走进Python requests库

一、前言

Requests is an elegant and simple HTTP library for Python, built for human beings.
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的HTTP库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。Requests 的哲学是以 PEP20 的箴言为中心开发的,所以它比 urllib 更加 Pythoner。更重要的一点是它支持 Python3!
Requests 允许你发送简单的HTTP/1.1请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive和 HTTP连接池的功能是100%自动化的,一切动力都来自于根植在Requests内部的 urllib3。
- Beautiful is better than ugly.(美丽优于丑陋)
- Explicit is better than implicit.(清楚优于含糊)
- Simple is better than complex.(简单优于复杂)
- Complex is better than complicated.(复杂优于繁琐)
- Readability counts.(重要的是可读性)
二、安装 Requests
通过pip安装
pip install requests
在博文《Python进阶(二十)-Python爬虫实例讲解》、《Python进阶(十八)-Python3爬虫小试牛刀之爬取CSDN博客个人信息》中讲解了利用urllib、bs4爬取网页信息。下面讲解利用requests和bs4的爬取网页信息。
三、数据获取
在模拟访问过程中,需要设置好请求头,已达到模拟浏览器访问的效果请求头设置如下:
#伪装headers
headers = {
#伪装成浏览器访问,直接访问的话csdn会拒绝
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
# 若写成'Proxy-Connection':'keep-alive',则CSDN会拒绝访问
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'http://write.blog.csdn.net/postlist/6788536/0/enabled/2',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
有关请求头的获取,可使用浏览器自带的“开发者工具获取”或利用Fiddler工具,有关Fiddler的详细使用参见博文《Fiddler(一) - Fiddler简介》、《Fiddler(二) - 使用Fiddler做抓包分析》、《Python进阶(三十五)-Fiddler命令行和HTTP断点调试》。
使用requests访问网站时语句特别简洁,如下:
#构造请求,访问页面
response = requests.get(myUrl,headers=headers)
其中,response即为访问返回结果。获取到结果之后requests的使用至此结束。然后就是使用bs4进行文档解析了。代码如下:
# 创建BeautifulSoup对象
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, "html.parser")
下面以获取博客访问信息为例,首先参照网页源码获悉页面元素布局。

bs4解析代码如下:
# 获取<ul id="blog_rank">
ul = soup.find('ul', {'id': 'blog_rank'})
# 获取所有的li
lists = ul.find_all('li')
# 对每个li标签中的内容进行遍历
for li in lists:
# 找到访问总量
data = li.find('span').string
# print(type(data))
if data is None:
# http://c.csdnimg.cn/jifen/images/xunzhang/jianzhang/blog8.png
src = dict(li.find('img', {'id': 'leveImg'}).attrs)['src']
# 52
# print(src.index('blog'))
# print(src[56])
data = src[56]
在获取等级时,需要进行特殊处理。
四、模拟登录
在获取粉丝数量时,首先要模拟用户登录。
采用python模拟登录CSDN的时候分为三步走:
- 获取url=https://passport.csdn.net/account/login;
- 分析登录信息:从网页中得到username,password和hideen标签隐藏的属性,在CSDN中有三个隐藏标签,lt,execution,_eventId //注意这三个标签是动态的。同时注意到表单使用post提交方式。

- 下面使用post方式实现表单提交操作,代码如下:
import re
import requests
url = "https://passport.csdn.net/account/login"
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36",
}
Username = "***"
PassWord = "***"
s = requests.session()
r = s.get(url,headers=head)
lt_execution_id = re.findall('name="lt" value="(.*?)".*\sname="execution" value="(.*?)"', r.text, re.S)
payload = {
"username": Username,
"password": PassWord,
"lt" : lt_execution_id[0][0],
"execution" : lt_execution_id[0][1],
"_eventId" : "submit"
}
r2 = s.post(url,headers=head,data=payload)
print(r2.text) #登录成功会返回一段loginapi.js的脚本
print("*"*100) #分隔符
r3 = s.get("http://my.csdn.net",headers=head)
print(r3.text) #成功获取"我的主页"源代码
程序运行结果如下:

五、bs4解析
接下来使用bs4解析出粉丝数量及个人信息。
def craw_csdn(self, response):
# 创建BeautifulSoup对象
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, "html.parser")
# 按照标准的缩进格式的结构输出
# print(soup.prettify())
# 获取body部分
body = soup.body
# <dd class="focus_num"><b><a href='/my/follow' target=_blank>5</a></b>关注</dd>
focus = soup.find('dd', class_='focus_num').find('a').string
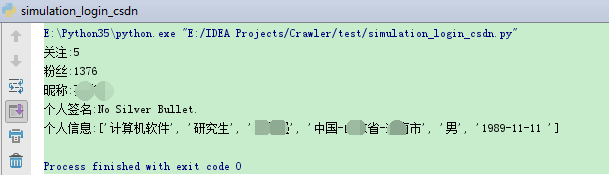
print("关注:" + str(focus))
# <dd class="fans_num"><b><a href='/my/fans' target=_blank>1374</a></b>粉丝</dd>
fans = soup.find('dd', class_='fans_num').find('a').string
print("粉丝:" + str(fans))
# <dt class="person-nick-name">
# <span>***</span> </dt>
nick_name = soup.find('dt', class_='person-nick-name').find('span').string
print("昵称:" + str(nick_name))
# <dd class="person-detail">
# 计算机软件<span>|</span>研究生<span>|</span>***<span>|</span>中国-**省-**市<span>|</span>男<span>|</span>19**11-11 </dd>
# <dd class="person-sign">No Silver Bullet.</dd>
person_detail = soup.find('dd', class_='person-detail').contents
# print(len(person_detail))
len_person_detail = len(person_detail)
pd = []
#代表从0到5,间隔2(不包含5)
for i in range(0,len_person_detail,2):
# print(person_detail[i])
if i == 0:
pd.append(person_detail[i].lstrip(' \n \t\t'))
else:
pd.append(person_detail[i])
print("个人信息:" + str(pd))
return int(fans)
爬取结果如下图所示:
六、总结
以上实现了利用requests结合bs4获取博客信息,同时实现了模拟用户登录获取粉丝数量,至于具体采集应用大家就请自行发挥吧。有关requests及bs4的其他具体应用详见参考资料。
七、string查找 && range
7.1 string查找
python的string对象没有contains方法,不用使用string.contains的方法判断是否包含子字符串,但是python有更简单的方法来替换contains函数。
方法1:使用 in 方法实现contains的功能:
site = 'http://www.jb51.net/'
if "jb51" in site:
print('site contains jb51')
输出结果:site contains jb51
方法2:使用find函数实现contains的功能。
s = "This be a string"
if s.find("is") == -1:
print ("No 'is' here!")
else:
Print("Found 'is' in the string.")
7.2 range()
# [1, 2, 3, 4]
range(1,5) #代表从1到5(不包含5)
# [1, 3]
range(1,5,2) #代表从1到5,间隔2(不包含5)
# [0, 1, 2, 3, 4]
range(5) #代表从0到5(不包含5)
八、拓展阅读


- 点赞
- 收藏
- 关注作者
评论(0)