深入Redis数据结构和底层原理

【摘要】 1 概述Redis为什么能支持每秒钟十万级的高并发?基于内存的存取方式高效的数据结构单线程,使用多路I/O复用模型,非阻塞IO…其中一个重要的原因,就是Redis中高效的数据结构,因此我们就专门的来研究下Redis的核心数据结构,Go! 2 五大基本数据结构分别是String、List、Set、ZSet、MapString类型:一个String类型的value最大可以存储512MList类...
1 概述
Redis为什么能支持每秒钟十万级的高并发?
- 基于内存的存取方式
- 高效的数据结构
- 单线程,使用多路I/O复用模型,非阻塞IO
- …
其中一个重要的原因,就是Redis中高效的数据结构,因此我们就专门的来研究下Redis的核心数据结构,Go!
2 五大基本数据结构
分别是String、List、Set、ZSet、Map
-
String类型:一个String类型的value最大可以存储512M
-
List类型:list的元素个数最多为2^32-1个,也就是4294967295个。
-
Set类型:元素个数最多为2^32-1个,也就是4294967295个。
-
Hash类型:键值对个数最多为2^32-1个,也就是4294967295个。
-
Sorted set类型:跟Sets类型相似,但是有序。
2.1 String
(1)使用
127.0.0.1:6379> set str hello
OK
127.0.0.1:6379> get str
"hello"
(2)原理
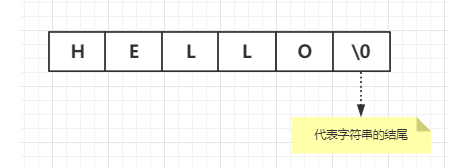
(3)源码
typedef char *sds;
/* Sdshdr5从未被使用过,我们只是直接访问标记字节,在这里是为了记录类型5 SDS字符串的布局。*/
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3LSB的类型,5MSB的字符串长度 */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len;
uint8_t alloc; /* 排除头和空结束符 */
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len;
uint16_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len;
uint32_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len;
uint64_t alloc;
unsigned char flags;
char buf[];
};
2.2 List
(1)使用
127.0.0.1:6379> lpush items a b c
(integer) 3
127.0.0.1:6379> lrange items 1 10
1) "b"
2) "a"
127.0.0.1:6379> lrange items 0 10
1) "c"
2) "b"
3) "a"
127.0.0.1:6379> lpush items d
(integer) 4
127.0.0.1:6379> lrange items 0 10
1) "d"
2) "c"
3) "b"
4) "a"
127.0.0.1:6379> lpop items
"d"
127.0.0.1:6379> lrange items 0 10
1) "c"
2) "b"
3) "a"
(2)原理
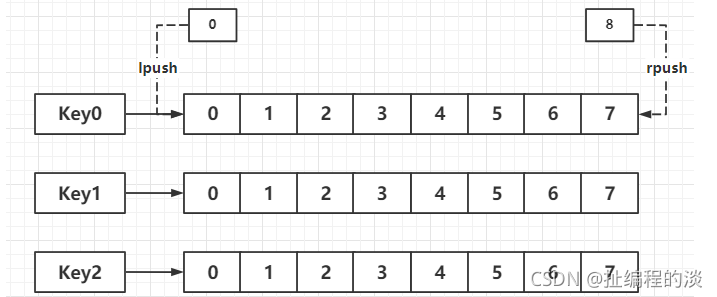
(3)源码
typedef struct listNode {
struct listNode *prev; //头指针
struct listNode *next; //尾指针
void *value; //节点的值
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
2.3 Set
(1)使用
127.0.0.1:6379> sadd set_items a b c c d d
(integer) 4
127.0.0.1:6379> smembers set_items
1) "c"
2) "b"
3) "d"
4) "a"
127.0.0.1:6379> sadd set_items e
(integer) 1
127.0.0.1:6379> smembers set_items
1) "d"
2) "a"
3) "e"
4) "b"
5) "c"
127.0.0.1:6379>
(2)原理
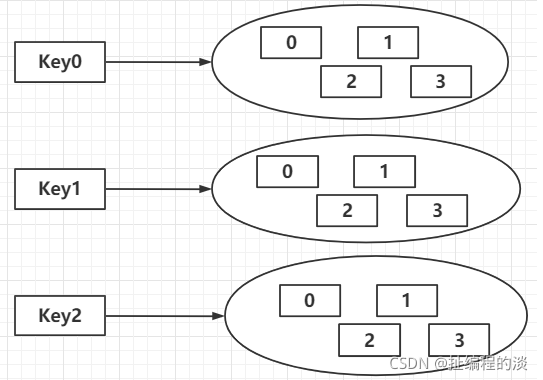
(3)源码
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
2.4 ZSet
(1)使用
127.0.0.1:6379> zadd zset_items 1 a 2 c 3 b
(integer) 3
127.0.0.1:6379> zrange zset_items 0 10
1) "a"
2) "c"
3) "b"
127.0.0.1:6379> add 2 d
(error) ERR unknown command 'add'
127.0.0.1:6379> zadd zset_items 2 d
(integer) 1
127.0.0.1:6379> zrange zset_items 0 10
1) "a"
2) "c"
3) "d"
4) "b"
(2)原理
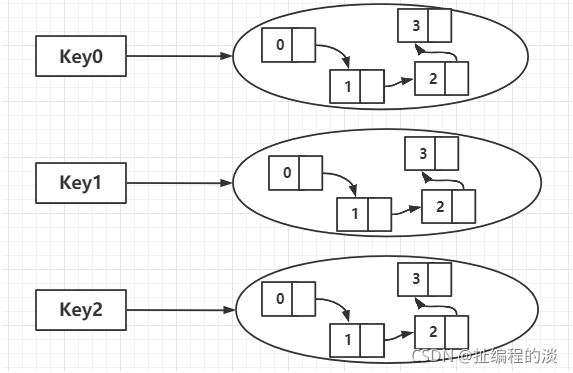
(3)源码
/* ZSET使用特殊版本的跳表 */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel { // 跳表的层数
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail; //头指针和尾指针
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict; //哈希表
zskiplist *zsl; //跳表
} zset;
2.5 Map
(1)使用
127.0.0.1:6379> hmset map name zs age 12
OK
127.0.0.1:6379> hgetall map
1) "name"
2) "zs"
3) "age"
4) "12"
127.0.0.1:6379> hget map name
"zs"
127.0.0.1:6379> hmset map school zz
OK
127.0.0.1:6379> hgetall map
1) "name"
2) "zs"
3) "age"
4) "12"
5) "school"
6) "zz"
127.0.0.1:6379> hdel map age
(integer) 1
127.0.0.1:6379> hgetall map
1) "name"
2) "zs"
3) "school"
4) "zz"
127.0.0.1:6379>
(2)原理
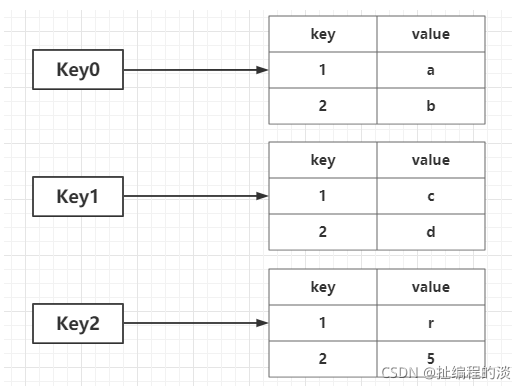
(3)源码
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* 这是哈希表结构。 当我们实现增量重哈希时,每个字典都有两个这样的表,从旧表到新表。 */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
unsigned long iterators; /* 当前运行的迭代器数量 */
} dict;
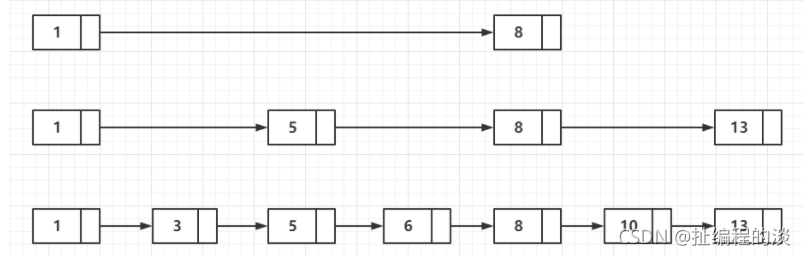
3 重点讲下跳表(SkipList)这个数据结构
3.1 图解
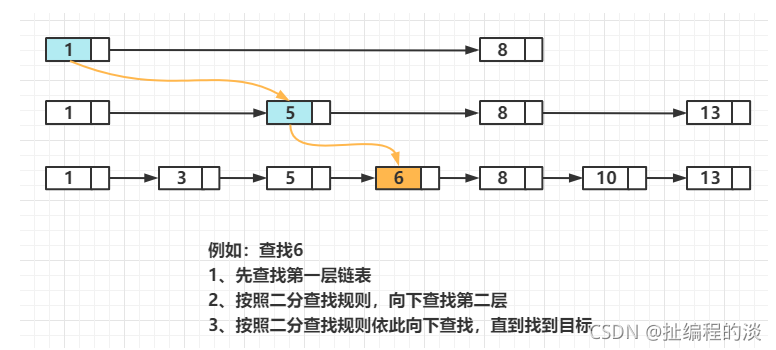
3.2 查找过程

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)