大数据CDM服务迁移实践【玩转华为云】

本文主要内容有
- 一 购买并配置相关云服务
- 二 旧集群Hive建库建表
- 三 新集群Hive建库建表
- 四 CDM迁移Hive数据表
- 五 CDM迁移HBase数据表
一 购买并配置相关云服务
1.1 配置云服务
点右上角的预置实验环境,等待系统预置,直到显示“预置成功”,即可进行下一步。若系统提示资源排队,则关闭页面重新进入就好

1.2 购买MRS集群
那首先什么是MRS?
是一个在华为云上部署与管理Hadoop系统的服务,可以一键即可部署Hadoop集群。就是MRS提供的完全可控一站式企业级大数据集群云服务,完全兼容开源接口,结合华为云计算、存储优势及大数据行业经验,为客户提供高性能、低成本、灵活易用的全栈大数据平台;
能轻松运行Hadoop、Spark、Hbase、Kafka、Storm等大数据组件,并具备在后续根据业务需要进行定制开发能力,帮助企业快速构建海量数据信息处理系统,通过对海量信息数据实时与非实时的分析挖掘,发现全新价值点和企业商机;
这个实验里我们需要购买两台MRS集群,其中一台mrs_old中有Hive和HBase历史数据,另一台mrs_new没有数据的。实验过程模拟从mrs_old搬迁Hive和HBase数据到mrs_new中
然后进入【控制台】,点击“服务列表”->“大数据”->“MapReduce服务”进入MRS服务控制台,如下
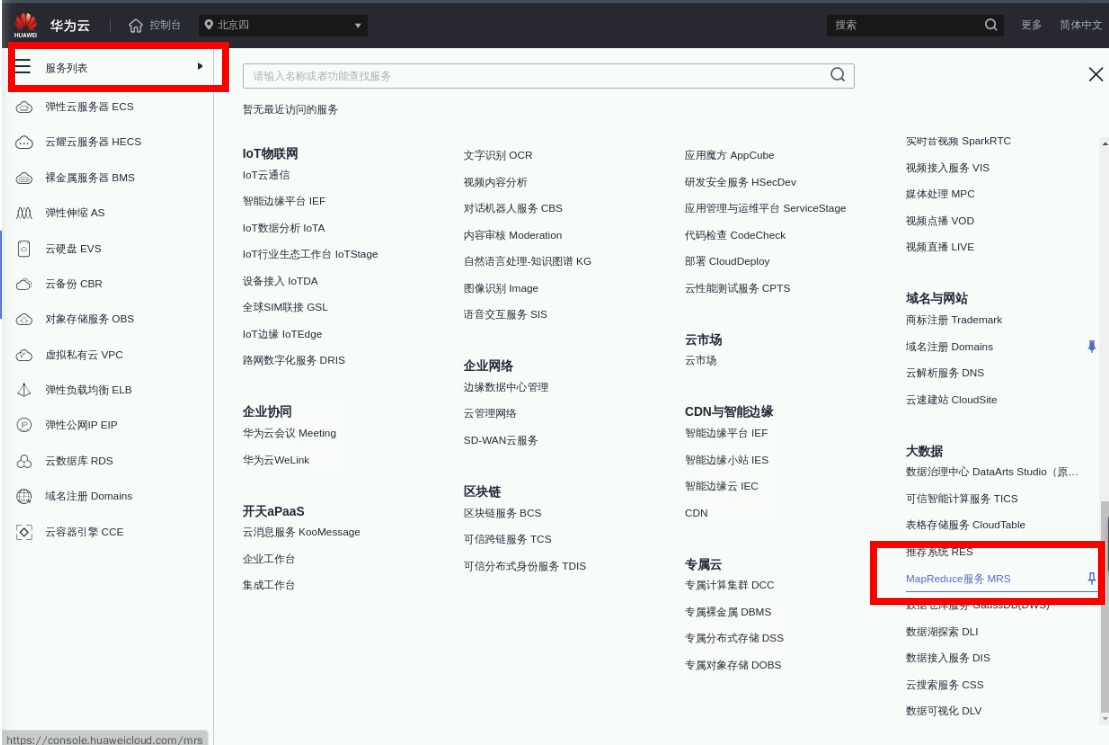
点击进入MRS页面,点击“购买集群”
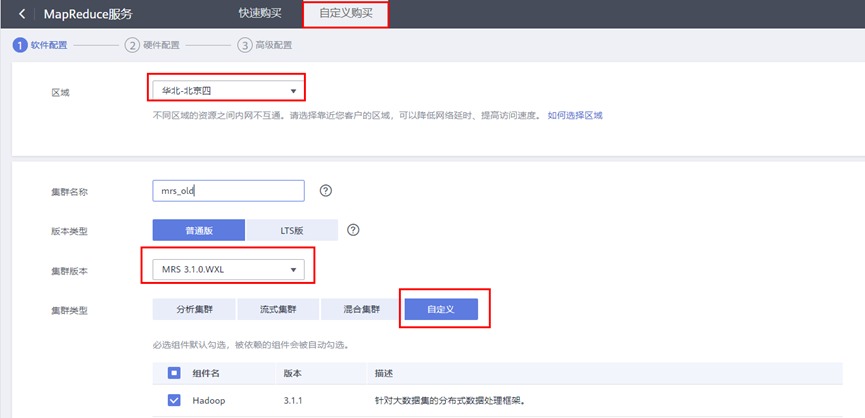
选择“自定义购买”
区域:北京四
集群名称:mrs-old
版本类型:普通版
集群版本:MRS 3.1.0 WXL
集群类型:自定义
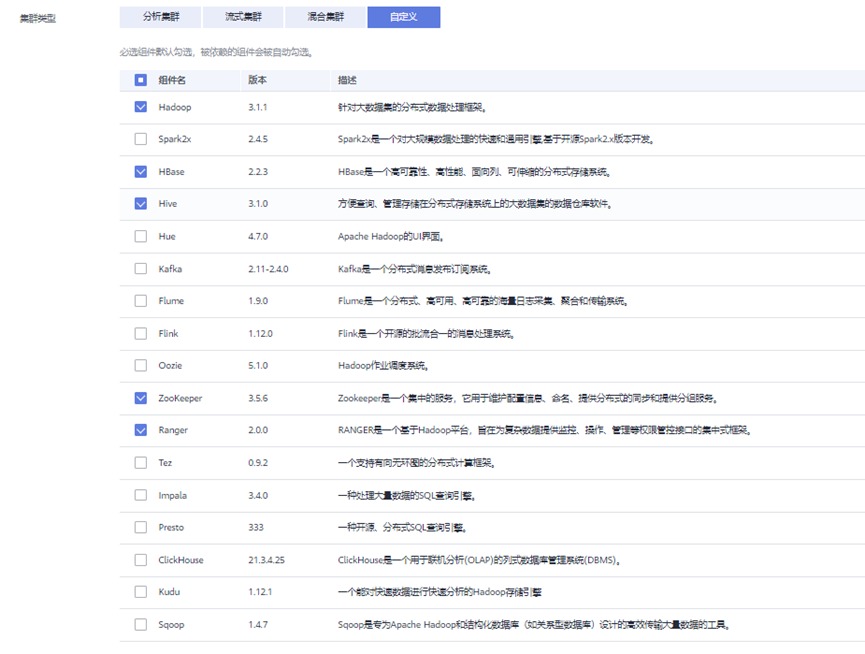
勾选组件:Hadoop/HBase/Hive/Zookeeper/Ranger
元数据:本地元数据

如果希望把Hive元数据存放在MySQL中,可以选择配置数据连接
确认无误后点击“下一步”
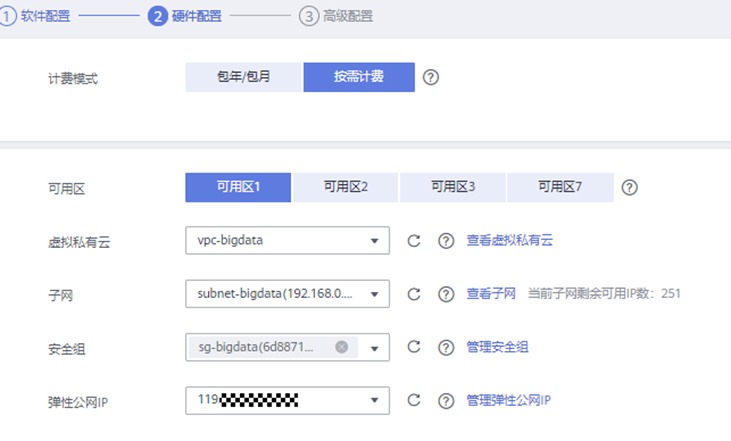
接下来配置硬件
计费模式:按需计费
可用区:可用区1
虚拟私有云:vpc-bigdata
子网:subnet-bigdata
安全组:sg-bigdata
弹性公网IP:下拉选择IP地址
集群节点
实例规格:全部选择通用计算增强型
8 vCPUs |32 GB | c6.2xlarge.4
系统盘:高IO 480 GB x 1
数据盘:高IO 600 GB x 1
实例数量:Master节点 3台
分析Core节点:2台
无需添加分析Task节点
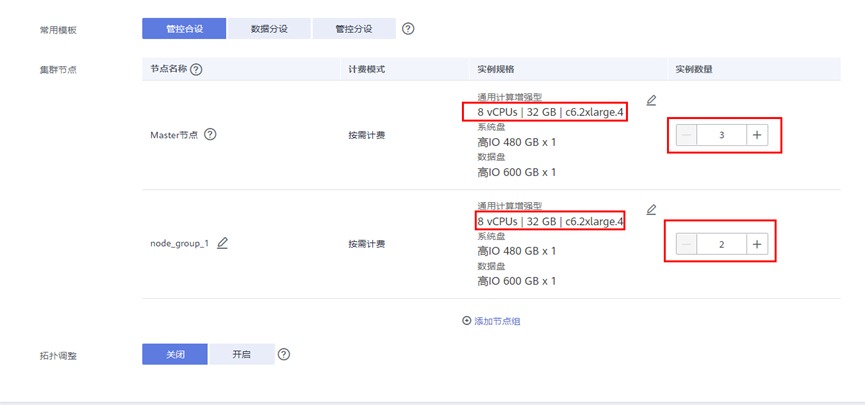
注意1:当实例规格选为“8 vCPUs |32 GB | c6.2xlarge.4”时,可能会出现如下警告。由于本次实验仅用于学习测试,不受影响,点击确认即可
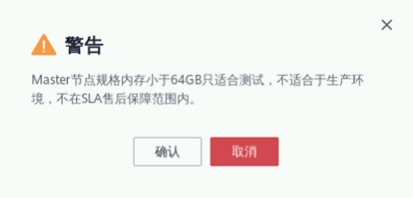
注意2:当node_group_1节点实例数量改为2后,可能会出现如下警告。暂时无需理会,后续步骤会解决

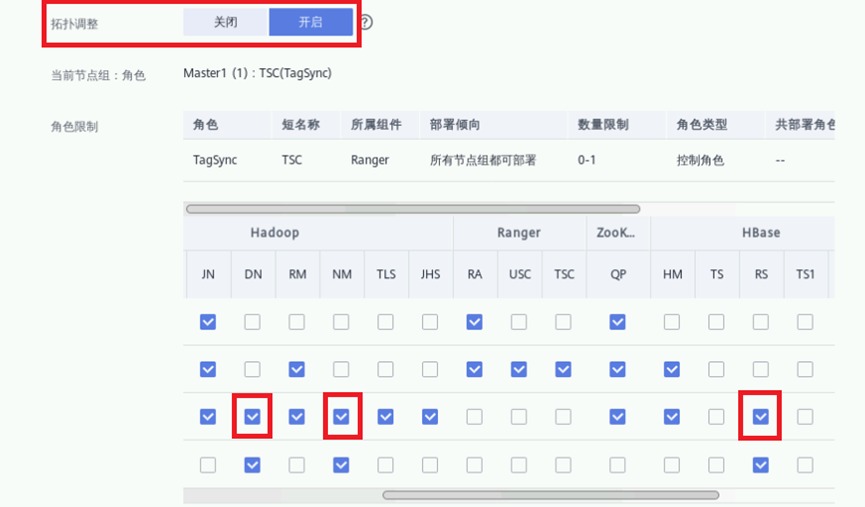
开启“拓扑调整”,勾选如下图位置所示的“DN, NM, RS”。此操作表示在Master3节点分别部署DataNode, NodeManager, RegionServer以解决如上警告
确认无误后点击“下一步”
接下来进行高级配置
标签,主机名前缀,弹性伸缩,引导操作均无需配置
委托:暂不绑定
告警:关闭
日志记录:关闭

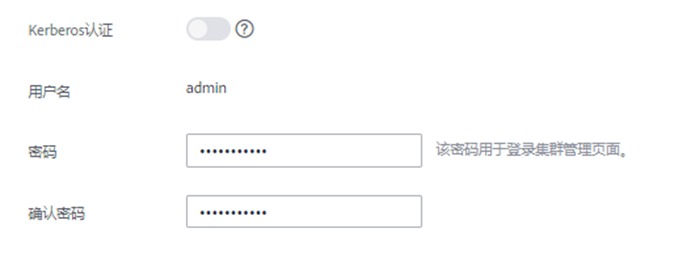
Kerberos认证:保持关闭状态
用户名:admin
密码:自定义密码,例如h#w@2ser
确认密码:再次输入
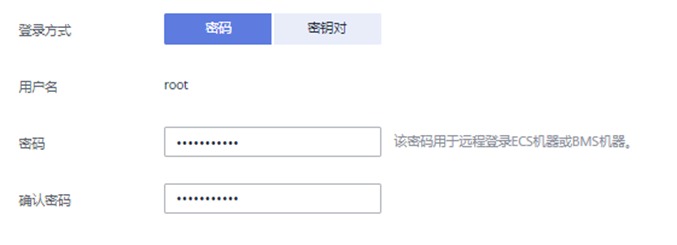
登录方式:密码
用户名:root
密码:自定义密码,例如h#w@2ser
确认密码:再次输入
通信安全授权:勾选“确认授权”

确认无误后点击“立即购买”->“返回集群列表”
此时可以购买另一台MRS,除了【集群名称】需修改为mrs_new外,其余配置均与之前保持一致
两台MRS集群可同时处于部署状态,共计约等待【35分钟】(等待)。可在集群列表中查看到两台MRS集群的购买“状态”由“启动中”更新为“运行中”即可正常使用
1.3 购买CDM集群
点击控制台左侧 “服务列表”->“迁移”->“云数据迁移 CDM”如下
进入CDM界面,点击“购买云数据迁移服务”
当前区域:华北-北京四
可用区:任意区即可
集群名称:cdm-bigdata
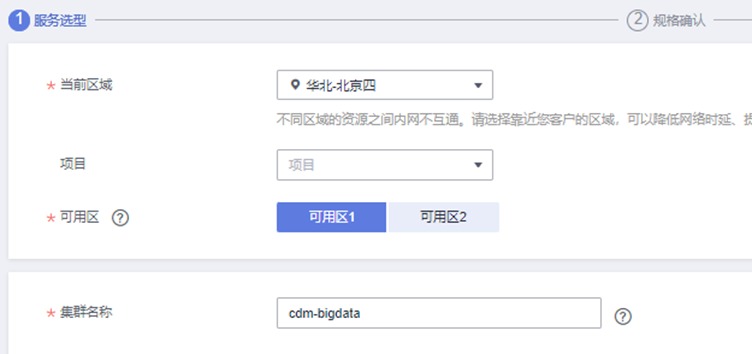
实例类型:cdm.large 8核16GB
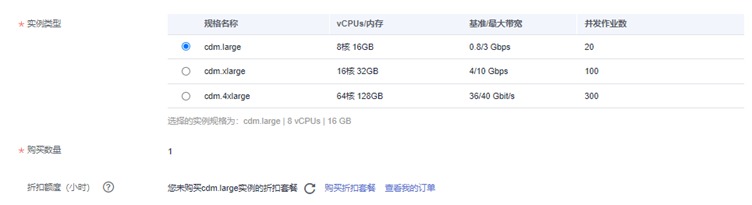
虚拟私有云:vpc-bigdata
子网:subnet-bigdata
安全组:sg-bigdata
消息通知:保持关闭状态
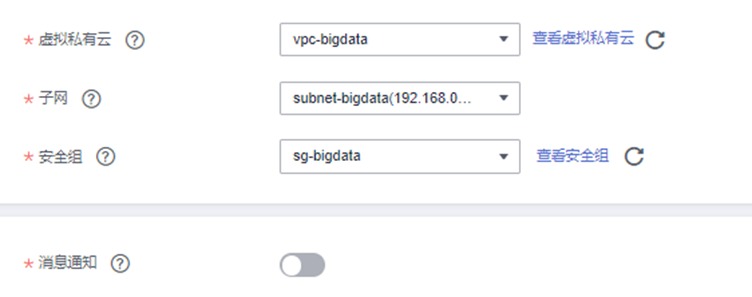
确认无误后点击“立即购买”
再次确认配置,确认无误后点击“提交”。等【8分钟】创建成功
二 🎯 旧集群Hive建库建表
业务数据通常存放在多个不同系统的不同业务表中,在需要进行统计分析和进一步的数据挖掘时合成宽表,汇总更多的特征
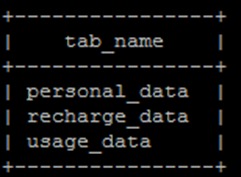
本实验中用户信息表(personal_data)来自客户办理业务时生成的表格,用户充值信息表(recharge_data)为用户平时的充值情况,用户业务使用表(usage_data)为用户平时通话、上网等数据,最终形成的业务宽表具有更多字段或者特征,为下一步分析和数据挖掘做好准备
备注:因为真实数据比较敏感,我们实验模拟数据都做了简化处理
2.1 下载数据至实验沙箱
重新启动一个Xfce终端连接,使用wget命令在Xfce终端下载personal_data.csv、recharge_data.csv、usage_data.csv三个文件
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com:443/20220726/usage_data.csv
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com:443/20220726/recharge_data.csv
wget https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com:443/20220726/personal_data.csv使用ls命令确认文件已下载
ls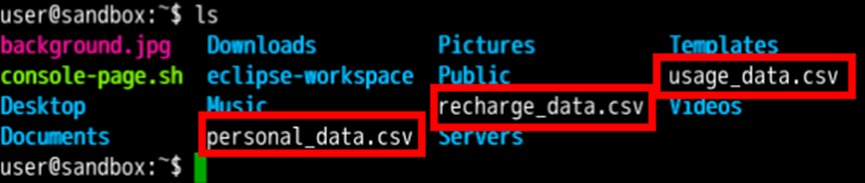
2.2 上传数据至集群服务器
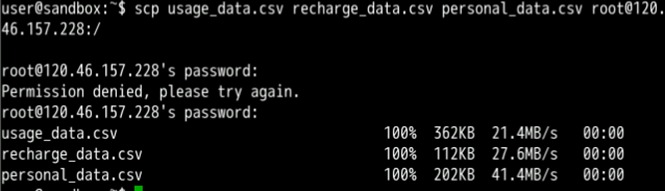
scp usage_data.csv recharge_data.csv personal_data.csv root@xxx.xxx.xxx.xxx:/注意:弹性公网IP见mrs_old集群详情页
登录集群主节点服务器(需要输入集群密码,例如HWcloud@user0)
ssh root@xxx.xxx.xxx.xxx查看根目录下是否存在以上三个文件
ls /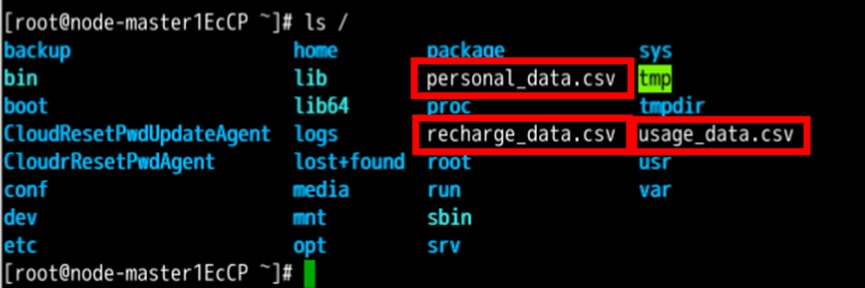
2.3 将数据上传至HDFS
在Xfce窗口输入以下命令,同时创建三个路径
hdfs dfs -mkdir -p /user/personal_dir_data /user/recharge_dir_data /user/usage_dir_data上传本地目录下的数据到HDFS目录
hdfs dfs -put /personal_data.csv /user/personal_dir_data
hdfs dfs -put /recharge_data.csv /user/recharge_dir_data
hdfs dfs -put /usage_data.csv /user/usage_dir_data查看HDFS上数据。注意命令后跟三个路径
hdfs dfs -ls /user/personal_dir_data /user/recharge_dir_data /user/usage_dir_data看到结果如下,说明已正确执行
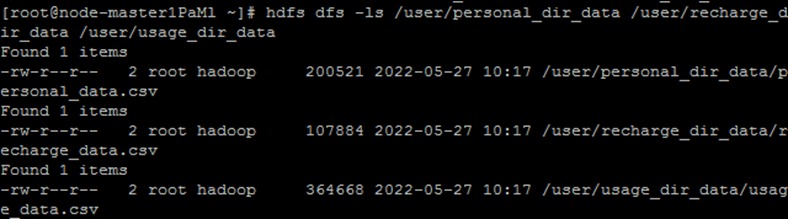
2.4 Hive中建库、建表并加载数据
进入Hive命令窗口
beeline显示现有的数据库
show databases;显示结果如下
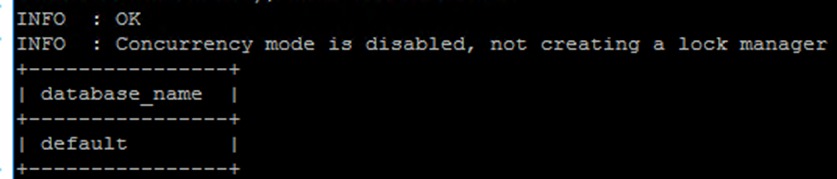
创建hive_batch数据库,并切换至hive_batch
create database hive_batch;
use hive_batch;显示当前数据库下所有表格
show tables;当前应该没有任何数据
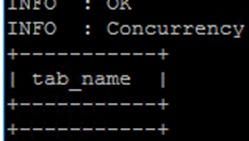
创建personal_data表
create table hive_batch.personal_data
(USER_ID int,SERVICE string, AGE int,LOCATION string, CAREER string,CREATEDATE string)
row format delimited fields terminated by ',' stored as textfile;加载数据到 personal_data
LOAD DATA INPATH '/user/personal_dir_data/personal_data.csv' OVERWRITE INTO TABLE hive_batch.personal_data;显示 personal_data 的前5行
select * from hive_batch.personal_data limit 5;输出结果如下

创建表recharge_data并导入数据
create table hive_batch.recharge_data
(USER_ID int,LAST_RECHARGE_VALUE int,TOTAL_RECHARGE_VALUE int,
TOTAL_RECHARGE_COUNT int,BALANCED int)
row format delimited fields terminated by ',' stored as textfile;
LOAD DATA INPATH '/user/recharge_dir_data/recharge_data.csv' OVERWRITE INTO TABLE hive_batch.recharge_data;显示recharge_data前5行
select * from hive_batch.recharge_data limit 5;输出结果如下

创建表usage_data并导入数据
create table hive_batch.usage_data
(USER_ID int,SERVICE_KIND string,CALL_DURATION int,CALLED_DURATION int,IN_PACKAGE_FLUX int,OUT_PACKAGE_FLUX int,MONTHLY_ONLINE_DURATION int,NET_DURATION int)
row format delimited fields terminated by ',' stored as textfile;
LOAD DATA INPATH '/user/usage_dir_data/usage_data.csv' OVERWRITE INTO TABLE hive_batch.usage_data;显示前5行的命令如下
select * from hive_batch.usage_data limit 5;输出结果如下

此时显示当前数据库下所有表格,应该能看见所有的三张表
show tables;输出结果如下
三 🚀 新集群Hive建库建表
同样的方法,利用Xfce登录mrs_new集群,注意用mrs_new集群所绑定的公网IP地址
ssh root@xxx.xxx.xxx.xxx然后登录后,进入Hive命令窗口
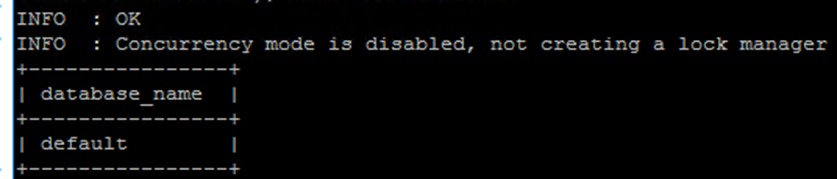
beeline显示现有的数据库
show databases;目前应该只有default数据库才对
创建hive_batch_new数据库,并切换到hive_batch_new
create database hive_batch_new;
use hive_batch_new;然后显示当前数据库下所有表格
show tables;当前应该没有任何数据表的
创建personal_data表
create table hive_batch_new.personal_data
(USER_ID int,SERVICE string, AGE int,LOCATION string, CAREER string,CREATEDATE string)
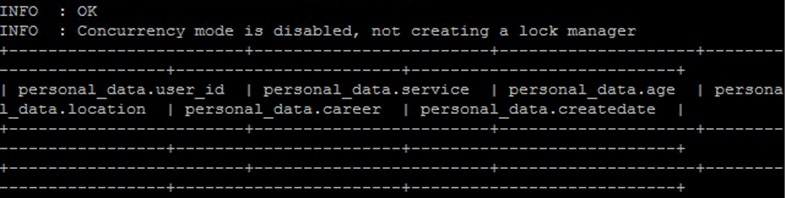
row format delimited fields terminated by ',' stored as textfile;该personal_data表应该是空表
select * from hive_batch_new.personal_data limit 5;输出结果如下
创建表recharge_data表
create table hive_batch_new.recharge_data
(USER_ID int,LAST_RECHARGE_VALUE int,TOTAL_RECHARGE_VALUE int,
TOTAL_RECHARGE_COUNT int,BALANCED int)
row format delimited fields terminated by ',' stored as textfile;该表应该也是空表
select * from hive_batch_new.recharge_data limit 5;输出结果如下
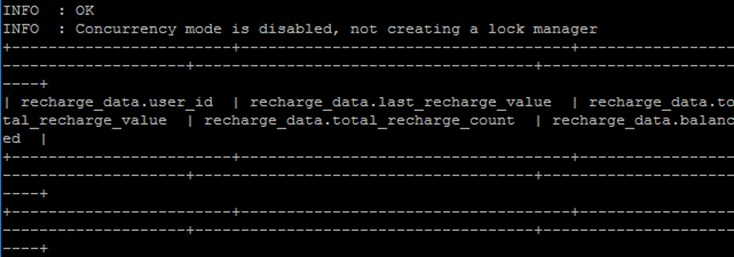
创建表usage_data并导入数据
create table hive_batch_new.usage_data
(USER_ID int,SERVICE_KIND string,CALL_DURATION int,CALLED_DURATION int,IN_PACKAGE_FLUX int,OUT_PACKAGE_FLUX int,MONTHLY_ONLINE_DURATION int,NET_DURATION int)
row format delimited fields terminated by ',' stored as textfile;同样是空表
select * from hive_batch_new.usage_data limit 5;输出结果如下
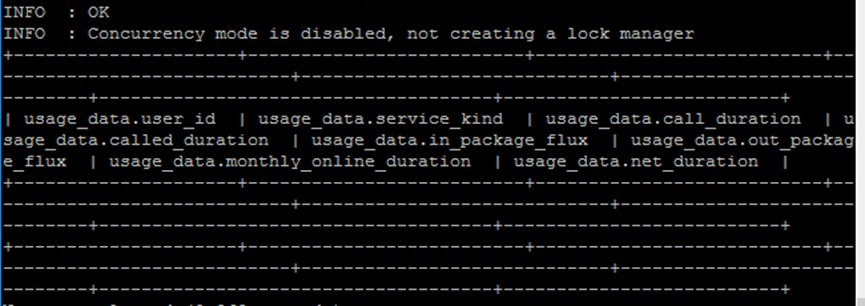
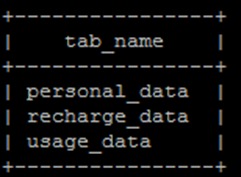
此时显示当前数据库下所有表格,应该能看见所有的三张表
show tables;输出结果如下
四 🥩 CDM迁移Hive数据表
4.1 创建CDM链接
进入CDM界面,然后点击“作业管理”

在“连接管理”标签下点击“新建连接”
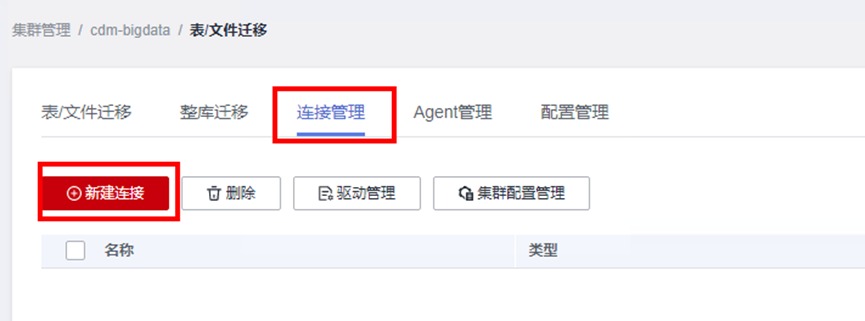
由于我们模拟从一台MRS集群迁移到另一台MRS集群,因此需分别针对mrs_old和mrs_new创建两个MRS Hive连接。先创建针对mrs_old的连接选择MRS Hive,点击下一步
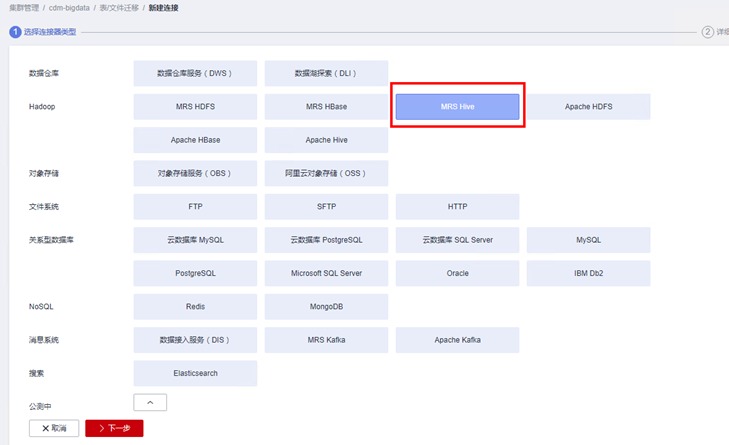
基本参数
① 名称:Hive_old
② 连接器:Hive
③ Hadoop类型:MRS
④ Manage IP:在右侧点击“选择”按钮,找到自己创建的mrs_old,点击该集群名称,会自动映射到该集群的Active Master节点IP
⑤ 认证类型:SIMPLE
⑥ Hive版本:HIVE_3_X
⑦ 用户名:admin
⑧ 密码:设置为自己购买MRS集群时的密码
⑨ OBS支持:否
⑩ 运行模式:EMBEDDED
⑪ 是否使用集群配置:否
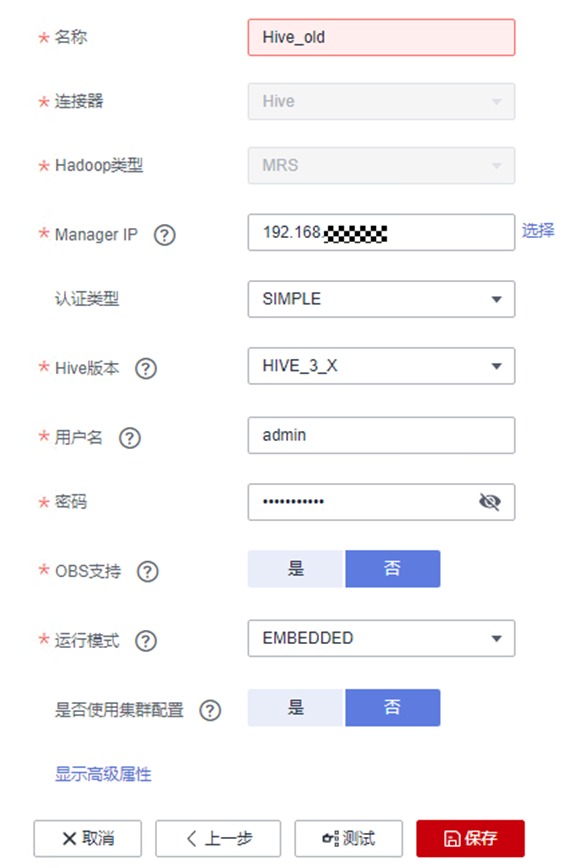
然后确认无误后点击“测试“。测试可能需要花费一定时间,请耐心等约半分钟,测试通过后点保存,即可保存所创建的连接了
类似的,再建立一个到mrs_new集群Hive的连接
① 名称:Hive_new
② 连接器:Hive
③ Hadoop类型:MRS
④ Manage IP:在右侧点击“选择”按钮,找到自己创建的mrs_new,点击该集群名称,会自动映射到该集群的Active Master节点IP
⑤ 认证类型:SIMPLE
⑥ Hive版本:HIVE_3_X
⑦ 用户名:admin
⑧ 密码:设置为自己购买MRS集群时的密码
⑨ OBS支持:否
⑩ 运行模式:EMBEDDED
⑪ 是否使用集群配置:否
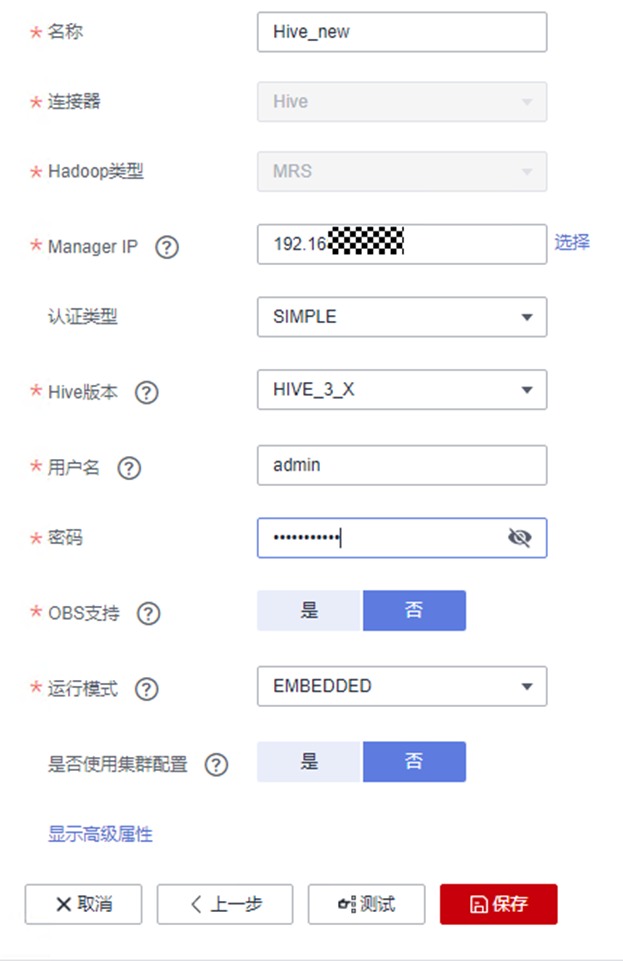
确认无误后点击“测试“。测试可能需要花费一定时间,请耐心等约半分钟,测试通过后点击保存,即可保存所创建的连接了
两个连接都创建成功后,完成后回到连接管理界面,可以看到所创建的连接如下
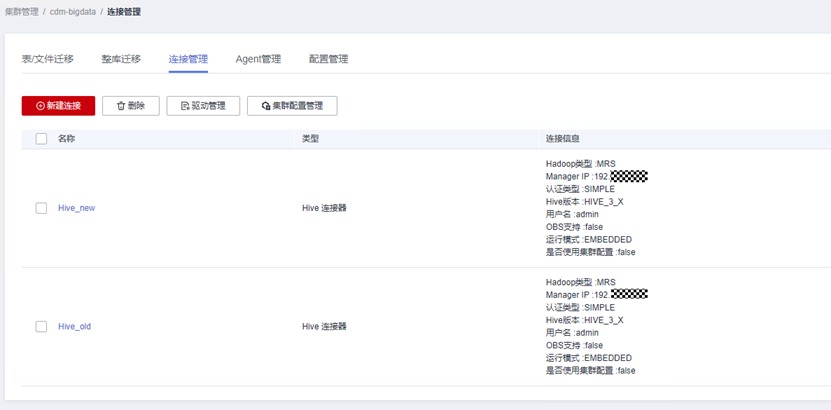
4.2 新建表迁移作业
进入“ 表/文件“迁移界面
点“新建作业”
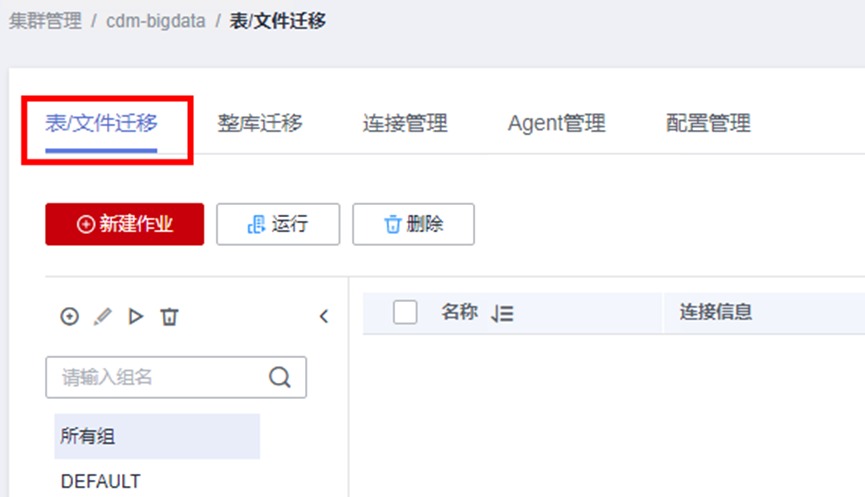
配置信息如下
作业名称:HiveQYCS
源端作业配置
源连接名称:下拉选择Hive_old
数据库名称:下拉选择hive_batch
数据表名称:下拉选择personal_data
读取方式:HDFS
目的端作业配置
目的连接名称:下拉选择Hive_new
数据库名称:下拉选择hive_batch_new
表名:下拉选择personal_data
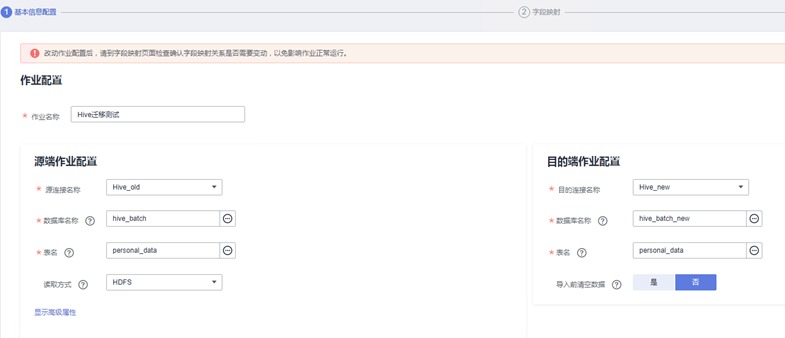
确认无误后点击“下一步“,进入字段映射的界面
由于我们建表时字段数量、名称和类型都是完全一致的,因此无需配置。在实际业务中可能会有目的端和源端字段不一致的情况,可根据实际需要进行配置
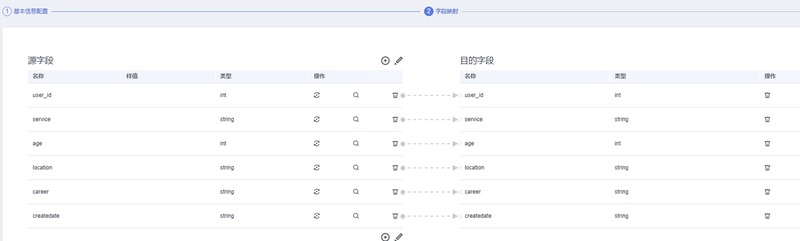
确认无误后点击下一步,进入任务配置,这一步可配置失败重试机制,能防止因网络问题导致迁移失败,同时在高级选项中还可根据迁移作业大小配置作业的并发度。由于我们的演示数据量不大,因此不做配置,保持默认即可
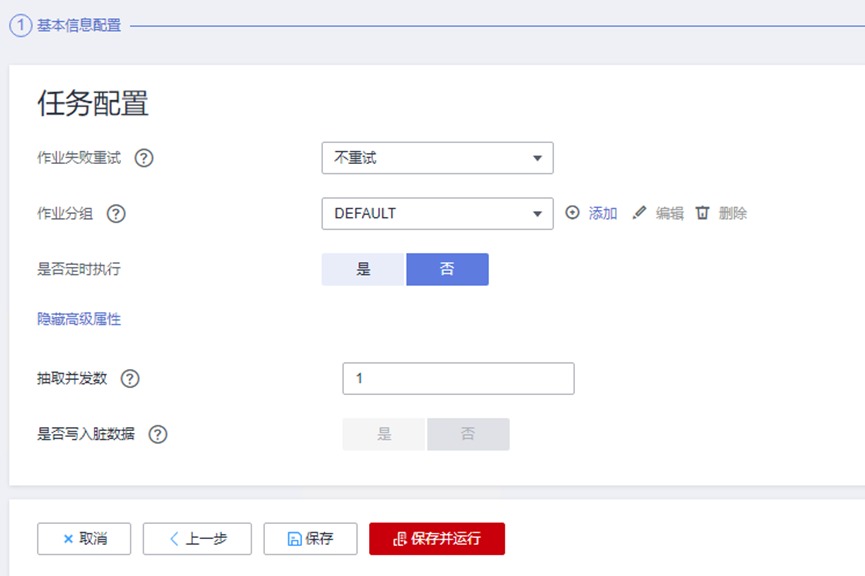
确认无误后,点击保存并运行。任务提交后等待约5秒左右即可完成迁移

使用Xfce回到mrs_new集群,进入Hive操作界面
beeline切换至hive_batch_new数据库,查看personal_data表前5行,发现数据已被正确迁移至新集群
use hive_batch_new;
select * from hive_batch_new.personal_data limit 5;
4.3 新建整库迁移作业
表迁移作业只能一次迁移一张表,当表文件数量较多时比较繁琐。在CDM服务中还提供了整库迁移的选项,可以一次性批量迁移多张表格,从而大大提高了迁移的效率
回到CDM作业配置界面,找到“整库迁移“标签,点击“新建作业”
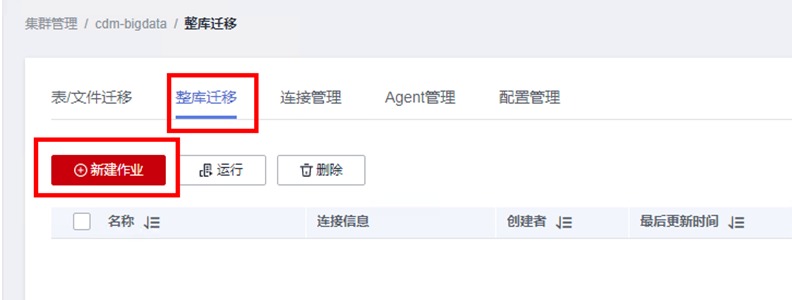
配置作业信息如下
作业名称:HiveZKQY
源连接名称:下拉选择Hive_old
数据库名称:下拉选择hive_batch
目的连接名称:下拉选择Hive_new
数据库名称:下拉选择hive_batch_new
另外,由于之前已经导入过personal_data表,因此需将“导入前清空数据” 选项选为“是“
注意:只有内部表才可清空数据,外部表无法执行清空数据选项
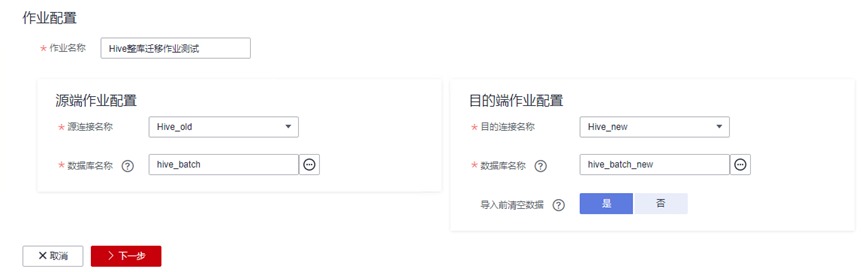
确认无误后点击下一步。此时字段映射选择的是需要迁移的表。如果需将所有表都迁移至新集群,可以点击“全选”,然后点击“>>”按钮
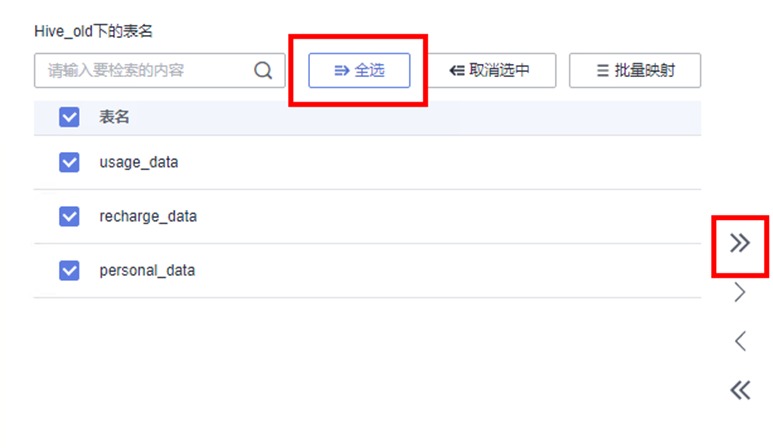
发现所有表均被放置到右侧
点击下一步
在任务配置界面,根据需要设定“同时执行的子作业个数”和“抽取并发数”。此处我们保持默认即可
确认无误后点击“保存并运行”。提交成功后等待约7秒即可迁移成功

利用Xfce登录mrs_new集群,回到Hive命令行:
beeline切换至hive_batch_new数据库,分别查看recharge_data表和usage_data表的前5行,发现数据已被正确迁移至新集群
use hive_batch_new;
select * from hive_batch_new.recharge_data limit 5;
select * from hive_batch_new.usage_data limit 5;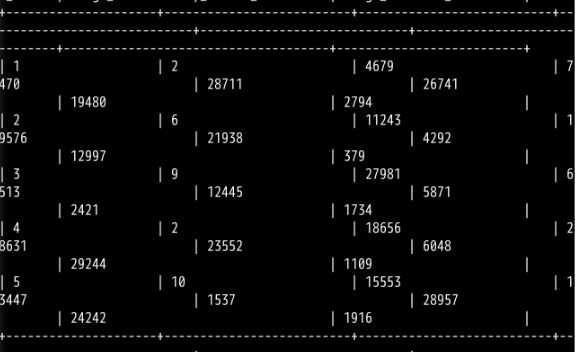
五 🌈 CDMHBase数据表
5.1 旧集群HBase建表
在mrs-old集群管理页中点击进入 Manager页 ,选择EIP方式,下载HBase命令行客户端并执行安装
浏览器会有风险提示,此时点击高级选择“继续前往”
登录FusionInsight Manager,账号名为admin,密码为购买云服务时自定义的密码
找到HBase组件,点击进入组件管理页面
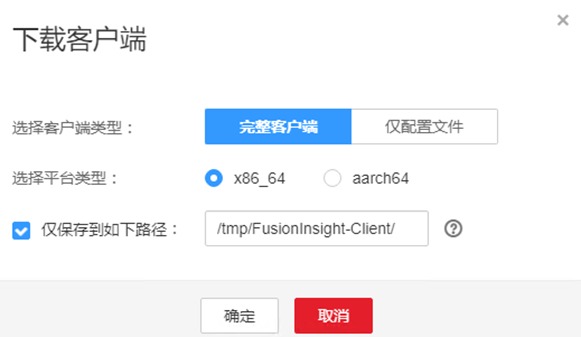
在右上角选择“更多 > 下载客户端”,弹出“下载客户端”信息提示框

“选择客户端类型”中选择“完整客户端”
“选择平台类型”中选择x86_64
勾选“仅保存到如下路径”,单击“确定”开始生成客户端文件
文件生成后默认保存在主管理节点“/tmp/FusionInsight-Client”

打开一个新的Xfce窗口,登录到MRS-old集群
ssh root@xxx.xxx.xxx.xxx进入安装包所在目录,例如“/tmp/FusionInsight-Client”
cd /tmp/FusionInsight-Client执行如下命令解压安装包到本地目录
tar -xvf FusionInsight_Cluster_1_HBase_Client.tar解压获取的安装文件
tar -xvf FusionInsight_Cluster_1_HBase_ClientConfig.tar进入安装包所在目录
cd /tmp/FusionInsight-Client/FusionInsight_Cluster_1_HBase_ClientConfig执行下列命令,安装客户端到指定目录(绝对路径),如安装到“/opt/client”目录
./install.sh /opt/client等待客户端安装完成。执行以下命令切换到客户端目录
cd /opt/client然后执行以下命令配置环境变量
source bigdata_env输入hbase shell进入hbase命令行
hbase shell在HBase中创建data_old数据表并导入数据
import java.util.Date
#创建表
create 'data_old','f'
#插入数据
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100001","p_name":"<张家界-凤凰-天门山-玻璃栈道飞机5日游>","price":"2141"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100002","p_name":"<丽江-香格里拉-泸沽湖双飞7日游>","price":"4429"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100003","p_name":"<香格里拉-昆大丽3飞6日游>","price":"2479"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100004","p_name":"<桂林-阳朔-古东瀑布-世外桃源双飞5日游>","price":"2389"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100005","p_name":"<海南三亚-无自费5日游>","price":"2389"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100006","p_name":"<成都-九寨沟-黄龙-花湖-红原-九曲双飞7日游>","price":"3729"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100007","p_name":"<海南三亚5日游>","price":"2168"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100008","p_name":"<海南三亚五星0购物6日游>","price":"2916"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100009","p_name":"<厦门双飞4日游>","price":"1388"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100010","p_name":"<绵阳-九寨-黄龙-都江堰-成都双飞5日游>","price":"2899"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100011","p_name":"<桂林-阳朔-古东-世外桃源双飞4日游>","price":"2249"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100012","p_name":"<成都-九寨沟-黄龙双飞6日游>","price":"2611"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100013","p_name":"<版纳-香格里拉-昆大丽4飞一卧8日游>","price":"3399"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100014","p_name":"<成都-都江堰-黄龙九寨沟双飞6日游>","price":"2989"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100015","p_name":"<桂林-大漓江-阳朔-龙脊梯田双飞4日游>","price":"2048"}'
put 'data_old',Date.new().getTime(),'f:content','{"p_id":"100016","p_name":"<长沙-张家界-黄龙洞-天门山-凤凰双飞7日游>","price":"3141"}'插入成功后,使用scan命令查看data_old数据表
scan 'data_old'结果如下(部分结果)
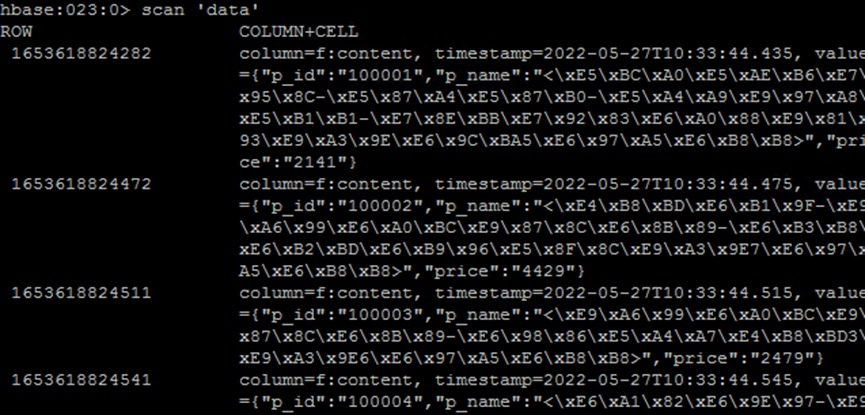
由于集群默认使用utf-8编码格式,因此中文显示不正常,但不影响后续使用
5.2 新集群HBase建表
使用同样的方法在新集群创建表
浏览器会有风险提示,此时点击高级选择“继续前往”
登录FusionInsight Manager,账号名为admin,密码为购买云服务时自定义的密码
找到HBase组件,点击进入组件管理界面
在右上角选择“更多 > 下载客户端”,弹出“下载客户端”信息提示框
“选择客户端类型”中选择“完整客户端”
“选择平台类型”中选择x86_64
勾选“仅保存到如下路径”,单击“确定”开始生成客户端文件
文件生成后默认保存在主管理节点“/tmp/FusionInsight-Client”
打开一个新的Xfce窗口,登录到MRS-new集群
ssh root@xxx.xxx.xxx.xxx进入安装包所在目录,例如“/tmp/FusionInsight-Client
cd /tmp/FusionInsight-Client执行如下命令解压安装包到本地目录
tar -xvf FusionInsight_Cluster_1_HBase_Client.tar解压获取的安装文件
tar -xvf FusionInsight_Cluster_1_HBase_ClientConfig.tar进入安装包所在目录
cd /tmp/FusionInsight-Client/FusionInsight_Cluster_1_HBase_ClientConfig执行下列,安装客户端到指定目录(绝对路径),例如安装到“/opt/client”目录
./install.sh /opt/client等待客户端安装完成。执行以下命令切换到客户端目录
cd /opt/client执行以下命令配置环境变量
source bigdata_env输入hbase shell进入hbase命令行
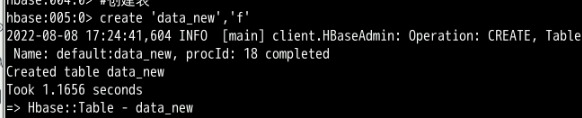
hbase shell在HBase中创建data_new数据表
import java.util.Date
#创建表
create 'data_new','f'创建成功后显示如下
插入成功后,使用scan命令查看data_new数据表
scan 'data_new'此时是一个空表

5.3 创建CDM链接
进入CDM界面,点击“作业管理”

在“连接管理”标签下点击“新建连接”
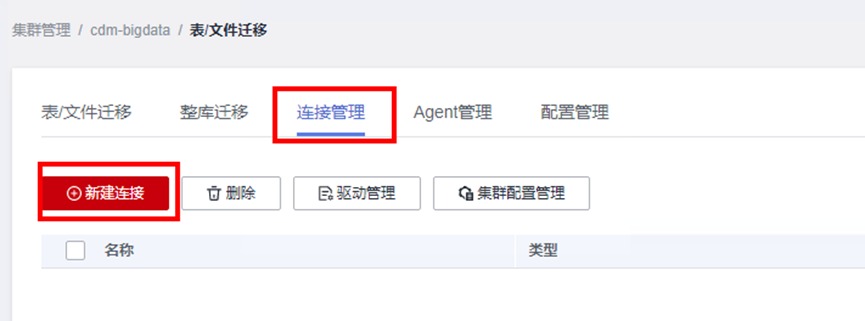
配置对应的HBase连接
类似地,我们需分别针对mrs_old和mrs_new创建两个MRS HBase连接,先创建针对mrs_old的连接
选择MRS HBase,点击下一步
配置基本参数
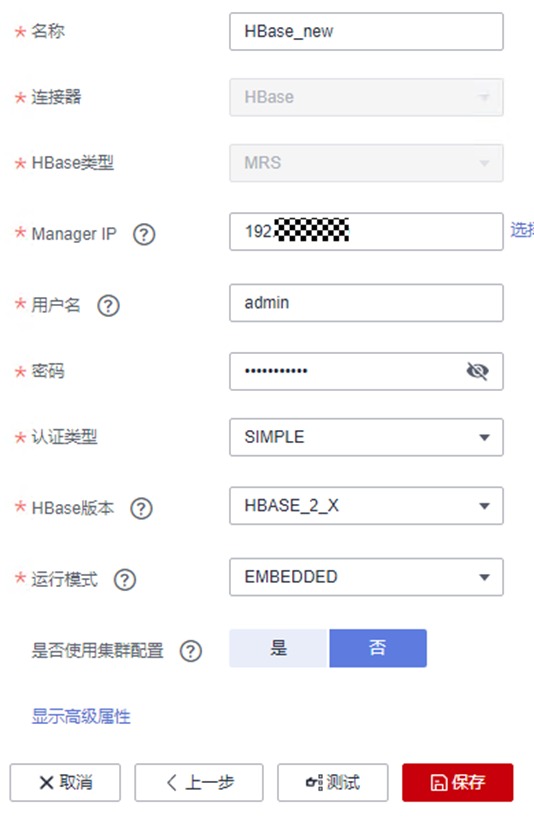
① 名称:HBase_old
② 连接器:HBase
③ HBase类型:MRS
④ Manage IP:在右侧点击“选择”按钮,找到自己创建的mrs_old,点击该集群名称,会自动映射到该集群的Active Master节点IP
⑤ 用户名:admin
⑥ 密码:设置为自己购买MRS集群时的密码
⑦ 认证类型:SIMPLE
⑧ HBase版本:HBASE_2_X
⑨ 运行模式:EMBEDDED
⑩ 是否使用集群配置:否
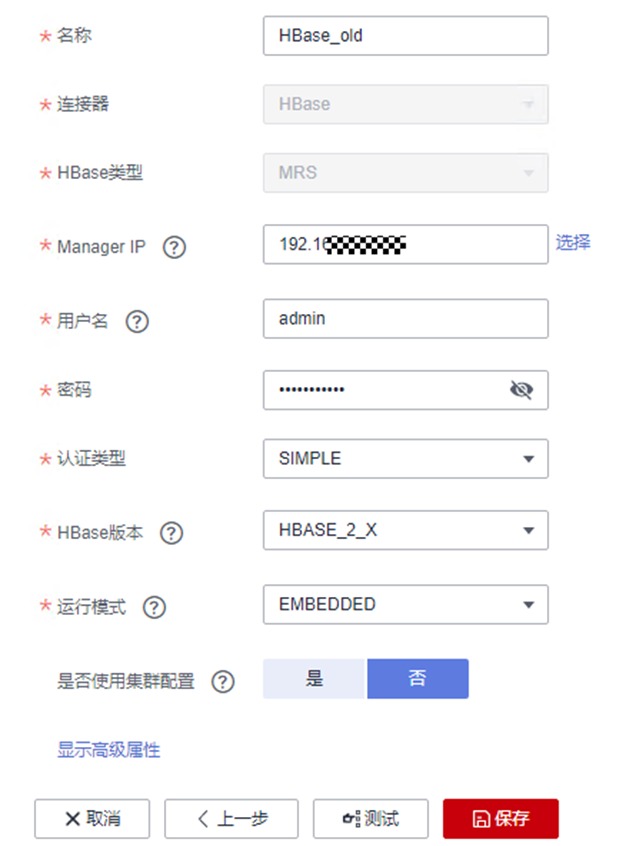
确认无误后点“测试“。测试可能要花费一定时间,请耐心等待约半分钟。测试通过后点保存,即可保存所创建的连接了!
类似的,再建立一个到mrs_new集群Hive的连接
① 名称:HBase_new
② 连接器:HBase
③ HBase类型:MRS
④ Manage IP:在右侧点击“选择”按钮,找到自己创建的mrs_new,点击该集群名称,会自动映射到该集群的Active Master节点IP
⑤ 用户名:admin
⑥ 密码:设置为自己购买MRS集群时的密码
⑦ 认证类型:SIMPLE
⑧ HBase版本:HBASE_2_X
⑨ 运行模式呢:EMBEDDED
⑩ 是否使用集群配置:否
确认无误后点“测试“,可能需要花一定时间,请耐心等约半分钟,测试通过后点击保存,即可保存所创建的连接了!
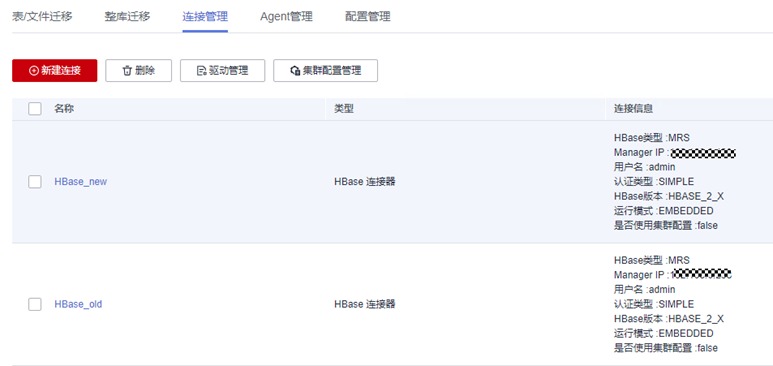
两个连接都创建成功后,完成后回到连接管理界面,可以看到所创建的连接如下
5.4 新建表迁移作业
进入“ 表/文件“迁移界面
点“新建作业“
配置信息如下
作业名称:HBaseQYCS
源端作业配置
源连接名称:下拉选择HBase_old
表名:下拉选择data_old
整表迁移:是
目的端作业配置
目的连接名称:下拉选择HBase_new
表名:下拉选择data_new
导入前清空数据:否
自动创表:下拉选择“不存在时创建”

确认无误后点击“下一步“,进入任务配置的界面
同样,这一步可配置失败重试机制,防止因网络问题导致迁移失败,同时在高级选项中还可根据迁移作业大小配置作业的并发度,由于我们的演示数据量不大,因此不做配置,保持默认即可
确认无误后,点击保存并运行。任务提交后等待约5秒左右即可完成迁移

使用Xfce回到mrs_new集群,进入HBase操作界面(需按之前类似步骤安装HBase客户端).
hbase shell使用list命令查看是否有data_new数据表
list结果如下
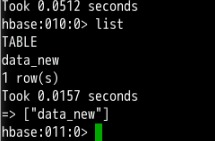
然后查看数据是否成功导入呢?
scan 'data_new'发现已有数据存在

任务结束!

- 点赞
- 收藏
- 关注作者
评论(0)