分类-KNN算法(鸢尾花分类实战)

简介
K近邻(K Nearest Neighbors,KNN)算法是最简单的分类算法之一,也就是根据现有训练数据判断输入样本是属于哪一个类别。
“近朱者赤近墨者黑",所谓的K近邻,也就是根据样本相邻最近的K个数据来进行判断,看K个邻居中所属类别最多的是哪一类,则将该样本分为这一类。
算法原理很简单,如下图,K取3时,输入数据为红色点,在它最近的3个邻居点中,有2个黄色1个蓝色,故应把它分类为黄色这一类。
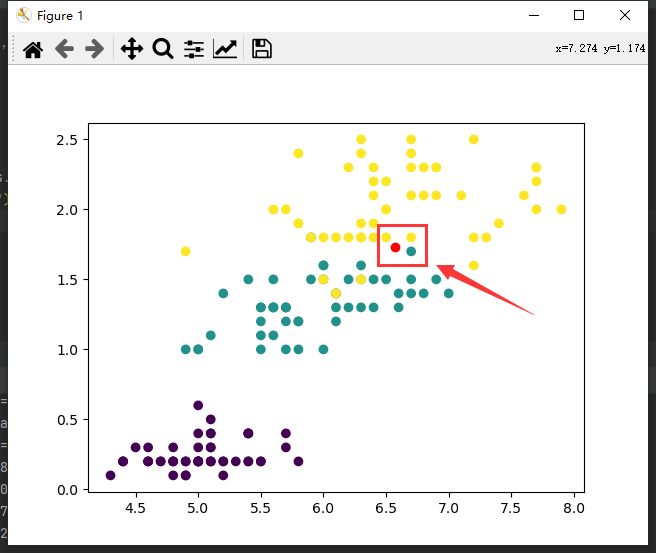
可以看出K的取值应为奇数,避免K近邻中有相同个数的类别,同时也不能为类别数的倍数,如3分类中K取3时,出现1:1:1无法分类的情况。注意如果K过小可能造成过拟合。
此外距离的定义公式也有很多,这里不再赘述,根据实际场景进行甄选,一般使用欧式距离更多,即 d i s t ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 dist(x,y)=\sqrt{\sum_{i=1}^n(x_i-y_i)^2} dist(x,y)=∑i=1n(xi−yi)2
代码复现
- 数据处理
采用典中典——鸢尾花数据集,Kaggle中有上传鸢尾花数据(下载链接)
鸢尾花数据集包含四个特征,和三种鸢尾花标签类别,共150条数据。
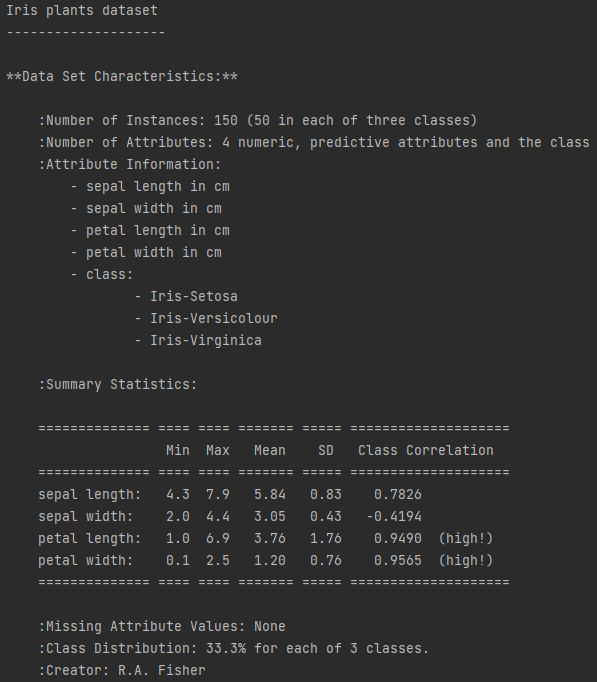
采用sepal length和petal width两个特征,你也可以采用其他特征。
使用pandas读取数据,不懂pandas可以参考我这篇:Pandas光速入门-一文掌握数据操作
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
data = pd.read_csv("D:\\Iris_flower_dataset.csv")
x = np.array(data.iloc[:, [1, 4]])
y_tmp = np.array(data["Species"])
y = []
label = ["Iris-setosa", "Iris-virginica", "Iris-versicolor"]
for i in y_tmp: # 将英文压为整型
if i == label[0]:
y.append(0)
elif i == label[1]:
y.append(1)
else:
y.append(2)
y = np.array(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=2022)
# 训练集可视化
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train)
plt.xlabel("sepal length[cm]") # 设置x轴名
plt.ylabel("petal width[cm]") # 设置y轴名
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
可视化可参考:Matplotlib光速入门-从安装到绘图实战
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
- KNN定义
只考虑两个特征,就简单化处理了,即用 ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 \sqrt{(x_1-x_2)^2+(y_1-y_2)^2} (x1−x2)2+(y1−y2)2
class KNN(object):
def __init__(self, k): # 初始化函数
self.k = k
def fit(self, x, y): # 载入训练集
self.x = x
self.y = y
def _distance(self, v1, v2): # 欧式距离
return np.sum(np.square(v1 - v2)) # (不开根号节省算力,效果一致
def predict(self, x):
y_pre = []
for i in range(len(x)): # x是测试集,是一个n维特征数组
dist_arr = [self._distance(x[i], self.x[j]) for j in range(len(self.x))] # 计算距离
sorted_index = np.argsort(dist_arr) # 排序
top_k_index = sorted_index[:self.k] # 得到K近邻
nearest = self._count(y_top_k=self.y[top_k_index]) # 根据K近邻分类做出预测
y_pre.append(nearest) # 加入预测答案
return np.array(y_pre)
def _count(self, y_top_k): # 统计各分类数量
y_map = {}
for y in y_top_k:
if y not in y_map.keys():
y_map[y] = 1 # 首次不在字典则置1
else:
y_map[y] += 1 # 否则value++
sorted_vote_dict = sorted(y_map.items(), key=operator.itemgetter(1), reverse=True) # 排序
return sorted_vote_dict[0][0] # 返回数量最多的分类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 测试
if __name__ == "__main__":
# 数据处理
data = pd.read_csv("D:\\Iris_flower_dataset.csv")
x = np.array(data.iloc[:, [1, 4]])
y_tmp = np.array(data["Species"])
y = []
label = ["Iris-setosa", "Iris-virginica", "Iris-versicolor"]
for i in y_tmp: # 将英文压为整型
if i == label[0]:
y.append(0)
elif i == label[1]:
y.append(1)
else:
y.append(2)
y = np.array(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=2022)
# 创建KNN对象
clf = KNN(5)
# 训练
clf.fit(x_train, y_train)
# 测试
pre_test = clf.predict(x_test)
# 计算正确率
correct = np.count_nonzero((pre_test == y_test) == True)
print("正确率:%.3f" % (correct / len(pre_test)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
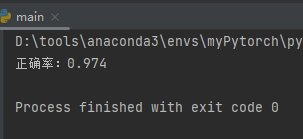
- 结果可视化
# 结果可视化
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train, alpha=0.3)
for i in range(len(x_test)):
if pre_test[i] == y_test[i]: # 正确标绿
plt.scatter(x_test[i][0], x_test[i][1], color="green")
else: # 错误标红
plt.scatter(x_test[i][0], x_test[i][1], color="red")
plt.xlabel("sepal length[cm]") # 设置x轴名
plt.ylabel("petal width[cm]") # 设置y轴名
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
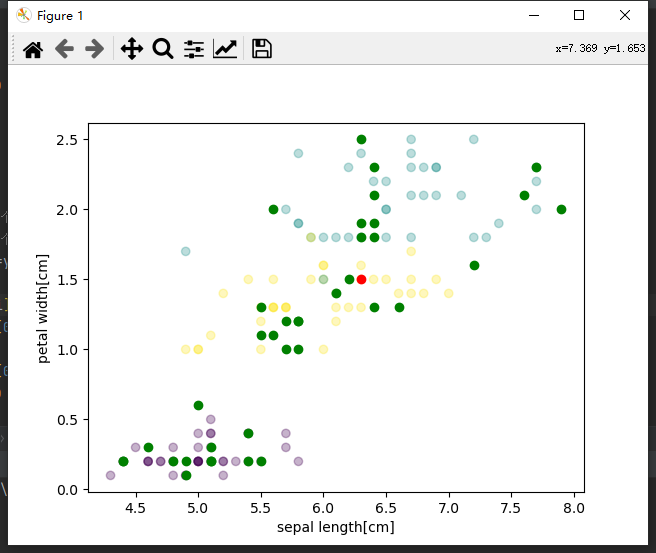
半透明的是训练数据,测试数据中,绿色是分类正确的点,红色是分类错误的点,可以看出上图只错了一个。
sklearn库调用
使用sklearn封装函数可以非常方便的实现:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 载入数据
iris = datasets.load_iris() # 已经内置了鸢尾花数据集
x = iris.data # 输入4个特征
y = iris.target # 输出类别
# 随机划分数据集,默认25%测试集75%训练集
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 创建一个KNN分类器对象,并设置K=5,
clf = KNeighborsClassifier(n_neighbors=5) # clf意为Classifier
# 训练
clf.fit(x_train, y_train) # 用训练数据拟合分类器模型
# 测试
pre_test = clf.predict(x_test) # 得到测试集的预测结果
# 计算正确率
print('正确率:%.3f' % accuracy_score(y_test, pre_test))
# 由于数据集是随机划分,每次得到正确率自然不同,可以设置random_state让随机一致
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
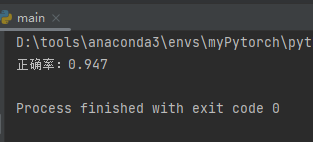
直接调用库函数简直不要太方便,芜湖起飞(~ ̄▽ ̄)~
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
文章来源: wzlodq.blog.csdn.net,作者:吾仄lo咚锵,版权归原作者所有,如需转载,请联系作者。
原文链接:wzlodq.blog.csdn.net/article/details/126828477

- 点赞
- 收藏
- 关注作者
评论(0)