【C语言】探索数据的存储(上篇)

✍前言
HelloHello,大家好,今天我们来一起来探索数据的存储问题,我将大概用2篇博客来写这块的内容,今天,利用这一篇先来完成一部分,介绍数据类型,整形在内存中的存储:原码、反码、补码,以及大小端字节序。数据的存储这块内容还是有点难度的。但是学起来是真的有趣,让我们一起来看一看把!💖

🍁数据类型
数据类型,一个经常说起的东西,我们前面了解过基本的数据类型:
==char //字符数据类型== ——1个字节
==short //短整型==——2个字节
==int //整型==——4个字节
==long //长整型==——4/8个字节
==long long //更长的整型==——8个字节
==float //单精度浮点数==——4个字节
==double //双精度浮点数==——8个字节
类型的作用与意义是什么?
- 使用这个类型开辟内存空间的大小(大小决定了使用范围)。
- 看待内存空间的视角不同。
🍁数据类型的基本分类
整型:
- char
unsigned char——无符号
signed char——有符号
- short
unsigned short [int]
signed short [int]
- int
unsigned int
signed int
- long
unsigned long [int]
signed long [int]
long long
问题1:为什么char也可以归类为整型❓
==答:字符的本质是ASCII值是整型,所以可划分到整型==
问题2:signed和unsigned的用处❓
**==答:生活中有些数据是没有负数的(体重、长度、日期等)==**自然有些数据是有负数的,比如温度之类的,这也是为什么会有有符号和无符号。
浮点数
float
double
构造类型
数组类型
结构体类型 struct
枚举类型 enum
联合类型 union
指针类型
int *pi;
char *pc;
float* pf;
void* pv;
空类型:void 表示空类型(无类型)通常应用于函数的返回类型、函数的参数、指针类型。

🍁整形在内存中的存储
计算机中的整数有三种2进制表示方法,即原码、反码和补码
我们之前讲过一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。那数据在所开辟内存中到底是如何存储的?不知道你有没有想过这个问题❓
原码、反码、补码
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”
对于数值位来说:
正数的原、反、补码都相同。
负整数的三种表示方法各不相同。
原码
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码
将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码
反码+1就得到补码。
不理解?我们来演示一下,比如int a = 20;int b = -10;来表示其原码、反码、补码
一个字节8比特位,一个int占4个字节,32位比特位,根据20二进制的计算方法,我们就能得到其原码,又因为是正数,原码反码补码相同。负数也是类似的。
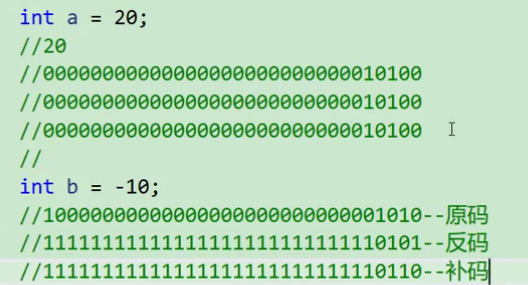
但是实际上呢,这样表示太过于冗长了,我们可以用十六进制来表示
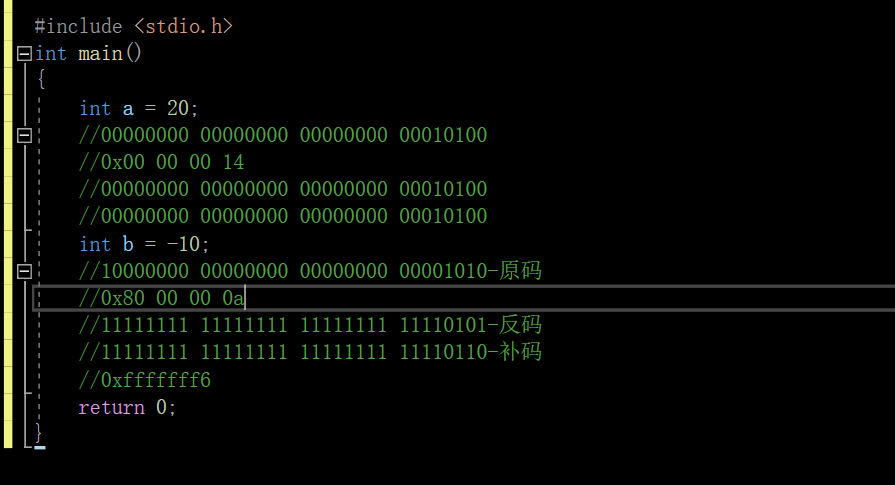
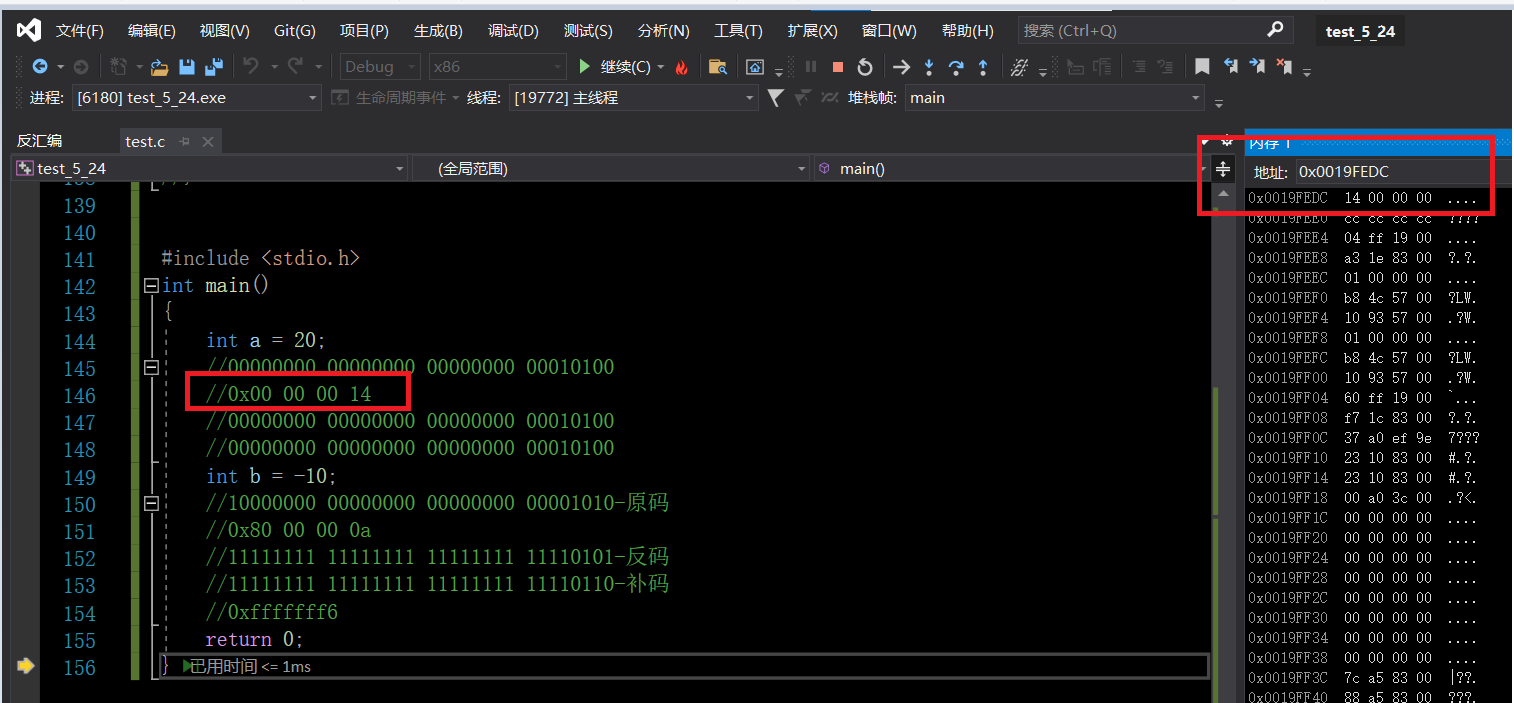
**对于整形来说:数据存放内存中其实存放的是补码。**为什么呢?调试看内存
调试观看内存布局:
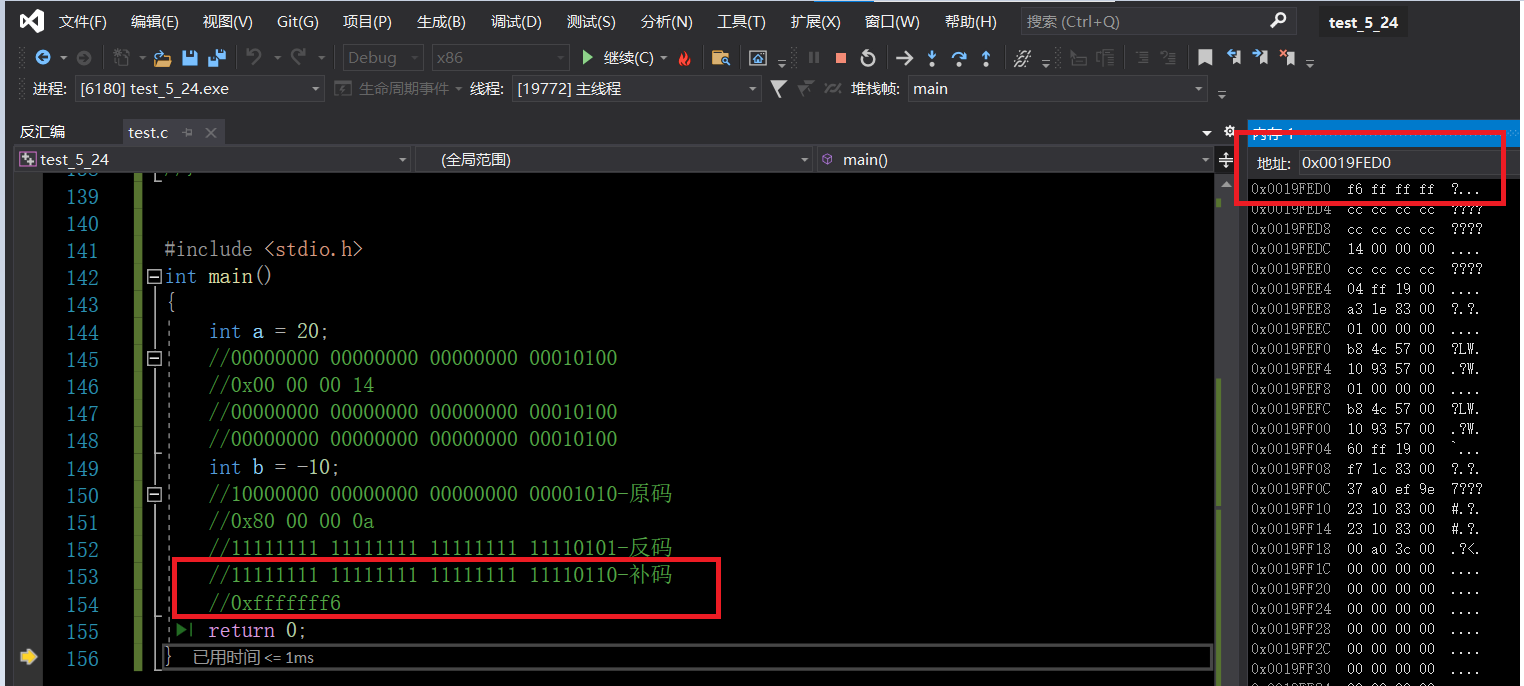
&a:由于原码反码补码相同比较难以说明,看负数&b
&b:
为什么呢?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;
同时,加法和减法也可以统一处理(CPU****只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路

不知道你有没有发现一个问题:为什么补码存储的方式是倒着存的
我们可以看到对于a和b分别存储的是补码。但是我们发现顺序有点不对劲。这是又为什么?

🍁大小端介绍
什么是大端小端?
==大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;==
==小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。==
这时候你肯定又要问了:为什么会有大端小端?
答:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式
那么问题又双叒叕来了:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序
概念性的东西上面说了,代码怎么设计?
我们来定义一个变量int a = 1;那么有两种存储方式:
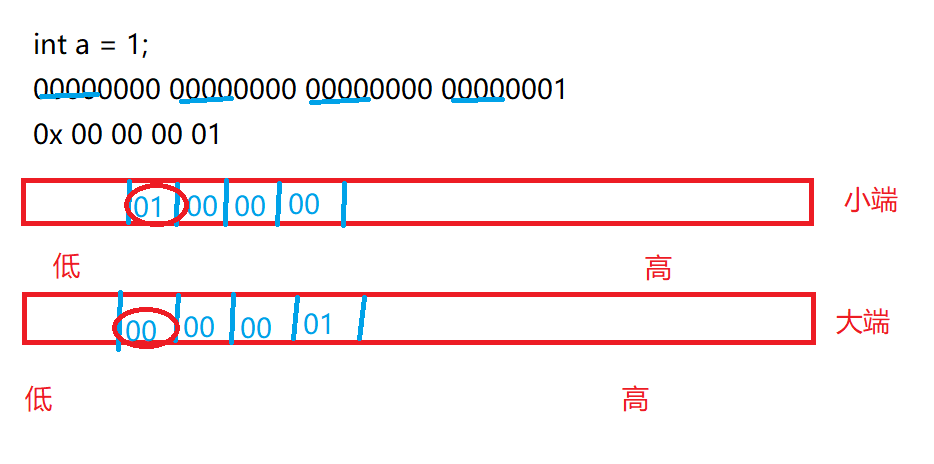
差别在于:小端存储第一个字节是01,大端存储第一个字节是00,好了,突破点就在这里:我们只要拿出a的第一个字节看看是1还是0就可以去判断是大端还是小端了,我们只要把a的地址取出来在强制转化成char*在解引用即可(因为a本身是int类型4个字节,我们只一个字节)下面我们来实现代码:
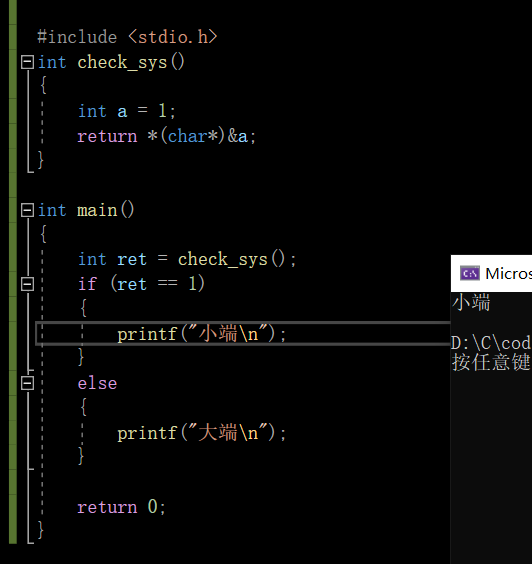
轻松解决该问题。
下面,我们来做一道题理解原码、反码、补码
🍁练习

1.
//输出什么?
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
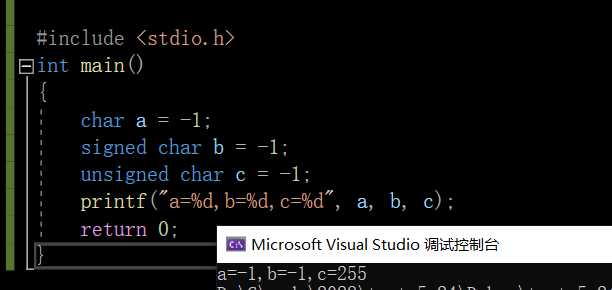
想想为什么?
有符号char可以表示-128——127,前两个范围没有问题,而无符号char可以表示0-255,-1不在范围内。具体是怎么回事呢?
-1出现的原因是:

255出现的原因:


- 点赞
- 收藏
- 关注作者
评论(0)