Linux进程管理(父子进程)

@[toc]
1.fork函数概念
fork函数在代码中创建进程的一个系统调用接口,它可以为进程创建子进程。
我们可以使用man手册来查询一下fork函数的相关内容:
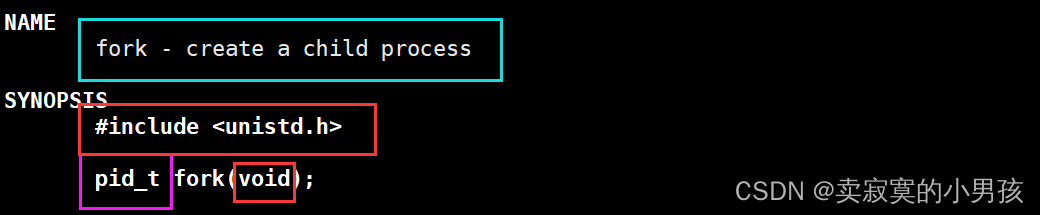
我们发现使用fork函数的意义在于创建一个子进程,并且需要包含系统的头文件,返回值是pid_t类型(可以暂时先理解成int),不需要传参数。
2.fork的举例
#include<stdio.h>
#include<unistd.h>
int main()
{
fork();
printf("I am a process,pid:%d,ppid:%d\n",getpid(),getppid());
sleep(1);
return 0;
}
我们发现代码被执行了两次,其中这两次是父进程和子进程分别执行的。
我们可以来查看一下两个进程的pid和ppid

通过观察进程编码,我们可以知道下面一个是子进程,上面的是父进程,因为子进程的ppid就是父进程的pid。这段代码父进程运行了一次,子进程也运行了一次。即有两个执行流在执行。而父进程的父进程其实就是bash,我们可以验证一下:
ps axj | head -1&&ps ajx|grep 4821

那么父子两个进程谁先会执行呢?这个由CPU自己来决定。
3.对进程创建的理解
(1)创建进程的两种方法
./或者直接运行指令
在代码中创建:fork()
站在操作系统的角度来说,这两种创建的方式是一样的。
(2)对创建进程的理解
在这一篇文章中Linux进程管理–进程概念,我们已经知道了进程=程序中代码和数据+进程的PCB。显然创建进程的过程就是重新创建代码和数据,并且生成PCB的过程。
PCB和代码
PCB在创建完代码和数据就可以直接生成了,那么代码和数据怎么创建呢?
通过上面的例子我们知道:fork之后子进程和父进程的代码是共享的。
数据
那么数据呢?在默认情况下,数据也是共享的。
既然有默认情况,就会有别的情况,当我们没有对数据进行修改的时候,数据仅仅只有一份。
但是当数据被修改了的话就会通过写时拷贝来维护数据的独立性。
画一张图来帮助大家理解:
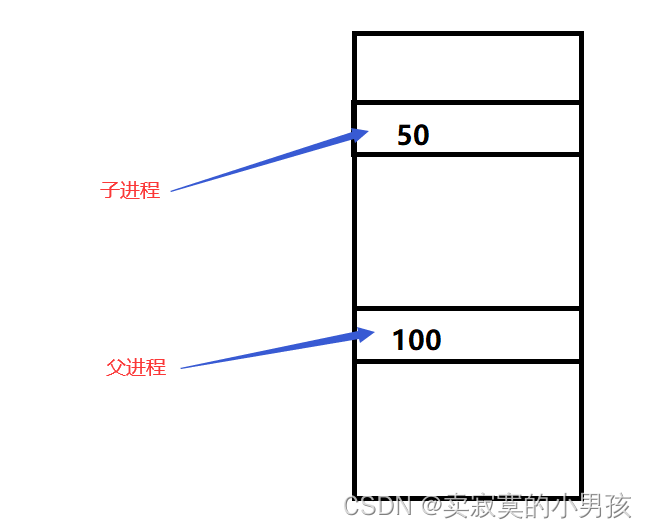
当父进程有一个数据是100的时候,子进程希望重写这个数据为50,此时操作系统会为其重新开辟一段空间使父进程使用原空间100,子进程使用新空间50,注意,子进程的其他数据内容使用的还是和父进程一样的空间。这就称为写时拷贝。
那么为什么不直接为子进程开辟一个和父进程存放数据的一样大小的空间呢?
这是因为不是所有的数据都需要进行写时拷贝,这样会使效率低下。
4.fork的返回值
通过刚才的man手册,我们知道了fork创建进程的返回值是pid_t类型,我们可以暂时理解成int,那么它的值有什么意义呢?
显然我们创建子进程并不是为了让它去和父进程做一样的事情。下面来介绍返回值的含义:
创建成功时:给父进程返回子进程的id,给子进程返回0
创建失败时:返回值<0
这样我们就可以通过if/else语句来让父子进程做不同的事情:
#include<stdio.h>
#include<unistd.h>
int main()
{
pid_t id=fork();
if(id==0)
{
printf("I am a child,pid:%d,ppid:%d\n",getpid(),getppid());
sleep(1);
}
else if(id>0)
{
printf("I am father,pid:%d,ppid:%d\n",getpid(),getppid());
sleep(1);
}
else
{
printf("fail to makeup");
}
return 0;
}
当id为0时表示为子进程,当id>0时,表示父进程,并执行相应的条件语句。

我们也可以把循环写死,然后观察一下正在运行的进程。

- 点赞
- 收藏
- 关注作者
评论(0)