js逆向之字体加密

首先我们来了解下什么是字体反爬:
为了能够更加清除的知道什么是字体反爬,我们直接上图看一下。
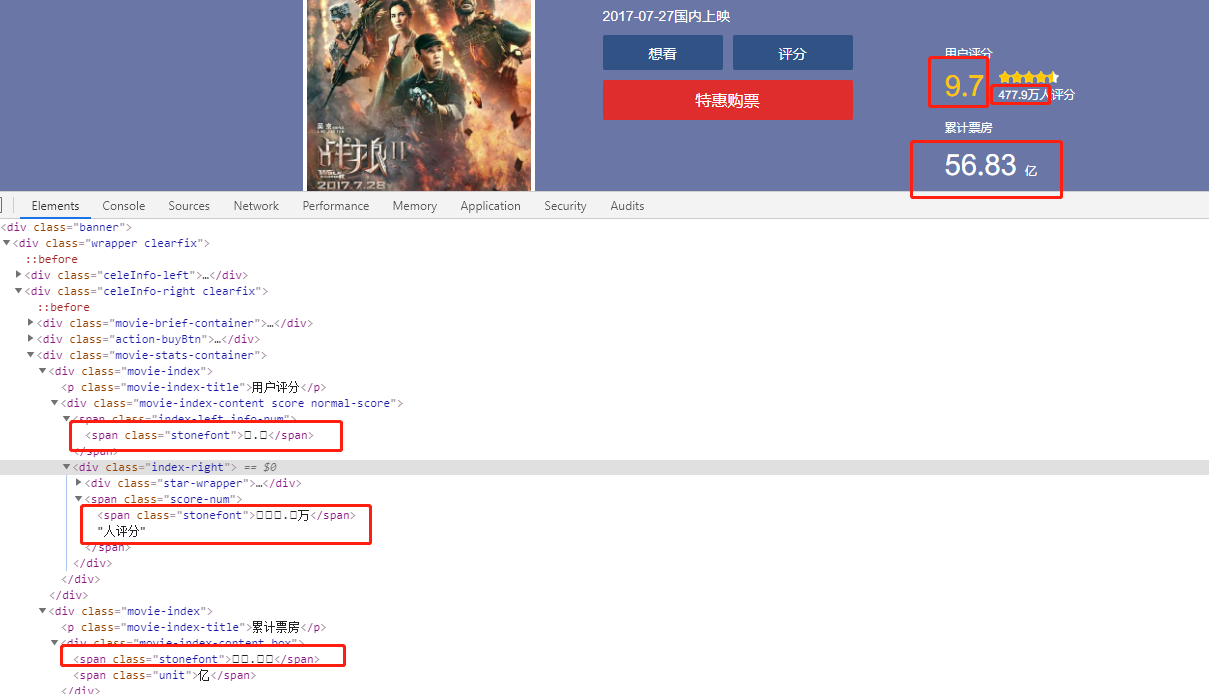
大家看一下,很明显的就能发现我们正常浏览能够看到数据,但是当我们打开Elements面板定位到对应元素上时发现竟然不是我们在页面上看到的数据,而是一些特殊的符号。我们按Ctrl+U直接看看页面源码,
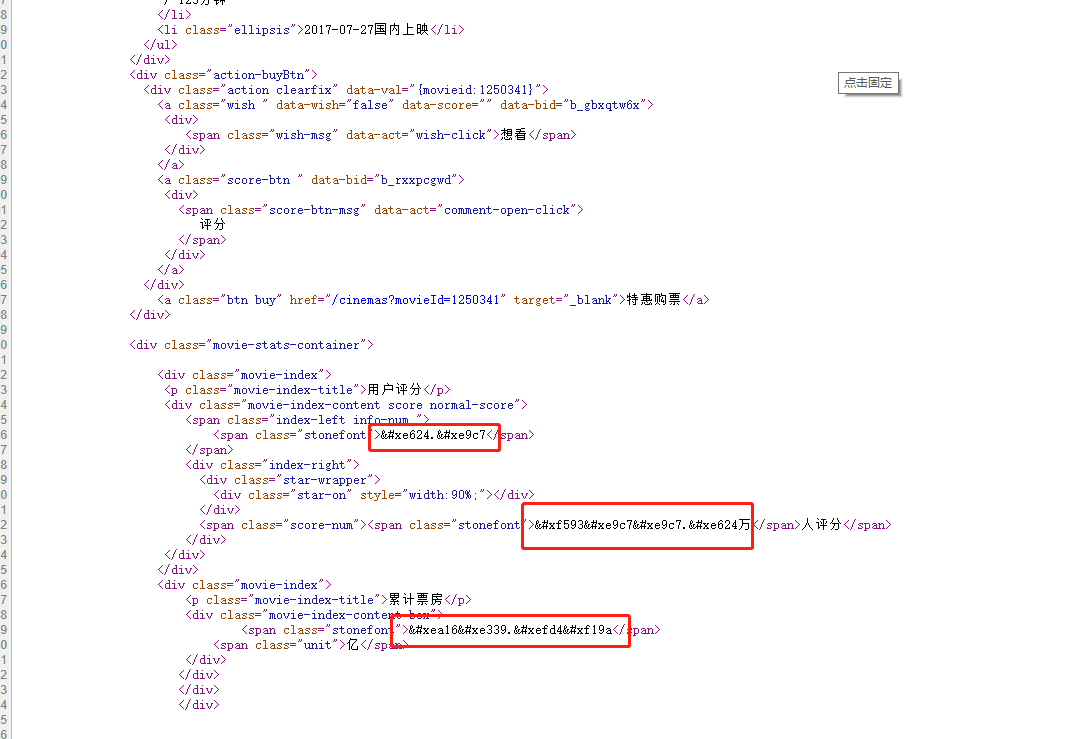
是不是很奇怪,竟然是一些编码。这个就是字体反爬,这里的字体都是自定义的字体,在CSS3之前,Web开发者必须使用用户计算机上已有的字体。但是在CSS3时代,开发者可以使用@font-face为网页指定字体,对用户计算机字体的一来。开发者可以将心仪的字体文件放在Web服务器上,并在Css样式中使用它。用户使用浏览器访问Web应用时,对应的字体会被浏览器下载到用户的计算上。
CSS的作用是修饰HTML,所以在页面渲染的时候不会改变HTML文档内容。由于字体的加载和映射工作是由CSS完成的,所以即使我们借助Splash、Selenium和Pypeeteer工具也无法获得对应的文字内容。字体反爬正式利用了这个特点,将自定义字体应用到网页中重要的数据上,是的爬虫程序无法获得正确的数据。
接下来我们这一篇先从一个较简单的练习网址入手,之后通过其他几篇讲解不同的字体反爬案例,大家会了之后可以找一些有相关反爬的案例练手,好了,我们开始进入正题。
在上面我们已经通过Elements面板和网页源代码看过真实数据(网页源码显示的)是什么样的了。这里我们先到Network面板,然后Ctrl+R让页面重新加载,我们会看到的内容如下图:
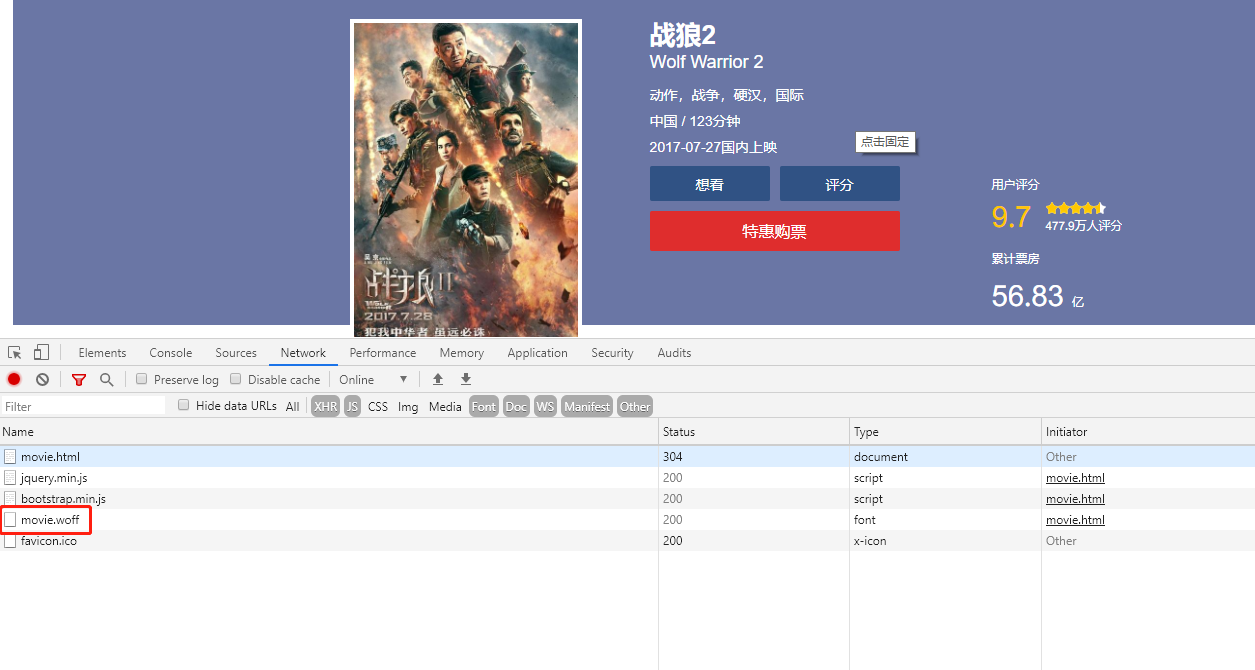
这里被我圈起来的这个woff文件是今天的重点,这个就是一个自定义字体文件。我们可以点击这个文件然后将URL复制到浏览器中去下载这个文件。
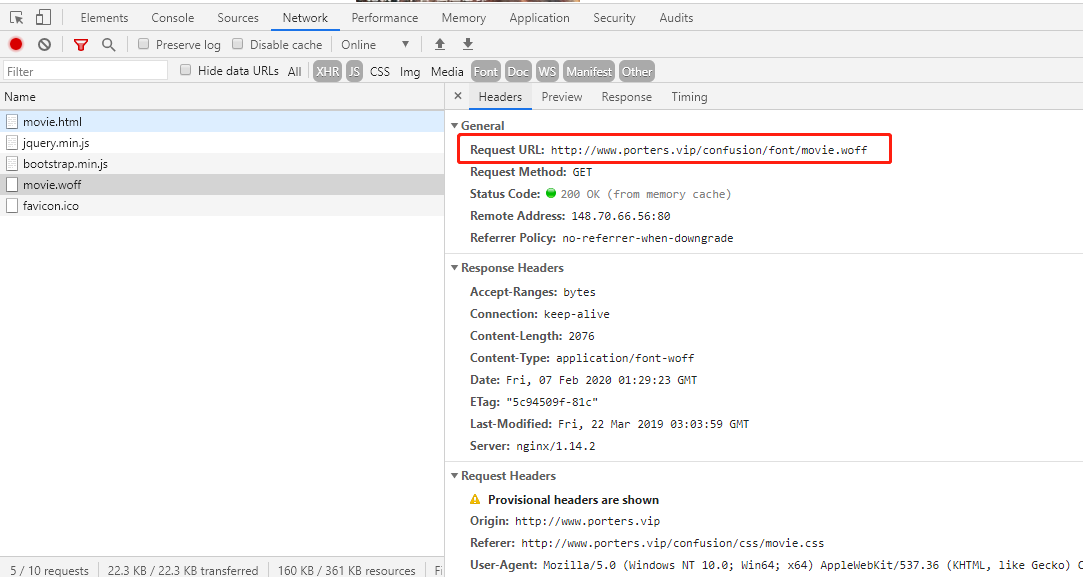
之后我们要用到一个叫FontCreator的工具(点击名称会直接跳到官网,当然也可以自己在网上找破解版),如果不想下载的话可以直接使用在线的工具-百度字体编辑器,这里我使用的是FontCreator工具,接下我们用工具打开刚才下载的woff文件,我们打开之后就会看到如下图所示的内容:
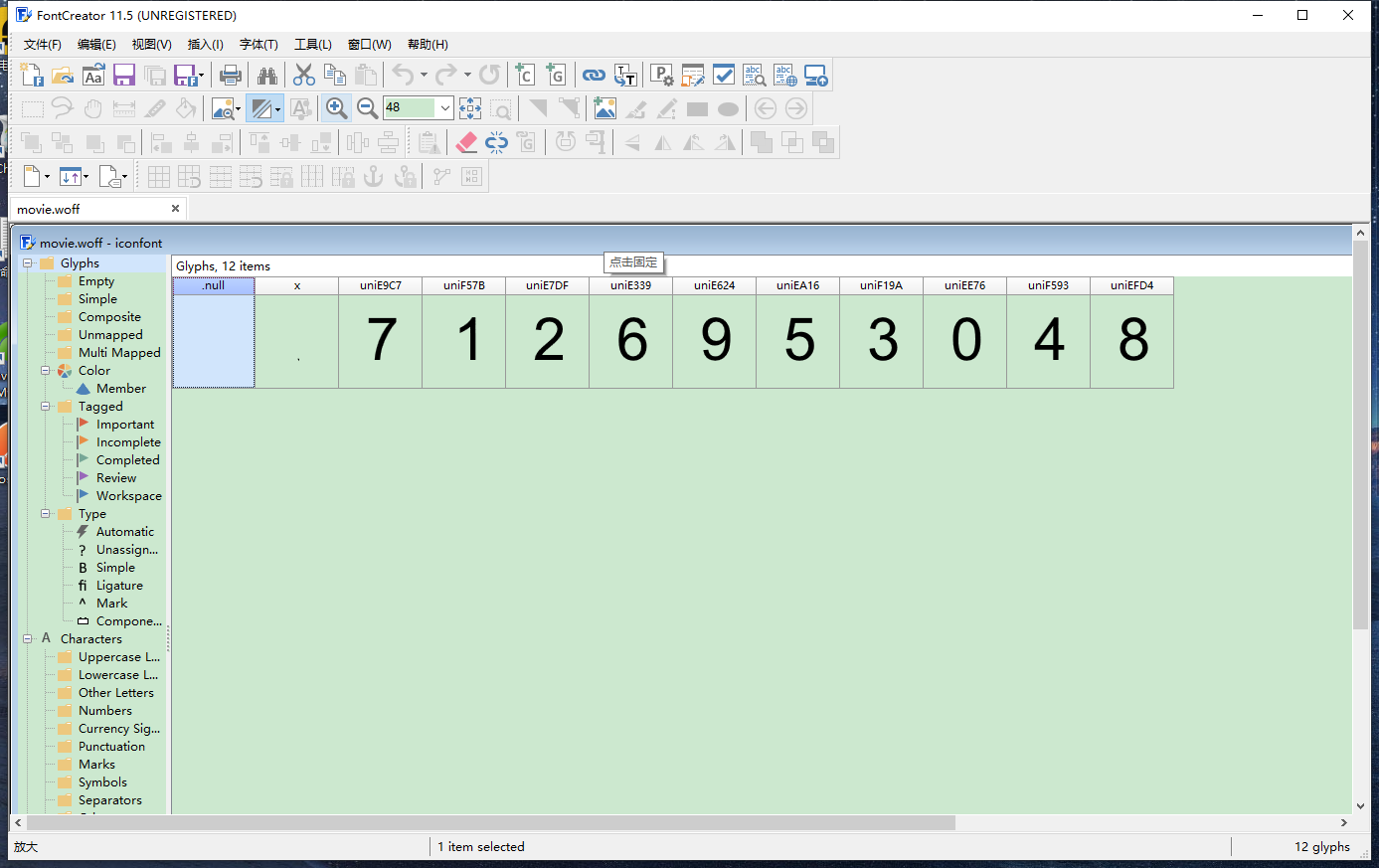
这里我们可以看到每个字符上面对应着一个编码,好了,我们开始使用代码来将woff文件中的数据展现出来,
这里我们会使用到一个叫fontTools的库,没有安装的可以在自己所在的环境中pip install fontTools,为了后续大家能看得懂,我先讲一下fontTools的使用方法,这里我给大家演示一下:
from fontTools.ttLib import TTFont
# TTFont() 用来打开woff文件的
movie_font = TTFont('movie.woff')
# 这里我们先看一下movie.off里面是什么样的
# 使用save()将拿到的文件数据保存为XML格式的文件
movie_font.saveXML('movie.xml')
我们打开保存的movie.xml文件,然后找到

这个就是文件中字符到字形映射表 < cmap > 的内容。这里我们回到代码中,接着上面的代码
#getBestCmap() 我们通过这个函数可以将字符关系映射起来
font_map= movie_font.getBestCmap()
print(font_map)
# 打印结果:
'''
{120: 'x', 58169: 'uniE339', 58916: 'uniE624', 59359: 'uniE7DF', 59847: 'uniE9C7',
59926: 'uniEA16', 61046: 'uniEE76',61396: 'uniEFD4', 61850: 'uniF19A',
62843: 'uniF57B', 62867: 'uniF593'}
'''
为了得到上图中 code和name的对应关系,这里我们需要做一个转换,代码如下 :
newmap= {}
for index, key in enumerate(font_map):
value = font_map[key]
# hex() 函数用于将10进制整数转换成16进制,以字符串形式表示
key = hex(key)
newmap[key] = value
print(newmap)
'''
{'0x78': 'x', '0xe339': 'uniE339', '0xe624': 'uniE624', '0xe7df': 'uniE7DF',
'0xe9c7': 'uniE9C7', '0xea16': 'uniEA16', '0xee76': 'uniEE76', '0xefd4': 'uniEFD4',
'0xf19a': 'uniF19A', '0xf57b': 'uniF57B', '0xf593': 'uniF593'}
'''
请大家仔细看,这个映射关系是不是和上图中的是一样的了,到这里为止就是讲解如何使用fontTools这个库从woff文件中拿到我们后面需要用到的映射关系了。
刚刚我们不仅讲解了如何使用fontTools这个库,而且还拿到了网站中woff文件里的映射关系,这里我们再去看网页源码,我们看一下网页中那些被反爬的数据:
用户评分:.
.万人评分
累积票房:.
我们将&#这两个字符换成0看看是怎么样的。
用户评分:0xe624. 0xe9c7
0xf593 0xe9c7 0xe9c7. 0xe624万人评分
累积票房:0xea16 0xe339. 0xefd4 0xf19a
为了让大家看的更清楚,这里我用空格将每个编码分开了,看看这里的编码格式是不是有些眼熟?没错,它就在我们刚才拿到的映射关系中,同样我们再仔细看看刚才的映射关系,看看字典中每个键对应的值,uni开头的,嗯?是不是很眼熟?对,你刚才肯定见过,在哪里见过呢?打开的XML文件中吗?不不不,不是这里,我们第一见到它是在用FontCreator工具打开woff文件的时候,我们再看一下:
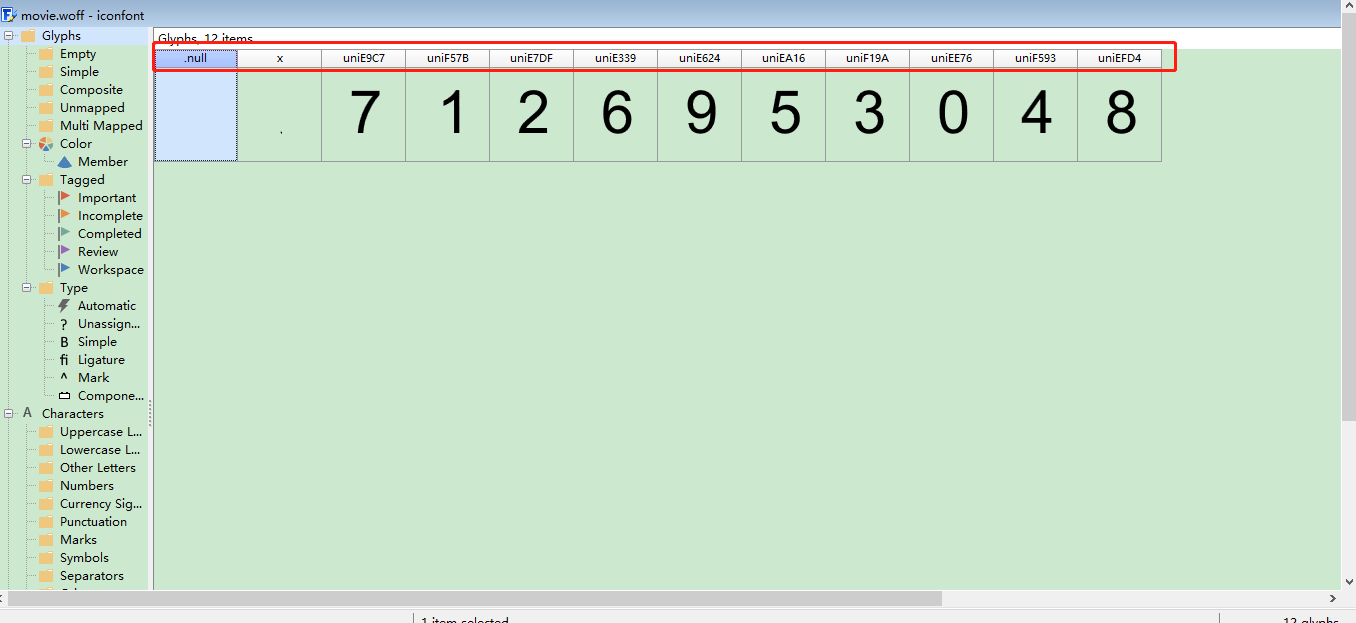
这个时候我们对比下,我们会发现字典中的每个值就是上图中每个字符对应的编码,那么整个关系不就出来了吗。手动将从FontCreator中获取的映射关系对应起来
relation_table = {'uniE9C7': '7', 'uniF57B': '1', 'uniE7DF': '2', 'uniE339': '6',
'uniE624': '9', 'uniEA16': '5','uniF19A': '3', 'uniEE76': '0', 'uniF593': '4',
'uniEFD4': '8'}
之后我们将这里每个键对应的值替换到我们用fontTools库拿到的映射关系中。(这里还是接着前面的代码)
for index, key in enumerate(font_map):
value = font_map[key]
# hex() 函数用于将10进制整数转换成16进制,以字符串形式表示
key = hex(key).replace('0', '&#')
# 为防止对关系中没有相应的value导致报错,这里捕捉下异常
try:
# 这里用
get_real_data = relation_table[value]
except:
get_real_data = ''
if get_real_data != '':
# 这里我们将字体文件中得到的编码字符和真是结果对应起来
newmap[key] = get_real_data
print(newmap)
# 打印结果:(这个也就是网页中编码与真实结果对应的关系)
'''
{'': '6', '': '9', '': '2', '': '7',
'': '5', '': '0', '': '8', '': '3',
'': '1','': '4'}
'''
到这里为止整个的对应关系都找出来了,我们将得到的这个映射关系去和网站中的编码去一 一对应一下看看。
用户评分:.
.万人评分
累积票房:.
对应出来的结果:
用户评分:9.7
477.9万人评分
累积票房:56.83
我们将这个结果和浏览器看到的结果对照一下,对,我们得到的最终结果和浏览器看到的是一样的,所以我们成功的破解了这个网站上的字体反爬,下面附上我的代码:
import requests, re
from fontTools.ttLib import TTFont
from io import BytesIO
from lxml import etree
# 这篇案例的编码是固定的,所以我们只需要在FontCreator中获取的映射关系即可
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'
}
# 手动将从FontCreator中获取的映射关系对应起来
relation_table = {'uniE9C7': '7', 'uniF57B': '1', 'uniE7DF': '2', 'uniE339': '6', 'uniE624': '9', 'uniEA16': '5',
'uniF19A': '3', 'uniEE76': '0', 'uniF593': '4', 'uniEFD4': '8'}
def woff_font(woff_url):
# 发送请求,获取响应
response = requests.get(woff_url)
woff_data = BytesIO(response.content)
# woff数据读取出来
font = TTFont(woff_data)
obj_list = font.getGlyphNames()[1:-1]
# 将读取出来的woff数据转为映射关系
cmap = font.getBestCmap()
font.close()
return cmap, obj_list
# 这里我们就不下载文件了,直接通过访问这个网址拿到woff文件中的数据
woff_url = 'http://www.porters.vip/confusion/font/movie.woff'
font_map, obj_list = woff_font(woff_url)
print(font_map)
# 打印结果:(这里显示的是10进制与编码的映射管辖)
# {120: 'x', 58169: 'uniE339', 58916: 'uniE624', 59359: 'uniE7DF', 59847: 'uniE9C7',
# 59926: 'uniEA16', 61046: 'uniEE76',61396: 'uniEFD4', 61850: 'uniF19A',
# 62843: 'uniF57B', 62867: 'uniF593'}
# 从font_map中将不需要的映射关系删除
newmap = {}
for index, key in enumerate(font_map):
value = font_map[key]
# hex() 函数用于将10进制整数转换成16进制,以字符串形式表示
key = hex(key).replace('0', '&#')
# 为防止对关系中没有相应的value导致报错,这里捕捉下异常
try:
# 这里用
get_real_data = relation_table[value]
except:
get_real_data = ''
if get_real_data != '':
# 这里我们将字体文件中得到的编码字符和真是结果对应起来
newmap[key] = get_real_data
print(newmap)
# 打印结果:(这个也就是网页中编码与真实结果对应的关系)
# {'': '6', '': '9', '': '2', '': '7', '': '5',
#'': '0', '': '8', '': '3', '': '1', '': '4'}
url = 'http://www.porters.vip/confusion/movie.html'
reponse_html = requests.get(url, headers=headers).text
# 这里直接在html页面使用正确数据将这些乱码或者编码替换掉
for i in newmap:
check_html = re.search(i, reponse_html)
if check_html != None:
reponse_html = re.sub(i, newmap[i], reponse_html)
# 这个时候可以使用正则或则Xpath(自己喜欢获取数据的方式)获取数据就行了
html = etree.HTML(reponse_html)
# 通过Xpath拿到数据
user_grade = html.xpath('//span[contains(@class,"info-num")]/span/text()')[0].strip()
user_grade_count = html.xpath('//span[@class="score-num"]//span/text()')[0].strip()
box_office_count = html.xpath('//span[contains(@class,"unit")]/preceding-sibling::span/text()')[0].strip()
print('用户评分:' + user_grade, '\n' + user_grade_count + '评分', '\n累积票房:' + box_office_count)
# 打印结果:
"""
用户评分:9.7
477.9万评分
累积票房:56.83
"""
以上就是这一篇要讲解的关于字体反爬的类容,关于字体反爬可不仅仅只有这一个案例,这个案例是比较简单的,后面还有更难的案例,比如58同城、猫眼电影票房、汽车之家、大众点评等等,像猫眼电影票房中,每次访问加载的字体文件中的字符的编码可能是变化的(字体形状不变),也就是说你如果仅仅只用一个woff文件去获取对应的关系很有可能也是拿不到正确的数据的,还有更难一些的,比如汽车之家的字体反爬,不仅是编码变化,而且是字体形状也有变化。就是说对象本身变化,不能再直接用比较对象的方法处理。
欢迎关注公众号:【时光python之旅】 (在这里你能学到我的所见、所闻、所思、所学)

- 点赞
- 收藏
- 关注作者
评论(0)