卷积神经网络详细指南

@TOC
全连接神经网络
全连接网络原理简述
我们举一个例子,假设房子的价格为y,那么他的地点x1与面积x2都与体制有关我们设定公式:
假设我们让这个模型训练了n轮,得到了最优解,权重系数
=0.3,
,我们就可以相对的认为地点与面积对房价的影响程度不同。而在实际场景中,有很多因素都影响房价,也就是说权重系数的维度会很大,以单层神经网络为例,如下图:
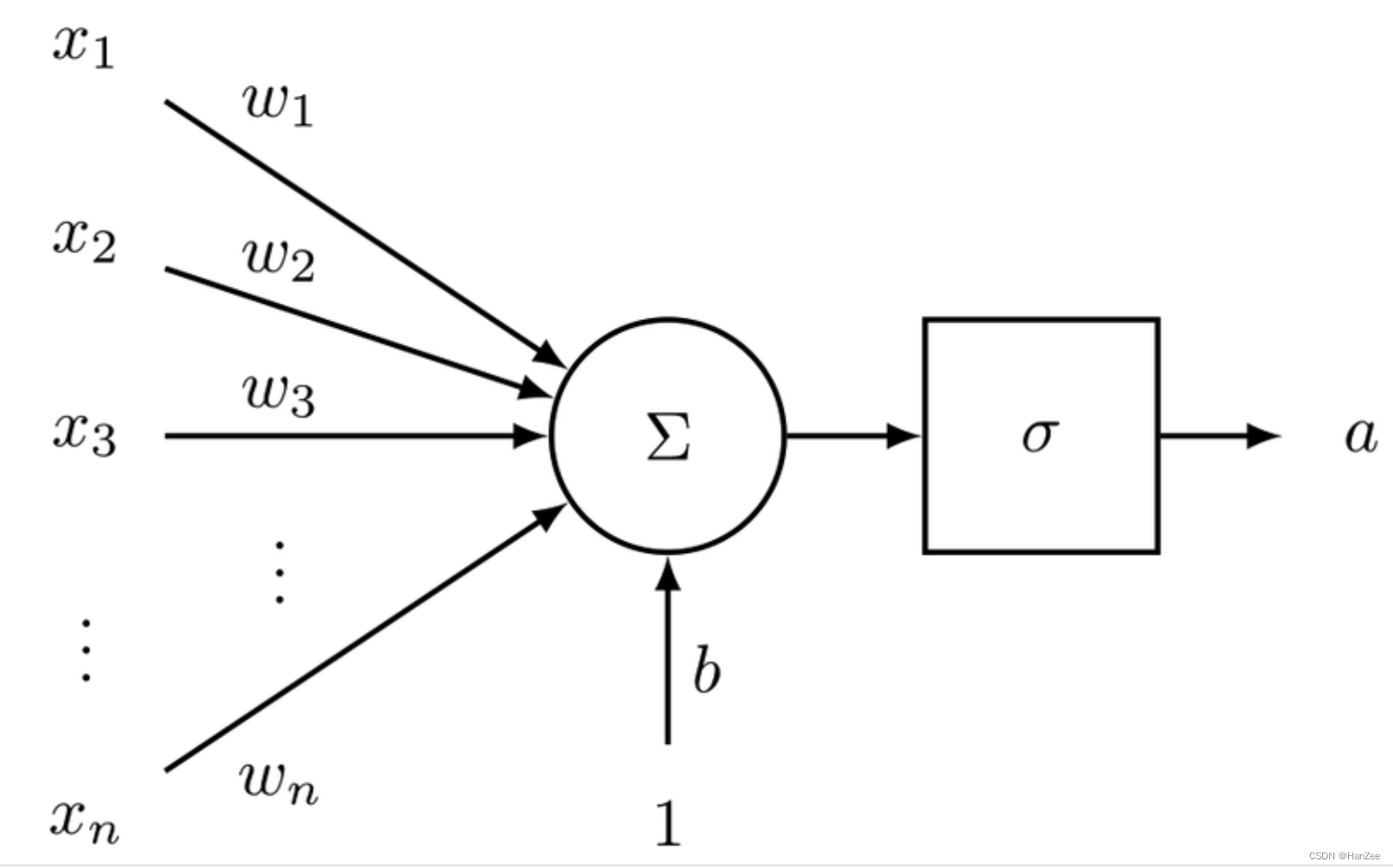
观测值的每一个维度xi都对应了一个权重系数wi,权重大小就代表了这个维度的xi对最后结果的贡献程度。
全连接网络处理图像的弊端
现在,我们的数据从结构化的表格数据转换成了图片,我们把数据换成图像,我们的想法是能不能跟上面的情况一样,找到一些特征,配备一些权重,就可以预测或者分类了。
首先我们想到的是给图像的像素点做flatten,当图片很小的时候,全连接神经网络还依旧能work,假设图片的尺寸是224*224的黑白图像,那么需要的参数数量就是50176,这样来看,训练的代价会非常大,如果类别也不多,很大可能会出现过拟合的情况,我们还不如直接One-hot。
卷积神经网络
卷积的奥义
直接对像素点flatten的方式走不通,我们就想换一种方式来提取特征,于是,就有了卷积这种提取图像特征的方式,卷积运算的公式在信号处理中被定义为: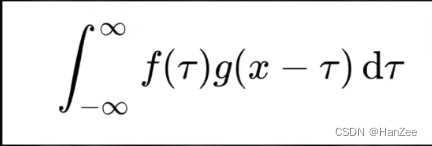
fx就是我们的输入,gx就表示卷积核,它有多种含义,在深度学习中理解为在特定卷积核的作用下提取某一个局部特征,如下图:

这两个卷积核分别提取了竖直方向的局部特征与水平方向局部特征。
下面我们介绍它是如何在图片上提取特征的,为了方便计算,我们以channel =1 的黑白图像举,下面是一张9*9的字母x图像:

卷积核选用3*3的卷积核: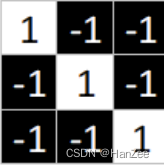
这个卷积核与图像中x的斜边很像,为了显示明显效果,我们先来用这个卷积核与图中这蓝色框内的区域做卷积运算。(*表示卷积运算)
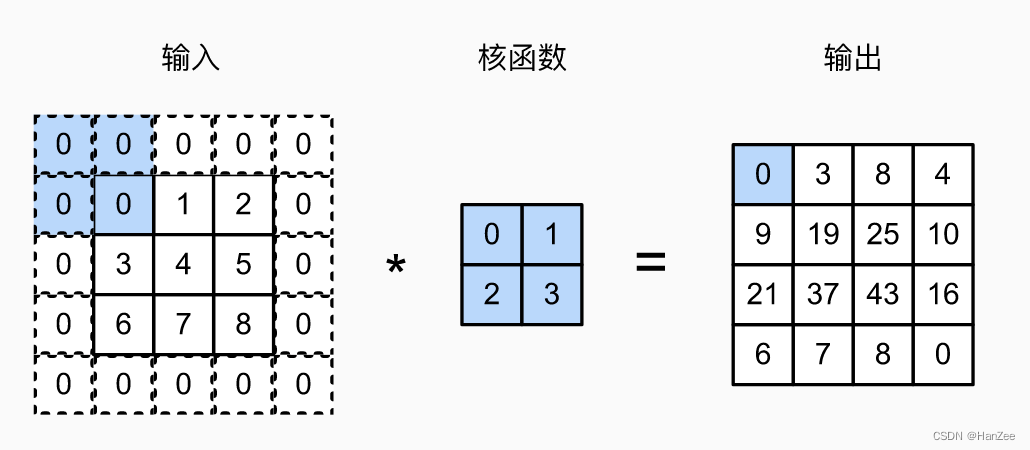
我们让对应的元素相乘在相加,运算过程如下:
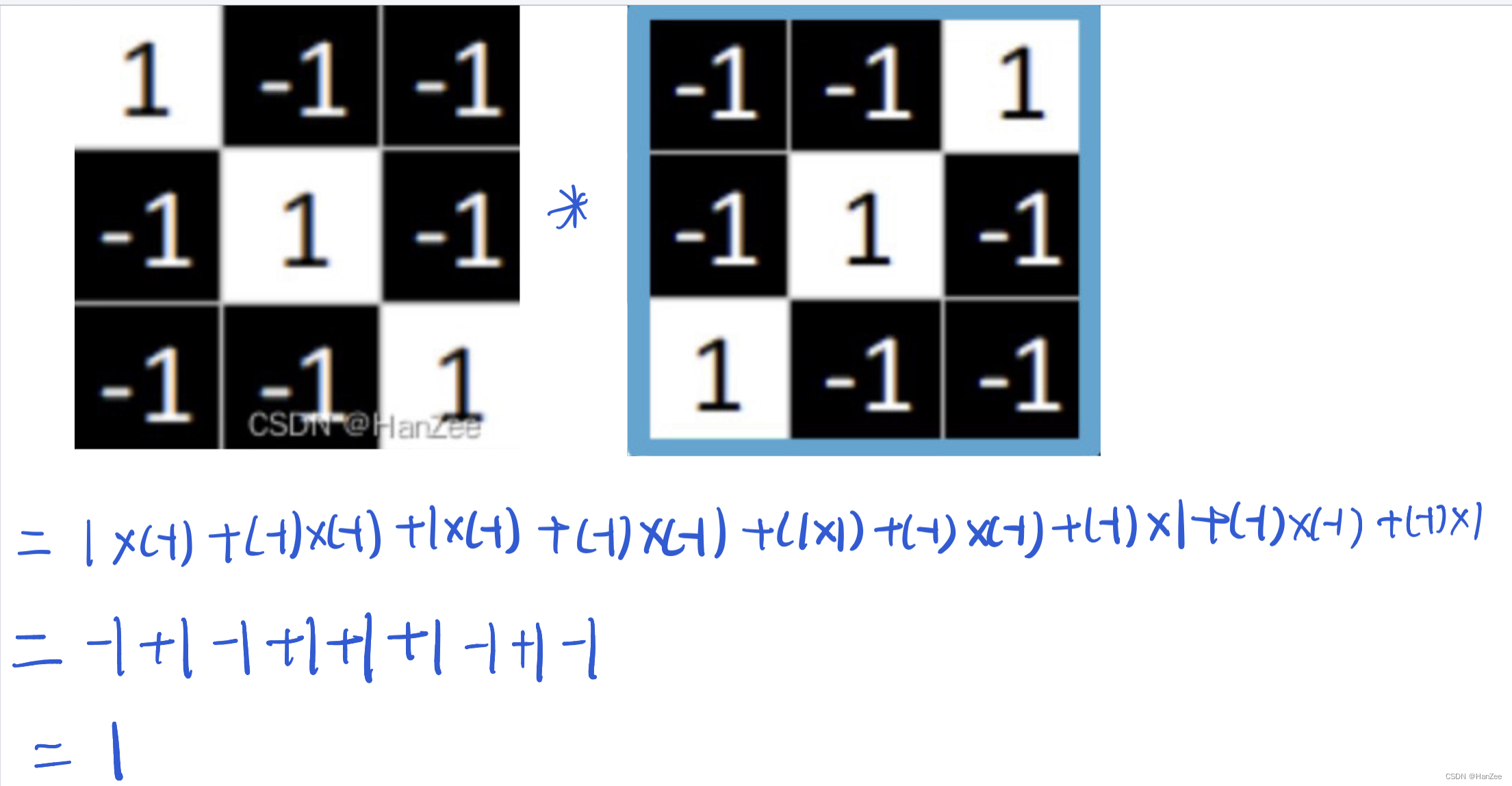
我们在来计算卷积核与黄框进行卷积运算:

我们发现,黄色框的结果要比蓝色框的结果大10倍,这个值越大,卷积核在这个框内提取到的某个特定的特征就越“多”。
而蓝色框里面的特征就不是卷积核所要提取的特征,所以他的值相对较小。
卷积核对图像提取特征后,图像的尺寸会缩小,计算公式图下:
上图图像为9*9,他的输出尺寸就是:
下图还做了均值处理:

单层卷积神经网络
卷积核的参数就是之前介绍的全连接网络的权重系数w,但是连接于计算的方式略有不同,可以看做卷积神经网络是特殊的全连接网络,如下图: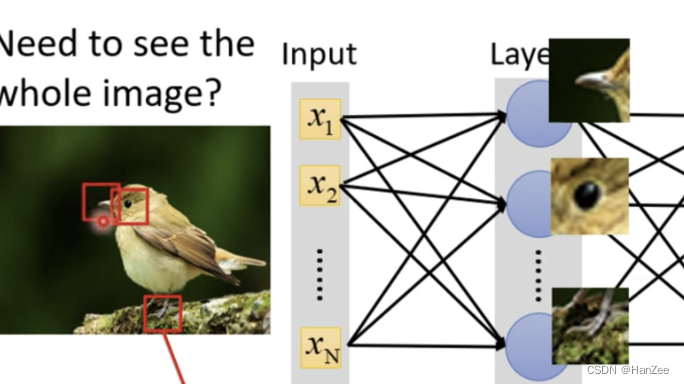
这是一张识别是否为鸟的神经网络,我们直接了解到卷积核可以提取某个局部特征,因为他在网络中是w权重系数,我们通过训练找到最优化的权重系数,我们就可以相对的得到提取鸟类特征的卷积核(如上图鸟嘴、眼睛、爪子)。
我们刚才了解到卷积核可以提取某个局部区域的特征,他的好处在于可以获得空间上的信息,而对全部像素点做flatten就会缺少空间信息。
权重共享
改为卷积核提取特征的的第二个好处就是权重系数要比之前的少很多,比如说鸟嘴这个特征他可以出现在图像的任何位置,所以我用提取鸟嘴特征的卷积从图像的左上角从左到右,从上到下,扫过整张图像,就可以知道是否存在这个特征(这也就是所谓的权重共享,用同一个卷积核在整个图像区域都走一遍)。这样看来,提取黑白图片的某一个特征就只需要一个特定的33卷积核(也就是权重系数w)和一个偏置系数b,总共10个参数,假设3232的图像总共有5个特征,我们用卷积就只需要50个参数,而全连接层就需要1024个参数。如果是彩色图像,卷积核的channel数就要*3。
Padding(填充法)
上面我们讲述,图像在卷积核的作用下会让图像的尺寸缩小,如果我们想训练特别深的网络,比如网络100层,采用3* 3的卷积核,图像尺寸32*32,那么在16层后,图像的尺寸就没了。
图像在被卷积核作用时,还有可能会丢失边缘像素。
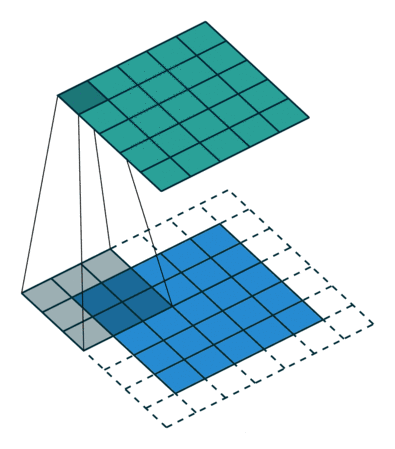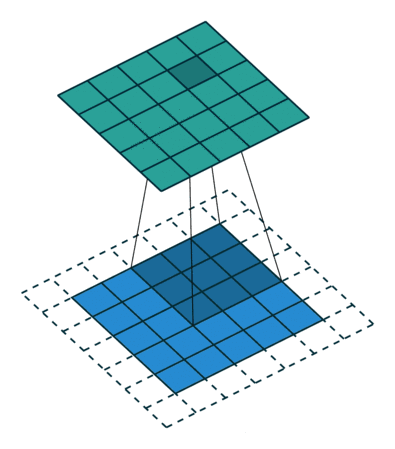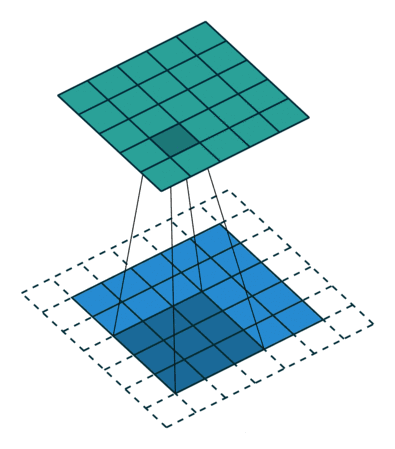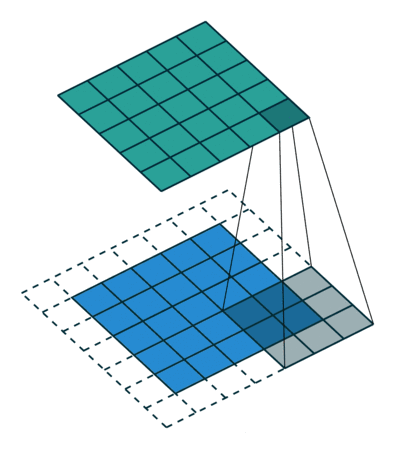
于是我们引入了padding操作,他的作用就是在卷积运算前在图像外围补上一圈数值,一般数值为0。
于是我们的输出尺寸计算公式就发生了变化:
图像为99,卷积核为33,padding补了一圈0,他的输出尺寸就是:
Sride(步长)
假设我们的网络层数为100层,而图像为10241024,那么即使不做padding,在33卷积核的作用下,经过100层网络后,图像还是824*824之大,如果网络层数太大,可能会造成梯度消失,梯度爆炸、过拟合等一系列问题。
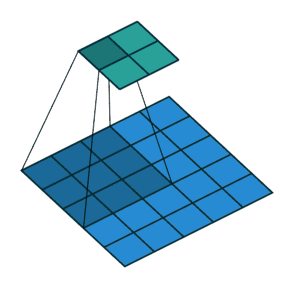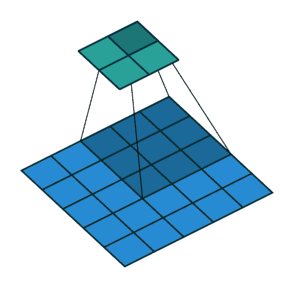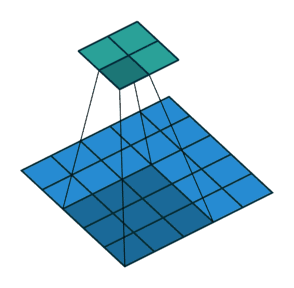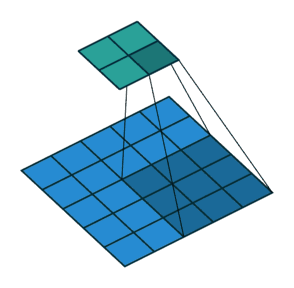
于是,就有了步长这一概念:卷积核的步长度代表提取的精度,步长越大,精度越小。默认每次步长为1,步长增大,可以减少计算量,减少时间。
上图的步长为默认的1,下图步长为2:
Pooling(池化)
卷积操作后,我们得到了一张张有着不同值的feature map,尽管数据量比原图少了很多,但还是过于庞大,因此接下来的池化操作就可以发挥作用了,它最大的目标就是减少数据量,但是过度池化也会损失掉一些特征从而减少精度,他也有抑制过拟合的作用。
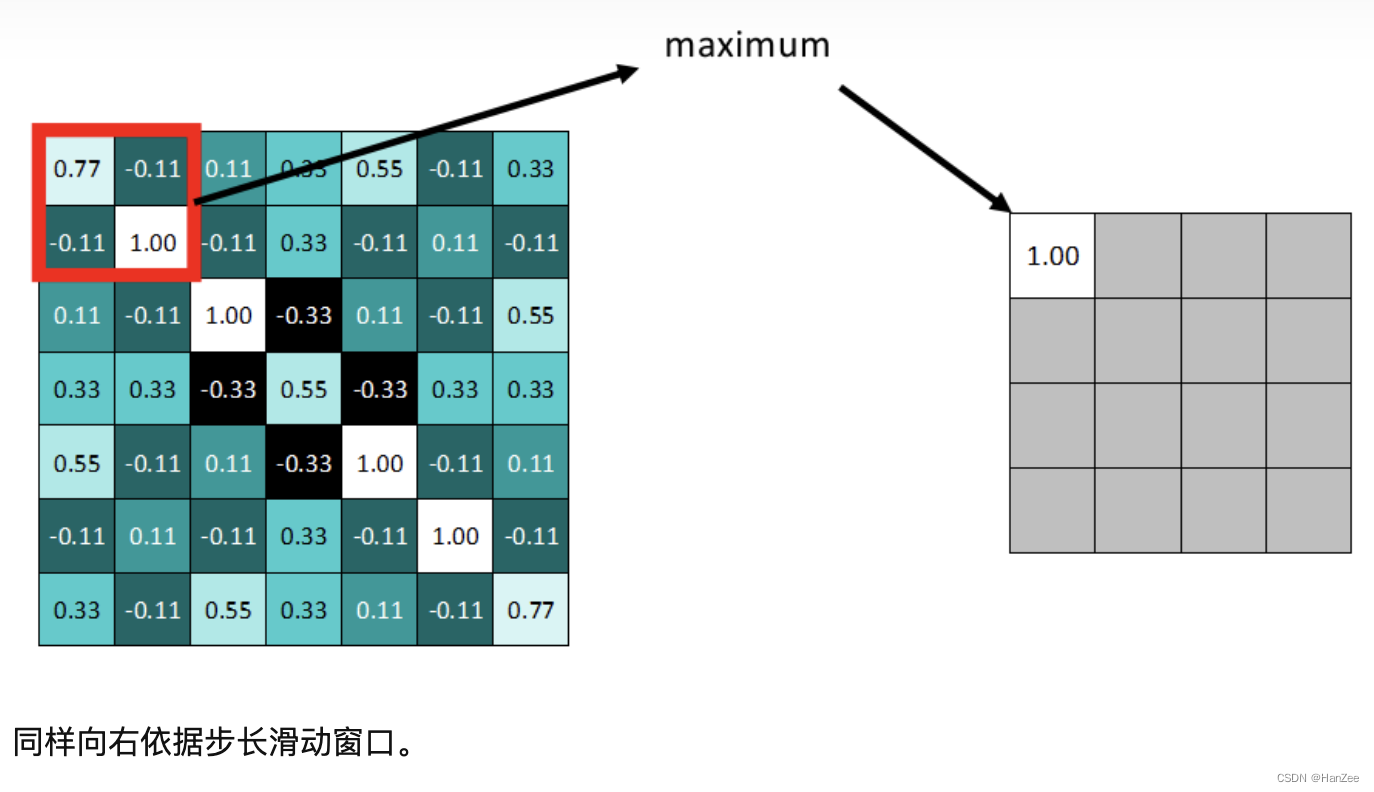
池化分为两种,Max Pooling 最大池化、Average Pooling平均池化。顾名思义,最大池化就是取最大值,平均池化就是取平均值。
拿最大池化举例:选择池化尺寸为2x2,因为选定一个2x2的窗口,在其内选出最大值更新进新的feature map。
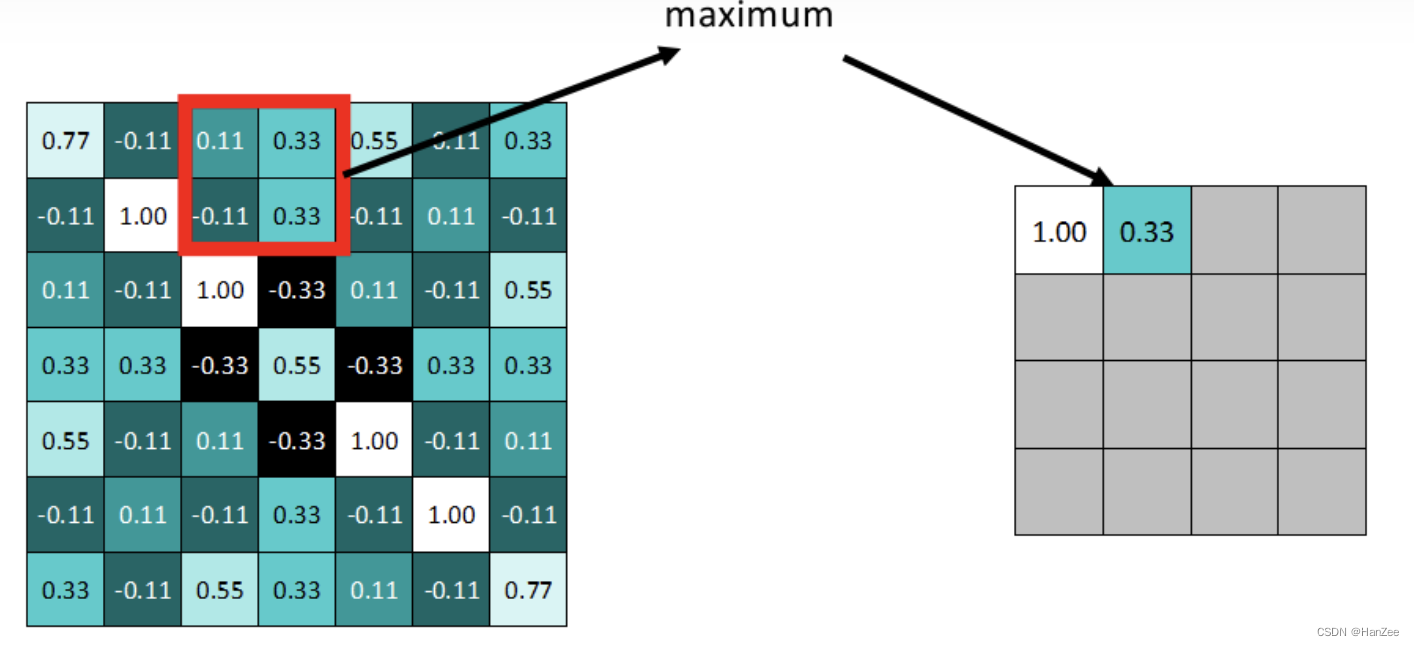
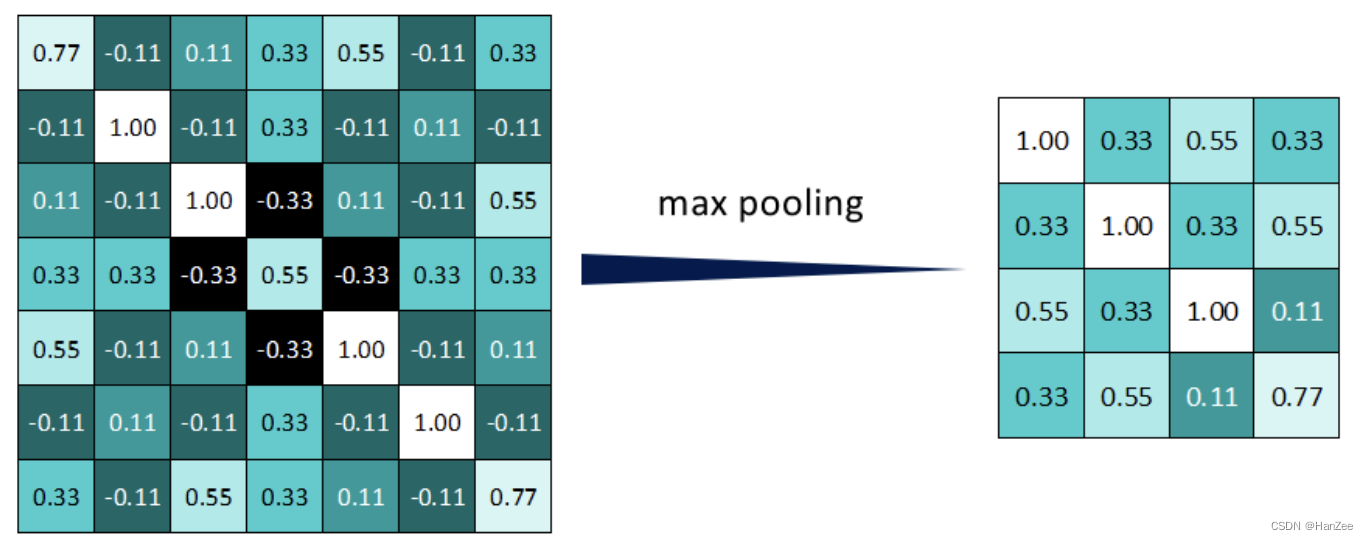
最终得到池化后的feature map。可明显发现数据量减少了很多。
因为最大池化保留了每一个小块内的最大值,所以它相当于保留了这一块最佳匹配结果(因为值越接近1表示匹配越好)。这也就意味着它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。这也就能够看出,CNN能够发现图像中是否具有某种特征,而不用在意到底在哪里具有这种特征。这也就能够帮助解决之前提到的计算机逐一像素匹配的死板做法。

- 点赞
- 收藏
- 关注作者
评论(0)