机器学习:线性判别分析从理论到公式推导(LDA)
数据定义
DataSet X:=
(xi,yi)i=1N,令X的每个观测值xi∈Rp,Y的每个元素
yi∈R,我们继续化简,X=
Y=
其中
yi为+1的输入C1类别,yi为−1的输入C2类别。
Xc1=(xi∣yi=+1)
Xc2=(xi∣yi=−1)
理论概述与变量定义
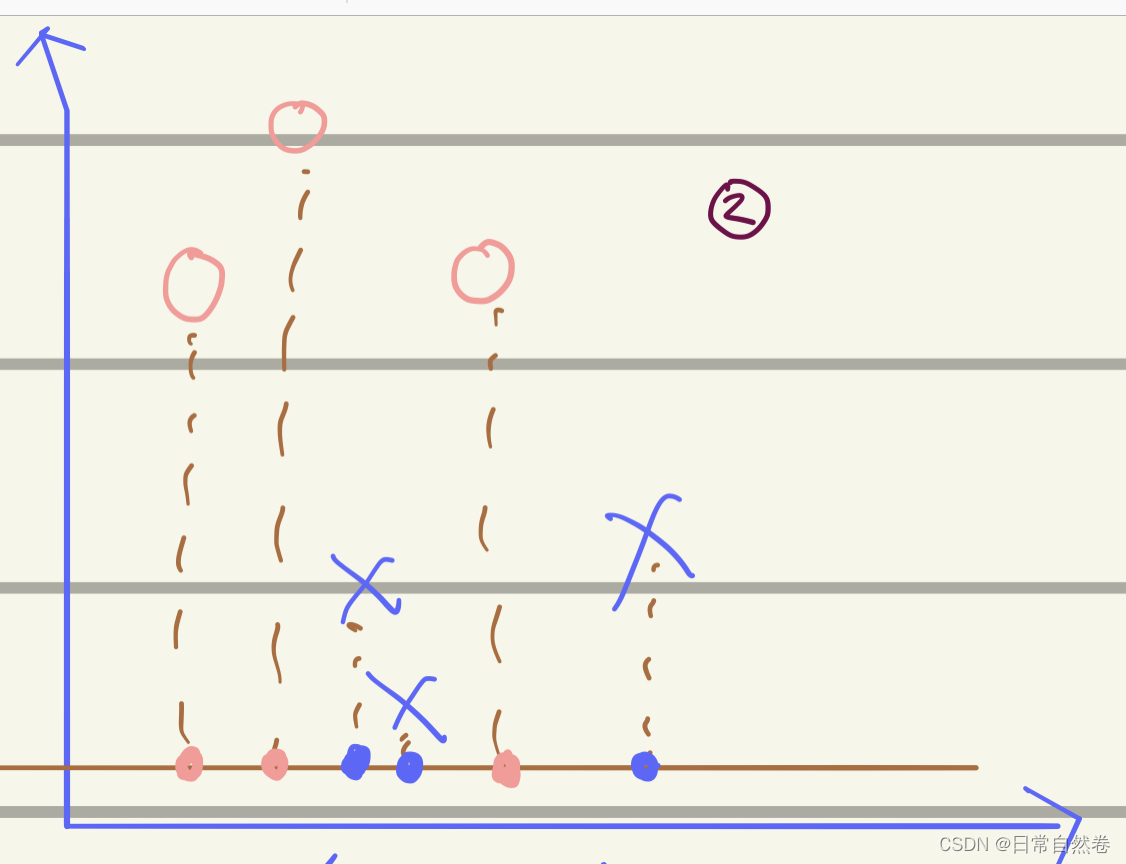
为了方便可视化,我们先令数据集的维度p=1,也就是每个观测值
xi的维度为1。
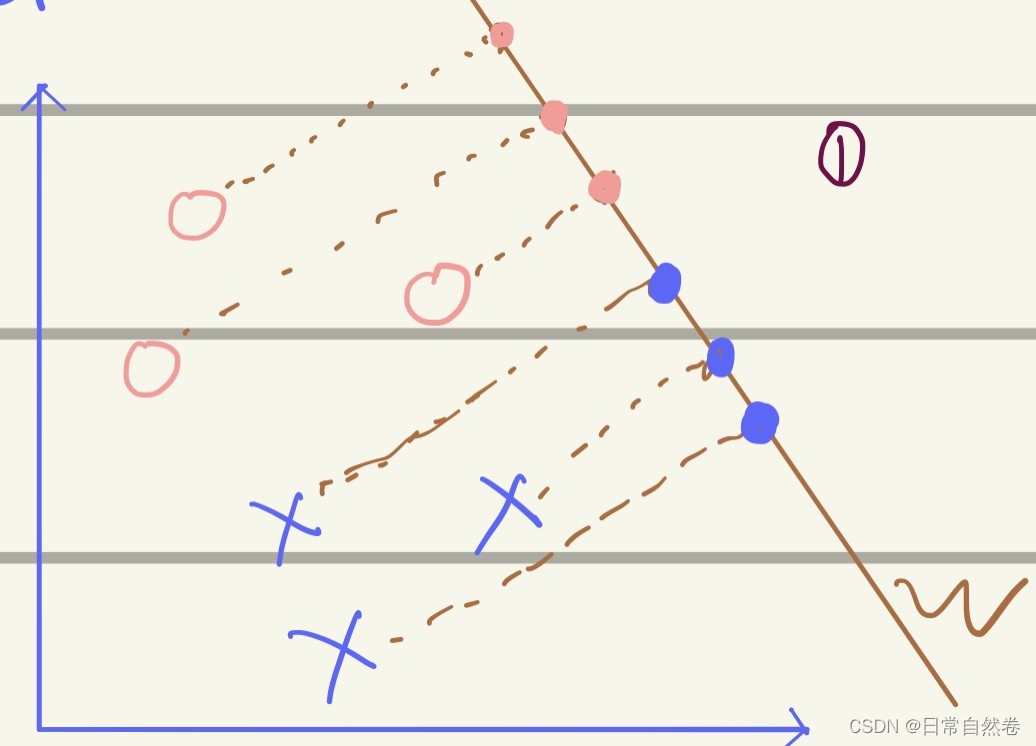
从图中我们可以看到,把这些坐标点投影到一维直线w上,可以发现,当观测值
xi如果投影到了一个合适的Vector上,就会很容易的在Vector上找到一个threshold(阈值),把⭕️与❌分开,但是如果,没有找到一个很好的Vector,就会像下面这幅图:
我们会发现,这两类数据交替出现,不能找一个一个合适的阈值将这两类数据分开。,所以我们要是想把这些数据分开就需要找到一个合适的Vector的方向。
我们通过观察投影到Vector w上面的坐标,我们发现当两类数据的距离越大分类效果越好,每一个分类内之间的数据约紧凑越好。也就是我们要找到一个Vector可以让投影在Vector 上的数据实现:类内小,类间大,还有一种解释:高内聚,松耦合,我起初听到这几句话的时候,感觉特别晦涩难懂,我们通过数学的口吻来解释:
类内小:也就是一个类别的观测值的在Vector上面的投影值之间方差足够小。
类间大:也就是说两个类别的观测值的在Vector上面的投影值的均值差距足够大。
我们现在已经有数据了,那么我们可以通过这个条件来反推出Vector的方向。
下面我们用公式表示:
观测值在Vector上面的投影可以表示为:
zi=wTxi,这里我们假设Vector的模
|w|的值为1(因为我们主要关心的是Vector的方向,长度是可以自由伸缩的)
公式推导
xi与w的点乘表示为:∣xi∣∗∣w∣∗cosθ,因为∣w∣=1,所以xi⋅w=∣xi∣⋅cosθ
均值:
N1∑i=1Nxi=zi
方差:
N1∑i=1N(xi−zi)(xi−zi)T
C1:
均值:
N11∑i=1N1xi=zi
方差:
N11∑i=1N1(xi−zi)(xi−zi)T=s1
C2:
均值:
N21∑i=1N2xi=zi
方差:
N21∑i=1N2(xi−zi)(xi−zi)T=s2
类间:
(z1−z2)2
类内:
s1+s2
为了让类内小,类间大,
目标函数
J(w)=s1+s2(z1−z2)2
化简分子:
(z1−z2)2=(N11∑i=1Nwtxi−N21∑i=1Nwtxi)2
=(wt(N11∑i=1Nxi−N21∑i=1Nxi)))2
=(wt(x1−x2))2
=wt(x1−x2)(x1−x2)Tw
s1+s2=N11∑i=1N(zi−zc1)(zi−zc1)T+N21∑i=1N(zi−zc2)(zi−zc2)T
提取w,最终化简结果
=wT(sc1+sc2)w
J(w)=wT(sc1+sc2)wwt(x1−x2)(x1−x2)Tw
我们令类间方差差
sb=(x1−x2)(x1−x2)
令类内方差:
sw=sc1+sc2
所以
J(w)=wTsbwwTsww
我们对目标函数求偏导数,令其等于0.最终得到:
w=wTsbwwTSwwsw−1sbw
由上面推到中可知:
w的size为1∗ps的size为p∗,所以
wTSww与
wTsbw为一维常数,
由于我们最终需要求的是Vector 的方向,所以我们约去与方向无关的变量。
w正比于sw−1(x1−x2),它的方向也就是最终我们要找的向量的方向。
【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com




评论(0)