实时即未来,车联网项目之项目展示和任务调度【八】

@[toc]
离线任务解析——多维统计数据的准确率
- 多维统计数据准确率
- 开发步骤
- 自定义InputFormat 用于读取 Hive 数据
- 对读取进来的数据Row(srcData,errorData)转换成Row(id,srcData,errorData,准确率,错误率,处理时间)
- 自定义OutputFormat 写入到 mysql 数据库中
车联网项目 web 接口
- springboot 分三层 MVC DAO层、Service层、Controller层
- 加载程序包,添加模块,可视化
车联网任务监控与部署
-
任务部署三种模式
-
本地部署 (开发使用)
-
Standalone 部署 ()
# 启动 flink 独立集群 bin/start-cluster.sh stop-cluster.sh # 提交任务 ./bin/flink run -p 4 ./examples/batch/WordCount.jar -
Flink on yarn 部署 (生产环境)
节点 yarn角色 flink角色(HA) node01(192.168.10.10) resourcemanager、nodemanager jobmanager、taskmanager node02(192.168.10.20) nodemanager jobmanager、taskmanager node03(192.168.10.30) nodemanager taskmanager # 开辟一定的资源 -s指定slot(cpu核数) ./bin/yarn-session.sh -jm 1024m -tm 4096m # 任务提交到yarn执行,指定并行度,指定jm可用内存,指定tm的可用内存 ./bin/flink run -m yarn-cluster -p 4 -yjm 1024m -ytm 2048m ./examples/batch/WordCount.jar
-
-
车联网任务分类总结
-
实时分析(Flink任务)
- 原始数据实时ETL
- 车辆明细数据实时ETL
- 驾驶行程分析
- 电子围栏分析
- 远程诊断故障实时分析
- 自定义告警规则分析
- 车辆数据指标即席查询(phoenix)
- mongo中geohash地理位置查询
- 自定义告警规则告警类型统计
- 自定义告警规则新增与历史告警统计
- 驾驶充电行程分析(扩展分析任务,类似驾驶行程分析)
- T3车型故障分析(扩展分析任务)
-
离线分析:
- 原始数据etl中hdfs结果正确数据与异常数据关联对应hive外部表(hive)
- 数据接入正确率离线分析(hive)
- 车辆动态监测(sql)
- 后台数据服务接口(application)
-
-
任务部署
-
实时 ETL 任务部署
-
编译实时子任务 —— StreamingAnalysis
-
在 pom.xml 文件中设置执行主类 (mainClass)
-
获得打包后的 jar 包,上传到到服务器
-
提交到 yarn 执行,由于虚拟机可用内存少,根据可用内存大小设置jm/tm内存
./bin/flink run -m yarn-cluster -p 3 -yjm 1024m -ytm 2048m /opt/CarNetworkingSystem/StreamingAnalysis-1.0-SNAPSHOT-jar-with-dependencies.jar -
提交任务到Flink集群
./bin/flink run -p 3 /opt/CarNetworkingSystem/StreamingAnalysis-1.0-SNAPSHOT-jar-with-dependencies.jar
-
-
车辆明细数据 ETL 任务部署——VehicleDetailETLTask
-
提交到 yarn 执行
./bin/flink run -p 4 -c cn.itcast.flink.streaming.task.VehicleDetailETLTask /opt/CarNetworkingSystem/StreamingAnalysis-1.0-SNAPSHOT-jar-with-dependencies.jar -
如果遇到不能分配足够的 slot 数,如何解决呢?
- 可以增加 slot 数,以满足任务所需 slot
- 减少提交任务的 slot 数,以满足集群中的 slot 数
-
-
-
选用 Linux crontab 进行任务部署会遇到各种问题,是否有更好的解决方案呢?
- 自研框架
- Oozie 、airflow、DelphinScheduler、 Azkaban、SchedulerX 等
- 这里选择 DelphinScheduler
DolphinScheduler任务调度
DolphinScheduler任务调度介绍
-
DolphinScheduler 的简介和项目背景
-
DolphinScheduler 的项目的优势:
- 易于使用
- 解决复杂任务依赖的问题
- 支持多租户
- 支持许多任务类型
- 支持HA和线性可扩展性
-
DolphinScheduler 的项目特点:
DolphinScheduler 的项目安装
-
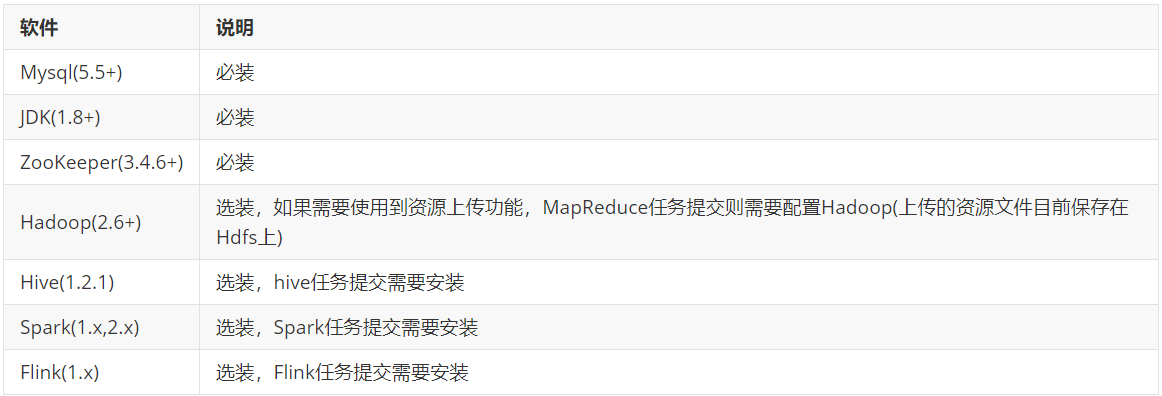
安装要求环境

-
上传安装包
tar zxvf apache-dolphinscheduler-incubating-1.2.0-dolphinscheduler-backend-bin.tar.gz -C /export/servers/dolphinscheduler/dolphinscheduler-backend-1.2.0 -
数据库初始化
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; SET GLOBAL validate_password_policy=LOW; SET GLOBAL validate_password_length=1; GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'root'@'%' IDENTIFIED BY '123456'; flush privileges; -
添加mysql的jar:mysql-connector-java-5.1.47.jar到$HOME/lib目录下
-
修改./conf/application-dao.properties中的下列属性
# mysql spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://node03:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8 spring.datasource.username=root spring.datasource.password=123456 -
建立 java 的软连接
ln -s /export/servers/jdk1.8.0_181/bin/java /usr/bin/java -
执行创建表和导入基础数据脚本($HOME目录下)
-
修改 DolphinScheduler 的 instal.sh 文件
# 这里填 mysql or postgresql dbtype="mysql" # 数据库连接地址 dbhost="node03:3306" # 数据库名 dbname="dolphinscheduler" # 数据库用户名,此处需要修改为上面设置的{user}具体值 username="root" # 数据库密码, 如果有特殊字符,请使用\转义,需要修改为上面设置的{passowrd}具体值 passowrd="123456" # conf/config/install_config.conf配置 # 注意:安装路径,不要当前路径(pwd)一样 installPath="/opt/soft/dolphinscheduler" # 部署用户 # 注意:部署用户需要有sudo权限及操作hdfs的权限,如果开启hdfs,根目录需要自行创建 deployUser="root" # zk集群 zkQuorum="node01:2181,node02:2181,node03:2181" # 安装hosts # 注意:安装调度的机器hostname列表,如果是伪分布式,则只需写一个伪分布式hostname即可 ips="node01,node02,node03" # conf/config/run_config.conf配置 # 运行Master的机器 # 注意:部署master的机器hostname列表 masters="node01,node02" # 运行Worker的机器 # 注意:部署worker的机器hostname列表 workers="node02,node03" # 运行Alert的机器 # 注意:部署alert server的机器hostname列表 alertServer="node03" # 运行Api的机器 # 注意:部署api server的机器hostname列表 apiServers="node01" ... resUploadStartupType="HDFS" defaultFS="hdfs://node01:8020" # resourcemanager HA配置,如果是单resourcemanager,这里为yarnHaIps="" yarnHaIps="" # 如果是单 resourcemanager,只需要配置一个主机名称,如果是resourcemanager HA,则默认配置就好 singleYarnIp="node01" # hdfs根路径,根路径的owner必须是部署用户。1.1.0之前版本不会自动创建hdfs根目录,需要自行创建 hdfsPath="/dolphinscheduler" # 拥有在hdfs根路径/下创建目录权限的用户 # 注意:如果开启了kerberos,则直接hdfsRootUser="",就可以 hdfsRootUser="root" -
创建 hadoop 配置文件连接
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/hdfs-site.xml ./ ln -s /export/servers/hadoop-2.7.5/etc/hadoop/core-site.xml ./ -
自动部署
#1.安装 pip yum install -y python-pip #2.安装 kz 工具 pip install kazoo #3.执行一键部署脚本 sh install.sh -
JPS查看是否安装成功
-
DophinScheduler 启停服务
bin/stop_all.sh bin/start-all.sh -
前端部署
-
上传并解压缩前端部署包
mkdir /export/servers/dolphinscheduler/dolphinscheduler-front-1.2.0 tar zxvf apache-dolphinscheduler-incubating-1.2.0-dolphinscheduler-front-bin.tar.gz -C /export/servers/dolphinscheduler/dolphinscheduler-front-1.2.0 -
执行自动部署:默认端口为 8888
sh ./install-dolphinscheduler-ui.sh -
登录到 DolphinScheduler
http://node01:8888/view/login/index.html
默认用户名密码: admin/dolphinscheduler123 -
启动前端服务
后台:
start-all.sh前端:
systemctl restart nginx
-
DolphinScheduler基础操作

- 点赞
- 收藏
- 关注作者
评论(0)