Docker下,五分钟极速体验机器学习

【摘要】 推荐理由:看标题是否很激动,花5分钟时间,准备好开发环境,运行一个经典demo,立即看到效果
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
- 看标题是否很激动,对机器学习很感兴趣,但是搭建环境和运行demo总是要花些精力和时间的,现在利用docker可以简化准备工作,一行命令即可直奔主题;
环境信息
-
操作系统:CentOS Linux release 7.6.1810
-
Docker:18.09.8
-
您没有看错,一个运行docker的Linux环境足矣!只要下载镜像的网速够快,几分钟之内即可体验机器学习。
极速搭建环境
- 执行下面这行命令,您就拥有了开始机器学习的开发环境:Annaconda3,并且jupyter notebook已经ready:
docker run --rm -p 8888:8888 bolingcavalry/anaconda3-jupyter:0.0.1
- 执行上述命令后,控制台输出如下:
(base) [root@centos7 ~]# docker run --rm -p 8888:8888 bolingcavalry/anaconda3-jupyter:0.0.1
Starting jupyter
[I 06:30:17.712 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
[I 06:30:18.460 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.7/site-packages/jupyterlab
[I 06:30:18.460 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 06:30:18.461 NotebookApp] Serving notebooks from local directory: /opt/notebooks
[I 06:30:18.461 NotebookApp] The Jupyter Notebook is running at:
[I 06:30:18.461 NotebookApp] http://(a61298ac6493 or 127.0.0.1):8888/?token=708d365fce9d9a76f98b2ade7e9aefcbc8401dbf5027ffa6
[I 06:30:18.462 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 06:30:18.465 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-6-open.html
Or copy and paste one of these URLs:
http://(a61298ac6493 or 127.0.0.1):8888/?token=708d365fce9d9a76f98b2ade7e9aefcbc8401dbf5027ffa6
[W 06:31:15.960 NotebookApp] Clearing invalid/expired login cookie username-192-168-121-137-8888
[W 06:31:15.961 NotebookApp] Couldn't authenticate WebSocket connection
[W 06:31:15.961 NotebookApp] Clearing invalid/expired login cookie username-192-168-121-137-8888
[W 06:31:15.962 NotebookApp] Clearing invalid/expired login cookie username-192-168-121-137-8888
[W 06:31:15.981 NotebookApp] 403 GET /api/kernels/5e3f93d5-4f80-4ed3-ad56-b04db61c8487/channels?session_id=33173ba03fee449da0839df0e10cfb6e (192.168.121.1) 22.41ms referer=None
-
注意上面的http://(a61298ac6493 or 127.0.0.1):8888/?token=708d365fce9d9a76f98b2ade7e9aefcbc8401dbf5027ffa6,其中的708d365fce9d9a76f98b2ade7e9aefcbc8401dbf5027ffa6是登录jupyter网页时要填写的token字段,后面会用到;
-
机器学习的开发环境已经OK了,够快吗?该运行经典入门实例了;
实战鸾尾花分类
- 运行docker的电脑IP地址是192.168.121.137,于是打开浏览器,输入地址:http://192.168.121.137:8888
- 出现jupyter登录页面,如下图,前面我们记下来了token字符串的值(708d365fce9d9a76f98b2ade7e9aefcbc8401dbf5027ffa6),在红框位置输进去,然后点击右侧的"Log in"按钮,即可登录成功;
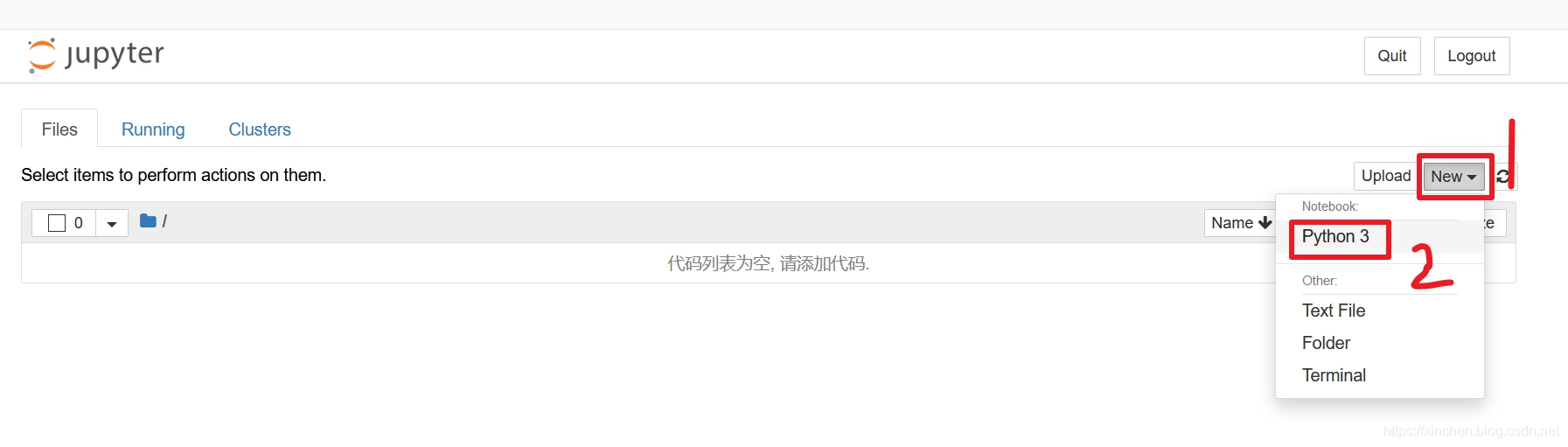
- 如下图,点击右侧的"New",在弹出的菜单中点击"Python 3":

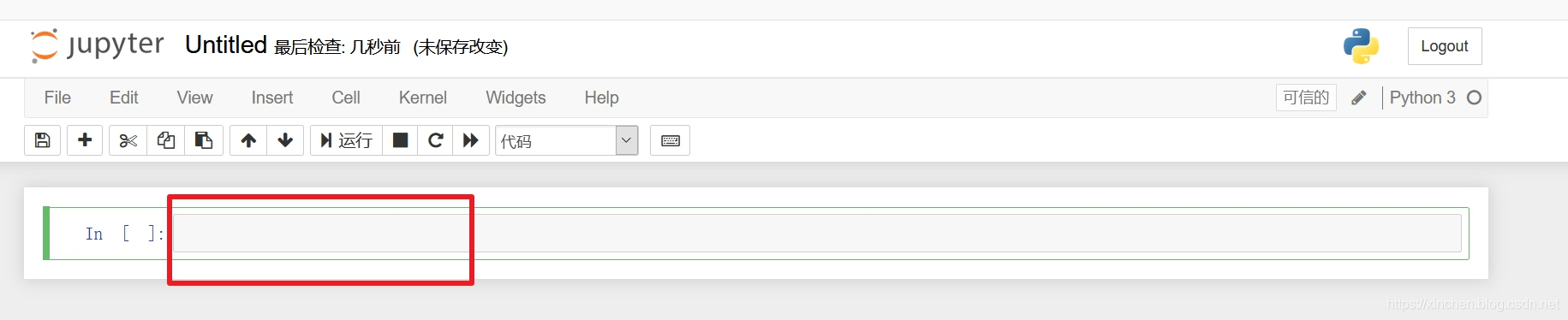
- 会出现新的页面,如下图,这就是我们输入代码和运行代码的地方:
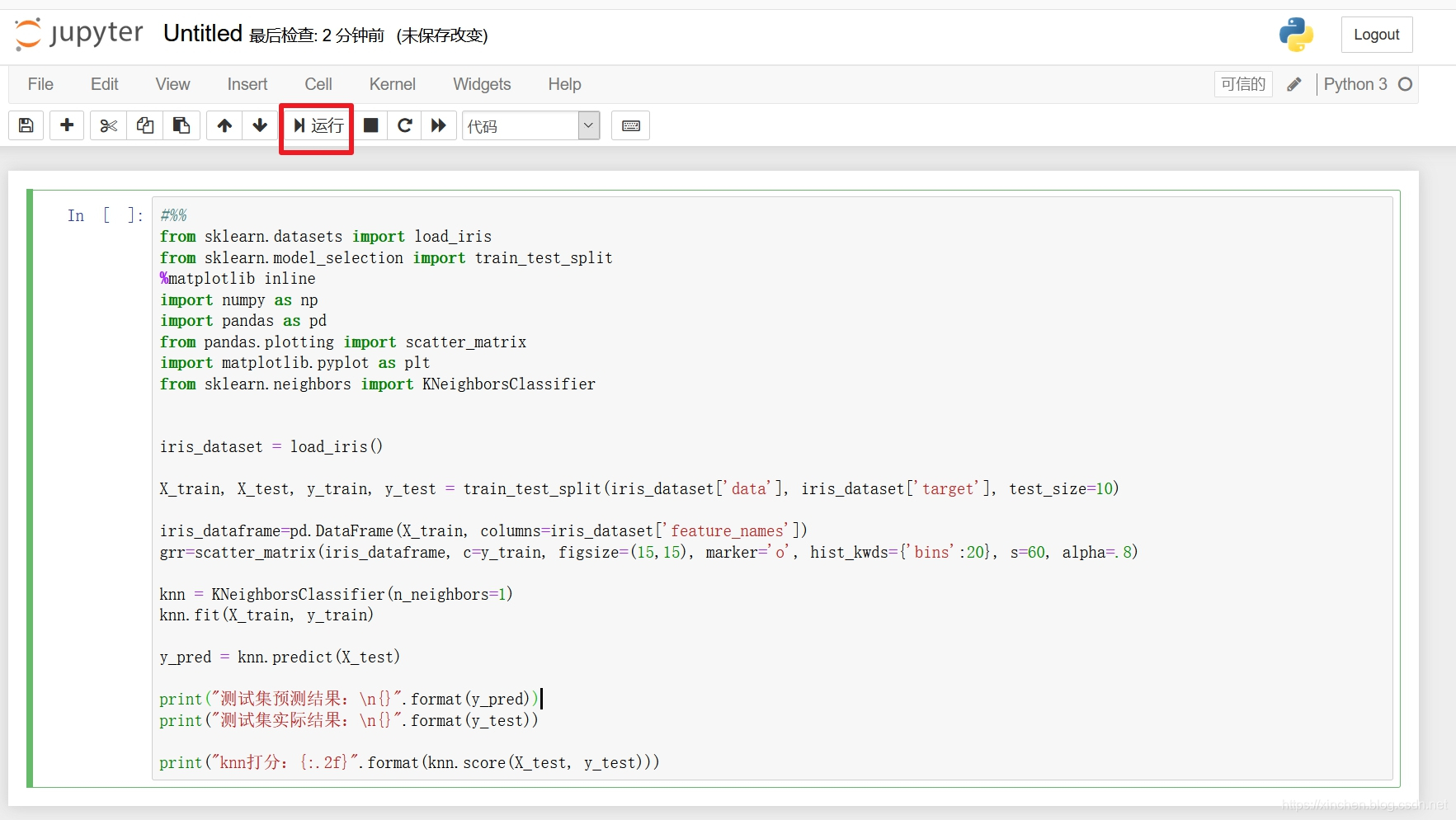
- 在上图红框中,输入以下代码,这段代码就是经典的鸾尾花分类:一共有150朵鸾尾花,每朵有自己的花萼长、花萼宽、花瓣长、花瓣宽这四个特征值,这150朵鸾尾花一共分为三类,我们取其中的140朵交给机器学习,学习完成后,我们将剩下10朵的特征给机器,让机器来分类,最后对比机器分类的结果和实际结果,看看误差有多大,代码中已经添加了详细的注释,就不再赘述了:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
#可以在浏览器上实时显示图像
%matplotlib inline
#取得鸾尾花数据集
iris_dataset = load_iris()
#将整个数据集分割成两部分:train用来训练,test用来测试,这里test_size等于10表示测试数据只有10条,其余的全部用作训练,
#注意,train_test_split会将iris_dataset的数据顺序打乱再分割
#X表示特征数据,每一行表示一朵鸾尾花的完整特征,该特征有四列:花萼长、花萼宽、花瓣长、花瓣宽
#y表示标签,例如y[0]=1,就表示X[0]的四个特征,对应的鸾尾花是第二类,总共有三类鸾尾花
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], test_size=10)
#在绘图的时候,指定数据列的名称来自数据集的'feature_names'
iris_dataframe=pd.DataFrame(X_train, columns=iris_dataset['feature_names'])
#绘图,散点矩阵图,每个小图和横轴是一个特征,纵轴是另个特征,
#例如花萼长做横轴、花萼宽做纵轴,可以看出不同的花萼长、花萼宽数据对应的鸾尾花类型分布情况
grr=scatter_matrix(iris_dataframe, c=y_train, figsize=(15,15), marker='o', hist_kwds={'bins':20}, s=60, alpha=.8)
#使用K最邻近算法来做训练
knn = KNeighborsClassifier(n_neighbors=1)
#用前面分割好的数据来做训练,X是特征,y是确定的鸾尾花的类型
knn.fit(X_train, y_train)
#训练完毕后,输入前面分割好的10组特征值,用K最邻近算法预测这10组特征值分别是哪10种鸾尾花
y_pred = knn.predict(X_test)
#把预测结果打印出来
print("测试集预测结果:\n{}".format(y_pred))
#y_test是早就准备好的,那10组特征对应的实际的类型
print("测试集实际结果:\n{}".format(y_test))
#将预测结果和实际结果做对比,可以得到预测的准确率
print("knn打分:{:.2f}".format(knn.score(X_test, y_test)))
-
写完了代码,点击下图红框中的按钮,即可运行:
-
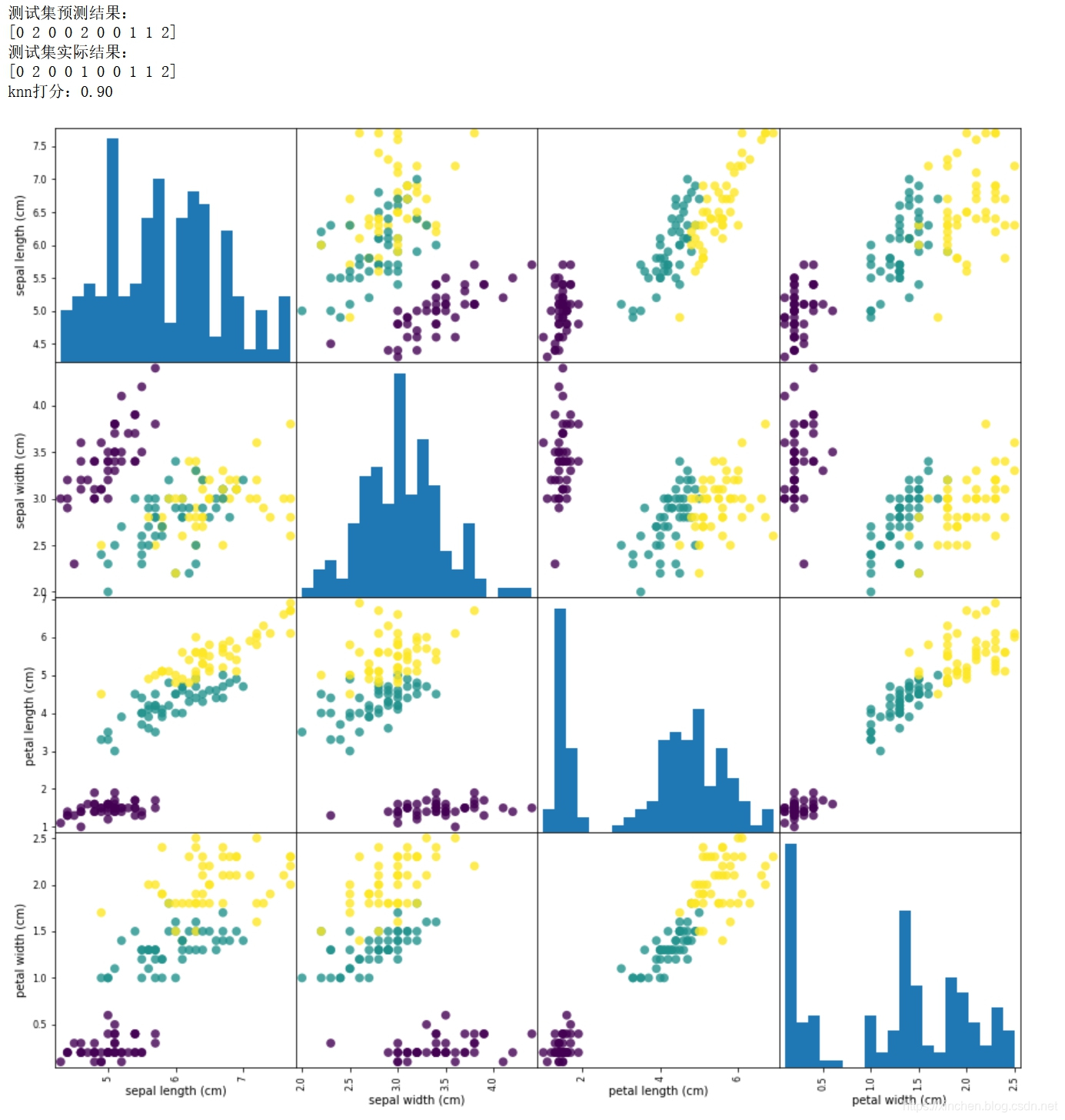
运行结果会立即显示出来,如下图:
-
您可以修改源码中train_test_split方法的test_size参数,例如从10改为50,这样学习样本就减少了,而测试数据增加了,理论上推测准确率会下降,请您自行修改和验证这个推论;
-
至此,您已经搭建好了机器学习的开发环境,并且运行了最经典的入门Demo。
关于Docker
- 一行命令就搭建好了开发环境,您也许会对该命令中的Docker镜像感兴趣,该镜像的关键是两个文件:制作镜像的Dockerfile和容器启动的docker-entrypoint.sh,您可以在可以从GitHub上下载这两个文件,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
- 这个git项目中有多个文件夹,本章的文件在jupyterdockerfiles文件夹下,如下图所示:
欢迎关注华为云博客:程序员欣宸

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)