HashMap源码解读(上篇)

前言
上一篇博主写了关于HashMap和Hashtable的区别与联系:
本篇博主将从浅入深地解读HashMap源码,学习一下被JDK收录的大神们写的代码思路~~
一、前置知识
1.哈希表:基于数组的高效查找衍生出来的数据结构
2.哈希函数:将任意的key转为数组索引的函数、映射。将任意key映射为数组索引。
3.哈希冲突:不同的key经过hash函数的运算竟然得到了相同的数字
如: f(x1) = f(x2) => x1 != x2 【f(x)为hash运算】
4.开散列:在冲突的数组索引处转为链表实现。所有不同的key映射到数字索引的元素都在同一个链表存储。
==若某个数组的索引位置冲突非常严重,哈希表查找有可能退化为链表遍历。==
解决方案:
- 在冲突严重的地方将链表转化为树
- 整个哈希表进行扩容,原本冲突的元素经过扩容后就不再冲突
5.闭散列(二次探测)(再哈希):
- 二次线性探测:若有元素冲突,就近寻找下一个不冲突的位置存放元素,好放难查。
- 再哈希:第一次哈希函数产生冲突,选一个备用的哈希函数2再次计算值,直到不冲突为止。
6.负载因子(loadFactor): 表示当前哈希表最多的有效元素个数 / 哈希表长度
- 这个值越大就说明冲突越严重一些
- 这个值越小说明冲突越小,数组利用率越低
如:
int[] data = new int[16];
loadFactor = 0.75f;
data.length * loadFactor = 12; //有效的元素个数最多为12个元素,超过这个个数,哈希表就会扩容
小技巧:
判断一个字符串中某个字符出现的次数。str只是由小写字母组成,一共26个小写字母。
int[] freq = new int[26]; //char -> int
c - a => int a = ‘c’ - ‘a’ = 2
存储字符c出现几次,字符c一定出现在freq[c - ‘a’] => 唯一的位置
char c = ‘a’ => freq[0] ++ ‘a’ -> 0 哈希函数
char c = ‘b’ => freq[1] ++ ‘b’ 出现一次
不同freq索引就映射了不同的小写字母,一一对应。
二、hashCode与equals方法(重要)
hashCode()与equals()都是Object类的方法,而在把自定义的类当作Key传入HashMap中的时候,会根据自定义类重写的这两个方法来解决hash冲突。
2.1 hashCode()
-
Object提供的hashCode()可以将任意对象转为int,不同的对象(地址不同)原则上一定转为不同的int。
-
原则上自定义的类若需要保存到HashMao哈希表中,不能直接使用Object提供的hashCode,需要覆写这个方法。(因为要是用Object的hashCode,数组开辟的空间会很大,浪费内存空间)
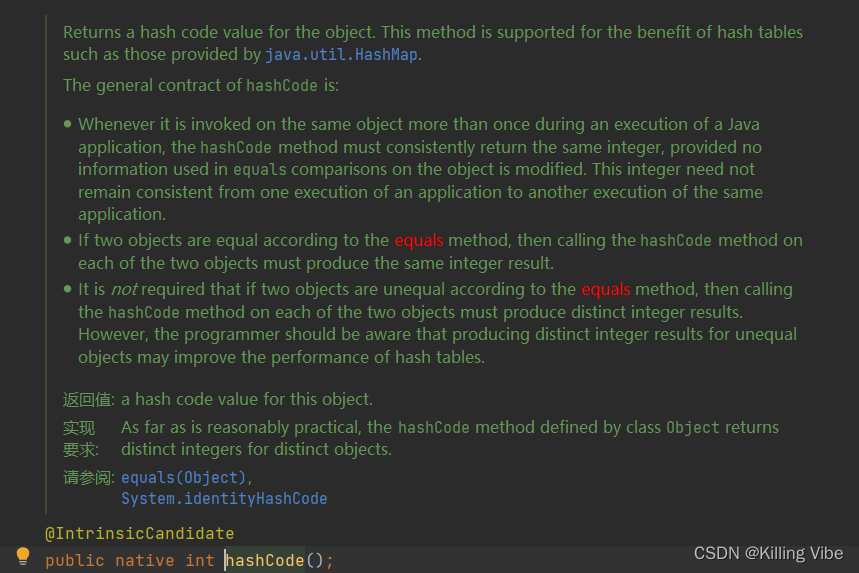
只要是不同的对象原则上都会返回不同的整数。
2.2 equals()
一般来说这个方法用于比较两个对象是否相等,Object中的这个方法比较的是两个对象的地址是否相等,我们可以自己重写这个方法来实现根据何种属性判断是否相等。

通常有必要在重写hashCode方法时重写该方法,以便维护hashCode方法的通用规定,规定相等的对象必须具有相等的哈希码。
三、HashMap中Key的存储机制
HashMap中Key的值是唯一的,所以HashMap会根据自定义的类中的equals方法来判断是否为同一个对象,如果此时HashMap又put进来一个相同的对象,那么HashMap中不会新增一个新的键值对,而是把这个Key对应的Value值更改。
现定义一个学生类:
class Student{
int age;
String name;
}
此时要将Student对象存储到HashMap的key上,会:
- 计算Student对象的哈希值,得到一个数组的索引下标。hashCode()
- 判断当前这个Student对象是否已经在哈希表中“存在”了。equals()
equals相同的两个对象,就认为是同一个对象,哈希表中的这个对象有且只能有一个。
自定义对象作为Key的唯一性,就是通过equals方法保证的。
拓展:equals相同的两个对象,hashCode是否相同?反之如何?
前者必须相同,后者不一定相同。
所以只有equals和hashCode都相同的对象才是唯一的对象。
总结
这篇文章是HashMap的一些前置知识,下一篇博主将深入HashMap源代码,分析HashMap是如何设计的,它的存储逻辑以及如何解决冲突的。希望能帮到大家~~

- 点赞
- 收藏
- 关注作者
评论(0)