Python3爬虫小试牛刀

一、前言
这篇文章主要介绍了如何使用Python3爬取csdn博客访问量的相关资料,在Python2已实现的基础上实现Python3爬虫,对比版本之间的差异所在,需要的朋友可以参考下。
使用python来获取自己博客的访问量,也是后面将要开发项目的一部分,后边会对博客的访问量进行分析,以折线图和饼图等可视化的方式展示自己博客被访问的情况,使自己能更加清楚自己的哪些博客更受关注。其实,在较早之前博客专家本身就有这个功能,不知什么原因此功能被取消了。
二、网址分析
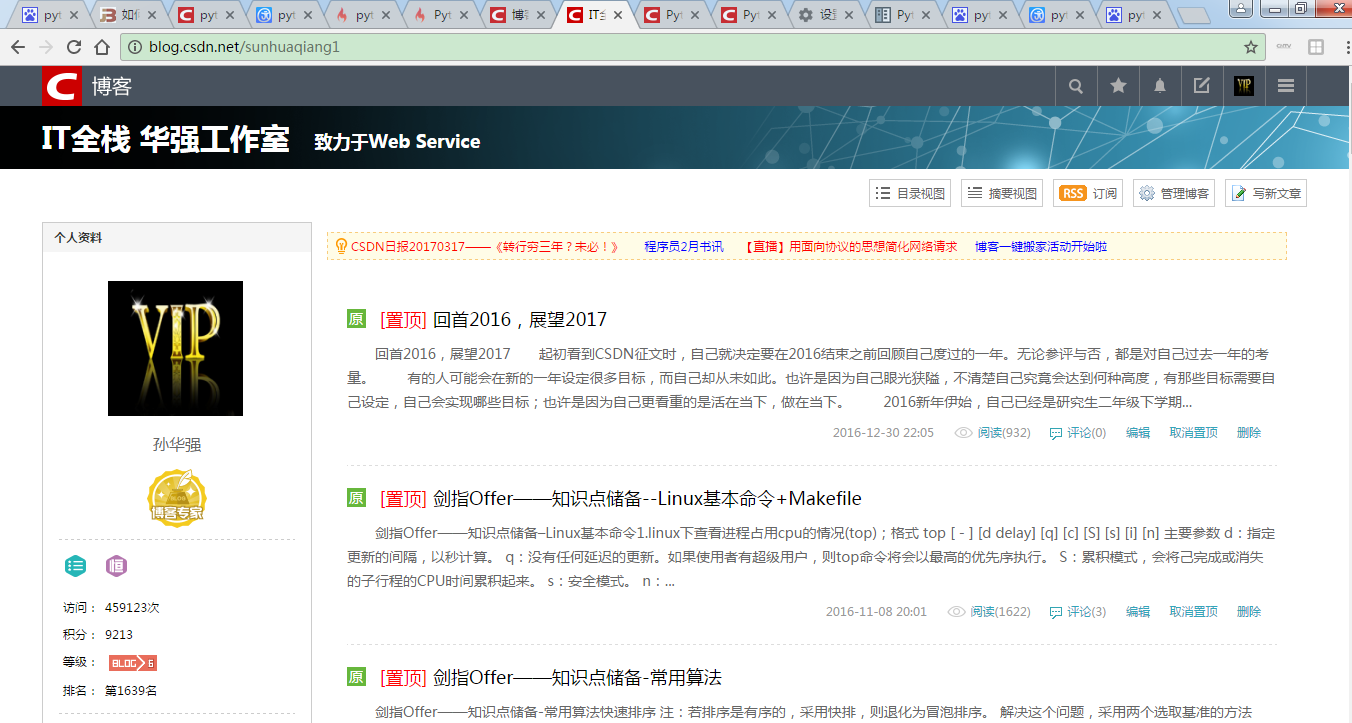
进入自己的博客页面,网址为:http://blog.csdn.net/sunhuaqiang1。 网址还是比较好分析的:就是csdn的网址+个人csdn登录账号,我们来看下一页的网址。
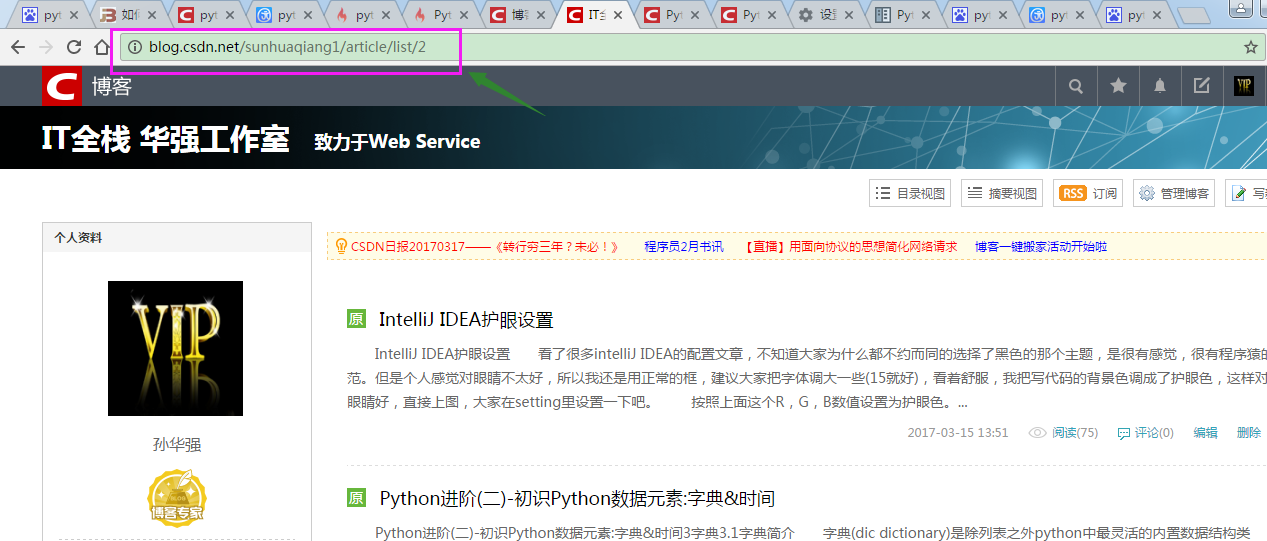
看到第二页的地址为:http://blog.csdn.net/sunhuaqiang1/article/list/2后边的数字表示现在正处于第几页,再用其他的页面验证一下,确实是这样的,那么第一页为什么不是http://blog.csdn.net/sunhuaqiang1/article/list/1呢,那么我们在浏览器中输http://blog.csdn.net/sunhuaqiang1/article/list/1试试,哎,果然是第一页啊,第一页原来是被重定向了,http://blog.csdn.net/sunhuaqiang1被重定向到http://blog.csdn.net/sunhuaqiang1/article/list/1,所以两个网址都能访问第一页,那么现在规律就非常明显了: http://blog.csdn.net/sunhuaqiang1/article/list/ + 页号
三、获取标题
右键查看网页的源代码,我们看到可以找到这样一段代码:


我们可以看到标题都是在标签
<span class="link_title">
<a href="/sunhuaqiang1/article/details/50651235">
...
</a>
</span>
所以我们可以使用下面的正则表达式来匹配标题:
<span class="link_title"><a href=".*?">(.*?)</a></span>
四、获取访问量
拿到了标题之后,就要获得对应的访问量了,经过对源码的分析,我看到访问量的结构都是这样的:
<span class="link_view" title="阅读次数"><a href="/sunhuaqiang1/article/details/51289580" title="阅读次数">阅读</a>(12718)</span>
括号中的数字即为访问量,我们可以用下面的正则表达式来匹配:
<span class="link_view".*?><a href=".*?" title="阅读次数">阅读</a>\((.*?)\)</span>
其中,’.?’的含义是启用正则懒惰模式。必须跟在或者+后边用。
如:“< img src="test.jpg" width="60px" height="80px"/>"
如果用正则匹配src中内容非懒惰模式匹配
src=".*"
匹配结果是:src="test.jpg" width="60px" height="80px"
意思是从="往后匹配,直到最后一个"匹配结束懒惰模式正则:
src=".*?"
结果:src="test.jpg"
因为匹配到第一个"就结束了一次匹配。不会继续向后匹配。因为他懒惰嘛。
.表示除\n之外的任意字符
*表示匹配0-无穷
+表示匹配1-无穷
五、尾页判断
接下来我们要判断当前页是否为最后一页,否则我们就不能判断什么时候结束了,我找到了源码中‘尾页'的标签,发现是下面的结构:
<a href="/sunhuaqiang1/article/list/2">下一页</a> <a href="/sunhuaqiang1/article/list/7">尾页</a>
所以我们可以用下面的正则表达式来匹配,如果匹配成功就说明当前页不是最后一页,否则当前页就是最后一页。
<a href=".*?">尾页</a>
六、编程实现
下面是摘自的Python2版完整的代码实现:
#!usr/bin/python
# -*- coding: utf-8 -*-
'''
Created on 2016年2月13日
@author: ***
使用python爬取csdn个人博客的访问量,主要用来练手
'''
import urllib2
import re
#当前的博客列表页号
page_num = 1
#不是最后列表的一页
notLast = 1
account = str(raw_input('输入csdn的登录账号:'))
while notLast:
#首页地址
baseUrl = 'http://blog.csdn.net/'+account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+'/article/list/'+str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent':user_agent}
#构造请求
req = urllib2.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
#在页面中查找是否存在‘尾页'这一个标签来判断是否为最后一页
notLast = re.findall('<a href=".*?">尾页</a>',myPage,re.S)
print '---------------第%d页-------------' % (page_num,)
#利用正则表达式来获取博客的标题
title = re.findall('<span class="link_title"><a href=".*?">(.*?)</a></span>',myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items).lstrip().rstrip())
#利用正则表达式获取博客的访问量
view = re.findall('<span class="link_view".*?><a href=".*?" title="阅读次数">阅读</a>\((.*?)\)</span>',myPage,re.S)
viewList=[]
for items in view:
viewList.append(str(items).lstrip().rstrip())
#将结果输出
for n in range(len(titleList)):
print '访问量:%s 标题:%s' % (viewList[n].zfill(4),titleList[n])
#页号加1
page_num = page_num + 1
由于自己现在的IDE为Python3,且自己在学习Python3。故在此基础上实现Python2项目的升级改造,并在改造过程中发现版本之间的差异性。以下为Python3版本下的爬虫代码。
#!usr/bin/python
# -*- coding: utf-8 -*-
'''
Created on 2017年3月19日
@author: SUN HuaQiang
目的:使用python爬取csdn个人博客的访问量,主要用来练手Python爬虫
收获:1.了解Python爬虫的基本过程
2.在Python2的基础上实现Python3,通过对比发现版本之间的差异
'''
import urllib.request
import urllib
import re
#当前的博客列表页号
page_num = 1
#初始化最后列表的页码
notLast = 1
account = str(input('请输入csdn的登录账号:'))
while notLast:
#首页地址
baseUrl = 'http://blog.csdn.net/' + account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+'/article/list/' + str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent':user_agent}
#构造请求
req = urllib.request.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib.request.urlopen(req)
#python3中urllib.read返回的是bytes对象,不是string,得把它转换成string对象,用bytes.decode方法
myPage = myResponse.read().decode()
#在页面中查找是否存在‘尾页'这一个标签来判断是否为最后一页
notLast = re.findall('<a href=".*?">尾页</a>', myPage, re.S)
print ('-----------第%d页--------------' % (page_num,))
#利用正则表达式来获取博客的标题
title = re.findall('<span class="link_title"><a href=".*?">(.*?)</a></span>',myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items).lstrip().rstrip())
#利用正则表达式获取博客的访问量
view = re.findall('<span class="link_view".*?><a href=".*?" title="阅读次数">阅读</a>\((.*?)\)</span>',myPage,re.S)
viewList=[]
for items in view:
viewList.append(str(items).lstrip().rstrip())
#将结果输出
for n in range(len(titleList)):
print ('访问量:%s 标题:%s' % (viewList[n].zfill(4),titleList[n]))
#页号加1
page_num = page_num + 1
下面是部分结果:
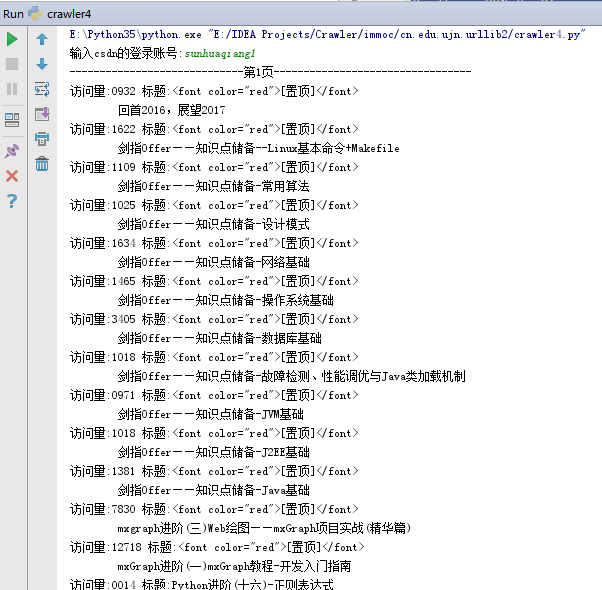
瑕疵:通过爬虫结果可以发现,在CSDN中,对于设置为指定的文章,爬取结果存在一定的问题,还包含部分css代码。
改善:通过更改获取博文标题的正则表达式,即可解决此问题。

想法是好的,但是直接利用正则实现标题获取时遇到了困难,暂时并未实现理想结果。
遂改变思路,将利用正则获取后的字符串再进行二次正则,即替换操作,语句如下:
for items in title:
titleList.append(re.sub('<font color="red">.*?</font>', '', str(items).lstrip().rstrip()))
更改后的结果如下。并同时为每篇博文进行了编号。
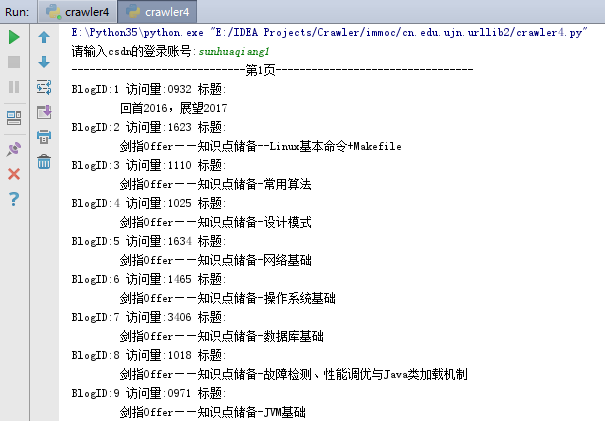
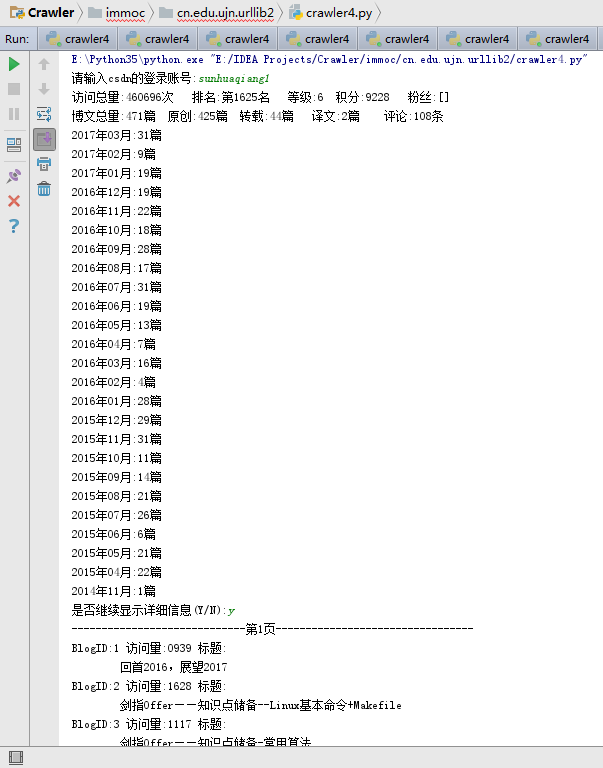
同时,自己还希望获取到的信息包括:访问总量、积分、等级、排名、粉丝、原创、转载、译文、评论等数据信息。
以上信息在网页源码中如下所示。
<ul id="blog_rank">
<li>访问:<span>459285次</span></li>
<li>积分:<span>9214</span> </li>
<li >等级: <span style="position:relative;display:inline-block;z-index:1" >
<img src="http://c.csdnimg.cn/jifen/images/xunzhang/jianzhang/blog6.png" alt="" style="vertical-align: middle;" id="leveImg">
<div id="smallTittle" style=" position: absolute; left: -24px; top: 25px; text-align: center; width: 101px; height: 32px; background-color: #fff; line-height: 32px; border: 2px #DDDDDD solid; box-shadow: 0px 2px 2px rgba (0,0,0,0.1); display: none; z-index: 999;">
<div style="left: 42%; top: -8px; position: absolute; width: 0; height: 0; border-left: 10px solid transparent; border-right: 10px solid transparent; border-bottom: 8px solid #EAEAEA;"></div>
积分:9214 </div>
</span> </li>
<li>排名:<span>第1639名</span></li>
</ul>
<ul id="blog_statistics">
<li>原创:<span>425篇</span></li>
<li>转载:<span>44篇</span></li>
<li>译文:<span>2篇</span></li>
<li>评论:<span>108条</span></li>
</ul>
则获取访问信息的正则表达式为:
#利用正则表达式获取博客信息
sumVisit = re.findall('<li>访问:<span>(.*?)</span></li>', myPage, re.S)
credit = re.findall('<li>积分:<span>(.*?)</span> </li>', myPage, re.S)
rank = re.findall('<li>排名:<span>(.*?)</span></li>', myPage, re.S)
grade = re.findall('<li >.*?<img src=.*?/blog(.*?).png.*?>.*?</li>', test3, re.S)
original = re.findall('<li>原创:<span>(.*?)</span></li>', myPage, re.S)
reprint = re.findall('<li>转载:<span>(.*?)</span></li>', myPage, re.S)
trans = re.findall('<li>译文:<span>(.*?)</span></li>', myPage, re.S)
comment = re.findall('<li>评论:<span>(.*?)</span></li>', myPage, re.S)

根据网页源码,可得出其正则表达式为
staData = re.findall('<li><a href=.*?>(.*?)</a><span>(.*?)</span></li>', myPage, re.S)
for i in staData:
print(i[0] + ':' + i[1].lstrip('(').rstrip(')')+'篇')
经过以上操作,得到的用户Blog信息如下图所示:
最终遇到的问题是:有关粉丝数的爬取遇到了问题,因为前面数据信息的获取不需要用户登录,而用户粉丝数是在用户已登录情景下获取的,故需要将用户登录信息添加进去。犯愁~
PS:论文盲审送回来了,自己这段时间要用来修改论文了,后面的博客后面再说吧~
七、注意事项
-
urllib2在3.5中为urllib.request; -
raw_input()在3.5中为input(); -
python3中
urllib.read()返回的是bytes对象,不是string,得把它转换成string对象,用bytes.decode()方法; -
re.S意在使.匹配包括换行在内的所有字符;
-
python3对
urllib和urllib2进行了重构,拆分成了urllib.request,urllib.response,urllib.parse,urllib.error等几个子模块,这样的架构从逻辑和结构上说更加合理。urljoin现在对应的函数是urllib.parse.urljoin。
注:Python2部分的爬虫代码为网络获取,在此向匿名人士表示感谢。

- 点赞
- 收藏
- 关注作者
评论(0)