【每日一读】Self-Paced Network Embedding


简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
【每日一读】每天浅读一篇论文,了解专业前沿知识,培养阅读习惯(阅读记录 仅供参考)
论文简介
原文链接:https://dl.acm.org/doi/10.1145/3219819.3220041
会议:KDD '18: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (CCF A类)
年度:2018年7月19日
ABSTRACT
网络嵌入在最近具有许多实际应用的数据挖掘研究中引起了越来越多的关注
网络嵌入是学习网络中节点的低维表示
一种流行的现有方法,例如 DeepWalk、Node2Vec 和 LINE,通过将正上下文节点推送到锚节点,同时在低维向量空间中将负上下文节点推离锚节点来学习节点表示
在对负上下文节点进行采样时,它们通常采用基于节点流行度的预定义采样分布
然而,这种抽样分布往往无法捕捉到每个节点的真实信息量,也无法反映训练状态
为了解决这些重要问题,在本文中,我们提出了一种新颖的自定进度网络嵌入方法
具体来说,我们的方法可以根据当前训练状态自适应地捕获每个节点的信息量,并根据其信息量对负上下文节点进行采样
所提出的自定进度采样策略可以通过训练过程逐渐选择困难的负上下文节点,以学习更好的节点表示
此外,为了更好地捕捉节点信息以学习节点表示,我们将我们的方法扩展到生成对抗网络框架,该框架具有更大的发现节点信息的能力
已经在基准网络数据集上进行了广泛的实验,以验证我们提出的方法的有效性
1 INTRODUCTION
近年来,网络嵌入因其是网络数据分析的基本工具而引起了广泛的关注。网络嵌入旨在学习网络中节点的低维表示,以便下游任务(例如节点分类、链接预测和网络可视化)可以从中受益。学习低维表示的基本思想是保持网络拓扑结构的接近性。通过保留这种接近度,具有较大接近度的节点将具有相似的低维表示,有利于下游任务。
为了获得有效的低维表示,近年来已经提出了各种各样的方法。它们旨在捕获网络中的各种邻近度
例如
- 开创性的 DeepWalk 模型 [21] 采用随机游走来获得节点序列,然后通过将节点序列视为词序列,将网络嵌入重新表述为词嵌入。这样,Skip-gram [20] 模型可以捕获节点之间的接近度
- 之后,Node2Vec [6] 基于类似的想法提出,但采用了一种新颖的随机游走算法
- 此外,在学习低维表示时,引入了 LINE [25] 以保持一阶和二阶接近度
- GraRep [4] 旨在在表示学习期间保持高阶接近度
- Struc2Vec [22] 旨在通过识别结构身份来保持结构邻近性
在这些现有方法中,基于 Skip-gram [20] 模型的方法,如 DeepWalk [21]、Node2Vec [6] 和 LINE [25] 备受关注
他们的基本思想是将相似的节点推到一起,同时推开不同的节点。在数学上,它被表述为一个二元分类问题,将两个相似的节点分类为正对,而将两个不同的节点分类为负对。尽管这些方法在许多任务中都表现出良好的性能,但它也有一个缺点。具体来说,为了训练这个二元分类问题,我们应该将正负对输入模型。对于每个节点,可以根据网络[25]的边缘或随机游走的结果[6,21]轻松获得其配对的正节点。但是如何获得负节点并不明显。一些负面节点信息量更大,而另一些则不然。如果采用随机抽样方法,我们无法区分不同节点的信息量。
因此,现有的方法,如 DeepWalk [21]、Node2Vec [6] 和 LINE [25],建议基于预先设计的分布对负节点进行采样。这种分布取决于节点的程度。这种采样方法背后的直觉是,对更多连接的节点进行过采样会带来更好的性能,因为这些节点比连接较少的节点携带更多的信息。虽然这种策略有正确的直觉,但这个想法是不完整的,因为这种方法忽略了连接较少的节点在实践中也可能提供信息。因此,我们不能仅仅使用连接信息来确定节点的信息量。如何为训练模型发现真正信息丰富的节点既重要又具有挑战性。
此外,现有网络嵌入方法[6,21,25]采用的采样分布是静态的,这意味着采样分布在训练过程中不会发生变化。因此,在训练模型时,节点的信息量是恒定的。然而,随着训练过程的进行,一些负节点被很好地推离了锚节点,而另一些则没有。在这种情况下,我们应该更多地关注这些困难节点。因此,最好在不同的训练阶段对具有不同概率的节点进行采样。另一方面,我们不能总是专注于困难的节点,而忽略容易的节点。根据人类的学习过程,我们在学习新模型时应该从容易的样本开始,然后逐步学习困难的样本[2, 13]。原因是我们可以通过使用简单的样本来学习一个草稿模型,然后通过获取困难的样本来对其进行细化。在我们的例子中,如果我们总是选择困难的负节点来训练我们的模型,那么容易的节点不能被充分利用,并且容易因为过于关注困难节点而干扰低维表示。
为了解决上述具有挑战性的问题,在本文中,我们提出了一种新颖的自定进度网络嵌入方法。使用这种方法,我们可以动态地对训练模型的信息负节点进行采样。具体来说,我们提出了一种自定进度的节点采样策略。该策略可以根据当前模型参数发现每个节点的信息量,然后根据其信息量对负节点进行采样。此外,这种自定进度的策略可以随着训练过程的进行逐渐对困难的负节点进行采样。此外,我们将这种自定进度的采样策略扩展到生成对抗网络框架。在七个基准网络数据集上进行了广泛的实验,以验证我们提出的方法的有效性。
2 RELATED WORK
2.1 Network Embedding
网络嵌入由于其在网络数据分析中的重要作用而成为近年来热门的数据挖掘研究课题。它是学习网络中每个节点的低维表示,同时保持邻近度。最近,在有效的网络嵌入算法方面取得了很大进展。例如,DeepWalk [21] 被提出利用随机游走将节点序列作为单词句子,然后使用 Skip-gram [20] 模型来学习节点嵌入,这对于通过最大化似然度来预测每个锚节点的上下文至关重要功能如下:
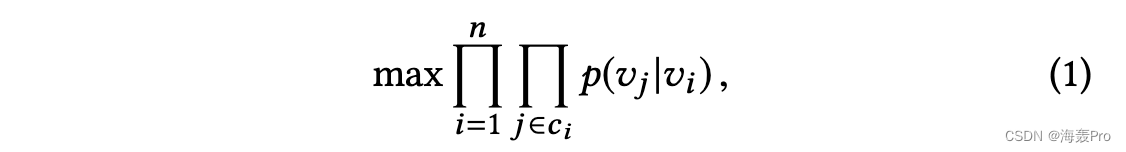
其中 vi 是锚节点, vj 表示其上下文节点,并且 cidenote 表示节点 vi 的上下文集。 p(vj |vi ) 是给定节点 vi 的节点 vj 的条件概率。基于这个模式,LINE[25]和Node2Vec[6]分别提出了不同的上下文构建方法。此外,其他一些方法也取得了很大进展。例如,GraRep [4] 旨在在表示学习期间保持高阶接近度。 Struc2Vec [22] 旨在通过识别结构身份来保持结构邻近性。 M-NMF [29] 在学习低维表示时捕获社区结构。 TADW [30] 和 ANE [8] 旨在整合拓扑结构和节点属性来学习节点表示。提出了一种动态网络嵌入方法[15]来处理动态网络。 SDNE [27] 采用深度自动编码器来捕获网络中的高非线性。在[12]中,提出了一种基于图卷积网络的半监督网络嵌入方法。尽管这些方法在许多任务中很有前景,但在本文中,我们将限制我们解决与方程相关的模型的兴趣。 (1)。
2.2 Sample Selection
Negative Sampling
Negative Sampling [7, 20] 是一种解决多类分类问题的有效方法。具体来说,当类的数量非常大时,多类分类问题,例如问题(1),效率相当低。负采样(或称为对比学习)通过构建正对和负对将其重新表述为二元分类问题。正对通常很容易基于一些先验知识构建。例如,网络中的正对可以根据节点之间的连接轻松构建[25]。挑战在于如何构建负对。在[20]中,作者提出根据词的流行度对否定对进行采样,而[25]则考虑根据节点的程度来构建采样分布。实际上,它们都有一个共同的直觉,即应该更频繁地选择更流行或相关的样本,因为它们信息量更大。在推荐系统的背景下,[31]提出了一种基于临时推荐结果的动态负采样算法。最近,IRGAN [28] 被提出具有与负采样相同的精神用于信息检索。与传统的负采样不同,它采用生成器动态生成负样本。
Self-Paced Learning
在机器学习社区中,如何选择训练样本来学习一个好的模型是一个重要的话题。众所周知,人类通常从简单的概念学习到复杂的概念。为了模仿人类的这种认知活动,课程学习[2]和自定进度学习[13]引起了很多关注。特别是,课程学习基于一些固定的先验知识,构造一个排序函数,为不同的样本分配不同的学习优先级。自定进度学习通过动态测量样本的性能来自愿选择训练样本,如下所示:
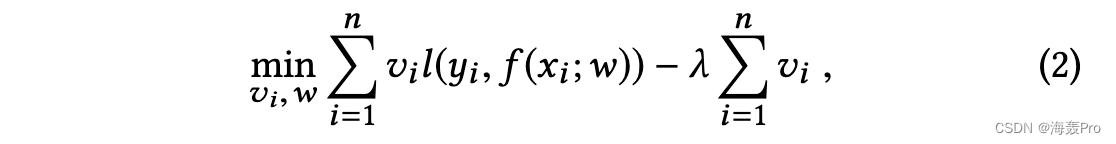
其中 w 是模型参数,vi ∈ {0, 1} 表示是否选择了训练样本 (xi , yi ),l(·,·) 表示损失函数。
沿着这条线,已经针对不同的情况提出了许多作品。例如,[9] 提出了一种自定进度的学习算法来选择简单多样的样本。 [16] 提出了半监督设置下的自定进度协同训练。 [24]被提出用于对象跟踪。 [ 10] 提出了将课程学习和自定进度学习相结合的方法。但是,据我们所知,我们的设置没有现成的作品。因此,受自定进度学习的启发,我们将重点关注如何动态地执行从简单样本到困难样本的负采样来求解方程。 (1)。
5 CONCLUSION
在本文中,我们提出了新颖的自定进度网络嵌入方法。我们提出的方法可以有效地捕获每个节点的信息量
基于节点的信息量,我们引入了一种自定进度的信息量感知采样策略
通过这种采样策略,我们提出的方法可以逐渐选择信息节点来训练模型参数
对不同数据挖掘任务的广泛实验证明了我们提出的方法的优越性能
读后总结
一般来说,负节点的数量会非常大,正常就是对负节点进行采样(固定信息量)
本文则是可以根据当前模型参数发现每个节点的信息量,然后根据其信息量对负节点进行采样(自适应)
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

文章来源: haihong.blog.csdn.net,作者:海轰Pro,版权归原作者所有,如需转载,请联系作者。
原文链接:haihong.blog.csdn.net/article/details/127082684

- 点赞
- 收藏
- 关注作者
评论(0)