【第16天】SQL进阶-查询优化一定要学EXPALIN (SQL 小虚竹)

回城传送–》《32天SQL筑基》
零、前言
我的学习策略很简单,题海策略+ 费曼学习法。如果能把这些题都认认真真自己实现一遍,那意味着 SQL 已经筑基成功了。后面的进阶学习,可以继续跟着我,一起走向架构师之路。
今天的学习内容是:SQL进阶-查询优化一定要学EXPALIN
一、练习题目
| 题目链接 | 难度 |
|---|---|
| – | – |
二、SQL思路
SQL进阶-查询优化一定要学EXPALIN
一定要学会EXPALIN!
一定要学会EXPALIN!
一定要学会EXPALIN!
初始化数据
drop table if exists user_profile;
CREATE TABLE `user_profile` (
`id` int PRIMARY KEY ,
`device_id` int NOT NULL,
`gender` varchar(14) NOT NULL,
`age` int ,
`university` varchar(32) NOT NULL,
`gpa` float);
INSERT INTO user_profile VALUES(1,2234,'male',21,'北京大学',3.2);
INSERT INTO user_profile VALUES(2,2235,'male',null,'复旦大学',3.8);
INSERT INTO user_profile VALUES(3,2236,'female',20,'复旦大学',3.5);
INSERT INTO user_profile VALUES(4,2237,'female',23,'浙江大学',3.3);
INSERT INTO user_profile VALUES(5,2238,'male',25,'复旦大学',3.1);
INSERT INTO user_profile VALUES(6,2239,'male',25,'北京大学',3.6);
INSERT INTO user_profile VALUES(7,2240,'male',null,'清华大学',3.3);
INSERT INTO user_profile VALUES(8,2241,'female',null,'北京大学',3.7);
drop table if exists question_practice_detail;
CREATE TABLE `question_practice_detail` (
`id` int NOT NULL,
`device_id` int NOT NULL,
`question_id`int NOT NULL,
`result` varchar(32) NOT NULL,
`date` date NOT NULL
);
INSERT INTO question_practice_detail VALUES(1,2234,111,'wrong','2021-05-03');
INSERT INTO question_practice_detail VALUES(2,2234,112,'wrong','2021-05-09');
INSERT INTO question_practice_detail VALUES(3,2234,113,'wrong','2021-06-15');
INSERT INTO question_practice_detail VALUES(4,2235,111,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(5,2235,115,'right','2021-08-13');
INSERT INTO question_practice_detail VALUES(6,2235,116,'right','2021-08-14');
INSERT INTO question_practice_detail VALUES(7,2236,117,'wrong','2021-08-15');
INSERT INTO question_practice_detail VALUES(8,2236,112,'wrong','2021-05-09');
INSERT INTO question_practice_detail VALUES(9,2236,113,'wrong','2021-08-15');
INSERT INTO question_practice_detail VALUES(10,2236,111,'right','2021-08-13');
解法
EXPALIN是什么
根据表、列、索引和WHERE子句中的条件的详细信息,MySQL 查询优化器会考虑许多技术来有效地执行 SQL 查询中涉及的查找。
可以在不读取所有行的情况下对一个巨大的表执行查询,也可以在不比较每个行组合的情况下执行涉及多个表的连接。
查询优化器选择执行最有效查询的一组操作称为“EXPALIN”
EXPALIN的用法
EXPLAIN 可与 SELECT, DELETE, INSERT, 和 UPDATE语句一起使用。
初体验:
explain select id,device_id
from user_profile
where device_id=2240

输出列介绍
对EXPALIN 解释输出列简单介绍下:
| 列 | 名称 | 备注 |
|---|---|---|
| id | 查询中的一个序号id | – |
| select_type | 查询中的一个类型 | – |
| table | 表名 | 当前查询(连接查询、子查询)所在的数据表 |
| partitions | 匹配的分区 | 如果当前数据表是分区表,则表示查询结果匹配的分区 |
| type | 联接类型 | 这是重要的列,显示连接使用了何种类型。结果值从好到坏依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL 。一般来说,得保证查询至少达到range级别,最好能达到ref。 |
| possible_keys | 可供选择的索引 | 显示可能应用在这张表中的索引。如果为空,没有可能的索引。 |
| key | 实际选择的索引 | 如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引 |
| key_len | 选择的索引长度 | 使用的索引的长度。在不损失精确性的情况下,长度越短越好 |
| ref | 与索引比较的列 | 显示索引的哪一列被使用了 |
| rows | 估计要检查的行数 | MYSQL认为必须检查的用来返回请求数据的行数 |
| filtered | 按表条件过滤的行百分比 | – |
| Extra | 附加信息 | – |
重要的列特别说明
id
表示SELECT语句的序列号,在EXPLAIN分析的结果信息中,有多少个SELECT语句就有多少个序列号。如果当前行的结果数据中引用了其他行的结果数据,则该值为NULL。
select_type
表示当前SQL语句的查询类型,可以表示当前SQL语句是简单查询语句还是复杂查询语句。select_type常见的取值如下:
-
SIMPLE:当前SQL语句是简单查询,不包含任何连接查询和子查询。
-
PRIMARY:主查询或者包含子查询时最外层的查询语句。
-
UNION:当前SQL语句是连接查询时,表示连接查询的第二个SELECT语句或者第二个后面的SELECT语句。
-
DEPENDENT UNION:含义与UNION几乎相同,但是DEPENDENT UNION取决于外层的查询语句。
-
UNION RESULT:表示连接查询的结果信息。
-
SUBQUERY:表示子查询中的第一个查询语句。
-
DEPENDENT SUBQUERY:含义与SUBQUERY几乎相同,但是DEPENDENT SUBQUERY取决于外层的查询语句。
-
DERIVED:表示FROM子句中的子查询。
-
MATERIALIZED:表示实例化子查询。
-
UNCACHEABLE SUBQUERY:表示不缓存子查询的结果数据,重新计算外部查询的每一行数据。
-
UNCACHEABLE UNION:表示不缓存连接查询的结果数据,每次执行连接查询时都会重新计算数据结果。
type
按从最佳到最差的顺序排列
- system:该表只有一行(系统表)。const这是连接类型 的一个特例。
- const:该表最多有一个匹配行,在查询开始时读取。因为只有一行,所以这一行中列的值可以被优化器的其余部分视为常量。
主键查询:
explain select id,device_id
from user_profile
where id =1

唯一索引查询:
创建唯一索引
CREATE UNIQUE INDEX uniq_idx_device_id ON user_profile(device_id);
explain select id,device_id
from user_profile
where device_id =2234

- eq_ref:如果查询语句中的连接条件或查询条件使用了主键或者非空唯一索引包含的全部字段,则type的取值为eq_ref,典型的场景为使用“=”操作符比较带索引的列。示例: 查询有错题的用户device_id
创建唯一索引
CREATE UNIQUE INDEX uniq_idx_device_id ON user_profile(device_id);
查看下这时候表的索引情况
SHOW INDEX FROM user_profile;

explain select up.device_id
from user_profile up
where up.device_id in (
select distinct device_id
from question_practice_detail qpd
where qpd.result = 'wrong'
)

- ref:当查询语句中的连接条件或者查询条件使用的索引不是主键和非空唯一索引,或者只是一个索引的一部分,则type的取值为ref。示例:
创建普通索引
CREATE INDEX idx_university ON user_profile(university);
查看下这时候表的索引情况
SHOW INDEX FROM user_profile;

explain select *
from user_profile
where university='北京大学'

使用组合索引的一部分示例:
alter table user_profile drop index idx_university ;
CREATE INDEX idx_university_age ON user_profile(university,age);
查看下这时候表的索引情况
SHOW INDEX FROM user_profile;

explain select *
from user_profile
where university='北京大学'

fulltext
当查询语句中的查询条件使用了全文索引时,type的取值为fulltext
查看下这时候表的索引情况
SHOW INDEX FROM user_profile;
创建全文索引
alter table user_profile drop index full_idx_university ;
CREATE FULLTEXT INDEX full_idx_university ON user_profile(university);

解析效果:
explain select *
from user_profile
where MATCH(university) AGAINST ('北京大学' )

ref_or_null
当查询的连接条件或查询条件索引列有null时,type类型值为ref_or_null
- 创建普通索引
alter table user_profile drop index full_idx_university;
CREATE INDEX idx_age ON user_profile(age);
- 查看下这时候表的索引情况
SHOW INDEX FROM user_profile;

解析效果:
explain select *
from user_profile
where age=20 or age is null;

index_merge
- 查询语句使用索引合并优化(条件有多个索引)时,此时,key列会显示使用到的所有索引,key_len显示使用到的索引的最长键长值。
- 查看下这时候表的索引情况
SHOW INDEX FROM user_profile;
解析效果:
explain select *
from user_profile
where age=20 or id=6;
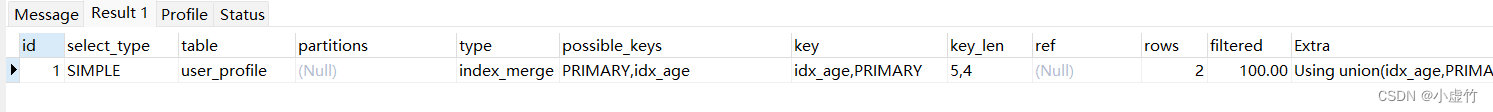
unique_subquery
- 查询语句的查询条件为IN的语句,并且IN语句中的查询字段为数据表的主键或者非空唯一索引字段时
- 查看下这时候表的索引情况
SHOW INDEX FROM user_profile;

解析效果:
explain select qpd.*
from question_practice_detail qpd
where qpd.device_id in (
select up.age
from user_profile up
)

由于Mysql会对select进行优化,基本无法出现type为unique_subquery的场景,如果你能重现,请一定要告诉虚竹哥
index_subquery
与unique_subquery类似,但是IN语句中的查询字段为数据表中的非唯一索引字段。一样无法重现,如果你能重现,请一定要告诉虚竹哥
range
- 当查询条件使用索引检索某个范围的数据,典型的场景为使用=、<>、>、>=、<、<=、IS [NOT] NULL、<=>、BETWEEN AND或者IN操作符时,类型为range。
- 查看下这时候表的索引情况
SHOW INDEX FROM user_profile;
解析效果:
explain select *
from user_profile
where age<22;

index
- 查询条件中的字段包含索引中的字段(含有非索引字段,就会是ALL了),此时只需要扫描索引树即可
- 查看下这时候表的索引情况
SHOW INDEX FROM user_profile;
解析效果:
explain select age,id
from user_profile

- 如果有涉及组合索引
alter table user_profile drop index idx_age ;
CREATE INDEX idx_university_age ON user_profile(university,age);
- 查看下这时候表的索引情况
SHOW INDEX FROM user_profile;

解析效果:
explain select age,id
from user_profile
explain select university,id
from user_profile


ALL
- 每次进行连接查询时,都会进行完整的表扫描。这种类型的查询性能最差
解析效果:
explain select *
from user_profile

总结
一定要学会EXPALIN!
一定要学会EXPALIN!
一定要学会EXPALIN!
type的类型从最好到最差:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL 。一般来说,得保证查询至少达到range级别,最好能达到ref。
参考
我是虚竹哥,我们明天见~

- 点赞
- 收藏
- 关注作者
评论(0)