多维分析预汇总应该怎样做才管用?

多维分析(OLAP)通常要求极高的响应效率,当涉及的数据量很大时,每次都基于明细数据汇总效率就会很低,人们会考虑采用预汇总的方式加快查询速度,即事先将要查询的结果计算好,使用时直接读取预汇总结果就可以获得实时响应,从而满足交互分析的需要。
不过,将可能的维度组合全部预汇总不太现实,按中间CUBE大小仅1KB计算50个维度的全量预汇总需要的存储空间高达1MT,需要100百万块1T的硬盘,即使只汇总其中20个维度也要占用470000T的空间(多维分析预汇总的存储容量),显然都不能接受。所以,一般会采用部分预汇总的方式,汇总其中一部分维度以平衡存储空间和性能需要。
预汇总方案的困境
其实,即使不考虑容量问题,预汇总也只能满足多维分析中一小部分相对固定的查询需求,稍微复杂灵活的场景就搞不定了,而这些场景在实际业务中大量存在。
-
非常规聚合:除了常见的合计、计数外,有些非常规聚合,比如唯一计数、中位数、方差等很可能被遗漏,也无法从其它聚合值计算出来。理论上有无数种聚合运算,不可能被预汇总。
-
组合聚合:聚合运算可能组合。比如我们可能关心月平均销售额,这个值是将每天的销售额按月合计后再求平均。它并不是单纯的合计和平均,而是两种聚合运算在不同维度层次上的组合。这些也不太可能事先预汇总。
-
条件测度:测度在统计时还可能带有条件。比如,我们想了解一下交易金额大于 100 元以上的订单销售额合计。这个信息也无法在预汇总时处理,因为 100 会是临时输入的参数。
-
时间段统计:时间是个特别维度,它即可以枚举、也可以采用连续区间的方式来做切片。查询区间的起止点可能是细粒度(比如到某日),就必须用细粒度的数据再统计,而无法直接使用更高层的预汇总数据。
预汇总的确能一定程度地提高多维分析的性能,但只能应对多维分析中很少的场景,而且还只能部分预汇总,使用场景就更有限了,即使这样还要面临巨大存储空间的问题。把多维分析的效果寄希望于预汇总方案并不靠谱。要做好多维分析,硬遍历的功夫是基本的,即使有了预汇总数据,也要在优秀的硬遍历能力辅助下才能发挥更大的作用。
SPL预汇总
开源的集算器SPL提供了常规多维分析预汇总方式,还有特色的时间段预汇总,更重要的是借助SPL优秀的数据遍历能力还能满足多维分析更广泛的场景需要。
首先看一下SPL的预汇总能力。
部分预汇总
全量预汇总不现实,只能进行部分预汇总,虽然无法达到O(1)的响应速度,但也可以把性能提升几十倍,有一定意义。SPL可以根据需要建立多个预汇总的中间结果。例如,数据表 T 有 A、B、C、D、E 五个维度。根据业务经验就可以预先计算出来了几个最常用的中间结果。
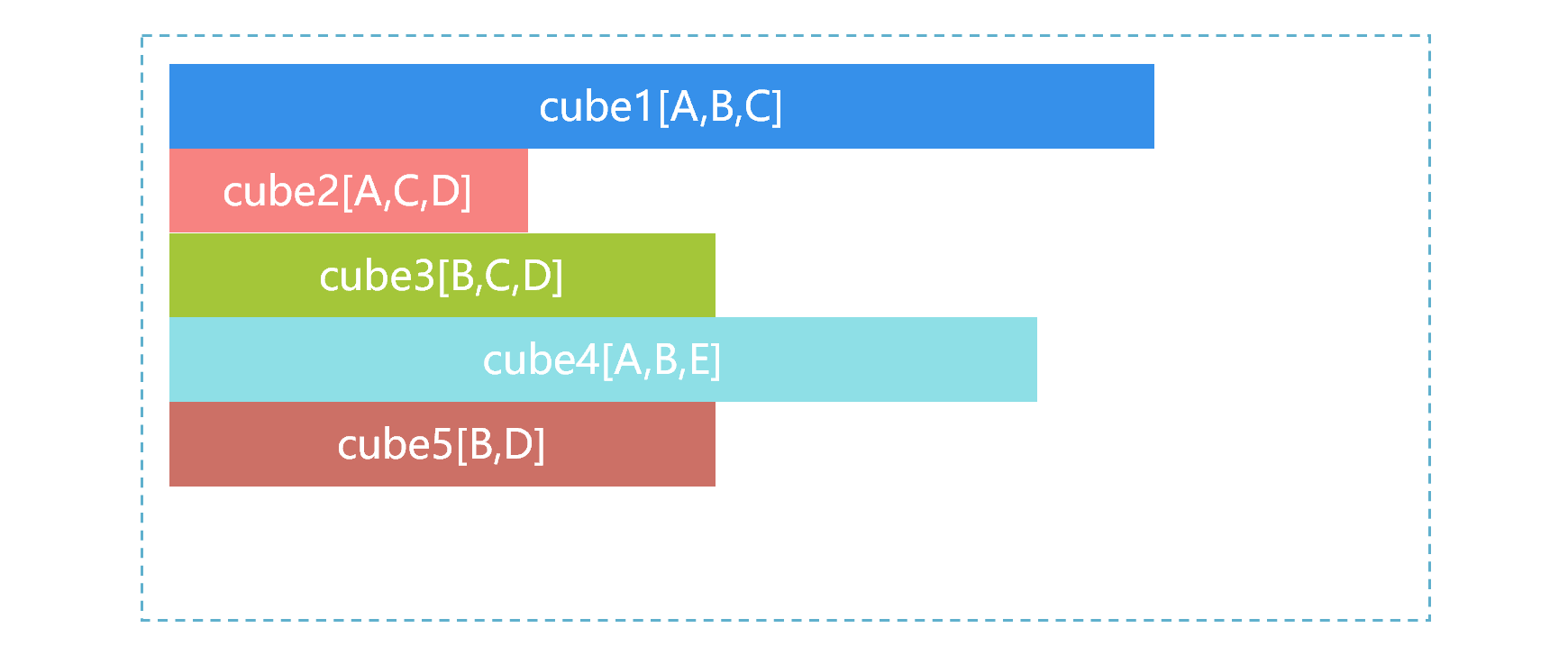
上图中cube 占用存储空间的大小用条形长度来表示,cube1 最大,cube2 最小。前端应用来了一个请求,要按照 B、C 做统计汇总。这时 SPL 对多个 cube 自动选择的过程大致如下。
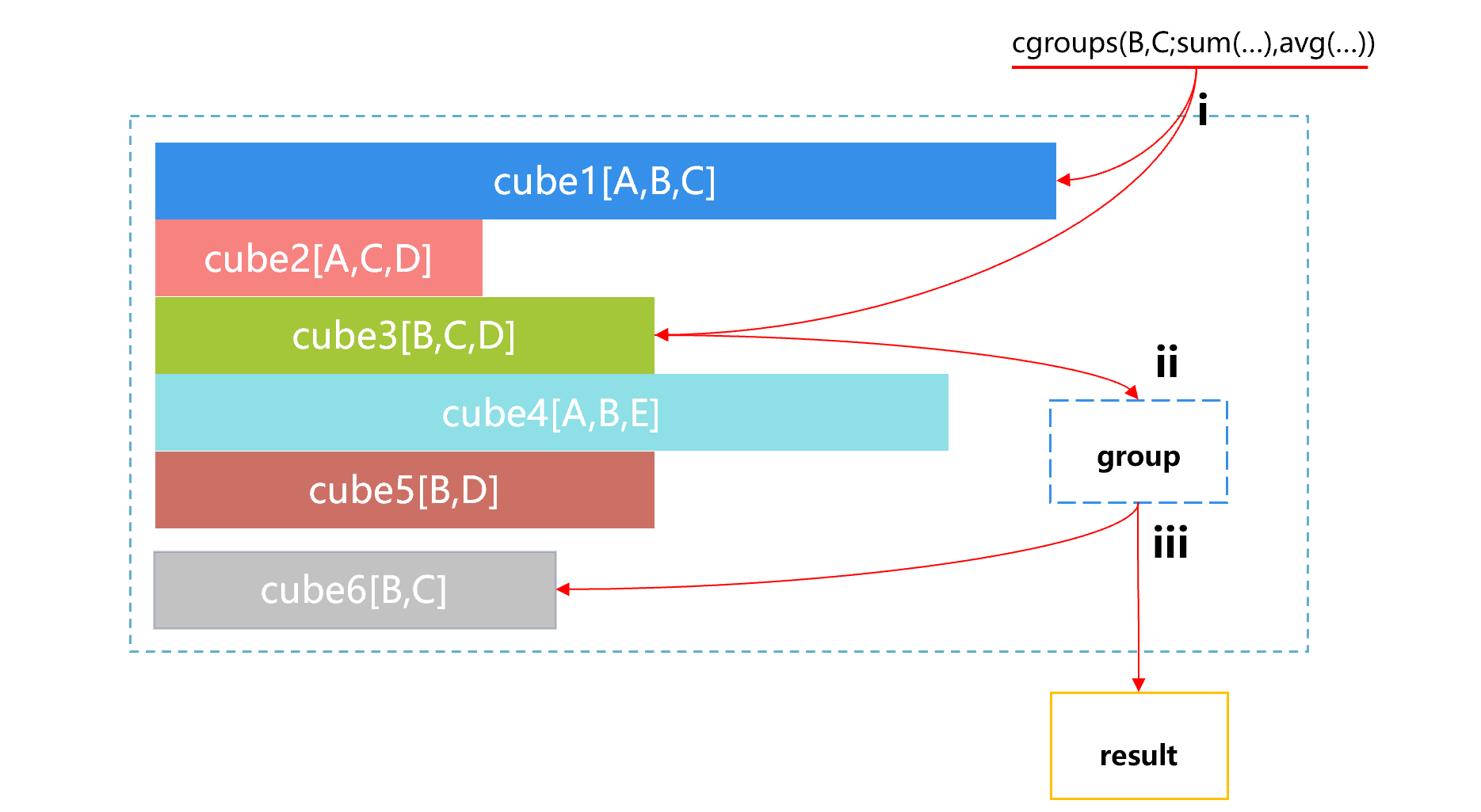
第i步,SPL 找到可以利用的 cube 是 cube1 和 cube3。第 ii 步,SPL 发现 cube1 比较大,就会自动选择比较小的 cube3,并在其基础上按 B、C 做分组汇总。
SPL代码示例:
| A | |
| 1 | =file("T.ctx").open() |
| 2 | =A1.cuboid(cube1,A,B,C;sum(…),avg(…),…) |
| 3 | =A1.cuboid(cube2,A,C,D;sum(…),avg(…),…) |
| 4 | =A1.cgroups(B,C;sum(…), avg(…)) |
使用 cuboid 函数建立预汇总数据(A2和A3),需要起个名字(如cube1),剩下的参数是维度和汇总测度;A4使用时通过cgroups函数就会自动利用上面的规则使用中间cube并选择数据量最小的使用了。
时间段预汇总
时间是多维分析中特别重要的一种维度,它即可以枚举、也可以采用连续区间的方式来做切片。比如业务中经常要查询如 5 月 8 日到 6 月 12 日之间的销售额合计,这个起止时间点也是查询时作为参数传递进来的,具有很强的随意性。时间段统计还可能有多个组合关联的情况,比如看看 5 月 8 日到 6 月 12 日间销出的、生产日期在 1 月 9 日到 2 月 17 日之间的货品总额。类似这种时间段统计有很强的业务意义,但却无法使用常规预汇总方案应对。
针对这种特殊的时间段统计,SPL提供了时间段预汇总方式。例如,订单表已经有一个按照订单日期预汇总的cube1,那么我们可以在此基础上再增加一个按月预汇总的cube2。这时要计算 2018 年 1 月 22 日到 9 月 8 日的金额汇总值,大致过程会是这样:
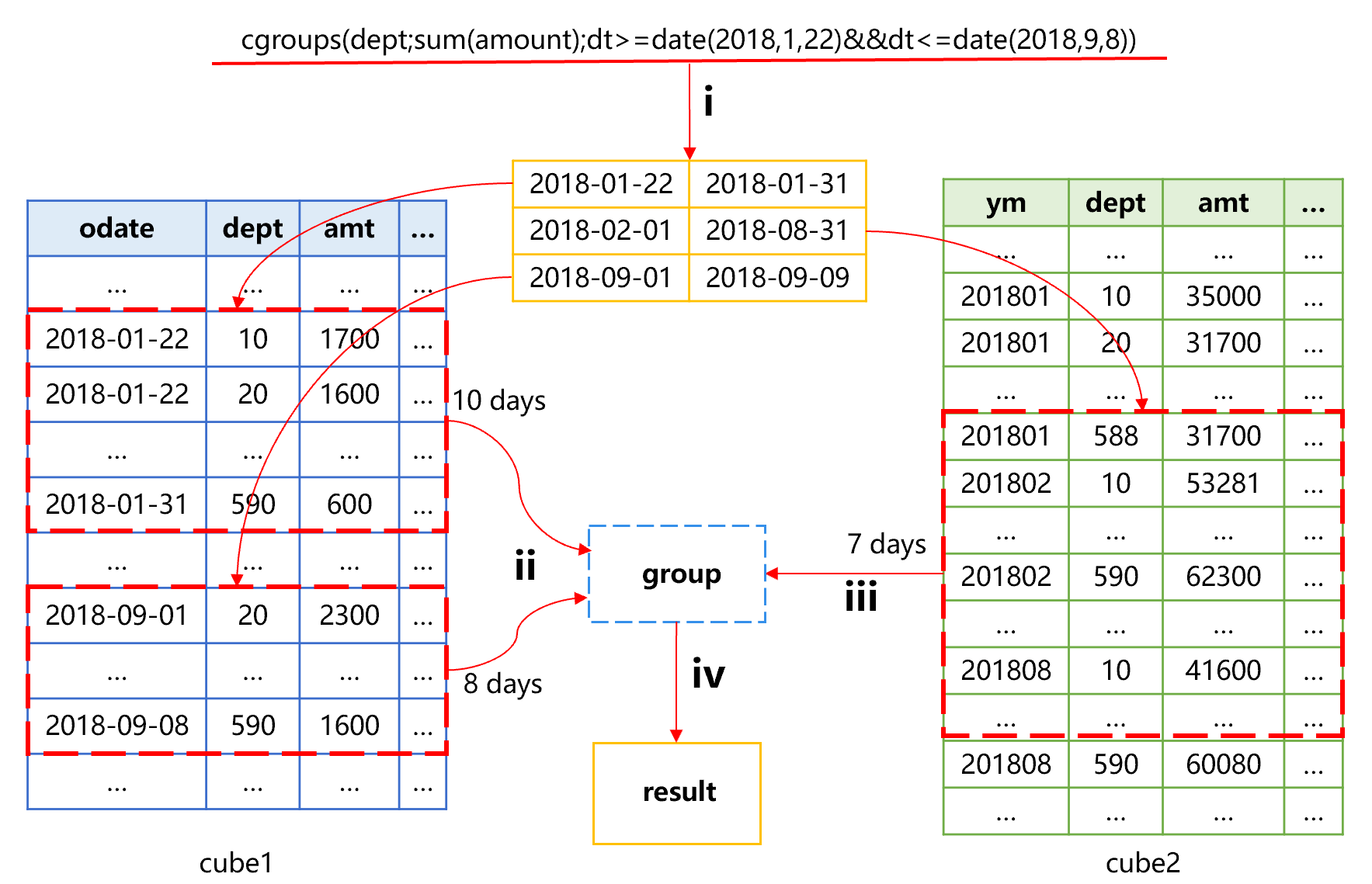
将时间段分成三段,2月到8月整月的数据基于月汇总cube2计算聚合值,再使用cube1计算 1 月 22 日到 1 月 31 日和 9 月 1 日到 9 月 8 日的聚合值,涉及的计算量是 7(2 月 -8 月)+10(1 月 22 日 -1 月 31 日)+8(9 月 1 日 -9 月 8 日)=25,而如果使用cube1数据聚合,其计算量是 223(从 1 月 22 日到 9 月 8 日的天数),几乎减少了 10 倍。
SPL代码示例:
| A | |
| 1 | =file("orders.ctx").open() |
| 2 | =A1.cuboid(cube1,odate,dept;sum(amt)) |
| 3 | =A1.cuboid(cube2,month@y(odate),dept;sum(amt)) |
| 4 | =A1.cgroups(dept;sum(amt);odate>=date(2018,1,22)&&dt<=date(2018,9,8)) |
cgroups 函数增加了条件参数,SPL 发现有时间段条件和更高层次的预汇总数据,则会使用时间段预汇总机制来减少运算量。本例中,就会分别从 cube1 和 cube2 中读取相应数据再来汇总。
SPL硬遍历
预汇总能够应对的场景仍然很有限,要做出灵活的多维分析,还是要指望过硬的遍历能力。多维分析运算本身并不算复杂,遍历计算主要是针对维度的过滤。传统数据库只能用WHERE硬算,维度相关的过滤也当作常规运算,不能获得较好的性能。SPL提供了多种维度过滤机制,可以满足各类多维分析场景的性能要求。
布尔维序列
多维分析中最常见的切片(切块)是针对枚举维度进行的,除了时间维度几乎都是枚举维度,如产品、地区、类型等。常规处理方式用SQL表达大概这样:
SELECT D1,…,SUM(M1),COUNT(ID)… FROM T GROUP BY D1,…
WHERE Di in (di1,di2…) …
其中的Di in(di1,di2)就是过滤字段在一个枚举范围内取值。在实际应用中,“按照客户性别、员工部门、产品类型等切片”都属于枚举维度切片。常规的IN方法需要进行多次比较判断才能筛选出符合条件的数据(切片),性能很低,IN的取值越多性能就越差。
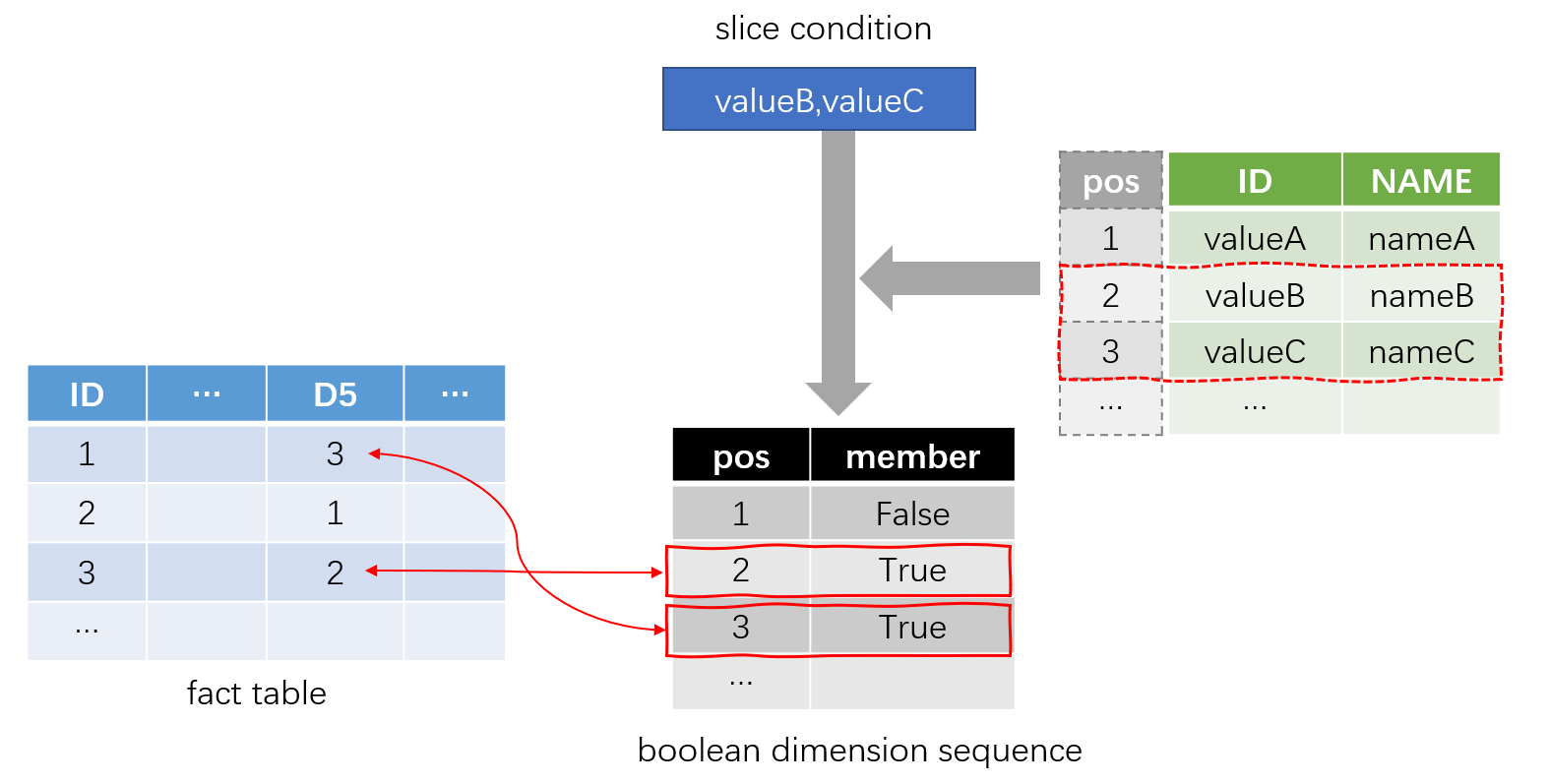
SPL将查找运算转换成取值运算来提升性能。先将枚举维度转换成整数),如下图将事实表中的维度D5取值转化成在维表中的序号(位置):
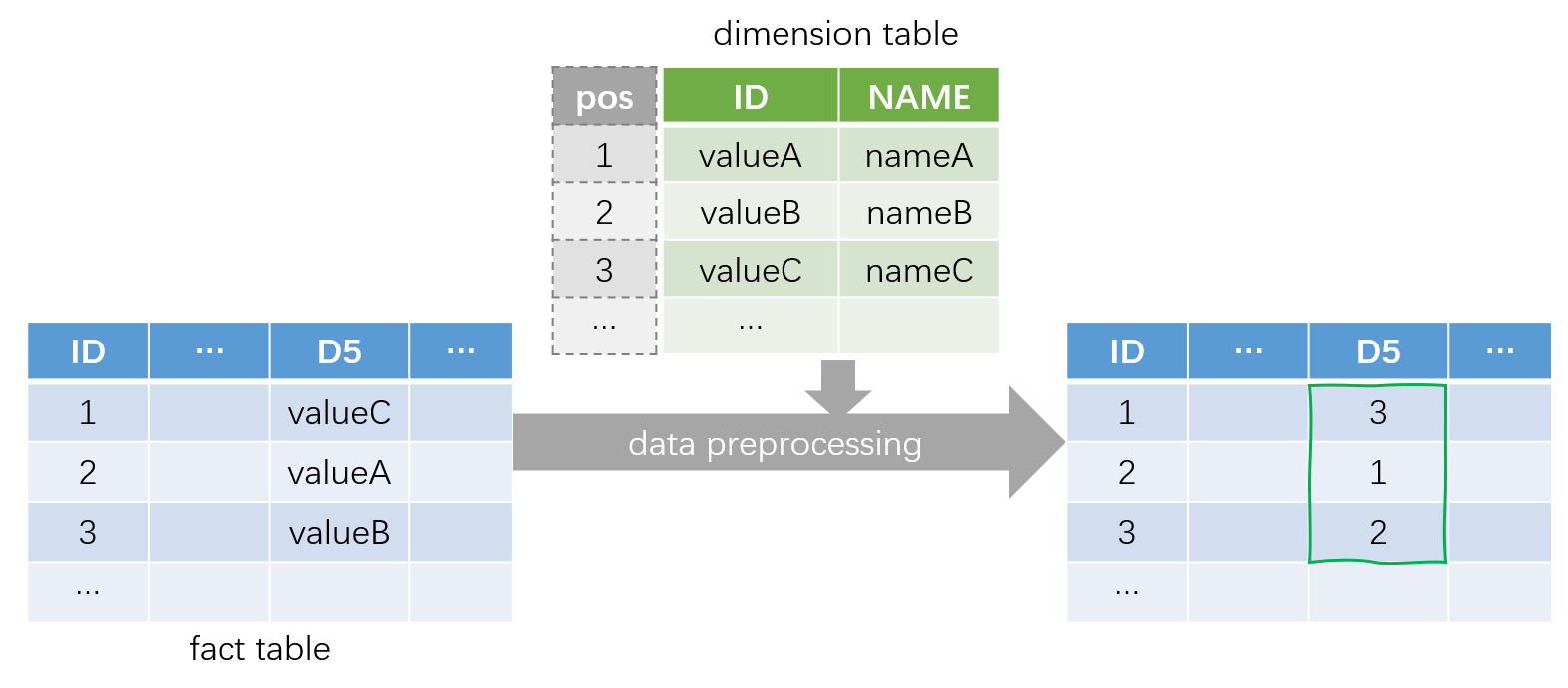
然后在查询时将切片条件转换成布尔值构成的对位序列,在比较时就可以直接从序列指定位置取出值(true/false)判断结果,快速完成切片操作。
SPL数据预处理代码示例:
| A | |
| 1 | =file("T.ctx").open() |
| 2 | =file("T_new.ctx”).create(…) |
| 3 | =DV=T(“DV.btx”) |
| 4 | =A1.cursor().run(D=DV.pos@b(D)) |
| 5 | =A2.append@i(A4) |
A3读取维表,A4 利用 DV 把维度 D 转换成整数。DV 将被另外保存供查询时使用。
切片汇总:
| A | |
| 1 | =file("T.ctx").open() |
| 2 | =DV.(V.pos(~)) |
| 3 | =A1.cursor(…;A2(D)) |
| 4 | =A3.groups(…) |
A2 将参数 V 转化成一个和 DV 同长的布尔值序列,DV 的成员在 V 中时,则 A2 对应位置的成员将非空(判断时起到 true 的作用),否则填成空(也就是 false)。然后在遍历切片时,只用已经转换成整数维度 D 作为序号去取这个布尔值序列的成员,如果非空就表明原来的维度 D 是属于切片条件 V 的。序号取值的运算复杂度远远小于IN比较,大幅提升切片性能。
SPL优秀的硬遍历能力在实践中应用效果明显,在开源 SPL 提速银行用户画像客群交集计算 200+ 倍 这个案例中,借助布尔维序列、游标前过滤等硬遍历技术将银行用户画像客群交集计算效率提升了200倍以上。
标签位维度
多维分析中还有一种特殊的枚举维度常用于切片(很少用于分组统计),其取值只有是/否或true/false两种情况,被称为标签维度或二值维度,比如人员是否结婚、是否上过大学、是否拥有信用卡等。标签维度切片属于过滤条件中的是否型计算,用SQL表达大概这样:
SELECT D1,…,SUM(M1),COUNT(ID)… FROM T GROUP BY D1,…
WHERE Dj=true and Dk=false …
标签维度很常见,对客户、事物贴标签是当前数据分析的重要手段,现代多维分析的数据集常常会有几百甚至上千个标签维度,如果将这种维度当作普通字段处理,无论是存储还是运算都会造成很多浪费,难以获得高性能。
标签维度只有两种取值,只要一个位就可以存储了。一个 16 位的整数可以保存 16 个标签,原本要用 16 个字段来存储的信息用一个字段就够了,这种存储方式称为标签位维度。SPL提供了这种机制,这将大幅度减少存储量也就是硬盘读取量,而且整数也不影响读取速度。
举个例子,这里我们假设总共有8个二值维度,用整数字段c1存储8位二进制数表示。要用按位存储的方法计算二值维度切片,需要先将事实表预处理为按位存储。
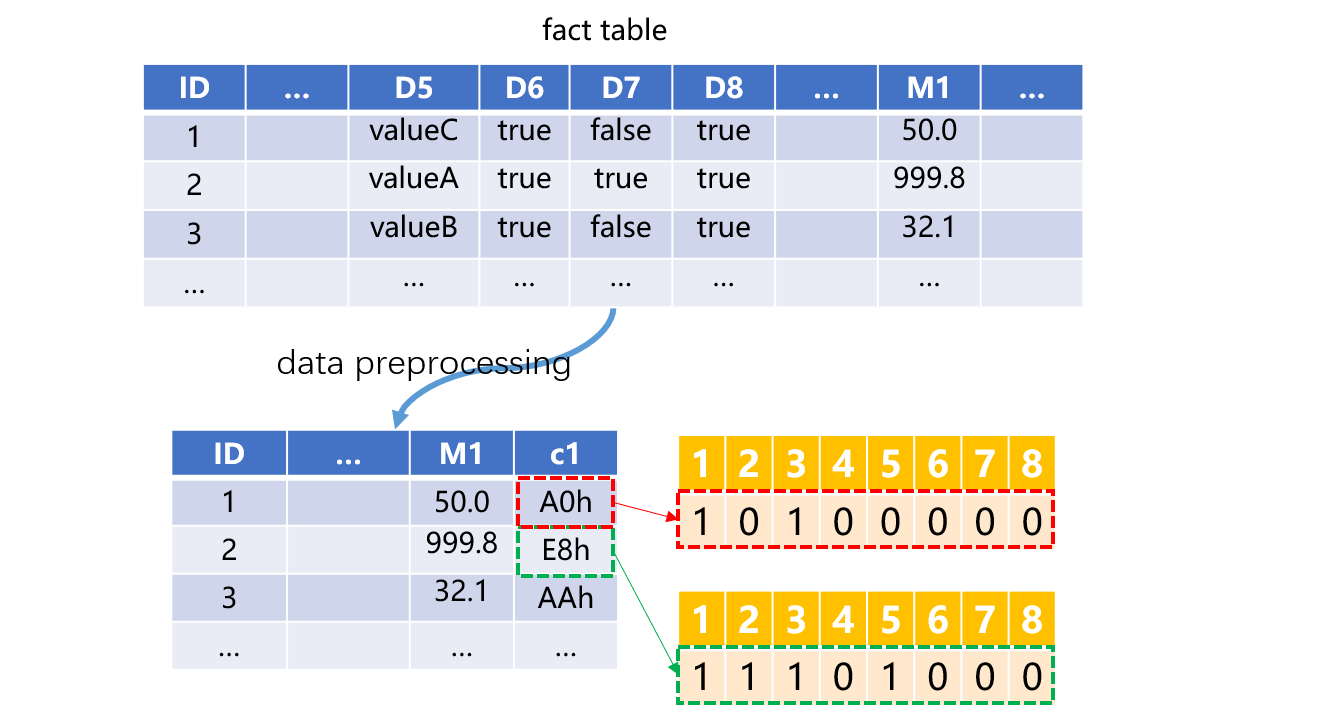
处理后的事实表,第一行c1为AFh,转换为二进制数为10100000,表示D6、D8是true,其他二值维度是false。然后就可以进行按位计算实现二值维度切片了。
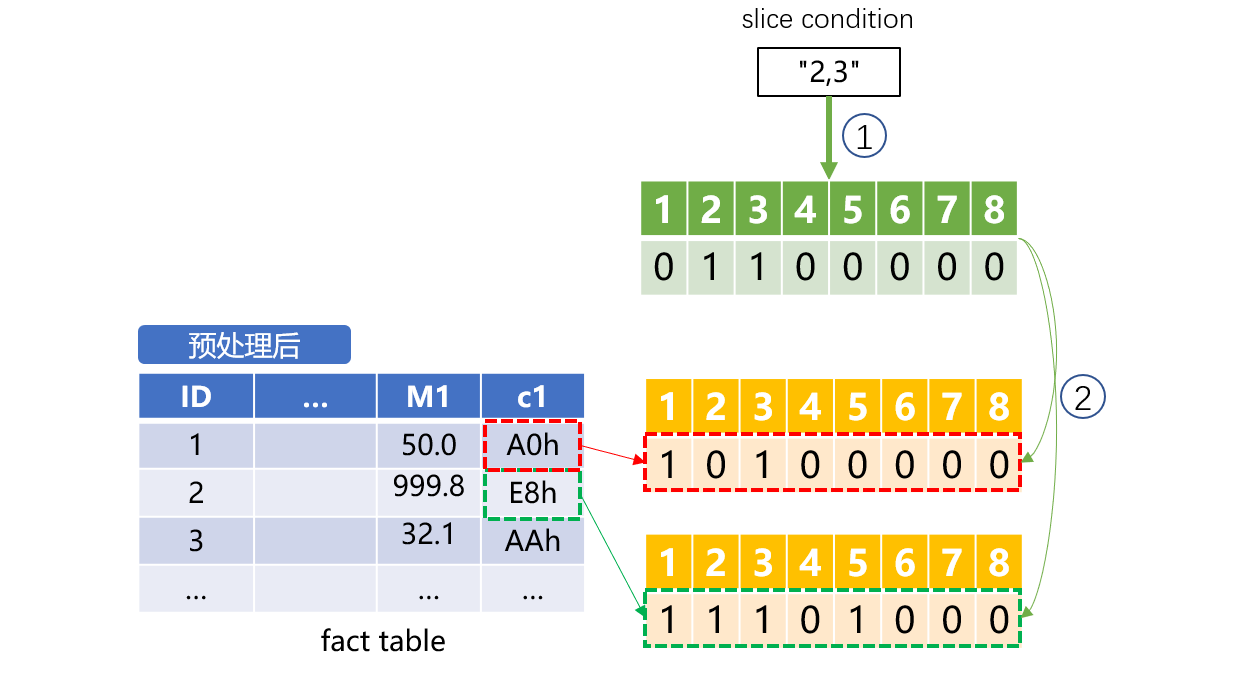
前端传入的切片条件为"2,3",也就是要过滤出第2个二值维度(D7)和第3个二值维度(D8)值是true,其他二值维度是false的数据。
SPL代码示例:
| A | B | |
| 1 | ="2,3" | =A1.split@p(",") |
| 2 | =to(8).(0) | =B1.(A2(8-~+1)=1) |
| 3 | =bits(A2) | |
| 4 | =file("T.ctx").open().cursor(;and(c1,A3)==A3) | |
| 5 | =A4.groups(~.D1,~.D2,~.D3,~.D4;sum(~.M1):S,count(ID):C) |
8个是否型条件过滤,只要做一次按位与计算即可实现。这样就将原来二值维度的多次比较计算,转换成了一次按位与计算,因此性能会有很明显的提升。多个是否值转换为一个整数,还可以减少数据占用的存储空间。
冗余排序
冗余排序是利用有序来加快读取(遍历)速度的优化手段,具体实现时按维度 D1,…,Dn排序后存储一份,再按 Dn,…,D1排序存储一份,数据量会翻倍,但还可以接受。对于任何维度 D,总能有一个数据集使 D 在其排序维度列表中的前半部分,如果不是第一个维度,切片后数据一般不会能连成一片区域,但也是由一些相对较大的连续区域构成的。在排序维度列表中越靠前的维度,切片后数据的物理有序程度就越高。
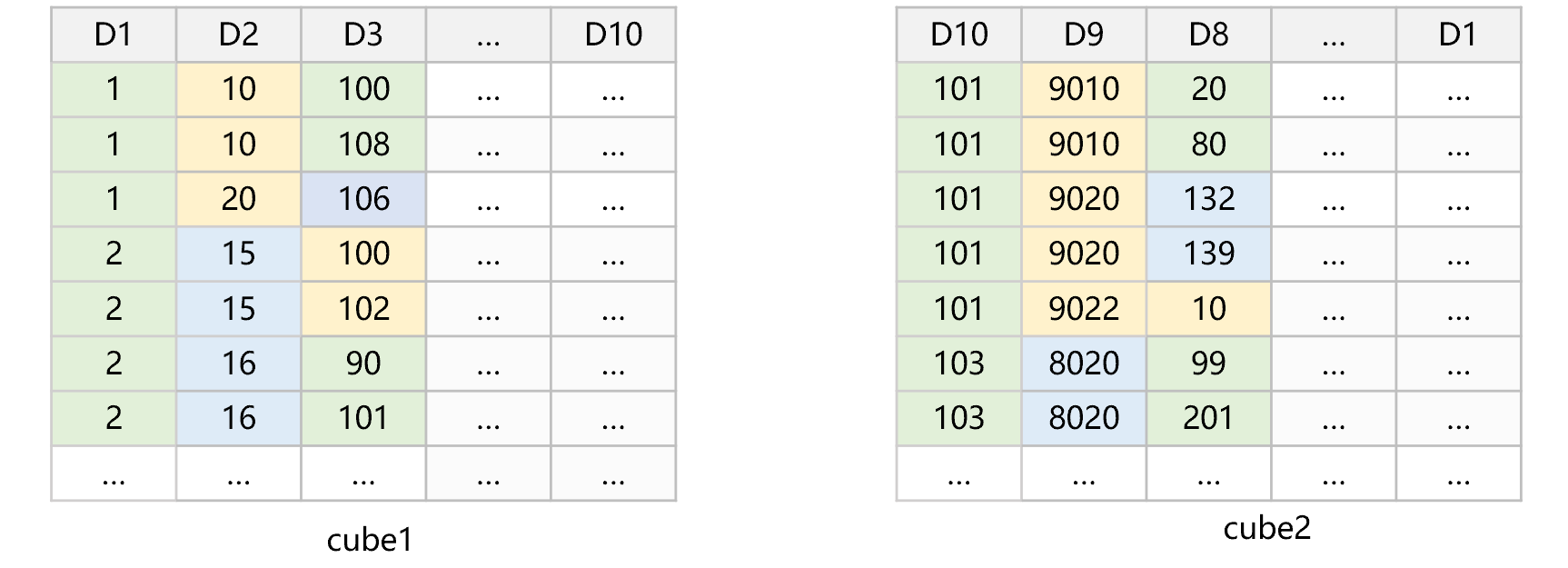
在计算时,使用一个维度的切片条件来筛选就可以了,其它维度上的条件仍然用遍历计算。多维分析时某一个维度上的切片,常常都能使涉及数据量减少数倍或数十倍,在其它维度上再利用切片条件的意义就不大了。有多个维度上都有切片条件时,SPL会选择切片后范围和总取值范围相比较小的维度,通常意味着过滤后的数据量更小。
SPL的cgroups 函数中实现了这个选择,如果发现有多个预汇总数据按不同维度排序的,且有切片条件时,则会选择最合适的那个。
| A | |
| 1 | =file("T.ctx").open() |
| 2 | =A1.cuboid(cube1,D1,D2,…,D10;sum(…)) |
| 3 | =A1.cuboid(cube2,D10,D9,…,D1;sum(…)) |
| 4 | =A1.cgroups(D2;sum(…);D6>=230 && D6<=910 && D8>=100 && D8<=10 &&…) |
cuboid 建立预汇总数据时分组维度的次序是有意义,针对不同的维度次序会建立出不同的预汇总数据。也可以人为用代码选择合适排序的数据集,以及存储更多种排序的数据集。
此外,SPL中还提供了很多高效运算机制不仅适用多维分析,还可以面向其他数据处理场景,如高性能存储、有序计算、并行计算等等,结合这些能力可以获得更高效的数据处理体验。
诚如前面所说,预汇总只能解决多维分析中一小部分相对简单固定的需求,其他大量常见的需求还需要使用诸如SPL这样的计算引擎实施高效硬遍历才能很好满足,在优秀的硬遍历能力基础上再结合SPL提供的部分预汇总与时间段预汇总功能就可以更好地满足多维分析在性能和灵活性方面的要求,同时将存储成本降到最低。
使用SPL应对多维分析场景覆盖范围广、查询性能高、使用成本低,这才是理想的技术方案。
SPL资料
欢迎对SPL有兴趣的加小助手(VX号:SPL-helper),进SPL技术交流群

- 点赞
- 收藏
- 关注作者
评论(0)