【面试题总结】分布式锦集

1. 负载均衡算法
- 随机访问策略。 系统随机访问,缺点:可能造成服务器负载压力不均衡,俗话讲就是撑的撑死,饿的饿死。
- 轮询策略。 请求均匀分配,如果服务器有性能差异,则无法实现性能好的服务器能够多承担一部分。
- 权重轮询策略。 权值需要静态配置,无法自动调节,不适合对长连接和命中率有要求的场景。
- Hash取模策略。 不稳定,如果列表中某台服务器宕机,则会导致路由算法产生变化,由此导致命中率的急剧下降。
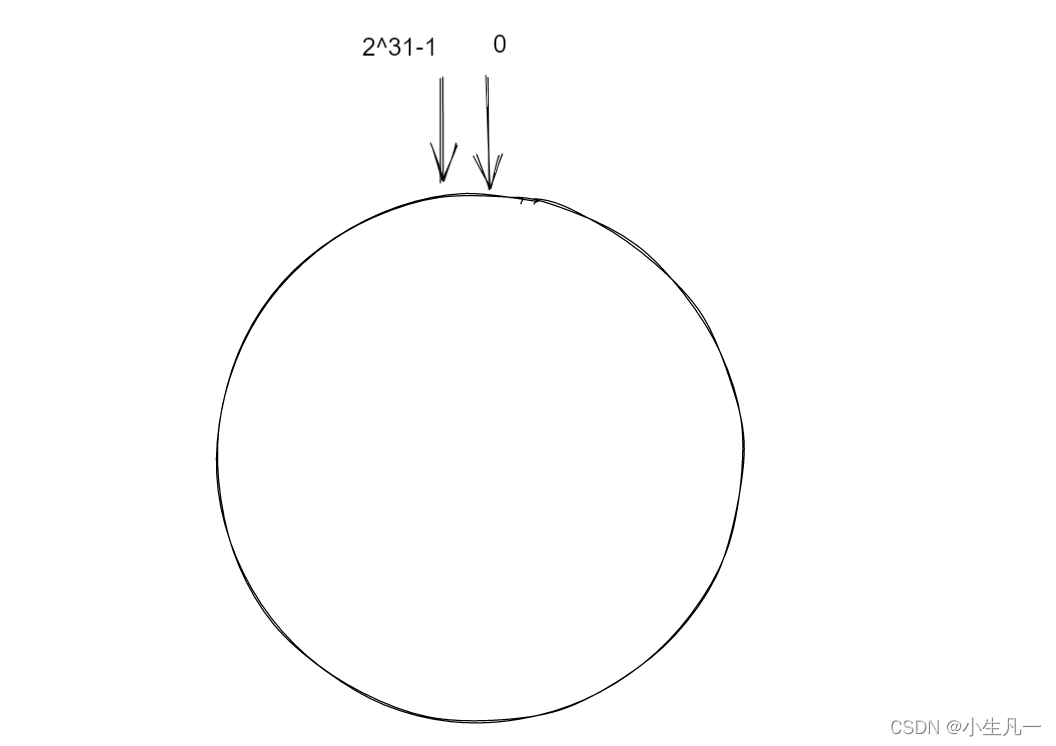
简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数 H 的值空间为 0 ~ 2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下:
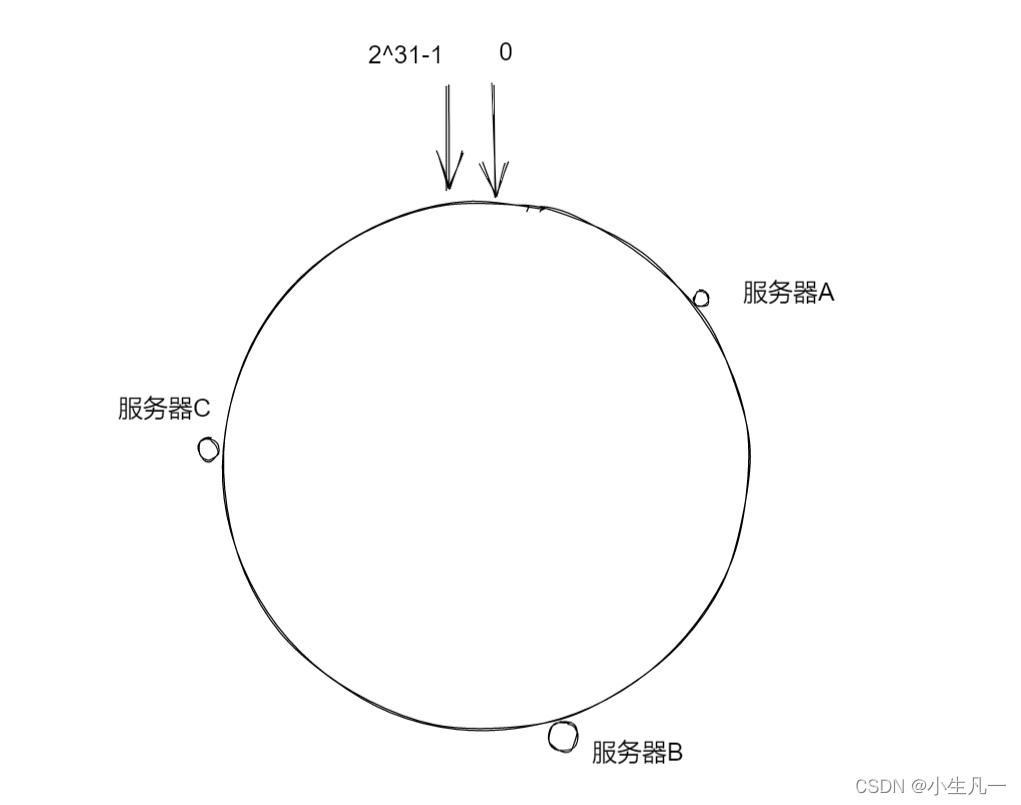
多个服务器都通过这种方式进行计算,最后都会各自映射到圆环上的某个点,这样每台机器就能确定其在哈希环上的位置,如下图所示。
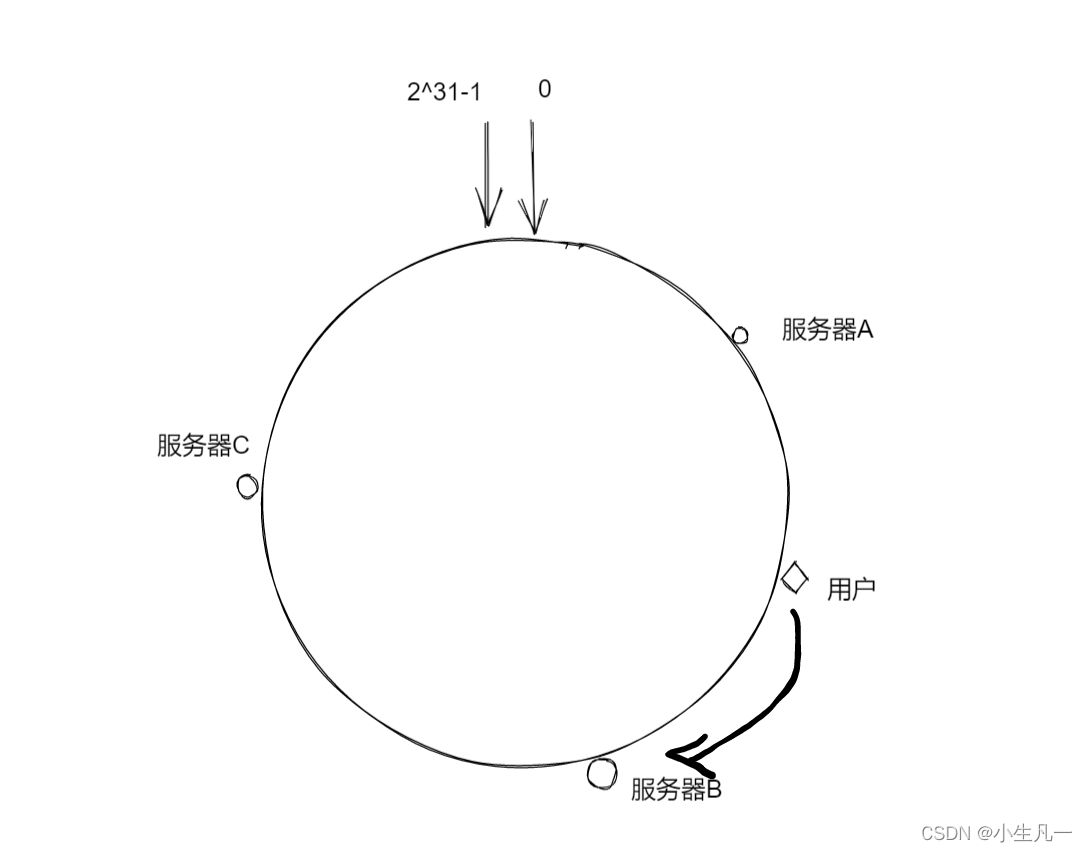
那么用户访问,如何分配访问的服务器呢?我们根据用户的 IP 使用上面相同的函数 Hash 计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针行走,遇到的第一台服务器就是其应该定位到的服务器。
2. 熔断和降级
2.1 熔断
一般是某个服务故障或者是异常引起的,当某个异常条件被触发,直接熔断整个服务,而不是一直等到此服务超时,为了防止防止整个系统的故障。
而采用了一些保护措施。过载保护。比如A服务的X功能依赖B服务的某个接口,当B服务接口响应很慢时,A服务X功能的响应也会被拖慢,进一步导致了A服务的线程都卡在了X功能上,A服务的其它功能也会卡主或拖慢。此时就需要熔断机制,即A服务不在请求B这个接口,而可以直接进行降级处理。
2.2 降级
服务器当压力剧增的时候,根据当前业务情况及流量,对一些服务和页面进行有策略的降级。以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和大部分客户的得到正确的响应。
自动降级:超时、失败次数、故障、限流
(1)配置好超时时间(异步机制探测回复情况);
(2)不稳的api调用次数达到一定数量进行降级(异步机制探测回复情况);
(3)调用的远程服务出现故障(dns、http服务错误状态码、网络故障、Rpc服务异常),直接进行降级。
人工降级:秒杀、双十一大促降级非重要的服务。
3. 幂等
幂等性的核心思想,其实就是保证这个接口的执行结果只影响一次,后续即便再次调用,也不能对数据产生影响,之所以要考虑到幂等性问题,是因为在网络通信中,存在两种行为可能会导致接口被重复执行。
用户的重复提交或者用户的恶意攻击,导致这个请求会被多次重复执行。
在分布式架构中,为了避免网络通信导致的数据丢失,在服务之间进行通信的时候都会设计超时重试的机制,而这种机制有可能导致服务端接口被重复调用。所以在程序设计中,对于数据变更类操作的接口,需要保证接口的幂等性。
使用 redis 里面提供的 setNX 指令,比如对于MQ消费的场景,为了避免MQ重复消费导致数据多次被修改的问题,可以在接受到MQ的消息时,把这个消息通过setNx写入到redis里面,一旦这个消息被消费过,就不会再次消费。
- 建去重表,将业务中由唯一标识的字段保存到去重表,如果表中存在,则表示已经处理过了。
- 版本控制,增加版本号,当版本号符合时候,才更新数据。
- 状态控制,例如订单有状态已支付,未支付,支付中,支付失败,当处于未支付的时候才允许修改成支付中。
4. 分布式事务
在分布式系统中,一次业务处理可能需要多个应用来实现,比如用户发送一次下单请求,就涉及到订单系统创建订单,库存系统减库存,而对于一次下单,订单创建与减库存应该是要同时成功或者同时失效,但在分布式系统中,如果不做处理,就很有可能订单创建成功,但是减库存失败,那么解决这类问题,就需要用到分布式事务,常用的解决方案如下:
- 本地消息表:创建订单时,将减库存消息加入在本地事务中,一起提交到数据库存入本地消息表,然后调用库存系统,如果调用成功则修改本地。
- 消息状态为成功,如果调用库存系统失败,则由后台定时任务从本地消息表中取出未成功的消息,重试
调用库存系统。 - 消息队列:目前 RocketMQ 中支持事务消息,它的工作原理是:
- 产订单系统先发送一条 half 消息到 Broker, half 消息对消费者而言是不可见的。
- 再创建订单,根据创建订单成功与否,向 Broker 发送 commit 或 rollback。
- 并且生产者订单系统还可以提供 Broker 回调接口,当 Broker 发现一段时间 half 消息没有收到任何操作命令,则会主动调此接口来查询订单是否创建成功。
- 如果消费失败,则根据
重试策略进行重试,最后还失败则进入死信队列,等待进一步处理。
5. 分布式锁
在单体架构中,多个线程都是属于同一个进程的,所以在线程并发执行时,遇到资源竞争时,可以利用ReentrantLock、 synchronized等技术来作为锁来共享资源的使用。
而在分布式架构中,多个线程是可能处于不同进程中的,而这些线程并发执行遇到资源竞争时,利用 ReentrantLock synchronized 等技术是没办法,来控制多个进程中的线程的,所以需要分布式锁,意思就是,需要一个分布式锁生成器,分布式系统中的应用程序都可以来使用这个生成器所提供的锁,从而达到多个进程中的线程使用同一把锁。
6. 分布式主键id
在开发中,我们通常会需要一个唯一ID来标识数据,如果是单体架构,我们可以通过数据库的主键,或直接在内存中维护一个自增数字来作为ID都是可以的,但对于-个分布式系统,就会有可能会出现ID冲突,此时有以下解决方案:
- uuid,这种方案复杂度最低,但是会影响存储空间和性能。
- 利用单机数据库的自增主键,作为分布式ID的生成器,复杂度适中,ID长度较之uuid更短,但是受到单机数据库性能的限制,并发量大的时候,此方案也不是最优方案。
- 利用redis、zookeeper的特性来生成id,比如
redis的自增命令、zookeeper的顺序节点, 这种方案和单机数据库(mysq|)相比,性能有所提高,可以适当选用。 - 4.雪花算法,一切问题如果能直接用算法解决,那就是最合适的,利用雪花算法也可以生成分布式ID,底层原理就是通过
某台机器在某一毫秒内对某一个数字自增,这种方案也能保证分布式架构中的系统 id 唯一,但是只能保证趋势递增。业界存在tinyid、 leaf等开源中间件实现了雪花算法。
7. 池化技术
对象池技术基本原理的核心有两点:缓存和共享,即对于那些被频繁使用的对象,在使用完后,不立即将它们释放,而是将它们缓存起来,以供后续的应用程序重复使用,从而减少创建对象和释放对象的次数,进而改善应用程序的性能。
事实上,由于对象池技术将对象限制在一定的数量,也有效地减少了应用程序内存上的开销。
文章来源: blog.csdn.net,作者:小生凡一,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_45304503/article/details/123678858

- 点赞
- 收藏
- 关注作者
评论(0)