MySQL数据库之数据查询

1.集函数查询
1.1 集合
在数学的概念中,指定的某些对象的全体称为一个集合。在MySQL中的集合是指查询结果中的全体记录。
1.2 函数
计算机中的函数是实现固定运算功能的一个程序段或子程序。计算机中函数调用格式:函数名(参数1,参数2,……)
1.3 集合函数查询
集合函数查询是指对查询的结果记录集针对某个或某几个列利用某个函数实施相应的运算,并输出运算结果,一般用于对某个或某几个列的值进行统计计算操作。
如:COUNT(student_id)、MAX)、MIN()、AVG()、SUM()等等
1.4 MySQL常用的集函数及功能
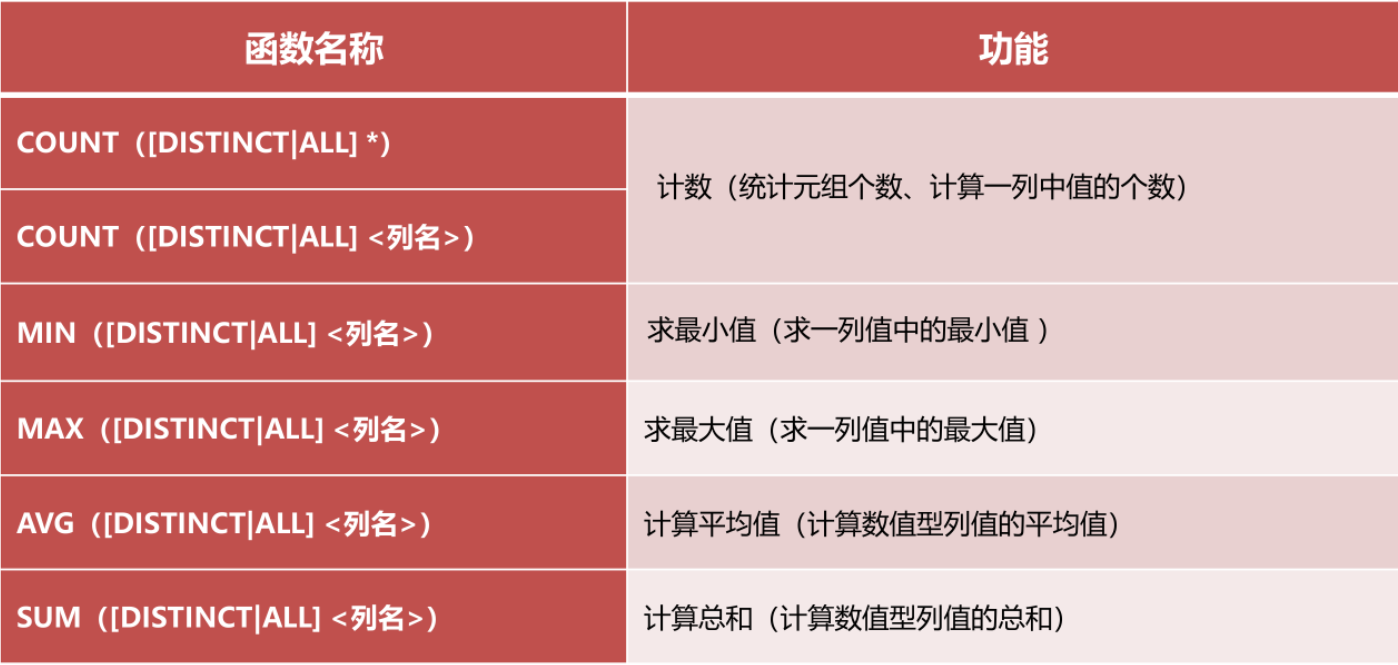
已知数据表department (department_id, department_name, department_dean,teacher_num, class_num, school_id)的信息如下:
| 系编号 | 系名称 | 系主任 | 教师人数 | 班级个数 | 学院编号 |
|---|---|---|---|---|---|
| A101 | 软件工程 | 李明东 | 20 | 8 | A |
| A102 | 人工智能 | 赵子强 | 16 | 4 | A |
| B201 | 信息安全 | 王月明 | 34 | 8 | B |
| B202 | 微电子科学 | 张小萍 | 23 | 8 | B |
| C301 | 生物信息 | 刘博文 | 23 | 4 | c |
| C302 | 生命工程 | 李旭日 | 22 | 4 | c |
| E501 | 应用数学 | 陈红萧 | 33 | 8 | E |
| E502 | 计算数学 | 谢东来 | 23 | 8 | E |
1.5 COUNT ()函数使用说明
-
COUNT(*)
- 返回数据表中的记录数
-
COUNT(column_name)
- 返回指定列的值的个数
-
COUNT(DISTINCT column_name)
- 返回指定列的不同值的个数
-
说明
- 在使用COUNT进行统计计数时,空值(NULL)不进行统计
1.6 举例
1.6.1 举例1
问题
利用department现有信息统计有多少个系。
查询指令
SELECT COUNT(*)AS系数FROM department
查询结果
以下是==SELECT COUNT(*)AS 教师人数 FROM departmen==t的执行结果集
虚表不能进行编辑、导出SQL操作

1.6.2 举例2
问题
在department中查找教师人数最多是多少。
查询指令
SELECT MAX(teacher_num)AS教师人数FROM department
查询结果
以下是SELECT MAX(Teacher_num)AS教师人数FROM department的执行结果集
虚表不能进行编辑、导出SQL操作

1.6.3 举例3
问题
在数据表class(class_id, class_name, student_num, monitor, major,department_id)中统计全体学生人数。
查询指令
SELECT SUM(student_num)AS全体学生数FROM class
查询结果
以下是SELECT SUM(student_num)AS全体学生数FROM class的执行结果集
虚表不能进行编辑、导出SQL操作

2.简单查询
所有列查询是指查询结果返回数据源的所有字段,而指定列查询是指只返回数据源查询的部分字段
2.1 所有列查询
所有列查询不会对数据源进行任何筛选和限制,直接返回数据源的所有行和所有列,所以我们可以用
*来代表所有行和所有列
2.1.1 语句格式
SELECT *[AII] ][DISTINCT]FROM <table_name >
2.1.2 功能
返回<table_name>表的所有记录的所有列。
2.1.3 举例1
已知数据表student,使用如下SQL查询语句可以返回student表的所有列。
查询指令
SELECT * FROM student
查询结果
在GaussDB(for MySQL)管理控制平台执行上述SQL查询命令,结果如下图所示。
2.2 指定列查询
2.2.1 语句格式
SELECT {[DISTINCT] / <column1>,<column2>...}FROM <table name >
2.2.2 功能
返回< table _name >表所有记录的< column1 >,< column2 >.……列。
2.2.3 举例2
问题
根据数据表student,查看全体学生学号、姓名、籍贯等信息。
查询指令
SELECT student_id, student_name, birthplace FROM student
结果
| student_id | student_name | birthplace |
|---|---|---|
| 190101 | 江膳珊 | 内蒙古 |
| 190102 | 刘东鹏 | 北京 |
| 190115 | 崔月月 | 黑龙江 |
| 190116 | 白洪涛 | 上海 |
2.3 指定行查询
2.3.1 定义
指在查询命令中添加了查询条件设置,查询时,只有数据集中满足条件的记录才会出现在查询结果集中,返回的记录将包含所有列。
2.3.2 语句格式
SELECT [All] |[DISTINCT] FROM <table name >WHERE <expression>
2.3.3 说明
1.WHERE:查询条件的引导关键字,查询条件必须以WHERE开头。
2.< expression >:查询条件表达式,一般由比较表达式或逻辑表达式组成。
2.3.4 举例3
问题
在数据表class(class_id,class_name, student_num, monitor, major, department_id)查看A101系各班级的信息。
| 班级编号 | 班级名称 | 班级人数 | 班长姓名 | 专业名称 | 系编号 |
|---|---|---|---|---|---|
| A1011901 | 1901 | 32 | 江珊珊 | 软件工程 | A101 |
| A1011902 | 1902 | 33 | 赵红蕾 | 软件工程 | A101 |
| A1011903 | 1903 | 32 | 刘西畅 | 软件工程 | A101 |
| A1011904 | 1904 | 37 | 李薇薇 | 软件工程 | A101 |
| A1022001 | 2001 | 36 | 王猛仔 | 信息安全 | A102 |
| A1022002 | 2002 | 35 | 许海洋 | 信息安全 | A102 |
| A1022003 | 2003 | 38 | 何盼女 | 信息安全 | A102 |
| A1022004 | 2004 | 32 | 韩璐惠 | 信息安全 | A102 |
查询指令
SELECT* FROM class WHERE department_id='A101'
查询结果
| Class_ld | class_name | student_num | Monitor | Major | Department_id |
|---|---|---|---|---|---|
| A1011901 | 1901 | 32 | 江珊珊 | 软件工程 | A101 |
| A1011902 | 1902 | 33 | 赵红笛 | 软件工程 | A101 |
| A1011903 | 1903 | 32 | 刘西畅 | 软件工程 | A101 |
| A1011904 | 1904 | 37 | 李薇菠 | 软件工程 | A101 |
2.4 指定行和列查询
2.4.1 定义
指在查询命令中添加了查询条件设置,查询时,只有数据集中满足条件的记录才会出现在查询结果集中,返回的记录只包含指定的列。
2.4.2 语句格式
SELECT {[ DISTINCT] | <column1>,<column2> ...}FROM <table_name> WHERE <expression>
2.4.3 说明
1.DISTINCT:重复记录只保留一条,可选项。
2.<column1>,<column2>>.…:指定查询结果中各记录返回的列名称。3.WHERE:查询条件的引导关键字,查询条件必须以WHERE开头。
4.<expression>:查询条件条件表达式,一般由比较表达式或逻辑表达式组成。
2.4.4 举例4
问题
在数据表class(Class_id, Class_name, Student_num, Monitor,Major,Department_id)查看A101系各班级的部分信息(班级名称,班级人数,系编号)。
| 班级编号 | 班级名称 | 班级人数 | 班长姓名 | 专业名称 | 系编号 |
|---|---|---|---|---|---|
| A1011901 | 1901 | 32 | 江珊珊 | 软件工程 | A101 |
| A1011902 | 1902 | 33 | 赵红蕾 | 软件工程 | A101 |
| A1011903 | 1903 | 32 | 刘西畅 | 软件工程 | A101 |
| A1011904 | 1904 | 37 | 李薇薇 | 软件工程 | A101 |
| A1022001 | 2001 | 36 | 王猛仔 | 信息安全 | A102 |
| A1022002 | 2002 | 35 | 许海洋 | 信息安全 | A102 |
| A1022003 | 2003 | 38 | 何盼女 | 信息安全 | A102 |
| A1022004 | 2004 | 32 | 韩璐惠 | 信息安全 | A102 |
查询指令
SELECT class_name, student_num,department_idFROM class WHERE department_id='A101'
查询结果
| Class_ld | class_name | student_num | Department_id |
|---|---|---|---|
| A1011901 | 1901 | 32 | A101 |
| A1011902 | 1902 | 33 | A101 |
| A1011903 | 1903 | 32 | A101 |
| A1011904 | 1904 | 37 | A101 |
3.多表查询
前面我们所学的查询语句中,查询源都只有一个,在实际1应用中,为了便于后期数据的维护,在进行数据库逻辑设计时,我们往往把不同主题的信息分别存放在不同的数据表中,在需要时从不同的数据表中提取出来。
3.1 两表查询
3.1.1 定义
指查询的数据源(记录源)不只一个数据表,而是两个数据表,查询结果集中的列也分别是来自这两个表的列或新增的计算列。
3.1.2 语句格式
SELECT{[AIl] [[DISTINCT] | <column1>,<column2>,
column n>}FROM <table_name 1>, <table_name 2>[WHERE<expression>]
3.1.3 说明
-
<table_name 1>,<table_name 2>:查询的两个数据源(两个数据表),表名称在命令中的排列不分先后。
-
当查询结果中返回的列在两个数据源中都存在且名称相同时,在命令中需要指明该列来自哪个数据表。引用形式为“数据表名称.列名称(class.Class_id)”。
-
为确保查询结果的正确性,查询的两个数据表必须能够建立关系。
3.1.4 举例1
问题
根据数据表student和class的信息,查看各班级的学生部分信息,并返回“班级名称”,“学号”,“姓名”,“性别”和“出生年月”。

student表
| 学号 | 姓名 | 性别 | 出生年月 | 籍贯 | 班级编号 |
|---|---|---|---|---|---|
| 190101 | 江珊珊 | 女 | 2000-01-09 | 内蒙古 | A1011901 |
| 190102 | 刘东鹏 | 男 | 2001-03-08 | 北京 | A1011901 |
| 190115 | 崔月月 | 女 | 2001-03-17 | 黑龙江 | A1011901 |
| 190116 | 白洪涛 | 男 | 2002-11-24 | 上海 | A1011901 |
| 190117 | 邓中萍 | 女 | 2001-04-09 | 辽宁 | A1011901 |
| 190118 | 周康乐 | 男 | 2001-10-11 | 上海 | A1011901 |
| 190121 | 张宏德 | 男 | 2001-05-21 | 辽宁 | A1011901 |
| 190132 | 赵迪娟 | 女 | 2001-02-04 | 北京 | A1011901 |
| 200413 | 杨水涛 | 男 | 2002-01-03 | 河北 | A1022004 |
| 200417 | 李晓薇 | 女 | 2002-04-10 | 上海 | A1022004 |
| 200401 | 罗笑旭 | 男 | 2002-12-23 | 四川 | A1022004 |
| 200407 | 张思奇 | 女 | 2002-09-19 | 吉林 | A1022004 |
| 200431 | 韩璐惠 | 女 | 2001-06-16 | 河南 | A1022004 |
class表
| 班级编号 | 班级名称 | 班级人数 | 班长姓名 | 专业名称 | 系编号 |
|---|---|---|---|---|---|
| A1011901 | 1901 | 32 | 江珊珊 | 软件工程 | A101 |
| A1011902 | 1902 | 33 | 赵红蕾 | 软件工程 | A101 |
| A1011903 | 1903 | 32 | 刘西畅 | 软件工程 | A101 |
| A1011904 | 1904 | 37 | 李薇薇 | 软件工程 | A101 |
| A1022001 | 2001 | 36 | 王猛仔 | 信息安全 | A102 |
| A1022002 | 2002 | 35 | 许海洋 | 信息安全 | A102 |
| A1022003 | 2003 | 38 | 何盼女 | 信息安全 | A102 |
| A1022004 | 2004 | 32 | 韩璐惠 | 信息安全 | A102 |
查询指令
SELECT class_name, student_id, student_name, gender, birthFROM class, student
WHERE class.class_id=student.class_id
查询结果
| class_name | student_id | student_name | gender | birth | |
|---|---|---|---|---|---|
| 1 | 1901 | 190101 | 江珊珊 | 女 | 2000-01-09 00:00:00 |
| 2 | 1901 | 190102 | 刘东鹏 | 男 | 2001-03-08 O0:00:00 |
| 3 | 1901 | 190115 | 崔月月 | 女 | 2001-03-17 00:00:00 |
| 4 | 1901 | 190116 | 白洪涛 | 男 | 2002-11-24 00:00:00 |
| 5 | 1901 | 190117 | 邓中萍 | 女 | 2001-04-09 00:0o:00 |
3.2 多表列查询
3.2.2 定义
指查询的数据源(记录源)是多个数据表,查询结果集中的列也分别是来自这些表的列或新增的计算列。
3.2.3 语句格式
SELECT {[AII] [DISTINCT] |<column1>,<column2>,<column n> }FROM<table_name 1>,......,<table_name n>
[WHERE<expression>]
3.2.4 说明
-
<table_name 1>…<table_name n>:指定查询的多个数据源(数据表名称)。
-
多个数据表名称在命令中的排列次序不分先后。
-
多个数据表之间能够根据主、外键建立关系。
3.2.5 举例2
问题
根据数据库表student、表course和表score的信息,查看部分学生成绩(学号,姓名,课程名称和成绩)。
其中各数据表的字段(列)分布如下
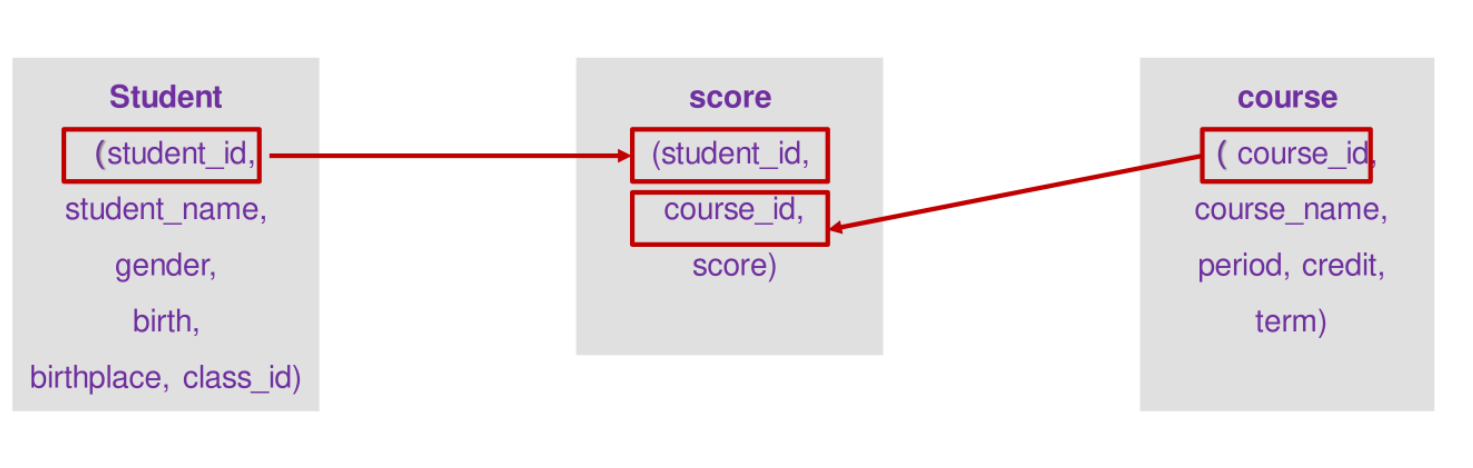
student表
| 姓名 | 性别 | 出生年月 | 籍贯 | 班级编号 | |
|---|---|---|---|---|---|
| 190101 | 江珊珊 | 女 | 2000-01-09 | 内蒙古 | A1011901 |
| 190102 | 刘东鹏 | 男 | 2001-03-08 | 北京 | A1011901 |
| 190115 | 崔月月 | 女 | 2001-03-17 | 黑龙江 | A1011901 |
| 190116 | 白洪涛 | 男 | 2002-11-24 | 上海 | A1011901 |
| 190117 | 邓中萍 | 女 | 2001-04-09 | 辽宁 | A1011901 |
| 190118 | 周康乐 | 男 | 2001-10-11 | 上海 | A1011901 |
| 190121 | 张宏德 | 男 | 学号 | 辽宁 | A1011901 |
| 190132 | 赵迪娟 | 女 | 2001-02-04 | 北京 | A1011901 |
| 200413 | 杨水涛 | 男 | 2002-01-03 | 河北 | A1022004 |
| 200417 | 李晓薇 | 女 | 2002-04-10 | 上海 | A1022004 |
| 200401 | 罗笑旭 | 男 | 2002-12-23 | 四川 | A1022004 |
| 200407 | 张思奇 | 女 | 2002-09-19 | 吉林 | A1022004 |
| 200431 | 韩璐惠 | 女 | 2001-06-16 | 河南 | A1022004 |
class表
| 课程编号 | 课程名称 | 学时 | 学分 | 学期 |
|---|---|---|---|---|
| 01-01 | 数据结构 | 54 | 2 | 2 |
| 01-02 | 软件工程 | 72 | 3 | 4 |
| 01-03 | 数据库原理 | 72 | 3 | 3 |
| 01-04 | 程序设计 | 54 | 2 | 1 |
| 02-01 | 离散数学 | 54 | 2 | 2 |
| 02-02 | 概率统计 | 54 | 2 | 1 |
| 02-03 | 高等数学 | 72 | 3 | 1 |
score表
| 学号 | 课程编号 | 成绩 |
|---|---|---|
| 190115 | 01-01 | 97 |
| 190115 | 01-02 | 89 |
| 190115 | 01-03 | 9o |
| 190115 | 01-04 | 91 |
| 190132 | 01-01 | 70 |
| 190132 | 01-02 | 66 |
| 190132 | 01-03 | 56 |
| 190132 | 01-04 | 60 |
| 190101 | 01-01 | 90 |
| 190101 | o1-02 | 76 |
| 190101 | 01-03 | 87 |
| 190101 | 01-04 | 94 |
查询指令
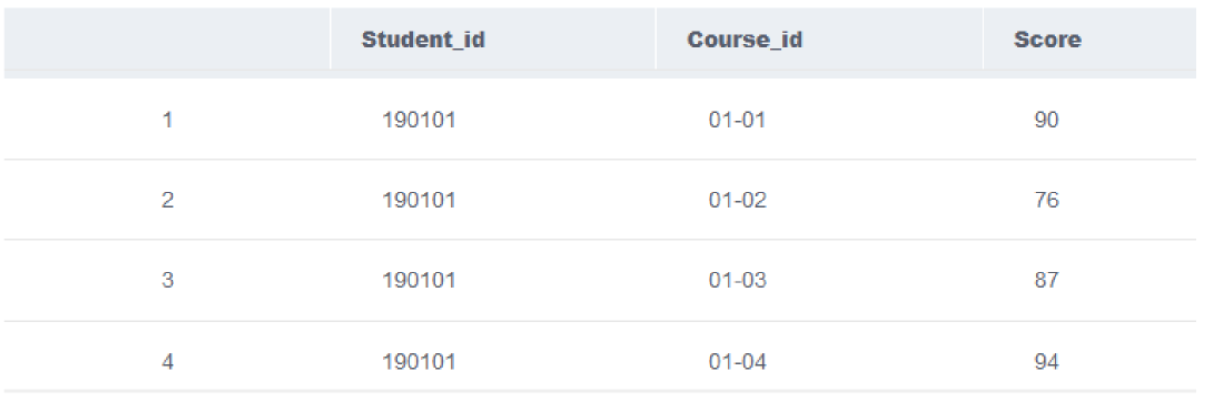
SELECT student.student_id, student_name, course_name, scoreFROM student, course,score
WHERE score.student_id=student.student_idAND score.course_id=course.course_id
查询结果
| student_id | student_name | course_name | ||
|---|---|---|---|---|
| 1 | 190101 | 江珊珊 | 数据结构 | 90 |
| 2 | 190101 | 江珊珊 | 软件工程 | 76 |
| 3 | 190101 | 江珊珊 | 数据库原理 | 87 |
| 4 | 190101 | 江珊珊 | 程序设计 | 94 |
| 5 | 190115 | 崔月月 | 数据结构 | 97 |
4.多表嵌套查询
嵌套查询指在查询中再包含查询,其中包含查询的查询称为主查询,被包含的查询称为子查询。
4.1 两表嵌套查询
4.1.1 定义
两表嵌套查询是指一个表的查询(子查询)结果作为数据源或查询条件应用到另一个查询(主查询)中。
4.1.2 语句格式
SELECT {[AII] [DISTINCT] |<column1>,<column2>,...... column n > }FROM<table_name 1>,<table_name 2>
[WHERE SELECT......]
4.1.3 说明
- WHERE SELECT…: WHERE所引导的查询为子查询,其查询结果为主查询的条件。
- 子查询的使用方法与主查询相似。
- 子查询的SELECT………语句在使用时用圆括号括起来,形如:
(SELECT… ) 。 - FROM之后也可以跟子查询。
4.1.4 举例1
问题
根据数据表class和表student的信息,查看部分班级学生部分信息(班级名称,学号,姓名,性别、出生年月)。
其中class和student的字段和数据分布如下
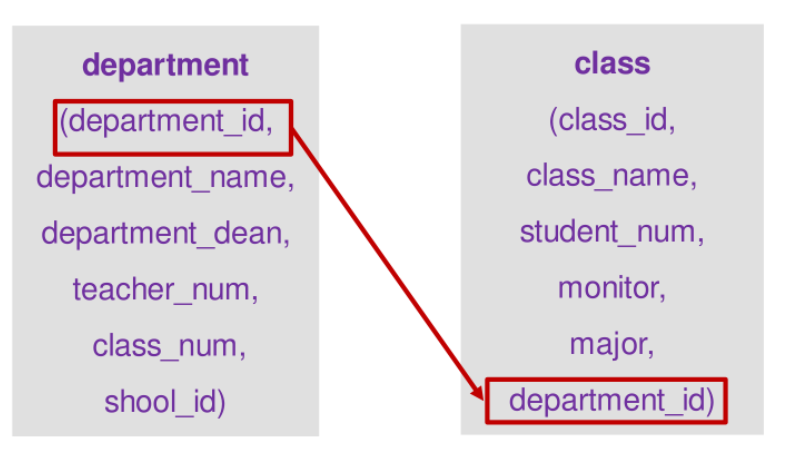
department表
| 系编号 | 系名称 | 系主任 | 教师人数 | 班级个数 | 学院编号 |
|---|---|---|---|---|---|
| A101 | 软件工程 | 李明东 | 20 | 8 | A |
| A102 | 人工智能 | 赵子强 | 16 | 4 | A |
| B201 | 信息安全 | 王月明 | 34 | 8 | B |
| B202 | 微电子科学 | 张小萍 | 23 | 8 | B |
| C301 | 生物信息 | 刘博文 | 23 | 4 | c |
| C302 | 生命工程 | 李旭日 | 22 | 4 | c |
| E501 | 应用数学 | 陈红萧 | 33 | 8 | E |
| E502 | 计算数学 | 谢东来 | 23 | 8 | E |
class表
| 班级编号 | 班级名称 | 班级人数 | 班长姓名 | 专业名称 | 系编号 |
|---|---|---|---|---|---|
| A1011901 | 1901 | 32 | 江珊珊 | 软件工程 | A101 |
| A1011902 | 1902 | 33 | 赵红蕾 | 软件工程 | A101 |
| A1011903 | 1903 | 32 | 刘西畅 | 软件工程 | A101 |
| A1011904 | 1904 | 37 | 李薇薇 | 软件工程 | A101 |
| A1022001 | 2001 | 36 | 王猛仔 | 信息安全 | A102 |
| A1022002 | 2002 | 35 | 许海洋 | 信息安全 | A102 |
| A1022003 | 2003 | 38 | 何盼女 | 信息安全 | A102 |
| A1022004 | 2004 | 32 | 韩璐惠 | 信息安全 | A102 |
查询指令
SELECT class_name, student_id, student_name, gender, birthFROM class, student WHERE class.class_id = student.class_id AND class.class_id lN ( SELECT DISTINCT class_id FROM student );
查询结果
| class_namo | student_id | student_namo | gender | birth | |
|---|---|---|---|---|---|
| 1 | 1901 | 190101 | 江珊珊 | 女 | 2o00-01-09 00:00:00 |
| 2 | 1901 | 190102 | 刘东鹏 | 男 | 2001-03-08 00:00:00 |
| 3 | 1901 | 190115 | 崔月月 | 女 | 2001-03-17 00:00:00 |
| 4 | 1901 | 190116 | 白洪涛 | 男 | 2002-11-24 00:.00.00 |
| 5 | 1901 | 190117 | 邓中萍 | 女 | 2001-04-09 00:00:00 |
4.2 多表嵌套查询
4.2.1 定义
指在“两表嵌套查询”的基础上增加更多的数据源,其他要求与“两表嵌套查询”相似。
4.2.2 语句格式
SELECT {[AlI] [[DISTINCT] | <column1>,<column2>,<column n> }FROM<table_name 1>,....... <table_name n>
[WHEERE SELECT.....]
4.2.3 说明
- <table_name 1>,…,<table_name n>:指定查询的多个数据源(数据表名称)。
- 子查询的SELECT…语句在使用时用圆括号括起来,形如:( SELECT…) 。
4.2.4 举例2
问题
根据数据库表teacher、表assignment和表course的信息,查看部分教师讲授的课程信息(教师姓名,课程名称,学分)。
其中teacher、assignment和course的数据分布如左图,字段分布如下图。
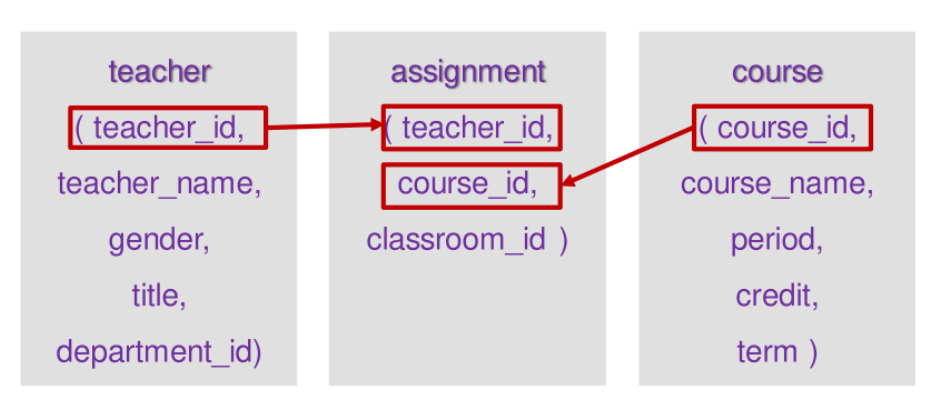
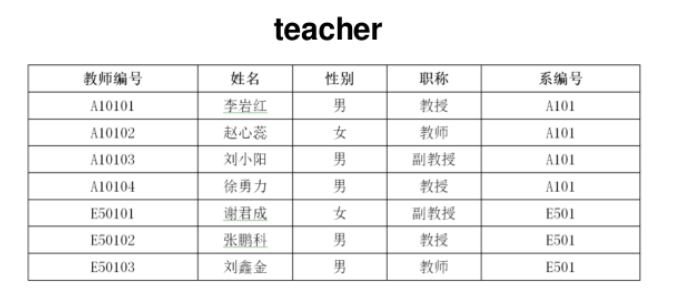
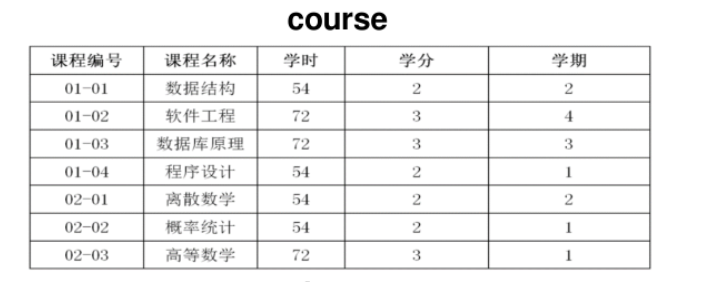
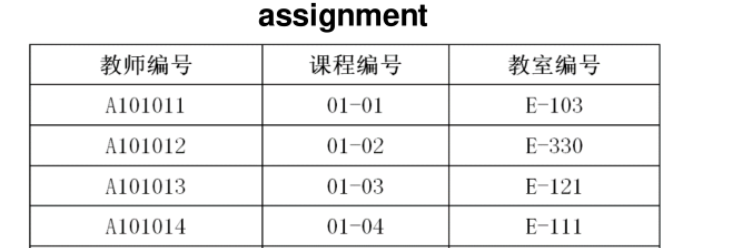
查询指令
SELECT TA.teacher_name, course_name, creditFROMcourse,
(SELECT teacher_name, course_idFROMteacher,assignment
WHERE teacher.teacher_id=assignment.teacher _id ) AS TAWHERE course.course_id=TA.course_id
查询结果
| teacher_name | course_name | credit | |
|---|---|---|---|
| 1 | 李岩红 | 数据结构 | 2 |
| 2 | 赵心蕊 | 软件工程 | 3 |
| 3 | 刘小阳 | 数据库原理 | 3 |
| 4 | 徐勇力 | 程序设计 | 2 |
| 5 | 谢君成 | 离散数学 | 2 |
5. 子查询
能够引导子查询的关键字有很多,我们主要学习IN,ALL,ANY.
5.1 带IN关键字的子查询
5.1.1适用情形
IN关键字主要适用于验证主查询条件值是否位于某个可枚举的数据集合中。
5.1.2 语句格式
SELECT {[AII] [[DISTINCT] | <column1>,<column2>.......,<column n> }FROM<table_name 1>,...... <table_name n>
[WHERE IN <expression>[HAVING <expression> [{<operator> <expression>}.....….]][ORDER BY <order by definition>]
5.1.2 说明
IN< expression >: expression在查询命令中需要用圆括号括起来。
5.1.3 举例1
问题
根据数据表course的信息,查看1、4学期的课程信息。
其中course的字段和数据分布如下
course ( course_id, course_name, period, credit, term ),对应的中文列名称为course (课程编号,课程名称,学时,学分,学期)
| 课程编号 | 课程名称 | 学时 | 学分 | 学期 |
|---|---|---|---|---|
| 01-01 | 数据结构 | 54 | 2 | 2 |
| 01-02 | 软件工程 | 72 | 3 | 4 |
| 01-03 | 数据库原理 | 72 | 3 | 3 |
| 01-04 | 程序设计 | 54 | 2 | 1 |
| 02-01 | 离散数学 | 54 | 2 | 2 |
| 02-02 | 概率统计 | 54 | 2 | 1 |
| 02-03 | 高等数学 | 72 | 3 | 1 |
查询指令
SELECT *FROM course WHERE term IN ('1';4')
等价于
SELECT * FROM course WHERE term='1' or term='4’
查询结果
| ourse_id | course_name | Period | redit | rerm | |
|---|---|---|---|---|---|
| 1 | 01-02 | 软件工程 | 72 | 3 | 4 |
| 2 | 01-04 | 程序设计 | 54 | 2 | 1 |
| 3 | 02-02 | 概率统计 | 54 | 2 | 1 |
| 4 | 02-03 | 高等数学 | 72 | 3 | 1 |
5.2 带ALL关键字的子查询
5.2.1 定义
将主查询的某个值与子查询返回的一组值进行比较,根据比较结果决定条件是否满足。必须所有比较满足才算满足。例如:x >ALL(…)
5.2.2 语句格式
SELECT {[AlI] ][DISTINCT] |<column1>,<column2>......., column n> }FROM<table_name 1>,......<table_name n>
[WHERE ALL <expression>
[HAVING <expression> [f<operator> <expression>}.... ..]][ORDER BY <order by definition>]
5.2.3 说明
ALL:比较运算包括=、<>、>=、<、<=等等。
5.2.4 举例2
问题
根据数据表score的信息,查看所有高于“01-03"课程最低分的课程成绩信息。
其中score的字段和数据分布score ( student_ id, course_id, score )
| 学号 | 课程编号 | 成绩 |
|---|---|---|
| 190115 | 01-01 | 97 |
| 190115 | 01-02 | 89 |
| 190115 | 01-03 | 90 |
| 190115 | 01-04 | 91 |
| 190132 | 01-01 | 70 |
| 190132 | 01-02 | 66 |
| 190132 | 01-03 | 56 |
| 190132 | 01-04 | 60 |
| 190101 | 01-01 | 9o |
| 190101 | 01-02 | 76 |
| 190101 | 01-03 | 87 |
| 190101 | 01-04 | 94 |
查询指令
SELECT*FROM score
WHERE score > ALL
(SELECT MIN(score) FROM scoreWHERE course_id='01-03')
查询结果
5.3带ANY关键字的子查询
5.3.1 定义
将主查询的某个值与子查询返回的一组值进行比较,根据比较结果决定条件是否满足,只要比较的任何一个满足就算满足。例如:x>ANY(…)
5.3.2 语句格式
SELECT {[AlI] ][DISTINCT] |<column1>,<column2>,.......<column n>}FROM <table_name 1>,...... <table_name n>
[WHERE ANY <expression>
[HAVING<expression> [{f<operator> <expression>}......]][ORDER BY <order by definition>]
5.3.3 说明
ANY:比较运算包括=、<>、>=、<、<=等等。
5.3.4 举例3
问题
根据数据表student的信息,查询比任意女同学年龄大的男同学信息。.
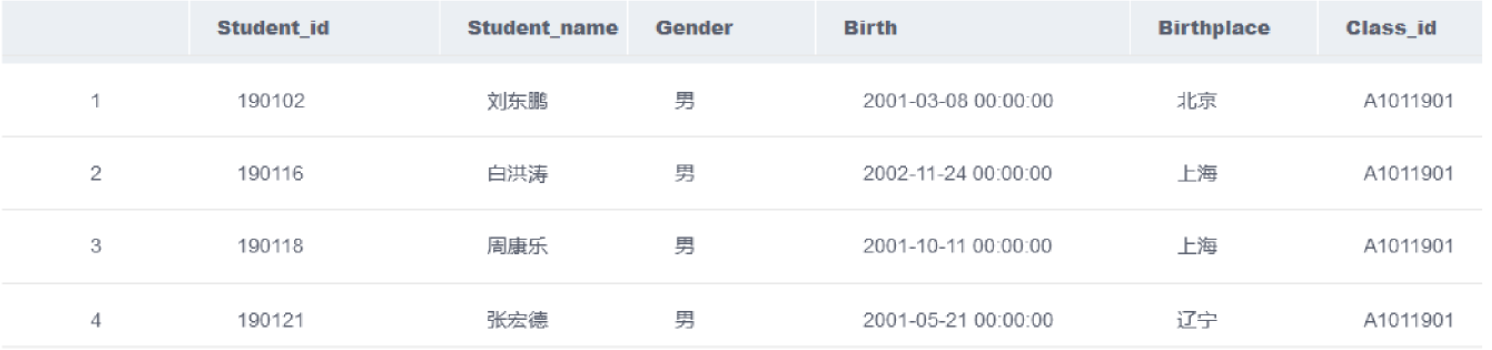
其中student的字段和数据分布如下
student ( student_id, student_name, gender, birth, birthplace,class_id )
| 学号 | 姓名 | 性别 | 出生年月 | 籍贯 | 班级编号 |
|---|---|---|---|---|---|
| 190101 | 江珊珊 | 女 | 2000-01-09 | 内蒙古 | A1011901 |
| 190102 | 刘东鹏 | 男 | 2001-03-08 | 北京 | A1011901 |
| 190115 | 崔月月 | 女 | 2001-03-17 | 黑龙江 | A1011901 |
| 190116 | 白洪涛 | 男 | 2002-11-24 | 上海 | A1011901 |
| 190117 | 邓中萍 | 女 | 2001-04-09 | 辽宁 | A1011901 |
| 190118 | 周康乐 | 男 | 2001-10-11 | 上海 | A1011901 |
| 190121 | 张宏德 | 男 | 2001-05-21 | 辽宁 | A1011901 |
| 190132 | 赵迪娟 | 女 | 2001-02-04 | 北京 | A1011901 |
| 200413 | 杨水涛 | 男 | 2002-01-03 | 河北 | A1022004 |
| 200417 | 李晓薇 | 女 | 2002-04-10 | 上海 | A1022004 |
| 200401 | 罗笑旭 | 男 | 2002-12-23 | 四川 | A1022004 |
| 200407 | 张思奇 | 女 | 2002-09-19 | 吉林 | A1022004 |
| 200431 | 韩璐惠 | 女 | 2001-06-16 | 河南 | A1022004 |
查询指令
SELECT*
FROM student
WHERE gender='男'AND birth < ANY(SELECT MIN(birth)FROM studentWHERE gender='女');
结果
6. 华为云RDS数据库使用
6.1 数据库购买流程
打开华为云数据库控制台(https://console.huaweicloud.com/rds)
首先在左上角选择自己需要购买的资源的所在区域,我这里以上海二为例
点击右上角购买数据库实例
可以根据自己的需要选择包年包月或者按需计费
不同的数据库引擎价格和功能也不一样,可以根据需要选取,我选择的为mysql
- 云数据库 RDS for MySQL
MySQL是目前最受欢迎的开源数据库之一,其性能卓越,搭配LAMP(Linux + Apache + MySQL + Perl/PHP/Python),成为WEB开发的高效解决方案。 云数据库 RDS for MySQL拥有即开即用、稳定可靠、安全运行、弹性伸缩、轻松管理、经济实用等特点。
1、架构成熟稳定,支持流行应用程序,适用于多领域多行业;支持各种WEB应用,成本低,中小企业首选。
2、管理控制台提供全面的监控信息,简单易用,灵活管理,可视又可控。
3、随时根据业务情况弹性伸缩所需资源,按需开支,量身订做。
- 云数据库 RDS for PostgreSQL
PostgreSQL是一个开源对象关系型数据库管理系统,并侧重于可扩展性和标准的符合性,被业界誉为“最先进的开源数据库”。云数据库 RDS for PostgreSQL面向企业复杂SQL处理的OLTP在线事务处理场景,支持NoSQL数据类型(JSON/XML/hstore),支持GIS地理信息处理,在可靠性、数据完整性方面有良好声誉,适用于互联网网站、位置应用系统、复杂数据对象处理等应用场景。
1、支持postgis插件,空间应用卓越,达到国际标准。降低“O”迁移复杂度100%。
2、适用场景丰富,费用低,随时可以根据业务情况弹性伸缩所需的资源,按需开支,量身订做。
- 云数据库 RDS for SQLServer
Microsoft SQL Server是老牌商用级数据库,成熟的企业级架构,轻松应对各种复杂环境。一站式部署、保障关键运维服务,大量降低人力成本。根据华为国际化安全标准,打造安全稳定的数据库运行环境。被广泛应用于政府、金融、医疗、教育和游戏等领域。云数据库 RDS for SQLServer具有即开即用、稳定可靠、安全运行、弹性伸缩、轻松管理和经济实用等特点。
拥有高可用架构、数据安全保障和故障秒级恢复功能,提供了灵活的备份方案。

在性能规格方面,根据实际开发需求选择对应规格
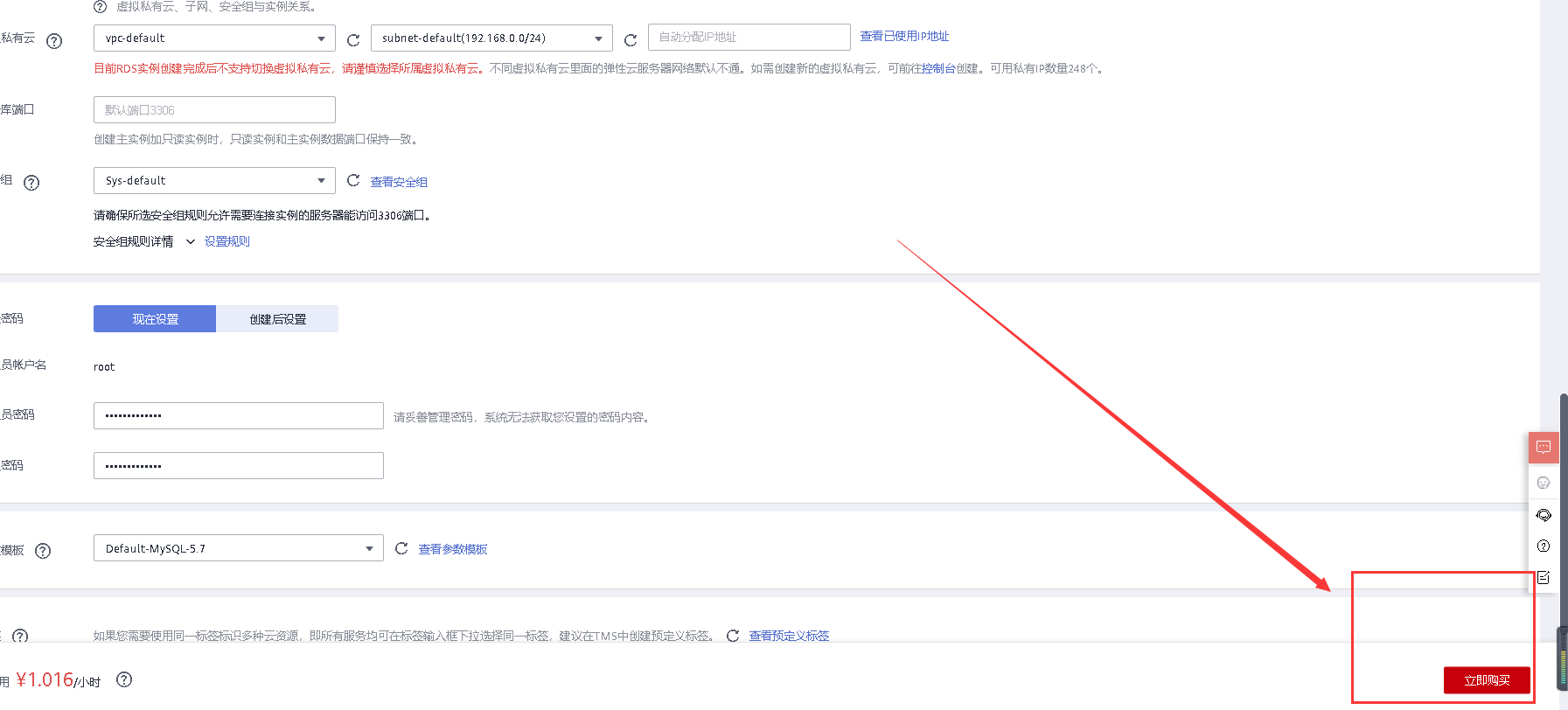
在配置完密码后选立即购买
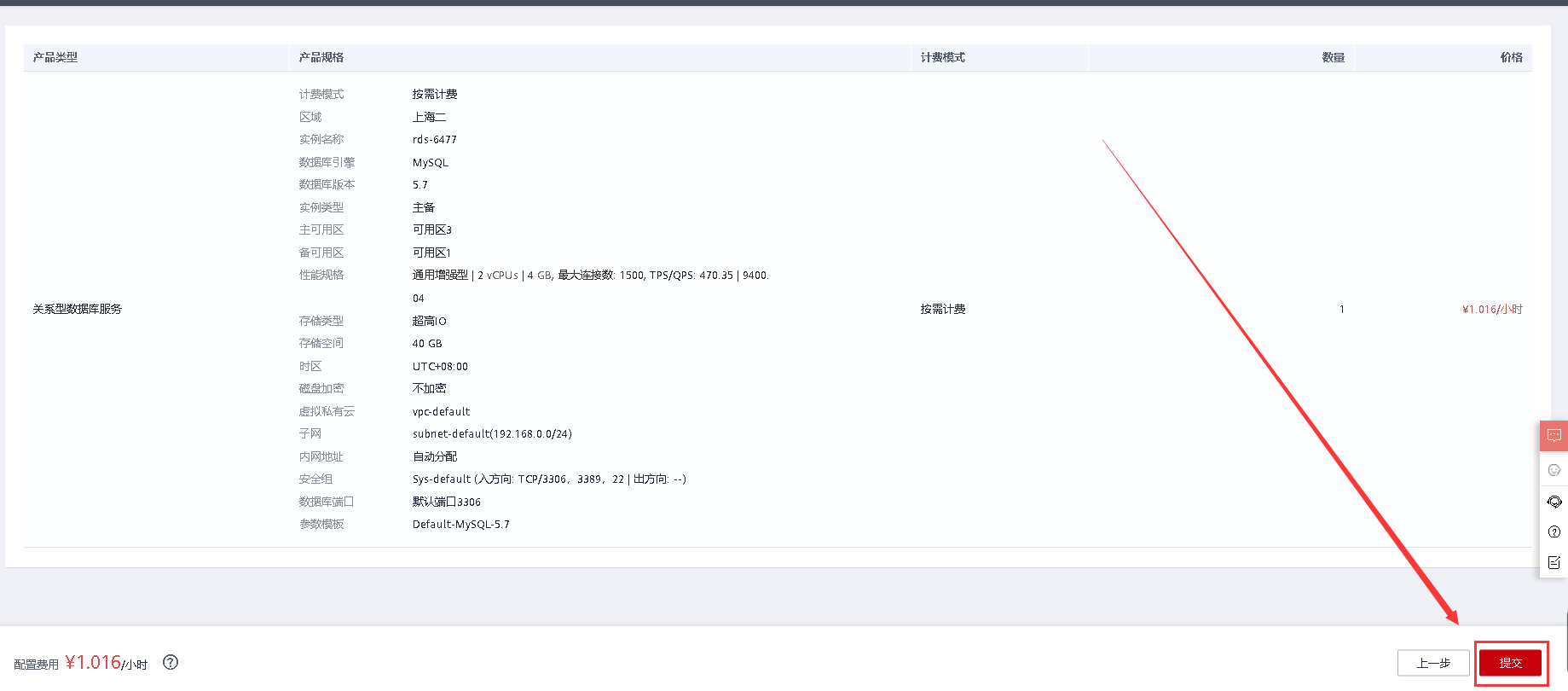
确认信息后点击提交
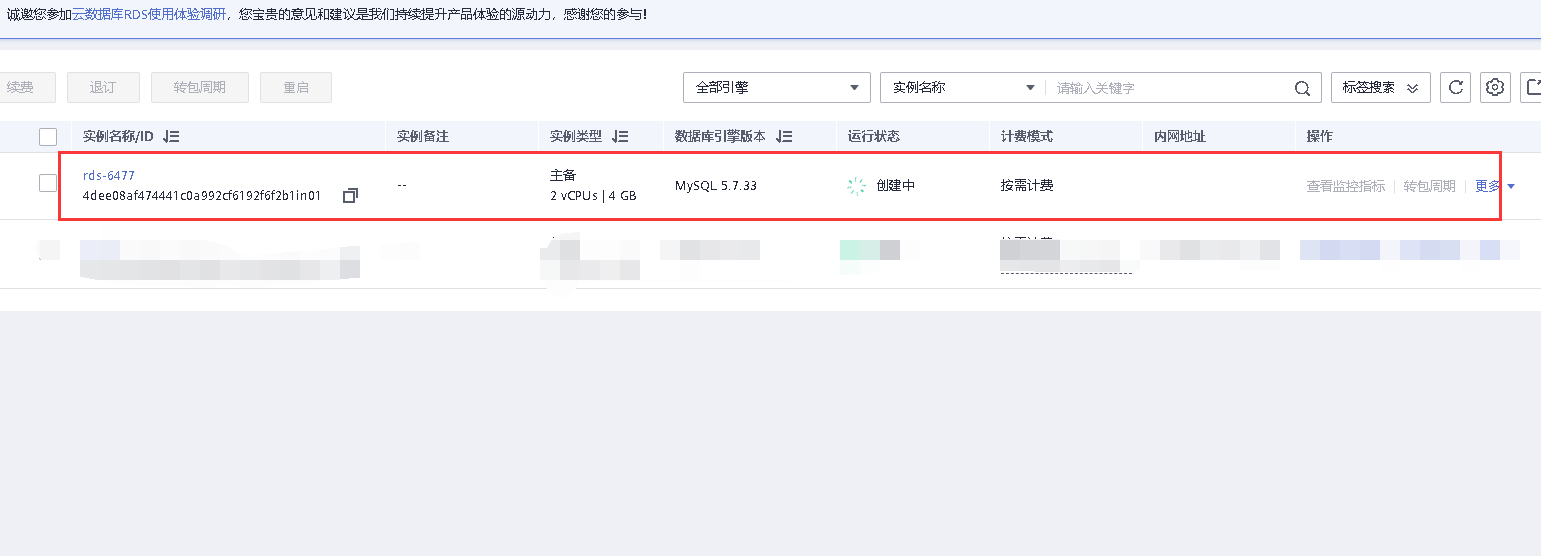
新的数据库实例在控制台可以看到,创建大概需要5-10分钟
6.2 MySQL环境配置
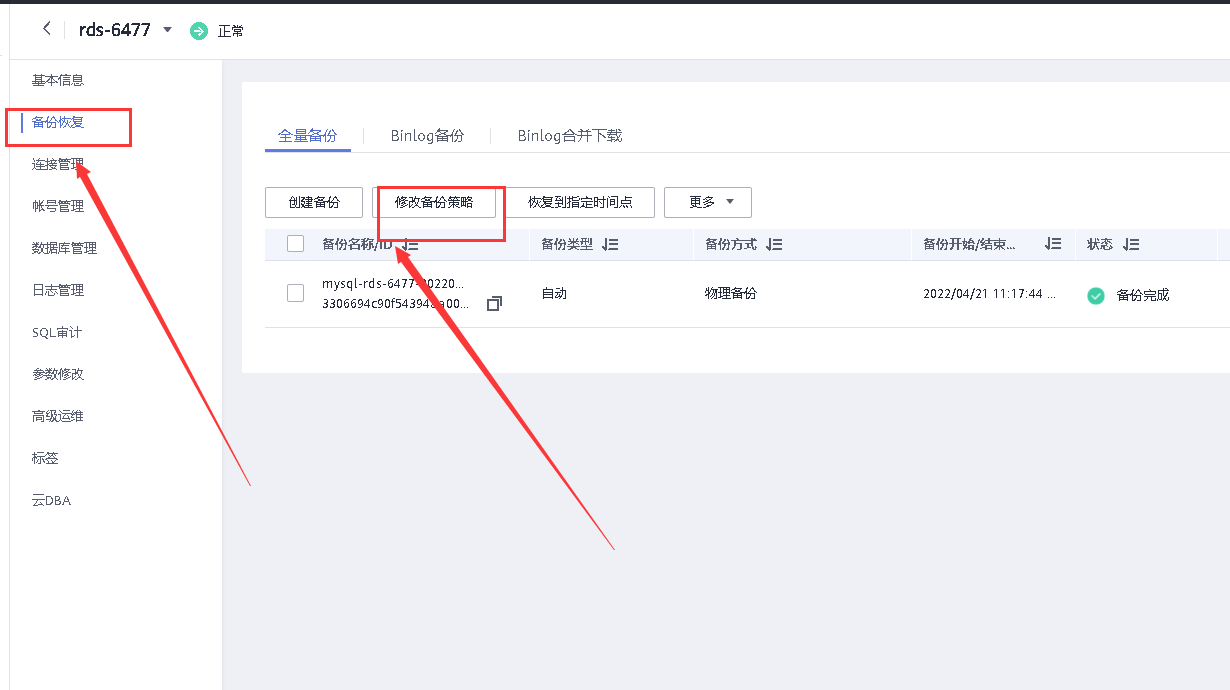
6.2.1 修改RDS MySQL自动备份策略
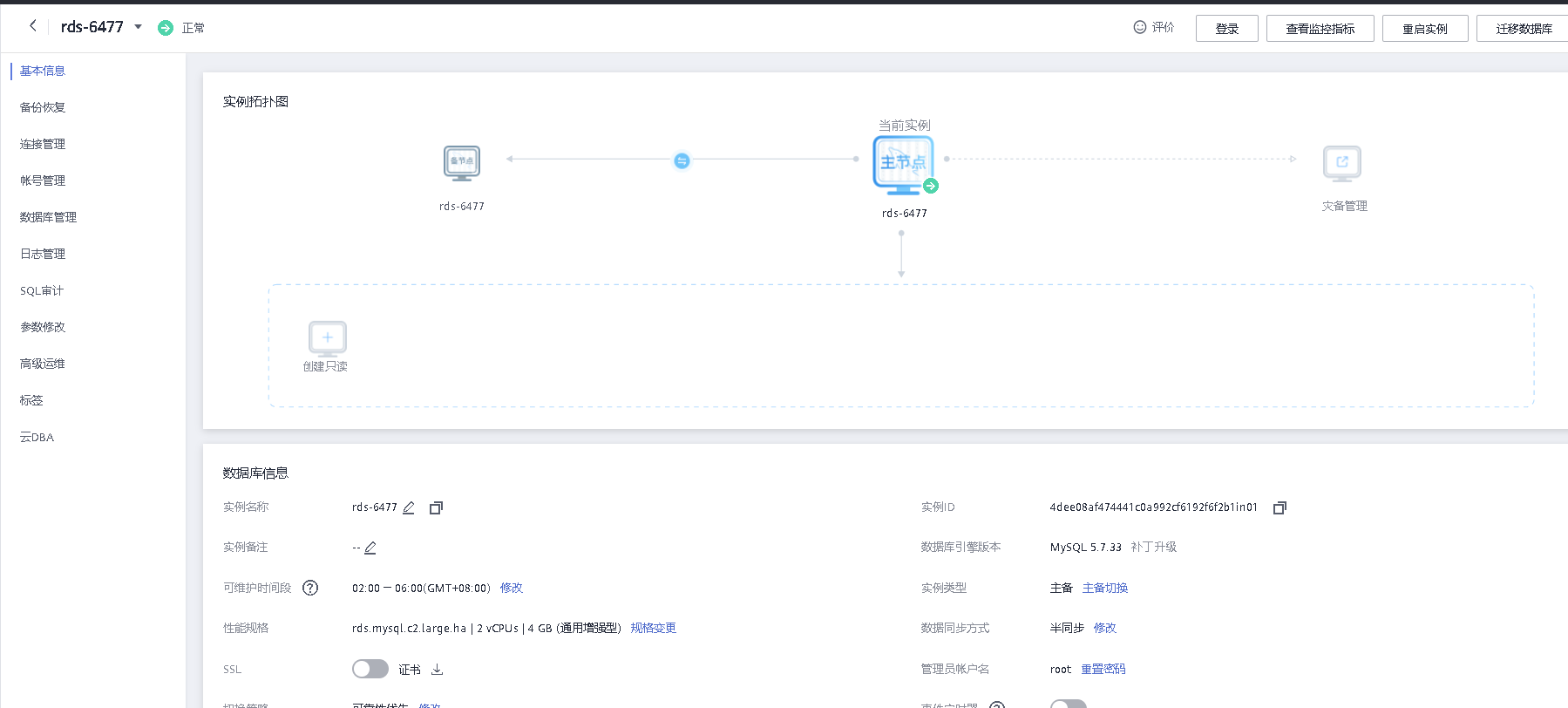
点击所创建数据库实例名称,进入数据库详情,可查看数据详情。
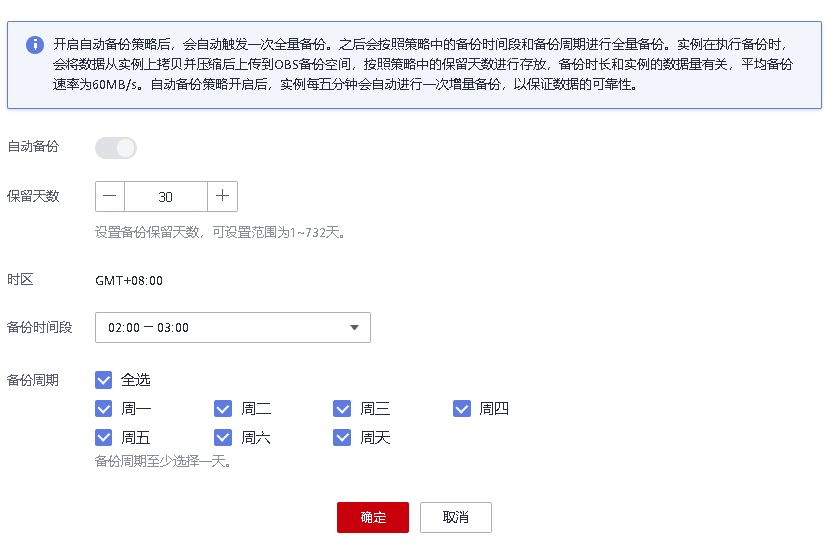
可以将备份更改为我们需要的时间(默认为7天)
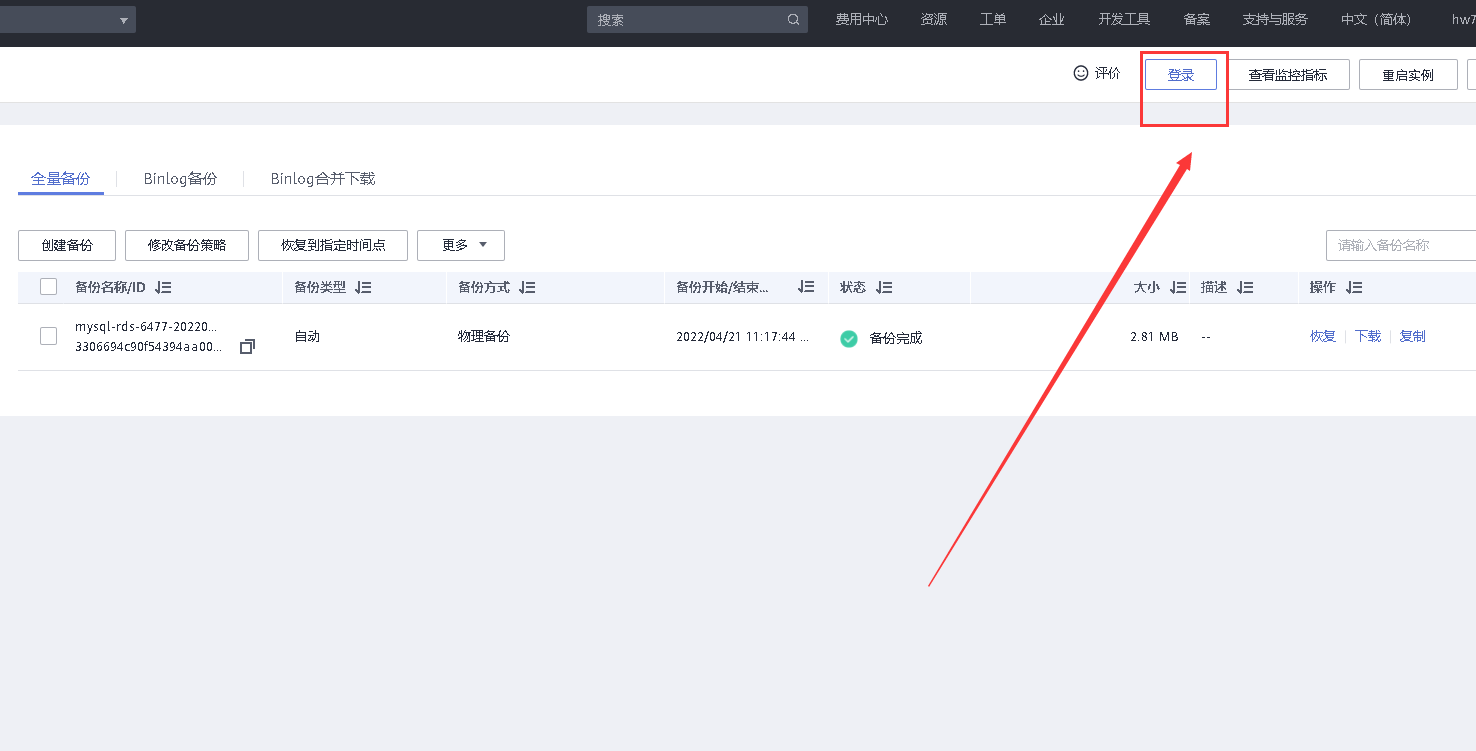
6.2.2 通过数据管理服务DAS连接MySQL实例
点击右上角登录
输入我们的数据库密码,在测试连接成功后进入服务
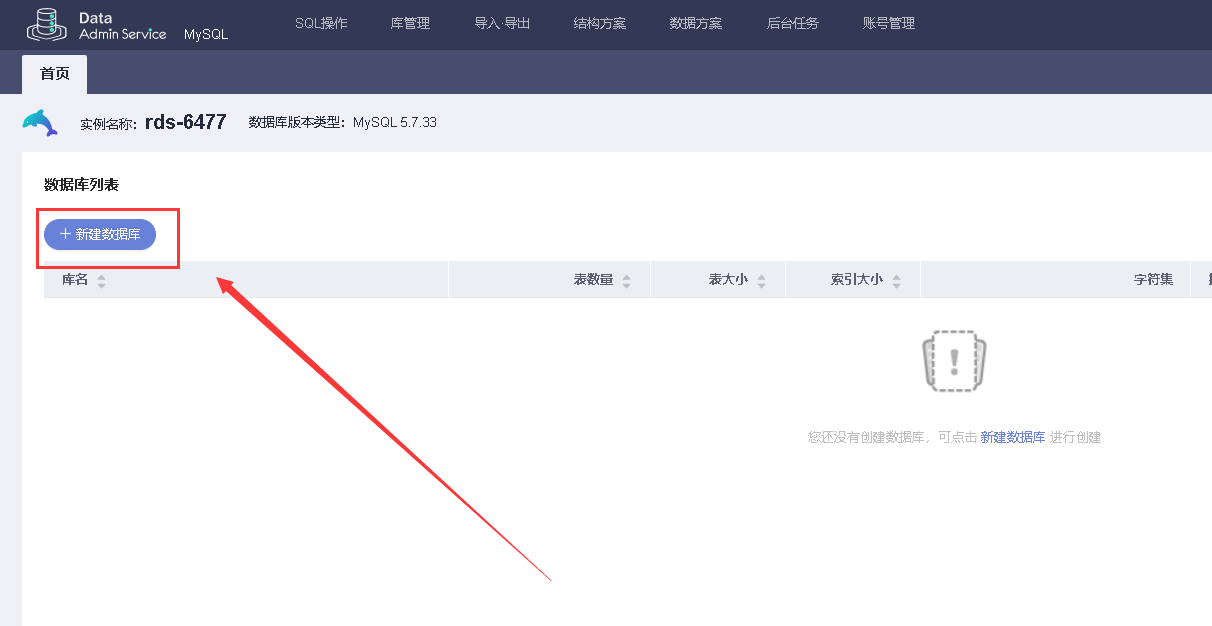
点击新建数据库
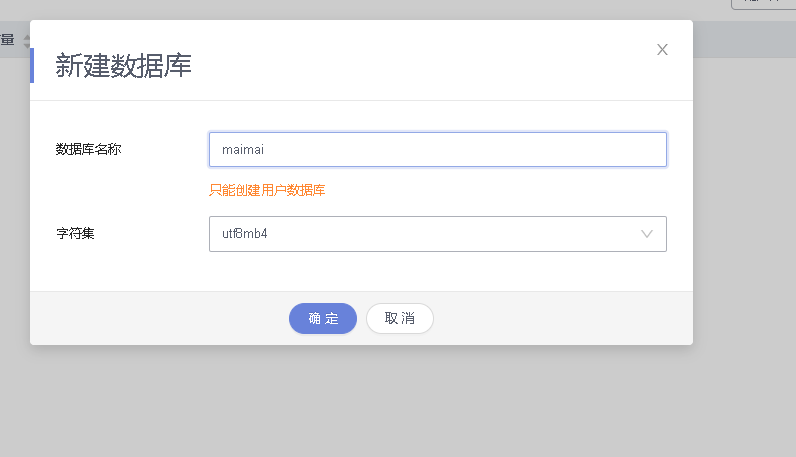
创建名为maimai的数据库
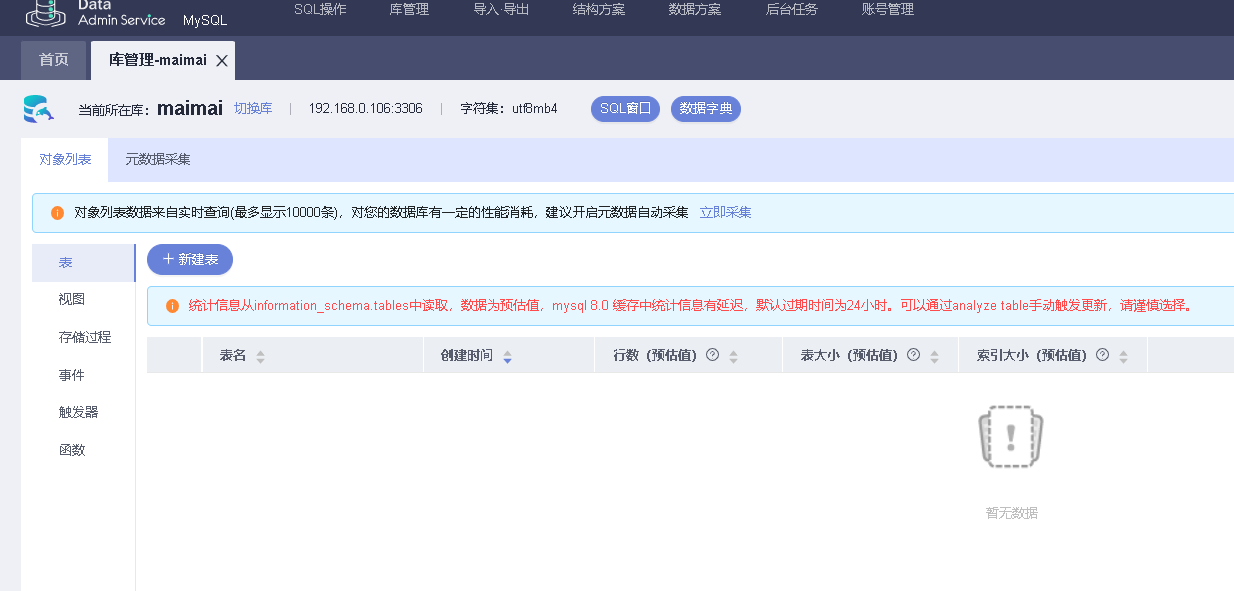
可以通过DAS数据库管理平台对数据库进行可视化操作
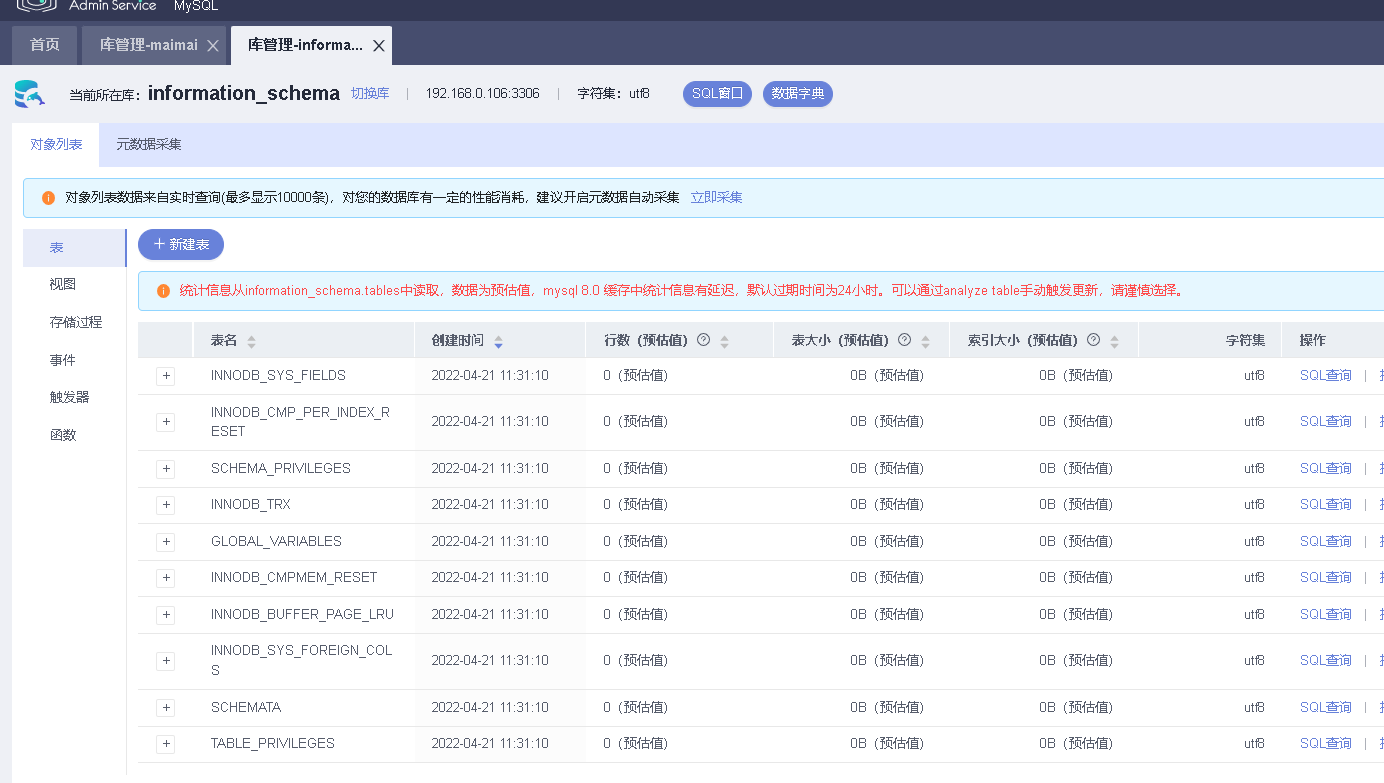
6.2.3 通过内网访问MySQL实例
云主机的VPC和安全组需要与RDS实例保持一致才可以成功访问,由于和公网访问mysql方法大致类似,主要介绍在公网访问mysql
6.2.4 通过公网连接 MySQL实例
通过公网连接MySQL,还需要提前购买弹性公网IP并绑定数据库
6.2.4.1 弹性公网IP购买
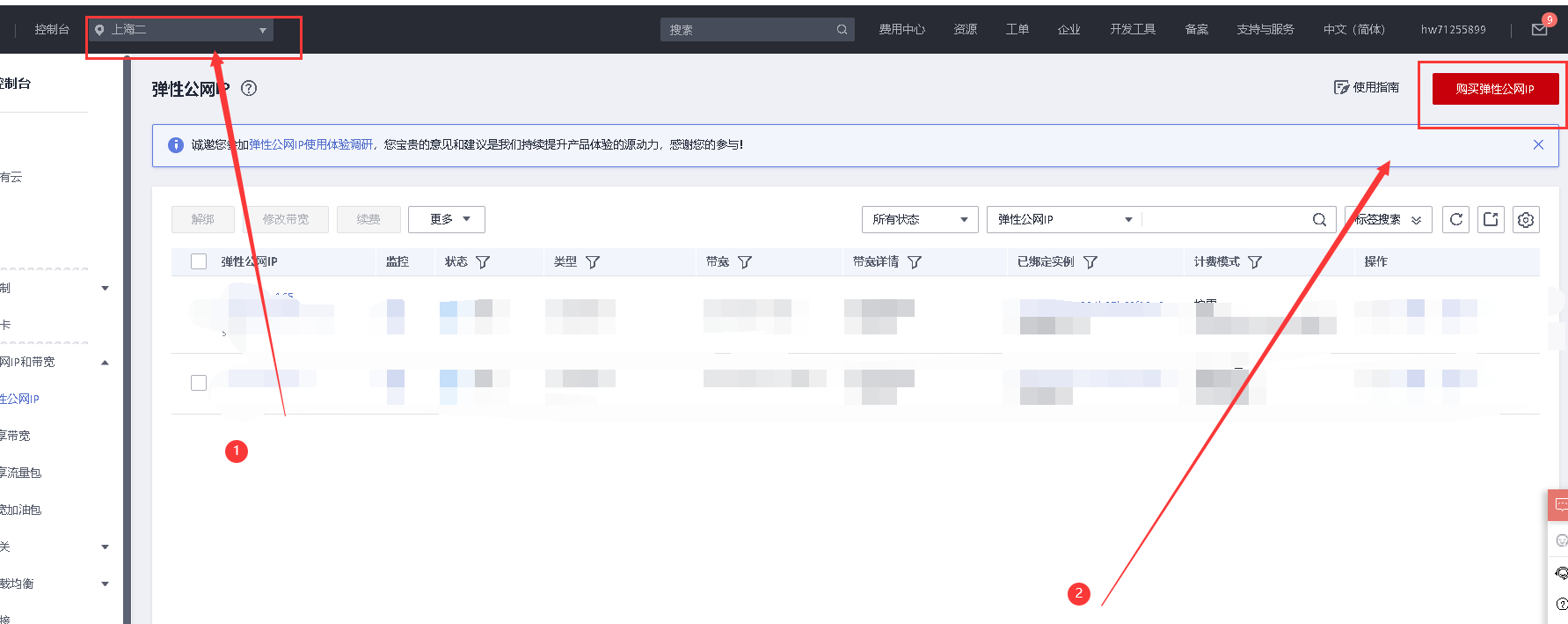
进入弹性公网控制台https://console.huaweicloud.com/vpc
选择和数据库所在区域保持一致,点击购买
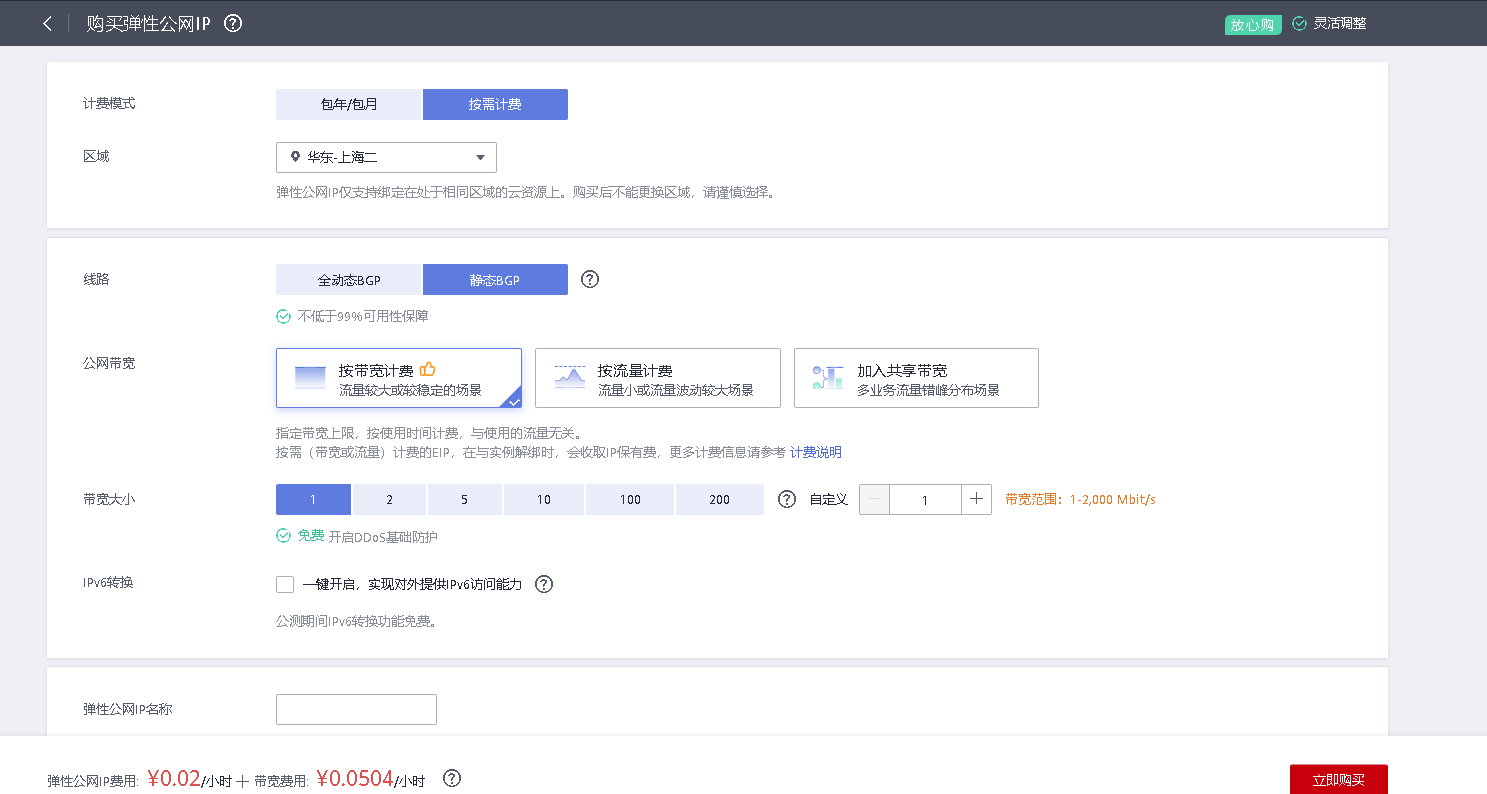
配置完参数后点击立即购买
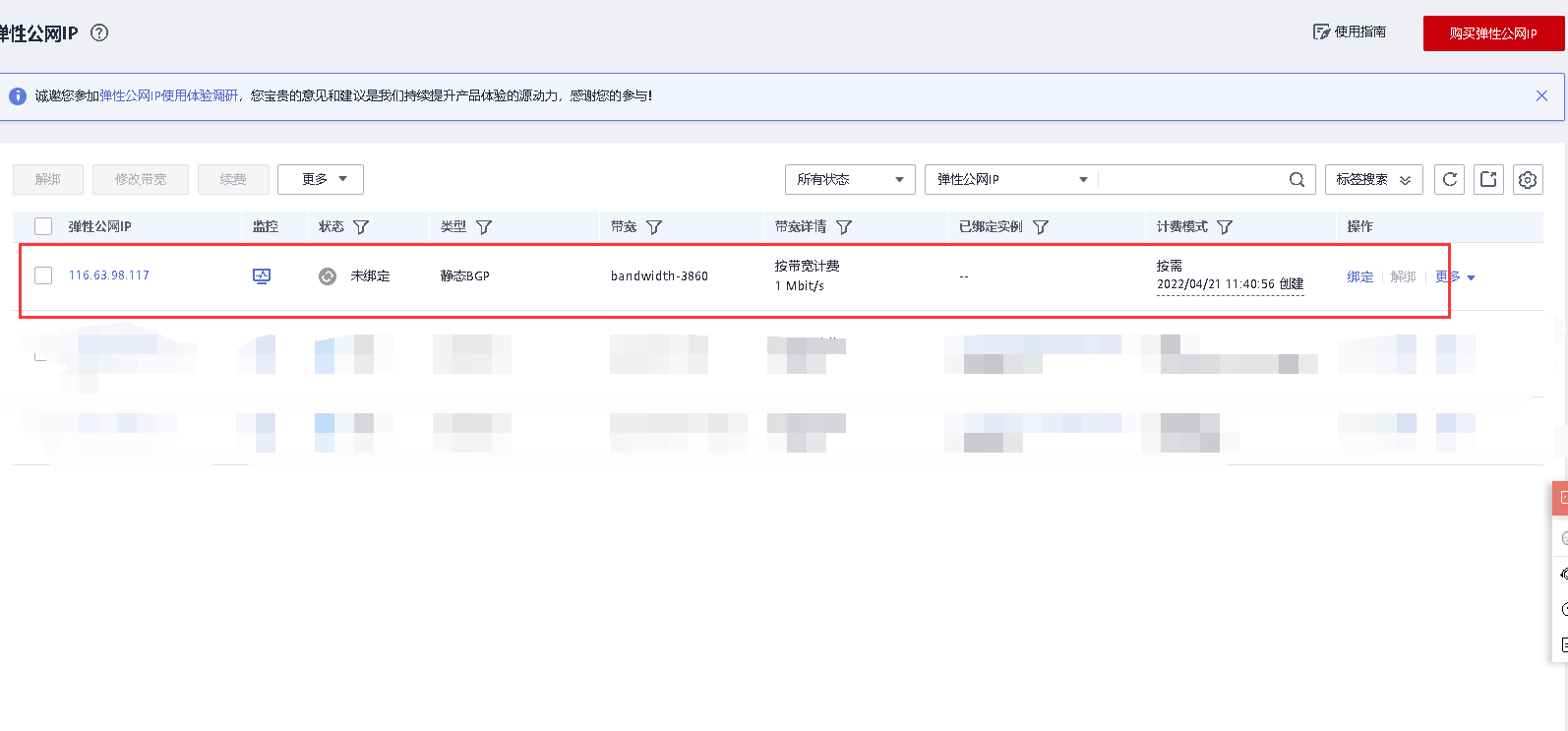
返回控制台可以看到我们购买的弹性公网
6.2.4.2 MySQL绑定公网IP
回到数据库控制台
在连接管理中选择公网ip绑定
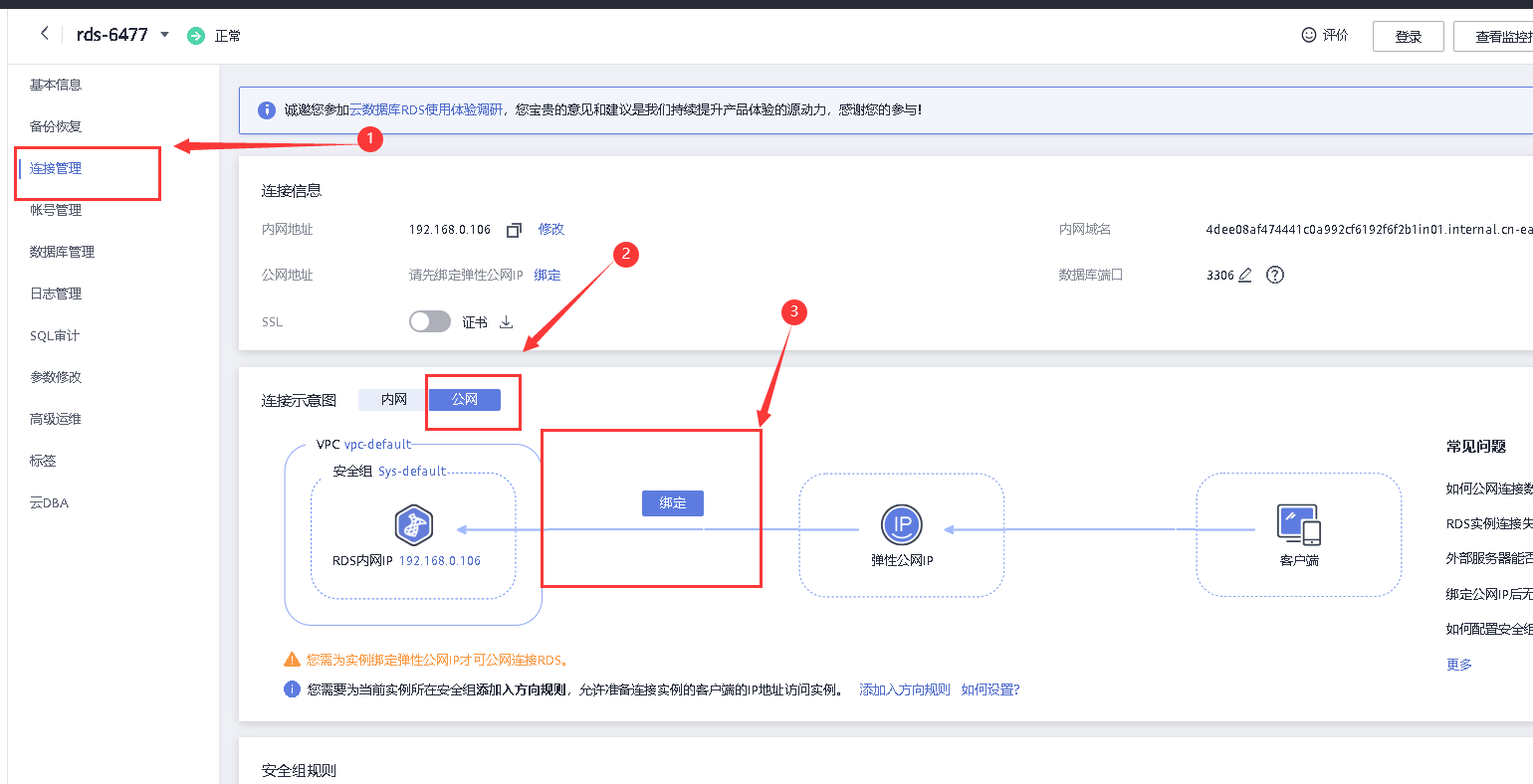
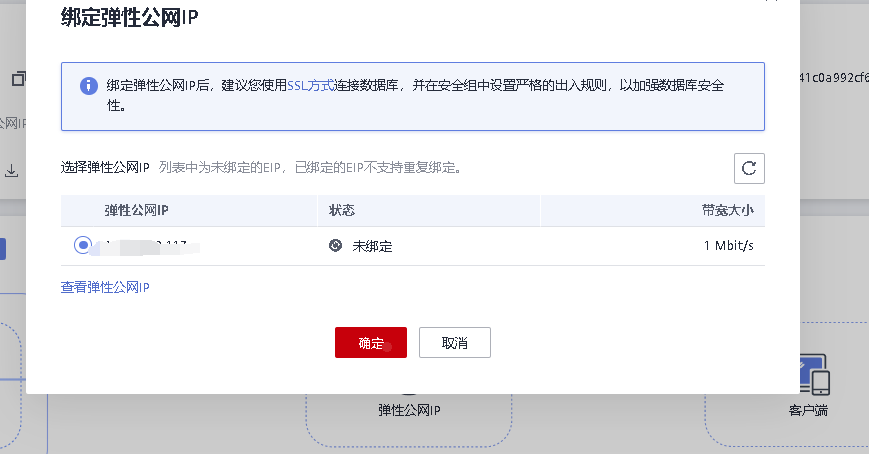
点击确定
此时我们就可在本地访问MySQL数据库
我使用的是sqlyog软件
成功访问
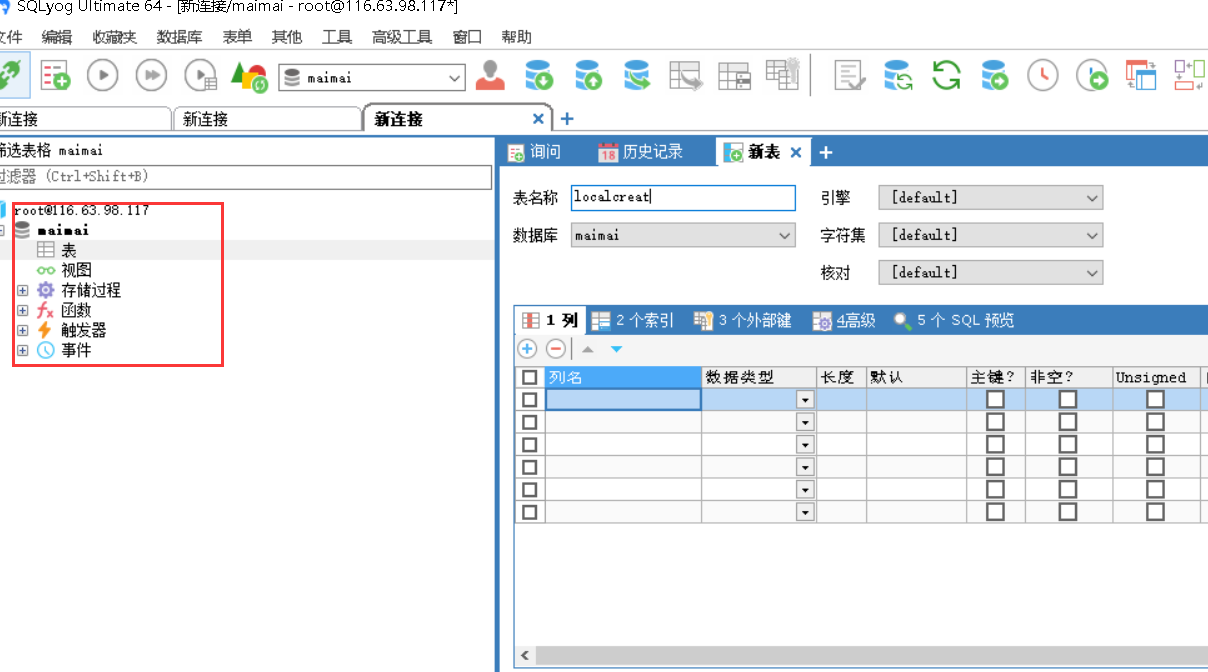
我在本地创建一个名为localcreat的表,然后在DAS进行查看

创建成功
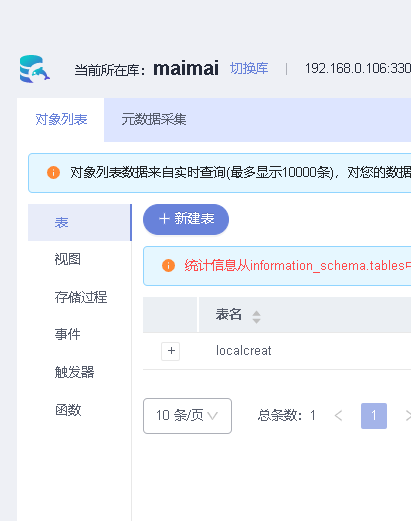
华为云RDS数据库搭建完成
7. 总结
本次内容共创主要讲述了数据库中的SELECT语句、集函数查询、单表查询、多表查询、嵌套查询、子查询、带EXISTS关键字的子查询,并通过案例演示SQL语句的实际应用,可以帮助很好的帮助大家数据库的入门学习。如果大家想进一步了解学习华为云数据库,还可以学习:沙箱实验10分钟快速入门RDS

- 点赞
- 收藏
- 关注作者
评论(0)