更多的实践,也欢迎向我推荐更多的有趣的AI workflow项目。
首先我们从企业主导孵化的几个项目开始来看,如果你的业务和需求和这些企业的主营业务比较相似,那么极有可能他们的workflow也是可能适合更多的探索。
Cadence
Uber和Lyft两家公司都是出行科技公司,Cadence项目相对来说出现的比Lyft要早,主要用户栈也是建立在Java和Go两种语言上的。Cadence项目所提出的初衷是基于复杂机器学习的业务流程,需要多种数据源与计算资源配合,Uber希望Cadence workflow能够提供一种容错的持久化编排能力,去帮助自身的业务团队更好地处理数据驱动的服务构建,在其use case中主要提及的场景有事件驱动的应用开发,批量作业排布,Big data & ML等领域。主要应用也包括了欺诈检测,用户行为分析等Uber的基础业务需求。
Flyte
Lyft则孵化了Flyte这个项目,相比于Cadence而言,他们想要解决的业务需求是类似的。不过技术实现手段,则有比较大的差异。简单来说就是Flyte是一个云原生的AI workflow项目,他的调度逻辑和应用生态主要聚焦在云原生领域的应用。通过与LF AI & Data Foundation的孵化,Flyte给我们的体验是通过其Python客户端书写细粒度的workflow逻辑,并且通过其Go后端高效地与k8s结合,调度并执行多种云原生应用。其动态DAG的设计,本地调测的工具,对于希望以k8s作为底座的AI+大数据用户来说是比较有吸引力的。
Metaflow
相比于前两个项目,Metaflow则是在服务Netflix的内部需求时创造出了这个项目,在其文档中的why metaflow也是非常直接一个“$?”美元从哪里来的符号表示了,metaflow是想通过端到端的AI+大数据业务流程构建,直接帮助用户做可以获得“$”的事情。做法也比较直接,计算资源除了本地之外,直接和AWS打通,目前适用于愿意在AWS上scale他们workflow的项目。
MLflow
MLflow严格意义上来说更像是一个experiement tracking的工作,不过经过用户的需求迭代,多次更新之后,在任务的编排上也具备了一定的能力。由于其背后的databricks公司,以及活跃的用户社区,在ML实验领域的很多场景都是the go-to的选项。借着其autolog的能力,顺理成章地帮助用户去做ML应用的包装,重复执行,甚至分发都是一个非常合理的场景。时至今日,如果你的应用场景是以实验作为中心的,那么MLflow是非常好的选择。如果愿意选择databricks的相关服务,那么MLflow的使用体验还能再上一个台阶。
Apache Airflow
Workflow领域有一个meme,把Apache airflow的小风车底下改成Apache fancy crontab。意思是说,这个工具本质上就是一个高级版的crontab,他能做的crontab也可以做。虽然这个meme不一定完全正确,但是却反映除了airflow的普适性,他更像是云上的crontab,把各种各样的云组件给连接起来。他的对手包括文中的其他workflow,但是仅限于一个应用领域,airflow的编排颗粒使得他成为更通用的workflow编排工具。包括但是不限于AI和大数据领域,如果你的应用满足这样的特征,airflow会是一个好的选择。通用需求多,选择airflow。
Argo
Argo也是一个通用需求的workflow产品,和airflow的区别在于Argo是以容器作为编排的粒度。原本是作为k8s的编排工作的身份出现的,你可能会问了k8s本身不就有编排功能么,为什么要再弄个Argo?因为k8s本身还是声明式的工作模式,我不是通过一步接着一步的步骤显式的操作k8s,而是通过声明最终想要系统达到的状态去让k8s自己通过观察现在的状态自我驱动到目标状态的,非常powerful却让人觉得没有控制感。为了获得这种控制感,argo又再造了DAG和step等概念,让控制欲比较强的程序员以workflow的形式操作k8s,降低心智负担。同样的,k8s通用需求多,选择argo。差异看云原生化,是直接调用服务多还是编排容器多。
Kubeflow pipeline
说道Argo就不得不提Kubeflow了,其实如果让我现在起名字,我会把kubeflow的名字给Argo。Argo的本意就是k8s的flow插件,不过历史上的命名总是先到先得,名不对题是常有的事情。Kubeflow本身其实更像是一个AI和大数据的生态体系,其中的编排部分是kubeflow pipeline。Kubeflow pipeline提供Python和RESTful的接口,如果你的组件选型和Kubeflow的生态支持匹配度搞,那么Kubeflow还是值得尝试的。
Dagster
如果要用两个词形容dagster,我会说他精致而特别。UI的质量,相比于本文的其他项目来说,完全达到了精致的标准,同时也是很特别的定位:为了生产力而创造的数据编排平台。因为Dagster的目标是这个领域的商业化产品,同时创始人也曾经创造了GraphQL项目,这都让这个项目非常特别。虽然是一个通用流程编排,dagster对于数据的关注超过了其他项目,适合愿意在技术上尝鲜的团队。
Ray workflow
Ray的workflow也是一个比较新的项目,按照最新的规划放在了Ray ML的功能部分,和Ray结合十分紧密。虽然因为发展实践比较短,但是归功于Ray的执行后端,是一个有共享内存共通的项目。这和其他项目很不一样,适合目前有一定Ray基础设施能力的团队去做一些前沿探索。
JINA.ai
JINA.ai 是一个主打Nerual Search的AI Workflow,在和其他workflow的差别主要是其对于开发与上线流程的协同能力,不需要k8s的强依赖。同时其Application的策略做的教其他workflow都更为完善,依托JINA hub的大量开源组件,可以快速地搭建以图搜图,chatbot等Neural Search的应用。
最后回到问题的本质上来,我对于Workflow的理解是有三个部分组成:编排 orchestration + 执行 execution + 应用 application。除了做好orchestration和execution两个基础之外,还需要能够满足不同的application。也正是因为这个原因Workflow被寄予了MLops承载的厚望,不过光靠workflow本身最多只能解决orchestration和部分execution的难题,application侧需要MLops更多基于领域模型的流程的优化。华为云ModelArts的workflow就是为了解决这些问题而进行研发的,敬请期待。

- 点赞
- 收藏
- 关注作者
评论(0)