一文搞懂MySQL中一条SQL语句是如何执行的

曾在面试中被问过这样的问题:
SELECT * FROM A WHERE B=1 AND C=2 GROUP BY D ORDER BY D在MySQL中是如何执行的?
因为没有专门的研究过这个问题,因此当时答的不是很好,所以想利用专门的时间来研究下这个内容,只有了解了SQL是如何执行的,才能够写出更好的SQL。
1 SQL执行总体过程
如图:先后顺序就是从上到下

- Client层:接收用户输入的SQL,显示响应的结果
- Server层:对SQL进行格式的校验、语言分析、优化和执行,并对执行结果进行返回
- 连接器:用户的认证和授权,对接口进行链接
- 缓存:对查询结果进行缓存,并在对缓存进行查询时返回命中结果
- 分析器:SQL的词法分析和语法分析
- 优化器:生成SQL执行计划,操作索引进行数据的查询
- 执行器:操作引擎,利用文件系统返回查询结果
- 文件系统层:对数据进行持久化
2 总体过程剖析
2.1 客户端和连接器
客户端这个词颇有些深意,比如我们常用来操作MySQL的Navicat、MyDB Studio、MySQL WorkBench等等,很好,我现在告诉你,他们都不是MySQL的客户端,意不意外?它们只能称为MySQL的客户端连接工具或可视化工具。
而真正意义上的MySQL客户端则是一个较为完整的Project,编译后可以是一个可执行文件,可以直接与MySQL Server进行连接和通信,比如Windows操作系统下的:
我们可以直接操作这个程序与MySQL Server进行交互,这就是MySQL Client。
现在我们看下连接器,首先是连接MySQL Server的操作:
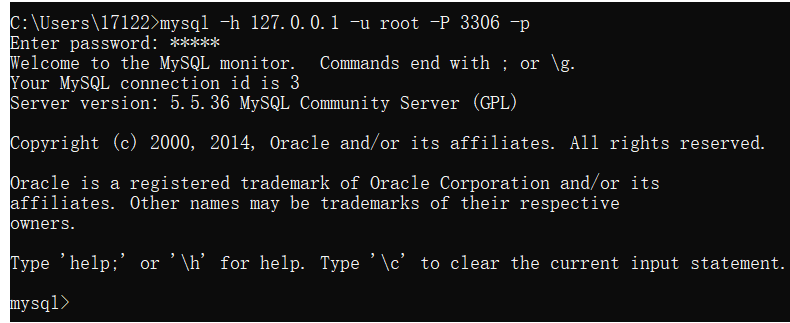
连接MySQL的语法:
mysql -h [host,默认为127.0.0.1] -u [用户名] -P [端口号,默认3306] -p
查看连接器都有哪些连接:

2.2 分析器
分析器主要负责SQL的语法分析和语义分析,对SQL进行初步的查验操作。
语法分析:
简单的讲语法分析就是检查SQL是否符合MySQL的语法和关键字,比如SELECT * FROM A WHERE B=C给写成了SELECT FROM * A WHERE B=C,这就会导致语法分析错误,例如:

语义分析(也叫词法分析):
就是判断除了SQL关键字顺序之外的其他语句词汇符不符合当前的查询条件,比如FROM A,表A却不存在,SELECT B,字段B不存在等等,例如:
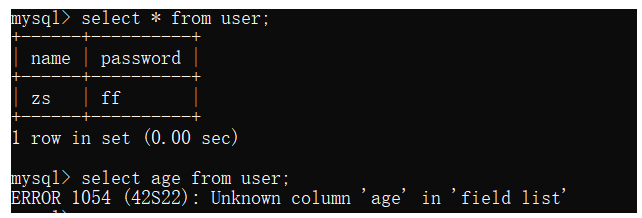
语法检查顺序:
SELECT
FROM
JOIN
ON
WHERE
GROUP BY
HAVING
UNION
ORDER BY
LIMIT
2.3 缓存
通常我们执行成功后的语句和结果(仅限查询语句),MySQL会进行缓存,当我们再次对该语句进行查询时,则会先查询缓存,查看是否命中。
在my.ini配置文件中我们可以设置MySQL缓存的大小和是否开启缓存:

2.4 优化器
这一步MySQL会帮助我们选择最优的查询方式,索引类型,确定执行方案。
优化器是在表中有多个索引的时候MySQL优化器会按照最小成本的原则(IO成本+CPU成本)决定使用哪个索引,或者有多表关联(join)的时候决定各个表的连接顺序。
2.5 执行器和文件系统
首先是执行器,调用执行接口将优化器优化后的SQL连接文件系统进行执行。
执行顺序:
FROM
ON
JOIN
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
UNION
ORDER BY
然后是文件系统,也叫存储引擎,分为内存数据和磁盘数据,因为为了快速查询一些数据,MySQL可以启用内存来存取数据,同样和缓存一样,内存区的大小也可以在my.ini配置文件中进行设置。
MySQL的文件系统并不单单是存放文件的作用,还有记录日志和维护事务功能的作用,比如常见的redo log 、undo log和bin log日志都是由执行器联合存储引擎进行生成和维护的。
3 回到面试题
SELECT * FROM A WHERE B=1 AND C=2 GROUP BY D ORDER BY D,因为是单表查询,而且在WHERE过滤的时候也比较简单,因此我们用流程图来表示下:
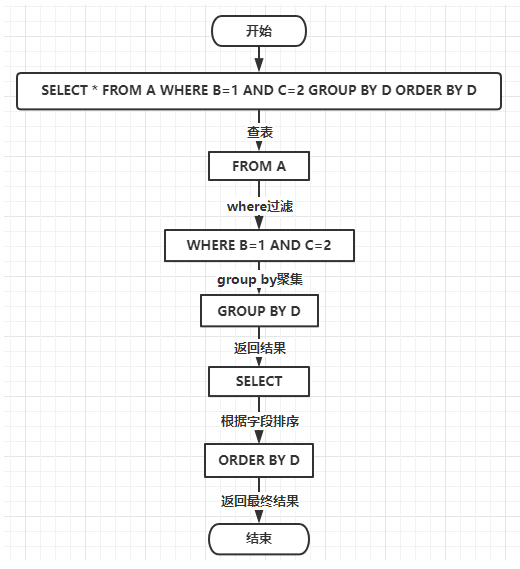
4 总结
一条SQL的执行过程能够帮助我们更好的了解MySQL内部的执行情况,但是对于SQL的优化而言,我们了解的知识还需要更多,比如使用explain查看SQL的执行计划,再针对执行计划对SQL进行进一步的优化等等我们都没有讲到,但是大多数的SQL可能并不需要优化,因此我们针对SQL的执行流程在基本的使用上也是能够帮助我们写出更优雅的SQL的。

- 点赞
- 收藏
- 关注作者
评论(0)