【每日一读】Leveraging network structure for efficient dynamic negativ

@TOC

简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
【每日一读】每天浅读一篇论文,了解专业前沿知识,培养阅读习惯(阅读记录 仅供参考)
论文简介
原文链接:https://www.sciencedirect.com/science/article/pii/S002002552200545X?via%3Dihub
期刊:Information Sciences (CCF B类)
年度: 2022年8月(发表日期)
Abstract
无监督网络嵌入根据网络结构学习节点的低维向量表示。然而,典型的图只包含正边。因此,大多数网络嵌入模型都以采样的负边作为输入,以避免解的琐屑
然而,传统的负采样方法遵循固定的分布产生负样本。这样的静态采样策略可能会极大地损害下游任务中节点嵌入的性能
研究人员提出了几种自适应抽样策略来提高负样本的质量
然而,现有的方法没有充分利用网络结构来挖掘高质量的样本,导致负采样复杂且效率低下
本文提出了一种新的动态负抽样方案,该方案为每个节点保持一个候选样本种群。我们动态地更新种群,并在每次迭代中保留高质量的样本
在此基础上,我们提出了一种新的网络嵌入算法,该算法能从种群中自适应地选择高质量的负样本。我们基于多个基准数据集进行了大量的实验来评估其有效性。实验结果验证了所提方法优于现有方法的优越性。
1. Introduction
网络嵌入从图结构数据中学习节点的低维表示。网络嵌入的基本思想是保持节点在潜在空间中的接近性,即相似度越高的节点在嵌入空间中的距离越小。该技术已经获得了广泛的应用,如节点分类和聚类[1-3]、链接预测[4,5]、网络可视化[6,7]、推荐[8,9]、社区检测[10-12]和社会网络分析[13]。由于网络嵌入的有效性,研究人员开发了许多有用的算法,如DeepWalk[14]、Node2vec[15]、LINE[16]、GraRep[17]和Struc2vec[18]。大多数这些方法都使用Skip-gram模型[19]来学习节点嵌入,因为它有效且简单。
Skip-gram模型将正样本和负样本都作为输入。它在嵌入空间中将相似的节点(正样本)拉到一起,而将不相似的节点(负样本)推开。然而,典型的图数据只包含正边,由于没有显式提供有用的负样本,因此很难检索到它们。此外,检索所有负样本的计算量很大。因此,大多数网络嵌入方法都是采用负采样,根据预先设计的分布,如节点度分布,生成负样本。这种静态抽样策略的结果是,节点的度高,被选中的概率大,而连接数少的节点往往被忽略。然而,在实际中,一些连接较少的节点对于嵌入特定的节点可能是有用的。另外,基于节点度的采样,由于节点度高,暴露率高,使得节点的嵌入向量非常小。这种过度收缩会降低嵌入的质量。
此外,使用固定抽样分布也是有问题的。在训练过程的最初几个步骤中,我们没有多少信息来评估节点的信息量。因此,根据先验分布生成负样本是很直观的。然而,在训练过程中,一些负节点被推离目标节点。这些节点对目标节点的信息较少,被选中的概率也较低。因此,我们应该动态关注这些具有高信息量的节点。然而,挖掘有信息的负样本具有挑战性,因为只有在训练过程中选择节点才能确定节点的信息量。因此,动态负采样策略可用于动态感知节点的信息量。
为了解决上述问题,开发了几种有用的抽样策略。它们大多采用生成对抗网络(GAN)动态选择高质量的负样本[20-22]。**然而,这些基于gan的方法需要训练额外的参数来拟合负样本的完整分布,计算效率很低。**此外,由于模型复杂度高,这些方法存在不稳定性和简并性。有研究提出在训练过程中动态捕获节点的信息量[23,24],解决了探索与利用问题。遗憾的是,这些方法在负样本的更新过程中未能充分利用网络结构,导致负样本的挖掘效率低下。
提出了一种新的网络嵌入动态负采样框架。其基本思想是从为每个目标节点精心维护的样本种群中选择高质量的负样本。种群由三种节点组成,包括幸存者、衍生物种和外来物种。幸存者是我们想要保留的最后一代种群中的合格样本。衍生品是基于幸存者产生的衍生品。我们提出了一种基于网络结构的高效生成方案来生成可能的高质量负样本。Exotics表示模型的探索能力,是从静态分布(如节点的度分布)中随机生成的。我们设计了一个方案,改变不同节点类型的比例,在优质负样本的开发和探索之间取得很好的平衡。
最后,我们基于提出的负采样算法开发了一种嵌入方法,并通过实验验证了其有效性。实验结果表明,该方法能显著提高网络嵌入质量,优于现有的嵌入方法。综上所述,我们作出了以下贡献:
- 我们提出了一个保持进化种群的动态负抽样框架,该框架包含三种节点样本。它允许我们为特定节点选择适当的负样本,并动态更新负候选。
- 我们开发了一种动态调整不同种类样本在种群中所占比例的方案,保持了对优质负样本的开发和探索之间的平衡。
- 该方法利用网络结构有效挖掘潜在的高质量负样本,显著提高了算法的探测能力。
- 通过大量的实验验证了基于多个下游任务的方法的有效性。实验结果表明,提出的负采样策略明显优于现有方法。
2. Related Work
2.1. Network Embedding
近年来,网络嵌入因其在网络分析中的重要作用而引起了人们的广泛关注。现有的方法大致可以分为三类:
- 基于矩阵分解的方法
- 基于结构上下文推理的模型
- 基于深度神经网络的方法
基于矩阵分解的方法如HOPE[25]和GraRep[17]采用传统的矩阵分解算法如奇异值分解(SVD)来学习节点的低维表示。
基于结构上下文推理的方法采用负采样的Skip-gram模型来训练有意生成的节点结构上下文
- DeepWalk[14]作为一项开创性的工作,利用随机行走获得的局部信息,将行走路径作为句子的等价对待,来学习潜在的表征
- Node2vec[15]采用有偏随机游走过程,由附加参数p和q引导,生成节点的结构上下文
- LINE[16]学习网络的低维表示,它既保留了本地网络结构,也保留了全局网络结构
- Struc2vec[18]构造多层图,对不同尺度的结构相似度进行编码,并根据构造的多层图进行随机游走,生成节点的结构上下文。
最近,将图结构数据嵌入到双曲空间中也因其捕获潜在层次结构的有效性而受到越来越多的关注[26,27]。
基于深度神经网络的方法利用神经网络的非线性特性,将图的原始离散表示转化为低维连续向量空间
- SDNE[28]采用具有多层非线性函数的半监督深度模型来捕获网络结构的隐藏信息
- DNGR[29]采用随机冲浪模型捕获图的结构信息
- sin[30]是一个针对有符号网络的深度神经网络学习框架,它在图论的指导下优化目标
- 图卷积网络(GCNs)基于一种高效的分层传播规则[31]对图结构和节点特征进行编码
- GraphSAGE[32]利用节点特征信息有效地学习节点嵌入
- ID-GNN[33]通过考虑消息传播过程中节点的身份和结构信息,提高了图神经网络(GNNs)的表达能力
- NINE[34]采用生成对抗网络学习节点嵌入,旨在捕获节点对的局部信息。
综上所述,负采样在大多数网络嵌入算法中起着至关重要的作用。然而,负样本对网络嵌入质量的影响一直被忽视。
2.2. Improvements of Negative Sampling
近年来,已有多种方法试图改善负抽样的质量
几种方法利用生成对抗网络(GAN)以强化学习的方式进行自适应负采样
- Wang等人[20]设计了一个生成器来获取高质量的负样本,并设计了一个鉴别器来更新嵌入
- Cai和Wang[21]利用嵌入模型作为负样本生成器来辅助所需模型的训练
然而,这些基于gan的算法由于模型复杂度高,存在不稳定性和简并性
- Zhang等人[23]设计了一种缓存方案来跟踪高质量的负样本进行知识图嵌入
- Dai等人[22]提出了一种对抗采样方法,为网络嵌入生成负样本
- Gao等人[24]提出了一种基于训练状态动态捕获节点信息量的自节奏网络嵌入算法
但这些方法都不能有效利用网络结构对高质量负样本进行挖掘和挖掘。
Armandpour等人[35]使用智能抽样方案和参数惩罚对鲁棒负样本进行抽样
然而,他们并不关注是什么构成了高质量的阴性样本
Chen等人[36]首先检测了群落结构,避免了同一群落中的节点被误采样为负样本。该方法在训练过程中无法探索抽取高质量的负样本
Kalantidis等人[37]分析了硬负样本在计算机视觉领域对比学习中的作用。他们提出了混合负样本的对比学习方案。然而,该方法忽略了网络结构对负样本生成的影响
最近,Yang等人[38]分析了负抽样的作用,从理论上证明了负抽样在确定优化目标和由此产生的方差方面与正抽样同样重要。他们在理论的基础上提出了马尔可夫链蒙特卡罗负采样策略来提高性能。
与现有的方法不同,我们的方法为每个目标节点维护一个填充。我们调整了不同样本在种群中的比例,以更好地平衡优质负样本的开发和探索。此外,我们的方法利用网络结构,有效地生成潜在的高质量负样本。
3. Preliminaries
将网络表示为g1 /4 ðV;EÞ,其中V是节点的集合,E表示边的集合。设n 1/4 jVj和m 1/4 jEj分别表示节点数和边数。网络嵌入方法定义为映射functionMðGÞ: V !Xn d从节点集V到d维向量空间x,其基本思想是将相似的节点推到一起,同时将潜在空间中不相似的节点推到一边。一些网络嵌入方法,如DeepWalk[14]、Node2Vec[15]、LINE[16]和Struc2vec[18],都使用Skip-gram模型[19]来学习节点嵌入。该模型通过最大化似然函数来预测目标节点vi的上下文:

其中Cvi表示目标节点vi的上下文节点集,pðvjjviÞ表示给定vi时vj的条件概率。不同的方法采用不同的方案构造目标节点的上下文集。例如,DeepWalk和Node2vec使用截断随机漫步来学习节点的上下文信息。LINE使用一阶(一跳邻居)和二阶(邻居的邻居)关系来构造上下文集。
Skip-gram模型作为一个多类分类器,其中类的数量为节点的数量n。当n非常大时,直接求解Eqn。(1)在计算上是昂贵的。因此,提出了一个采用负抽样方法的等价问题:

其中vj2cvi为vi的正上下文节点;NCvi为采样的vi的负上下文节点集,vk为vi的负上下文节点,设k 1/4 jNCvi j为负样本数。负抽样将计算复杂度从OðnmÞ降低到OðkmÞ。当k = n时,效率明显提高。将正上下文集和负上下文集都输入到Skip-gram模型中,更新目标节点在每个训练历元中的嵌入向量。负上下文集在每个时代的开始时生成。传统的负抽样方法通常根据固定分布(如度分布)生成NCvi。然而,它有两个缺点。首先,这种抽样策略忽略了一些连接较少的节点,这可能对特定节点有用。第二,该方法没有捕捉到训练过程的动态性。本文提出了一种新的动态负采样框架来解决这些问题。
在训练过程中,节点的嵌入更新如下:

其中,þ1包含模型中需要更新的所有参数,gt是第t代的学习率;5为梯度算子,L为损失函数,用于评价当前嵌入的质量。
4. Our Solution
本文基于进化算法的思想,提出了一种新的动态负采样方法。图1是我们方法的流程图。基本思路是逐步学习高质量的负样本。因此,我们为每个目标节点维护一个样本总体。在每个训练阶段,我们从维持种群中检索负样本。更新节点嵌入后,更新种群,保持高质量样本。在最初的几个训练步骤中,我们对节点的信息量知之甚少。因此,我们从预先设计的分布中抽取随机样本开始。随着训练的进行,我们可以根据适当的标准[23]来评估所选负样本的质量。这些高质量的样本不仅可以用于培训,还可以用来衍生出更有用的样本。其动机是高质量负样本的邻居对于相同的目标节点有很高的概率成为有益样本。根据这一原理,我们在模型已经识别的负样本的基础上,生成更多高质量的负样本。它解决了负采样中的利用问题。此外,我们改变种群中优质节点样本的分数来解决探索问题。
4.1. Sample Types
具体来说,我们在训练过程中为目标节点vi维护一个样本总体Pvi。设N 1/4 jPvi j表示总体中样本的数量。种群包含三种个体,包括幸存者Svi、衍生dvi和外来Ivi。S tvi的比例;tvi和ptvi中的I tvi在第t个纪元用at表示;分别是Bt和ct。我们在逐渐调整;随着训练的进行,根据训练的阶段进行训练。最初,我们设为1/4 bt 1/4 0当t 1/4 0。在最初的几个步骤中,我们对节点的信息量知之甚少。因此,at和bt应该很小。随着培训的进行,我们可以获得更多关于样品质量的知识。因此,at和bt应该随着t逐渐增加。因此,我们使用移位的Sigmoid函数来计算at的值:

其中,amax和a为可调参数;T是最大迭代次数。由于导数是基于余数产生的,在本文中我们设置:

至于异域风情,我们有:

4.2. Evolution of Population
我们在每个训练阶段结束时更新种群。给定节点vi的当前总体为P tvi,我们生成stv . 1vi;D . þ1vi, I . þ1vi如下。
1)幸存者的生成:幸存者S tþ1vi包含从P tvi中保留的样本。幸存者是根据健康分数选出来的。根据网络嵌入的几何性质,我们设计了一个适合度评分函数如下:

哪里 sðxi; xjÞ 表示目标节点 vi 和 vj 在当前状态下的相似度。我们将 P tvi 中的样本按其适应度得分降序排序,并将顶部的蝙蝠 Nc 节点放入 Stþ1vi 。不难看出,与目标节点相似度较高的样本是首选。在本文中,我们使用余弦相似度:

其中 xi 和 xj 分别是在 t 时期 vi 和 vj 的节点嵌入。
2)导数的生成:在本文中,我们提出了一种生成方案,可以有效地基于网络结构生成高质量的负样本。直觉是,与高质量的负节点连接的节点对于同一目标节点来说是高质量的概率很高。给定幸存者 S tþ1vi ,我们收集所有候选节点如下:

其中 Nvj 是 vj 的直接连接邻居的集合,Cvi 是 vi 的正上下文节点的集合。然后,我们从 RSvi 中随机选择 bbt Nc 节点来构造导数 Dt+1vi 。值得注意的是,我们允许在生成导数时重复节点。所以导数的实际分数可能小于 bt
3)Exotics的生成:Exotics代表了模型的探索能力,可以找到更多高质量的负样本,提高训练模型的通用性。在本文中,我们根据静态分布 PðvÞ / d3=4v [16,19] 从 V 中随机选择 dct Ne 奇异值作为 I tþ1vi。我们还允许在生成外来物时重复节点。
最后,我们更新人口如下:

在新的训练时期,我们从 P t+1vi 中随机选择 k 个负样本作为 vi,样本被选择的概率等于其适应度得分。
衍生节点由幸存者的邻居生成,利用网络结构进行高质量的负样本探索。它允许我们在总体中添加更多潜在的高质量负样本。我们认为靠近目标节点的样本是高质量的。因此,我们计算种群中节点的适应度分数,该分数捕获派生节点与目标节点的相似性。然后,我们利用高质量的负样本选择具有最高适应度分数的顶部节点作为下一次迭代的幸存者。因此,我们平衡了负样本的开发和探索。
4.3. The Embedding Model
本节介绍了具有提议的动态负采样的网络嵌入模型。嵌入模型的伪代码如算法 1 所示。我们首先随机初始化嵌入向量,并根据节点度分布为每个节点生成一个样本总体。然后我们将图中的边缘视为正样本。在每次迭代中,我们对一个 mini-batch S 批次进行采样,其中包含图中的许多边。对于 Sbatch 中的每个目标节点,我们根据样本适应度分数的分布更新其总体并检索负样本。最后,我们将正样本和负样本提供给 Eqn。 (3) 用于嵌入更新。在本文中,我们将损失函数定义为:

其中vi是目标节点,vj是vi的上下文节点,NCvi是负样本集。

值得注意的是,由某些现有方法初始化的向量将导致更快的收敛 [39,40]。然而,这项工作的重点是使用更好的负采样策略来改进网络嵌入。我们随机初始化节点嵌入向量,以便更清楚地评估负采样的效果。我们将在未来的工作中评估向量初始化的效果。
5. Experiments

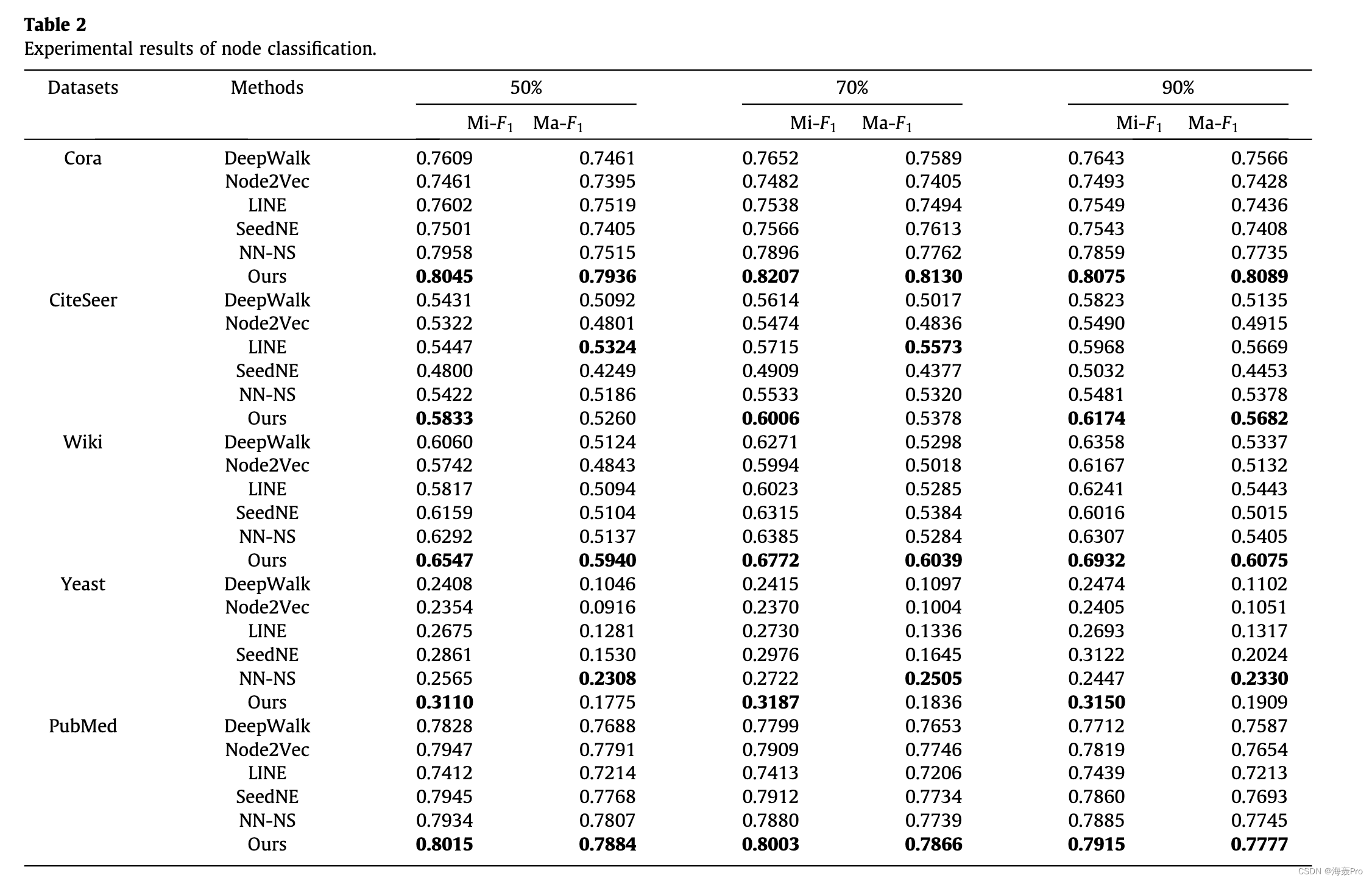
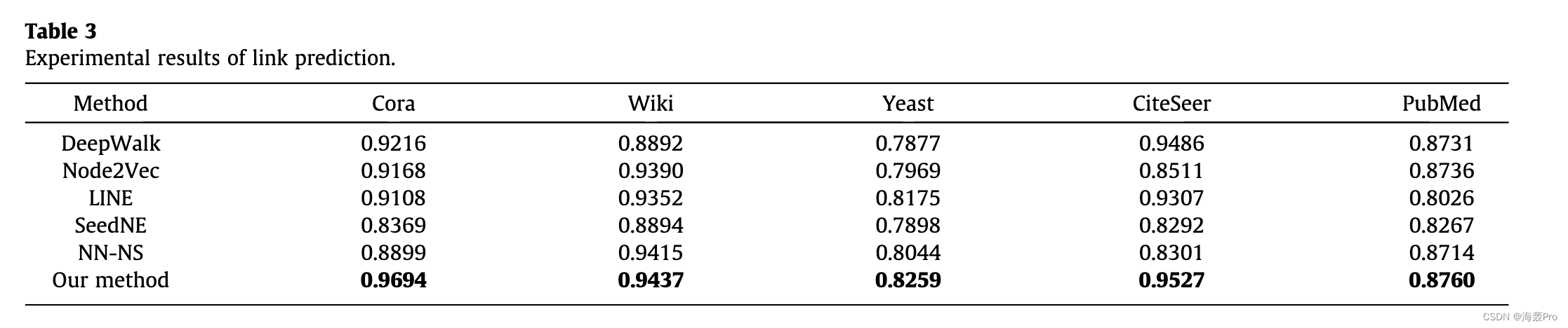
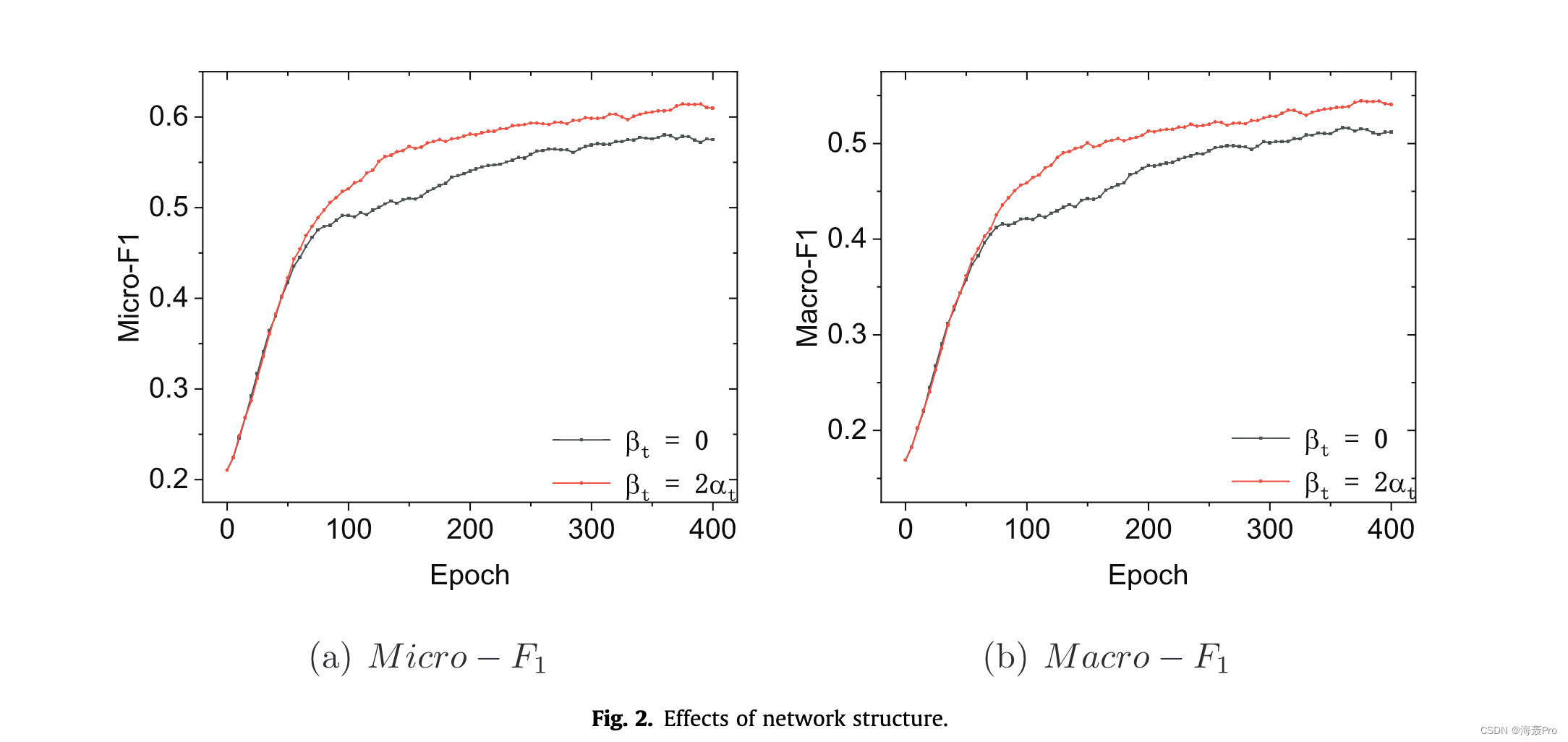

6. Conclusion and Future Work
本文提出了一种用于高质量网络嵌入的新型动态负采样框架。我们的方法为每个目标节点维护一个样本群,并在训练过程中持续跟踪高质量的负样本。我们还开发了一种利用网络结构来探索可能的高质量负样本的方案,这些负样本易于在其他基于负采样的网络嵌入方法中使用。我们将探索在未来的工作中将我们的负抽样方案应用于对比学习的可能性。最后,我们基于所提出的负采样方法开发了一种嵌入算法,并进行了实验以评估其在多个下游任务中的有效性。实验结果表明,所提出的负采样方法优于最先进的方法。
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正


- 点赞
- 收藏
- 关注作者
评论(0)