分布式系统设计理论之一致性哈希

分布式系统设计理论之一致性哈希
主要参考和围绕这篇论文讲解:Consistent Hashing
1 问题引入
什么是一致性哈希?为什么要用一致性哈希?
2 一致性哈希算法出现之前的分布式系统设计
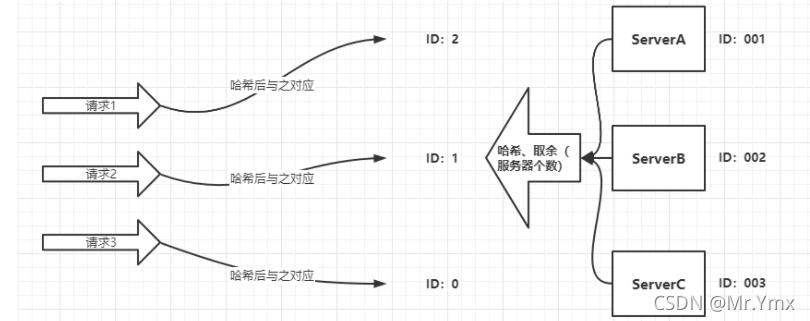
例如系统需要构建分布式缓存,多个节点分别部署而形成的一个分布式集群,当有请求到来时进行负载均衡,具体的负载均衡方式就是将节点的ID(唯一标识)进行哈希值的取余运算,得到结果的机器就是进行请求处理的机器。
上述方式存在的问题:
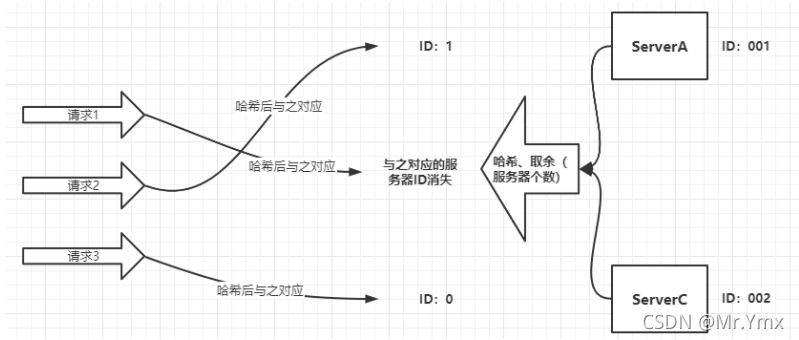
当一个节点进行更换(增加或删除节点)时,原有的节点消失或增加新的节点,会导致多个请求同时指向一个节点进而造成节点的宕机等问题。
总之一句话就是,当服务器个数发生改变时,缓存可能会失效。
图解:
正常情况下:
删除一个服务器之后:
3 什么是一致性哈希,它是如何解决上述问题的?
3.1 一致性哈希的核心思想
⼀致性哈希算法的基本思想是使⽤相同的哈希函数服务器节点对象和请求的缓存进⾏哈希,即⼀致地将对象映射到相同的缓存机器。
3.2 引入哈希环
整数int在Java中的取值范围是2的-31次方到2的31次方-1之间,那么就可以让请求的缓存和服务器节点同时进行相同的哈希算法后得到一个int值,进而形成一个哈希环,请求和服务器节点保持“顺时针就近”原则进行对应的请求:
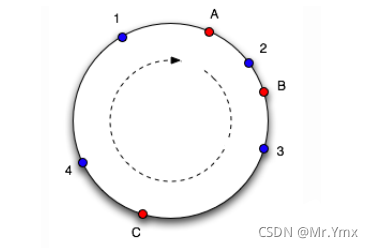
A,B,C代表三个服务器节点,1,2,3,4代表着不同的缓存请求,按照“顺时针就近”原则,1,4会请求服务器A节点,2请求服务器B节点,3请求服务器C节点。
3.3 存在问题
(1)增删节点带来的问题

新增服务器节点D,按照之前的原则4就会向服务器D节点发起请求,在4和D之间的一部分缓存将会失效,这是问题之一。
(2)哈希倾斜
所谓哈希倾斜就是表示如上图,服务器A,B相距较近,假如没有服务器D节点,那么B到A这一段的请求都会落在A节点上,即大部分请求都指向A节点,而极少部分请求放在了B节点,这个问题就是“哈希倾斜”。
3.4 增加虚拟节点解决问题
解决上边两个问题的最佳方案就是增加虚拟节点,就是在哈希环中增加无数个虚拟节点,请求指向虚拟节点,虚拟节点指向真实节点,这样就会增加请求平均的概率,如图:
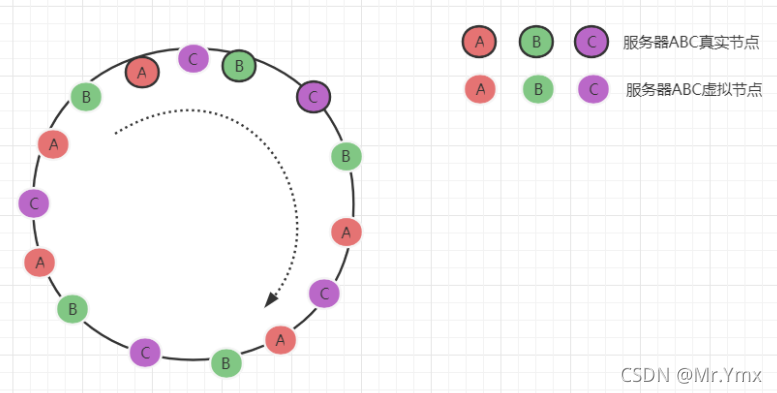
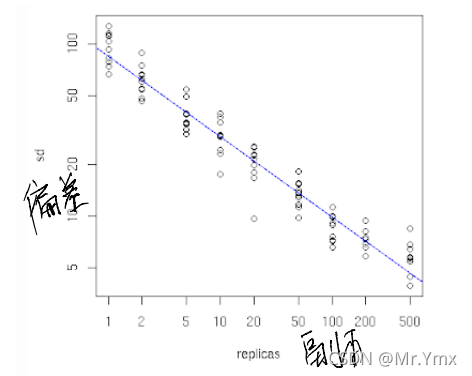
而且论文中还指出,虚拟节点的数量越大,请求产生的偏差越小:
4 Java代码实现一致性哈希
/**
* @desc: Java实现一致性哈希
* @author: YanMingXin
* @create: 2021/10/16-16:46
**/
public class ConsistentHash<T> {
/**
* 哈希函数类
*/
private final HashFunction hashFunction;
/**
* 虚拟节点个数(不同节点一共的,会自动平均)
*/
private final int numberOfReplicas;
/**
* 哈希环
*/
private final SortedMap<Integer, T> circle = new TreeMap<Integer, T>();
/**
* 构造方法
*
* @param hashFunction 自定义哈希函数类(必须有hash()方法)
* @param numberOfReplicas 副本个数
* @param nodes 服务器节点
*/
public ConsistentHash(HashFunction hashFunction,
int numberOfReplicas, Collection<T> nodes) {
this.hashFunction = hashFunction;
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
add(node);
}
}
public ConsistentHash(int numberOfReplicas, Collection<T> nodes) {
this.hashFunction = new HashFunction();
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
add(node);
}
}
/**
* 向哈希环增加节点的副本
*
* @param node
*/
public void add(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.put(hashFunction.hash(node.toString() + i), node);
}
}
/**
* 删除节点
*
* @param node
*/
public void remove(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.remove(hashFunction.hash(node.toString() + i));
}
}
/**
* 根据请求得到他将要访问的节点
*
* @param key
* @return
*/
public T get(Object key) {
if (circle.isEmpty()) {
return null;
}
//将请求hash转换
int hash = hashFunction.hash(key);
//将请求放入哈希环
if (!circle.containsKey(hash)) {
//返回该映射中键值大于或等于hash的部分的视图。
SortedMap<Integer, T> tailMap = circle.tailMap(hash);
//判断tailMap是否为空,是则返回哈希环第一个节点的值,反之则返回最近的节点
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hash);
}
/**
* 哈希函数类
*/
class HashFunction {
/**
* 具体的哈希函数
*
* @param key
* @return
*/
public int hash(Object key) {
return key.hashCode() / Integer.MAX_VALUE;
}
}
}
部分图片和内容来自:http://tom-e-white.com/2007/11/consistent-hashing.html

- 点赞
- 收藏
- 关注作者
评论(0)