通过SLOs获得调试影响

在事故期间,了解客户是否受到影响以及影响到什么程度是至关重要的。这是任何事件中最重要的拐点,可以用来指导适当和比例的反应。SLO(由Google SRE定义)是描述客户体验的一种有效方法,它连接了工程师和客户,并有助于理解事故期间客户的影响。
影响客户的事件需要与影响成比例的全面和立即响应,而内部、非客户影响的事件需要低得多的响应,甚至可能不是立即响应:
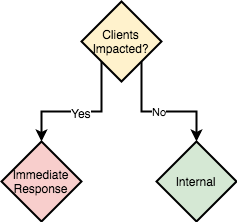
这个决定沿着两个逻辑维度存在:一个表示客户体验和他们对延迟的感知,以及他们对可用性的体验。第二个维度是内部层面,大多数工程师都在内部层面操作。内部/实现级别是服务、流程和机器的级别。这些是为了交付客户体验而精心安排的事情:
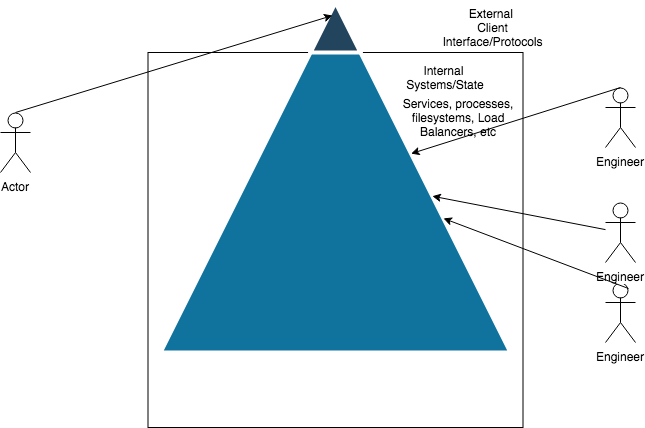
客户体验下面的一切都是实现细节。如何确保客户期望交付的价值被实际交付并不重要。有两个世界:客户和我们。你有没有觉得世界正在融化,一切都着火了,但却被所有人告知客户再幸福不过了?在事故中的困难是对这两个观点进行描述和推理,并理解任何给定的事故对客户的实际影响是什么。这两种观点会在事件发生时以无益的方式影响我们。作为一个专注于实现的操作员,很容易迷失在系统状态中,认为任何不健康的服务、主机或客栈延迟的增加都需要关注。
服务级对象是帮助运营商和客户机进行通信的中间路径。SLO可以用来通知最初的影响评估,并帮助我们了解客户是否受到影响。
为了说明这一点,假设我们有一个正在处理事件的反应作业队列和工作者池:
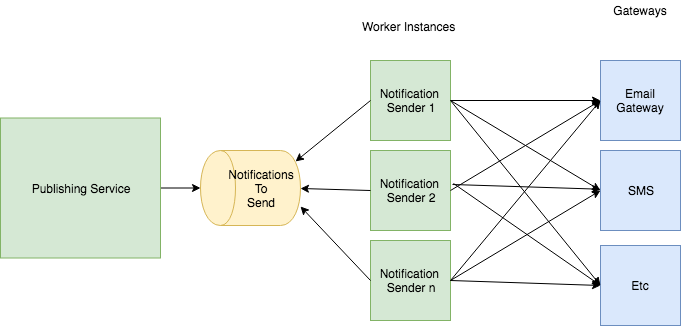
Notification service实例在其提供的服务周围有以下SLO:
80%的消息处理可用性(即成功处理的消息/总处理的消息>80%)-实例能够为我们的客户发送消息吗?
99%的消息应该在<1秒内处理(接收、处理、发送和发送邮件)–客户端等待通知请求注册到网关需要多长时间?
选择要围绕哪些信号构建目标和支持数据收集超出了本文的范围,也是非常重要的。此外,这些SLO可能需要在定义方面进行改进,本文的目标是说明如何使用SLO将客户告知非客户。虽然表征服务延迟的最准确方法是将合成事务生成为发布服务,但我们可以使用基于通知和队列的度量来创建客户端体验的代理。
用客户影响来表达影响
假设通知发送者机器不健康的警报开始触发。什么是合适的回应?挑起事端?拿我们的名誉冒险?吃掉它然后等到早上?假设这是一个警报,我们如何响应并确保我们的响应与问题成正比?

如何解决客户影响?
从工程的角度来看,我们可能会转移资源,立即找出机器故障的根源是什么,它是如何进入那种状态的。我们可能会挑起事端。另一种方法是使用SLO的度量标准,这些度量标准代理客户体验,并位于客户体验的顶端,以指导决策:

咨询我们的服务SLO显示,我们能够跟上预期的工作量(水平深度),我们正在做的工作质量符合预期(>80%的成功率),执行该工作所需的时间是可以接受的(p99<10秒)。
使用SLOs会通知拐点,并允许我们划分调试空间。了解客户机不受机器故障的影响,或者他们受影响的程度,可以让我们做出相应的响应。在这种情况下,处于非功能、非恶意状态的机器甚至不保证立即响应。
用SLOs引导
由于SLO对于描述客户端体验非常重要,因此用SLO定义警报会大大受益。高优先级警报应指示立即或即将发生的事件,根据它们对客户端的影响来定义。当警报触发时,应该明确当前客户的影响是什么。在所有团队都与他们的产品经理达成明确的SLO协议之前,返回SLO作为第一个调试步骤是一个有效的解决方案。SLO是了解客户体验的关键第一步,是连接客户和工程师的最高层次的可观察性。

- 点赞
- 收藏
- 关注作者
评论(0)