【论文阅读】Improved Deep Embedded Clustering with Local Structure Pre

@TOC

简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
【每日一读】每天浅读一篇论文,了解专业前沿知识,培养阅读习惯(阅读记录 仅供参考)
论文简介
原文链接:https://www.ijcai.org/proceedings/2017/243
会议:IJCAI International Joint Conferences on Artificial Intelligence Organization (CCF A类)
年度:2027年(发表日期)
Abstract
深度聚类使用神经网络学习有利于聚类任务的深度特征表示。一些开创性的工作建议通过明确定义面向聚类的损失来同时学习嵌入式特征和执行聚类。
尽管已经在各种应用中证明了有希望的性能,但我们观察到这些工作忽略了一个重要因素,即定义的聚类损失可能会破坏特征空间,从而导致非代表性的无意义特征,进而损害聚类性能。
为了解决这个问题,在本文中,我们提出了改进的深度嵌入式聚类(IDEC)算法来处理数据结构的保存。具体来说,我们使用聚类损失作为指导来操纵特征空间以分散数据点。
为了约束操作并保持数据生成分布的局部结构,应用了欠完整的自动编码器。通过整合聚类损失和自动编码器的重建损失,IDEC 可以联合优化聚类标签分配并学习适合聚类的特征并保留局部结构。由此产生的优化问题可以通过小批量随机梯度下降和反向传播有效地解决。图像和文本数据集的实验经验验证了局部结构保存的重要性和我们算法的有效性。
1 Introduction
无监督聚类是数据科学和机器学习的重要研究课题。传统的聚类算法,如 k-means [MacQueen, 1967]、高斯混合模型 [Bishop, 2006] 和谱聚类 [Von Luxburg, 2007] 根据内在特征或相似性对手工特征的数据进行分组。然而,当输入特征空间(数据空间)的维度非常高时,由于相似性度量不可靠,聚类变得无效。将数据从高维特征空间转换到执行聚类的低维空间是一种直观的解决方案,并且已被广泛研究。这可以通过应用主成分分析 (PCA) 等降维技术来完成,但这些浅层模型的表示能力是有限的。由于深度学习的发展,这种特征转换可以通过使用深度神经网络(DNN)来实现。我们将这种聚类称为深度聚类。
深度聚类是最近提出的,但仍有很多问题没有解决。例如,什么类型的神经网络是合适的?如何提供指导信息,即定义面向聚类的损失函数?在转换过程中应该保留哪些数据属性?深度聚类中的原始工作侧重于通过将先验知识添加到主观上来学习保留数据某些属性的特征 [Tian et al., 2014;彭等人,2016]。它们是两阶段算法:特征转换和聚类。后来,联合完成特征变换和聚类的算法应运而生[Yang et al., 2016;谢等人,2016]。 Deep Embedded Clustering (DEC) [Xie et al., 2016] 算法以自学习的方式定义了一个有效的目标。定义的聚类损失用于同时更新变换网络和聚类中心的参数。集群分配隐式集成到软标签。然而,聚类损失不能保证局部结构的保存。因此,特征转换可能会被误导,导致嵌入空间的损坏。
为了解决这个问题,在本文中,我们假设面向聚类的损失引导和局部结构保存机制对于深度聚类都是必不可少的。受 [Peng et al., 2016] 的启发,我们使用欠完备自动编码器来学习嵌入式特征并保留数据生成分布的局部结构。我们建议将自动编码器合并到 DEC 框架中。通过这种方式,所提出的框架可以联合执行聚类并学习具有局部结构保留的代表性特征。我们将我们的算法称为改进的深度嵌入式聚类 (IDEC)。 IDEC的优化可以直接进行小批量随机梯度下降和反向传播。最后,精心设计和进行了一些实验。结果验证了我们的假设和我们的 IDEC 的有效性。
这项工作的贡献总结如下:
- 我们提出了一种深度聚类算法,可以联合执行聚类并学习具有局部结构保留的代表性特征。
- 我们凭经验证明了局部结构保留在深度聚类中的重要性。
- 提议的 IDEC 在很大程度上优于最新的对手。
2 Related Work
2.1 Deep Clustering
现有的深度聚类算法大致分为两类:
- (i)在学习表示后应用聚类的两阶段工作
- 以及(ii)联合优化特征学习和聚类的方法。
前一类算法直接利用了现有的无监督深度学习框架和技术。例如,[Tian et al., 2014] 使用自动编码器学习原始图的低维特征,然后运行 k-means 算法得到聚类结果。 [Chen, 2015] 逐层训练深度信念网络 (DBN),然后将非参数最大边距聚类应用于学习的中间表示。 [Peng et al., 2016] 在学习同时适应局部和全局子空间结构的非线性潜在空间中的表示之前使用具有稀疏性的自动编码器,然后使用传统的聚类算法来获得标签分配。
另一类算法试图明确定义聚类损失,模拟监督深度学习中的分类错误。 [Yang et al., 2016] 在深度表示和图像集群中提出了一个循环框架,它将两个过程集成到一个具有统一加权三元组损失的模型中,并对其进行端到端优化。 DEC [Xie et al., 2016] 使用深度神经网络学习从观察空间到低维潜在空间的映射,可以同时获得特征表示和聚类分配。
所提出的算法本质上是 DEC 的修改版本,其中结合了一个不完整的自动编码器以保留局部结构。它在简单性方面优于 [Yang et al., 2016],没有重复性,并且在聚类准确性和特征的代表性方面优于 DEC。由于IDEC主要依赖于autoencoder和DEC,我们将在下面的章节中更详细地介绍它们。
2.2 Autoencoder
自编码器是一种经过训练以尝试将其输入复制到其输出的神经网络。在内部,它有一个隐藏层z,用于描述用于表示输入的代码。该网络由两部分组成:编码器函数 z = fW (x) 和解码器 x′ = gW ′ (z),产生重构。有两种广泛使用的自动编码器类型。
不完整的自动编码器。它控制潜在代码 z 的维度低于输入数据 x。学习这种不完整的表示会迫使自动编码器捕获数据的最显着特征。
去噪自动编码器。去噪自编码器不是重建 x givenx,而是最小化以下目标:
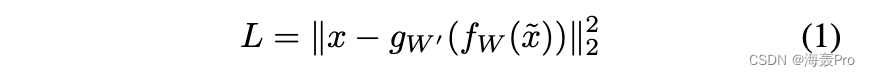
其中 ̃x 是被某种形式的噪声破坏的 x 的副本。因此,去噪自编码器必须从这种损坏中恢复 x,而不是简单地复制它们的输入。这样,去噪自编码器可以强制编码器 fW 和解码器 gW’ 隐式捕获数据生成分布的结构。
在我们的算法中,去噪自编码器用于预训练,在初始化后将欠完备自编码器添加到 DEC 框架中。
2.3 Deep Embedded Clustering
深度嵌入式聚类 (DEC) [Xie et al., 2016] 从预训练自动编码器开始,然后移除解码器。剩余的编码器通过优化以下目标进行微调:
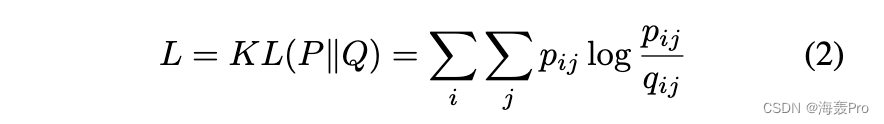
其中 qij 是嵌入点 zi 和聚类中心 μj 之间的相似度,由学生 t 分布测量 [Maaten 和 Hinton,2008]:
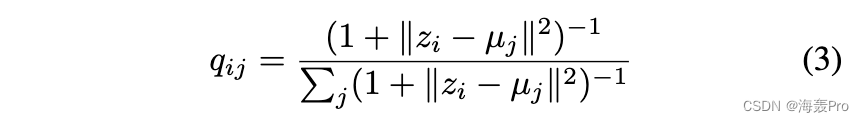
并且 (2) 中的 pij 是定义为的目标分布
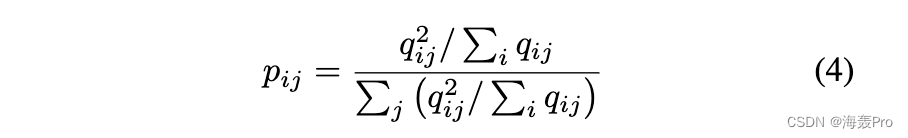 正如我们所见,目标分布 P 由 Q 定义,因此最小化 L 是一种自我训练的形式 [Nigam and Ghani, 2000]。
正如我们所见,目标分布 P 由 Q 定义,因此最小化 L 是一种自我训练的形式 [Nigam and Ghani, 2000]。
令 fW 为编码器映射,即 zi = fW (xi) 其中xi 是数据集 X 的输入示例。预训练后,可以使用 fW 提取所有嵌入点 {zi}。然后在 {zi} 上使用 k-means 得到初始聚类中心 {μj }。之后,可以根据(2)、(3)和(4)计算L。样本 xi 的预测标签为 arg maxj qij 。
在反向传播期间,可以很容易地计算出∂L/∂zi 和∂L/∂μj。然后 ∂L/∂zi 被向下传递以更新 fW 并且∂L/∂μj 用于更新聚类中心 μj :

DEC 的最大贡献是聚类损失(或目标分布 P,具体而言)。它的工作原理是使用高机密样本作为监督,然后使每个集群中的样本分布更密集。但是,不能保证将靠近边缘的样本拉向正确的集群。我们通过显式保留数据的本地结构来处理这个问题。在这种情况下,高机密样本的监督信息可以帮助边缘样本走到正确的簇。
3 Improved Deep Embedded Clustering
考虑具有 n 个样本的数据集 X,每个样本 xi ∈Rd,其中 d 是维度。聚类数 K 是先验知识,第 j 个聚类中心由 μj ∈ Rd 表示。设 si ∈ {1, 2, . . . , K} 表示分配给样本 xi 的聚类索引。定义非线性映射 fW : xi → zi 和 gW ′ : zi → x′i 其中 zi 是 xi 在低维特征空间中的嵌入点,x′i 是 xi 的重建样本。
我们的目标是找到一个好的 fW 使得嵌入点{zi}n i=1 更适合聚类任务。为此,两个组件是必不可少的:自动编码器和聚类损失。自动编码器用于以无监督的方式学习表示,学习的特征可以保留数据中的固有局部结构。借鉴 [Xie et al., 2016] 的聚类损失负责操纵嵌入空间以分散嵌入点。整个网络结构如图1所示。目标定义为
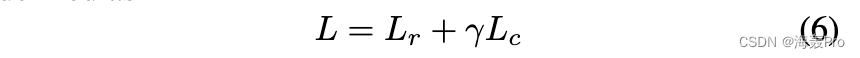
其中 Lr 和 Lc 分别是重建损失和聚类损失,γ > 0 是控制嵌入空间扭曲程度的系数。当 γ = 1 且 Lr ≡ 0 时,(6) 简化为 DEC 的目标 [Xie et al., 2016]。
3.1 Clustering loss and Initialization
[Xie et al., 2016] 提出了聚类损失。定义为分布P和Q之间的KL散度,其中Q是Student’s tdistribution测量的软标签分布,P是从Q导出的目标分布。也就是说,聚类损失定义为
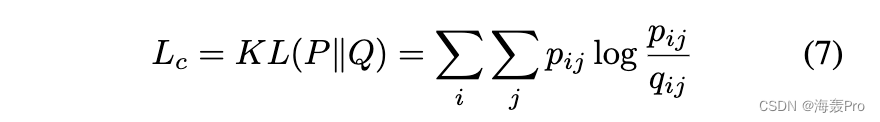
其中 KL 是 KullbackLeibler 散度,用于衡量两个概率分布之间的非对称差异,P 和 Q 由 (4) 和 (3) 定义。详细信息可以在第 2.3 节和 [Xie et al., 2016] 中找到。
按照 [Xie et al., 2016] 中的建议,我们还在执行聚类之前预训练了一个堆叠去噪自编码器。预训练后,嵌入点是输入样本的有效特征表示。然后可以通过在 {zi = fW (xi)}n i=1 上使用 k-means 来初始化聚类中心 {μj }K j=1
3.2 Local structure preservation
3.1 节获得的嵌入点不一定适合聚类任务。为此,DEC [Xie et al., 2016] 放弃了解码器,并使用聚类损失 Lc 对编码器进行微调。然而,我们认为这种微调会扭曲嵌入空间,削弱嵌入特征的代表性,从而损害聚类性能。因此,我们建议保持解码器不变,并将聚类损失直接附加到嵌入空间。
为了保证聚类损失的有效性,预训练中使用的堆叠去噪自编码器不再适用。因为应该对干净数据的特征执行聚类,而不是在去噪自编码器中使用的噪声数据。所以我们直接去除噪音。然后堆叠去噪自编码器退化为不完全自编码器(参见第 2.2 节)。重建损失通过均方误差 (MSE) 测量:
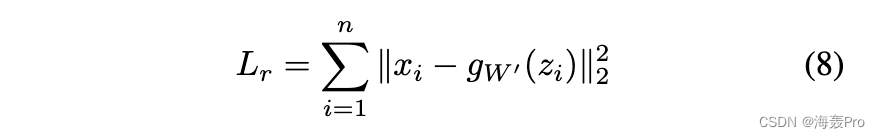
其中 zi = fW (xi) 和 fW 和 gW ’ 分别是编码器和解码器映射。如 [Peng et al., 2016] 和 [Goodfellow et al., 2016] 所示,自动编码器可以保留数据生成分布的局部结构。在这种情况下,使用聚类损失稍微操纵嵌入空间不会导致损坏。所以系数 γ 最好小于 1,这将在 4.3 节中进行经验证明。
3.3 Optimization
我们使用小批量随机梯度下降(SGD)和反向传播优化(6)。具体来说,有3种参数需要优化或更新:autoencoder的权重、聚类中心和目标分布P
更新自动编码器的权重和聚类中心。固定目标分布 P ,则 Lc 相对于嵌入点 zi 和聚类中心 μj 的梯度可以计算为
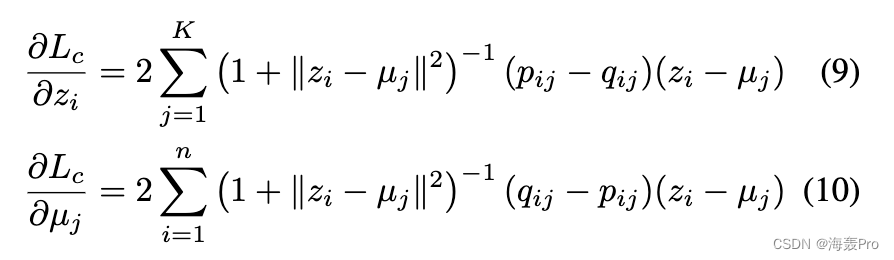
请注意,上述推导来自 [Xie et al., 2016]。然后给定一个包含 m 个样本的 mini batch,学习率 λ,μj 更新为

解码器的权重更新为
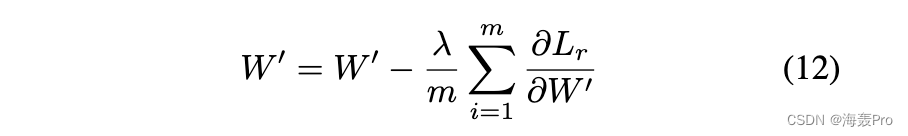
编码器的权重更新为

更新目标分布。目标分布作为“groundtruth”软标签,但也取决于预测的软标签。因此,为避免不稳定性,不应仅使用一批数据在每次迭代时更新 P(使用小批量样本更新自动编码器的权重称为一次迭代)。在实践中,我们每 T 次迭代使用所有嵌入点更新目标分布。更新规则见(3)和(4)。更新目标分布时,分配给 xi 的标签由下式获得
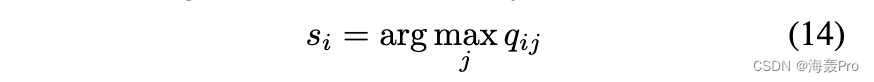
其中 qij 由 (3) 计算得出。如果目标分布的两次连续更新之间的标签分配变化(百分比)小于阈值 δ,我们将停止训练。
整个算法总结在算法 1 中。

不难看出,IDEC算法的时间复杂度为O(nD2 + ndK),其中D、d、K分别为隐藏层的最大神经元个数、嵌入层的维数和聚类的个数。一般 K ≤ d ≤ D 成立,所以时间复杂度为 O(nD2)。
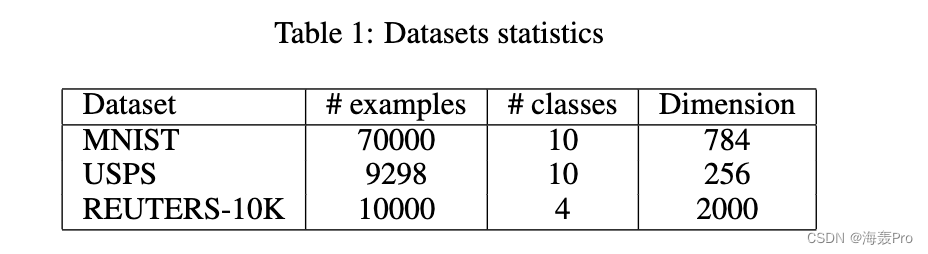
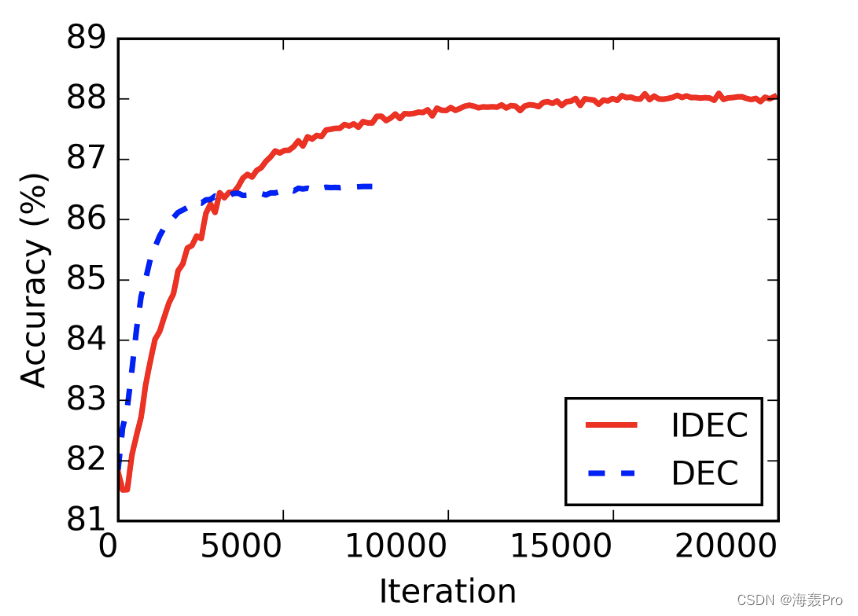
4 Experiments
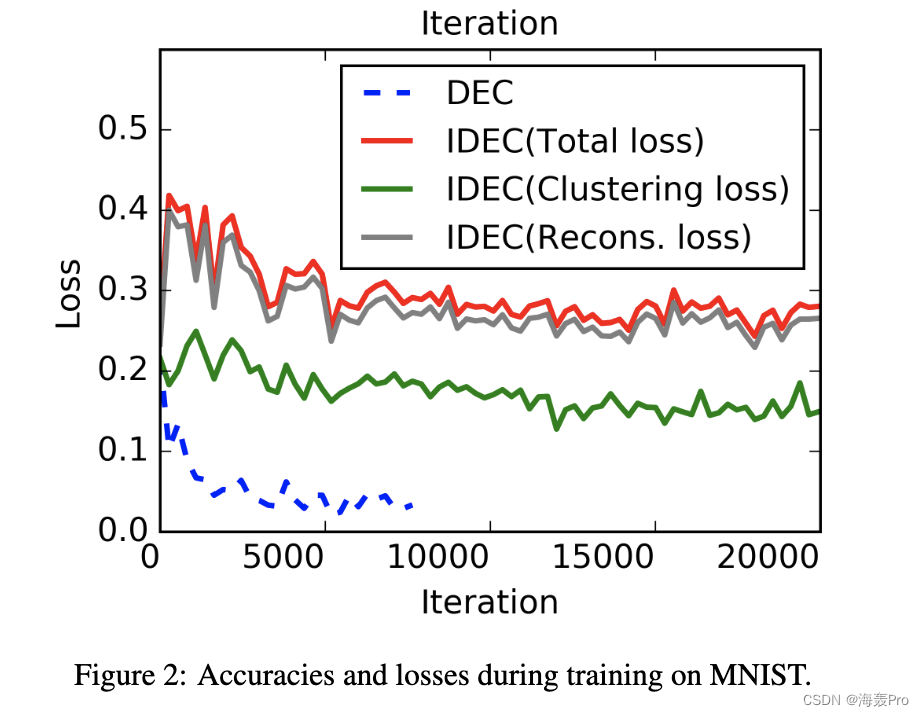

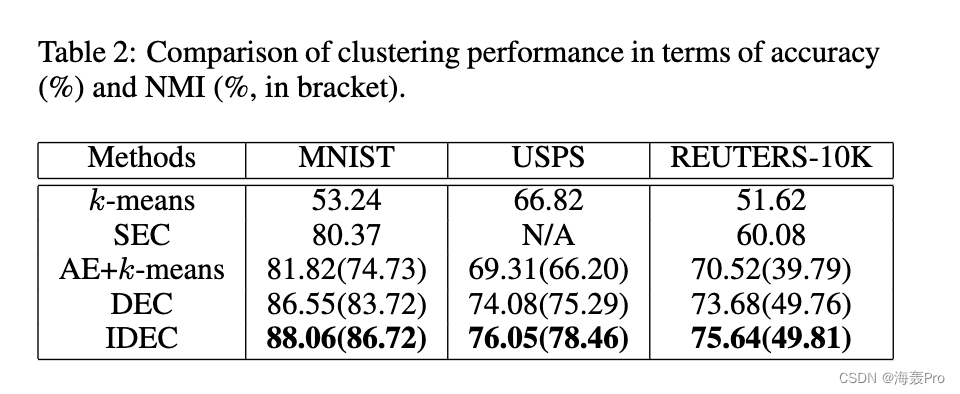
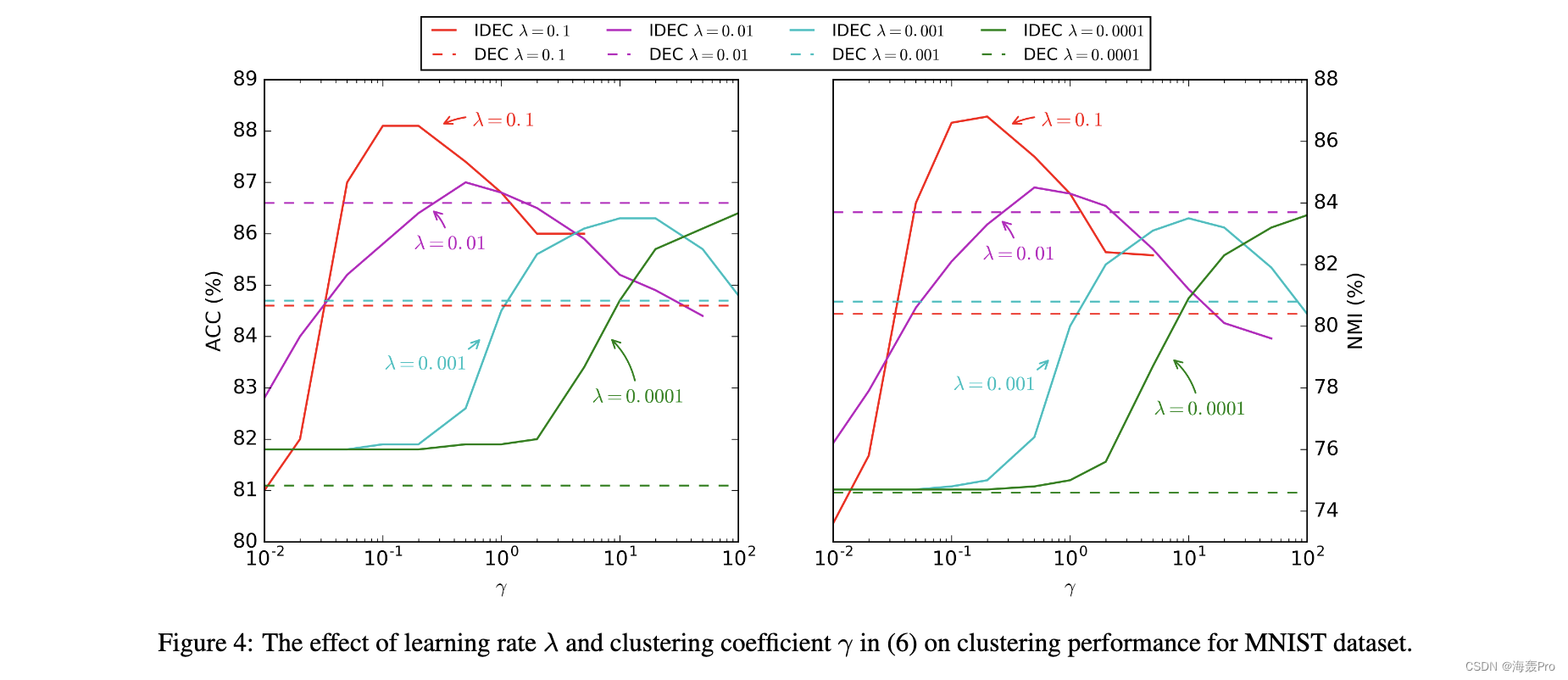
5 Conclusion
本文提出了改进的深度嵌入聚类(IDEC)算法,该算法联合执行聚类并学习适合聚类的嵌入特征并保留数据生成分布的局部结构。 IDEC 通过优化基于 KL 散度的聚类损失来操纵特征空间以分散数据。它通过结合自动编码器来维护局部结构。实证实验表明,结构保持对于深度聚类算法至关重要,并且可以提高聚类性能。未来的工作包括:在 IDEC 框架中添加更多的先验知识(例如稀疏性),并为图像数据集合并卷积层。
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正


- 点赞
- 收藏
- 关注作者
评论(0)