SQL检索数据的超全教程 2

汇总数据
聚集函数
聚集函数:运行在行组上,计算和返回单个值的函数
SQL聚集函数
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
AVG函数
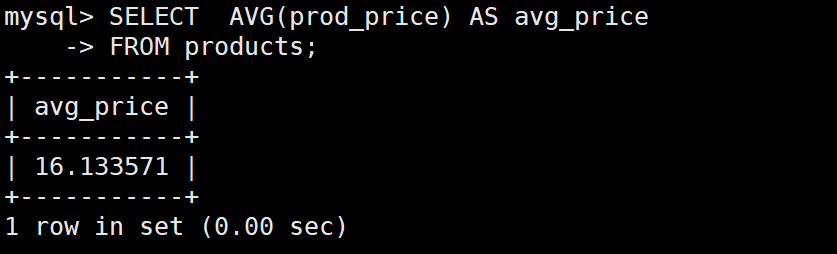
例:返回products表中所有产品的平均价格:
SELECT AVG(prod_price) AS avg_price
FROM products;
:paintbrush:AVG函数忽略列值为NULL的行
COUNT函数
确定表中行的数目或符合特定条件的行的数目。
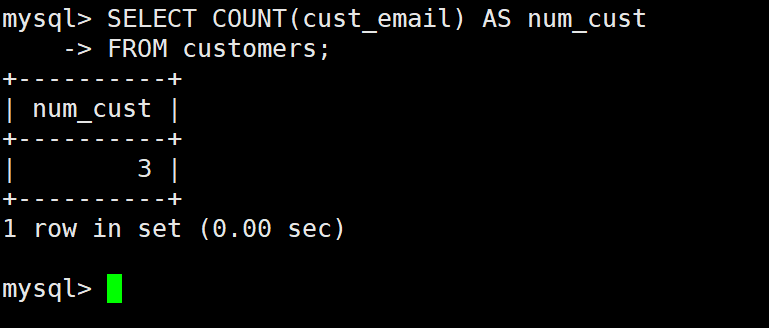
例:返回customers表中客户的总数
SELECT COUNT(*) AS num_cust
FROM customers;

例:只对具有电子邮件的客户计数
SELECT COUNT(cust_email) AS num_cust
FROM customers;
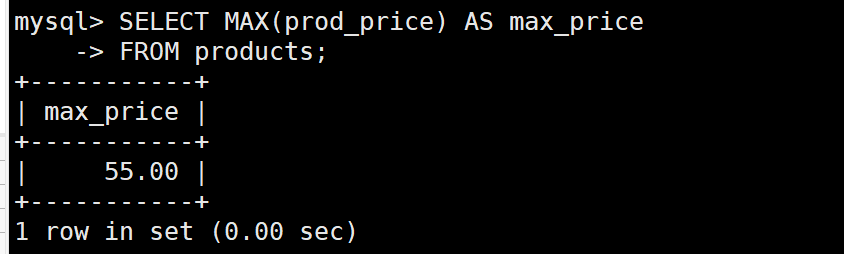
MAX函数
SELECT MAX(prod_price) AS max_price
FROM products;
:unicorn:用于文本数据时,如果数据按相应的列排序,则max返回最后一行。
:dagger:MAX函数忽略列值为NULL的行
MIN函数
MIN函数与MAX函数正好相反
SUM函数
sum用来返回指定列值的和
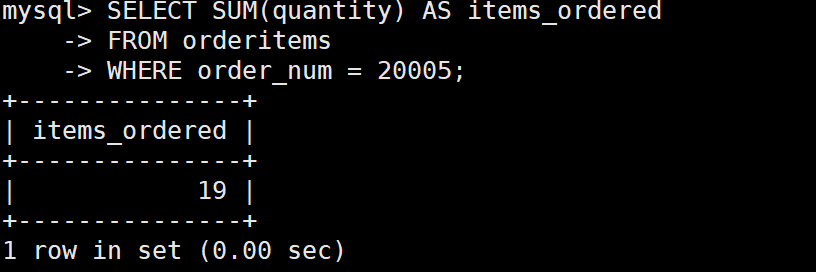
例:检索所订购的物品的总数。
SELECT SUM(quantity) AS items_ordered
FROM orderitems
WHERE order_num = 20005;
SUM还可以与之前的计算字段进行联动
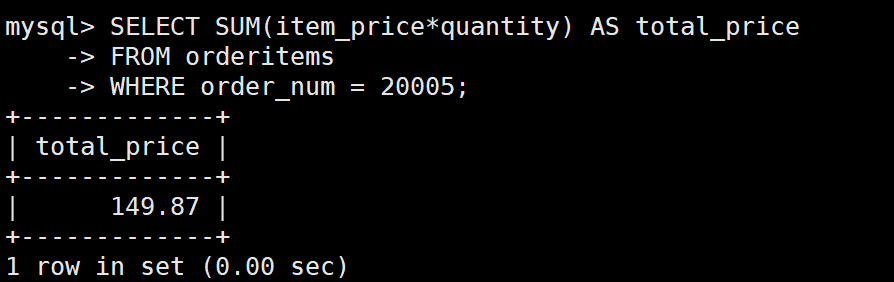
例:求总的订单金额
SELECT SUM(item_price*quantity) AS total_price
FROM orderitems
WHERE order_num = 20005;
聚集不同值
:warning:下面介绍聚集函数的DISTINCT的使用,mysql4.x是不能正常使用的。
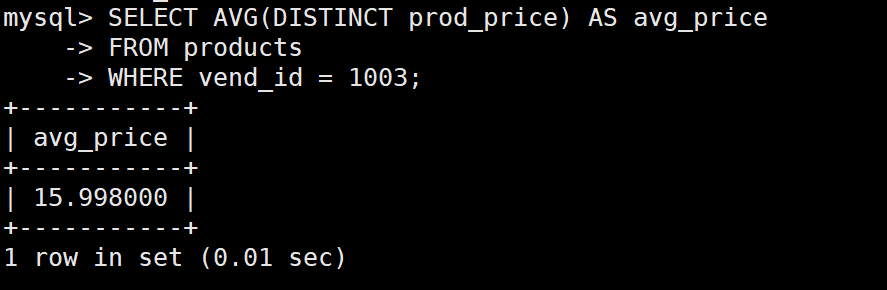
SELECT AVG(DISTINCT prod_price) AS avg_price
FROM products
WHERE vend_id = 1003;
:date:DISTINCT不能用于COUNT(*)。
组合聚集函数
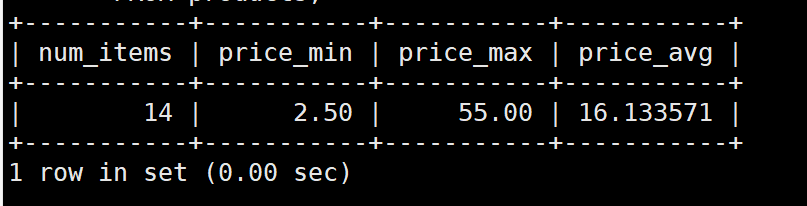
SELECT COUNT(*) AS num_items,
MIN(prod_price) AS price_min,
MAX(prod_price) AS price_max,
AVG(prod_price) AS price_avg
FROM products;
分组数据
数据分组
分组允许把数据分为多个逻辑组,以便能对每个组进行聚集计算。
创建分组
分组是在SELECT语句的GROUP BY子句中建立的。
例:
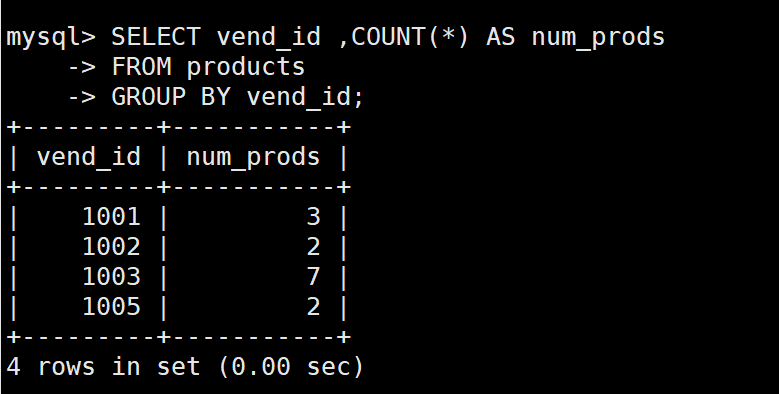
SELECT vend_id ,COUNT(*) AS num_prods
FROM products
GROUP BY vend_id;
重要规定
- GROUP BY子句可以包含任意数目的列,这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY 子句中嵌套了分组,数据将会在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算。(所以不能从个别列取回数据)
- GROUP BY 子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式,不能使用别名
- 除聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出
- 如果分组列中有null值,则null将作为一个分组返回,如果有多行null值,他们将分为一个组
- GROUP BY子句必须在WHERE子句之后,ORDER BY 子句之前。
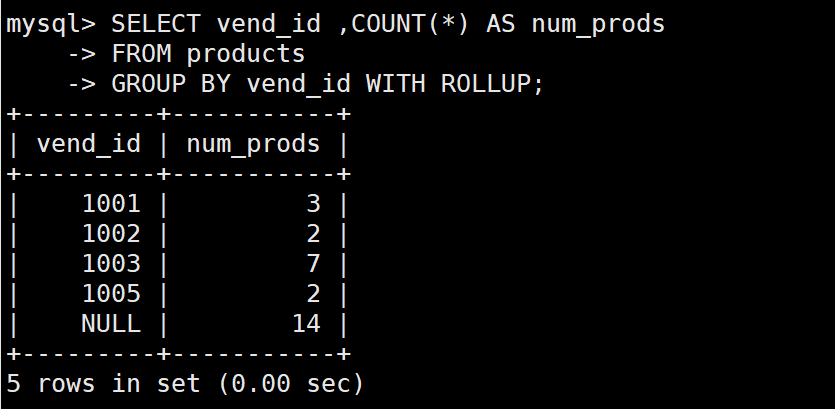
使用ROLLUP关键字
SELECT vend_id ,COUNT(*) AS num_prods
FROM products
GROUP BY vend_id WITH ROLLUP;
过滤分组
HAVING非常类似WHERE。事实上,目前为止的所学习的所有类型的WHERE子句均可用HAVING来代替。唯一的区别在于HAVING过滤分组,WHERE过滤行
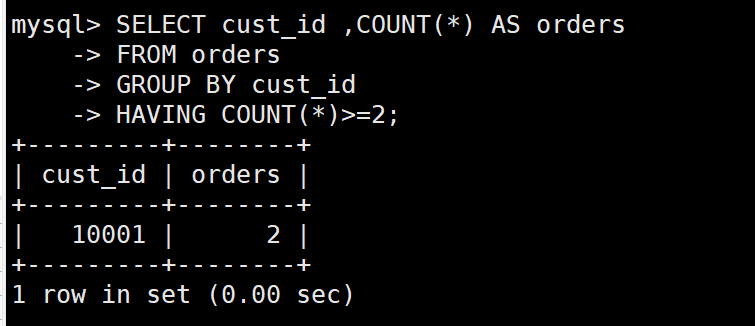
SELECT cust_id ,COUNT(*) AS orders
FROM orders
GROUP BY cust_id
HAVING COUNT(*)>=2;
:pencil:HAVING和WHERE的区别:
WHERE是在数据分组前进行过滤,HAVING是在数据分组后进行过滤。这是一个重要区别,WHERE排除的行不包括在分组中。这可能改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
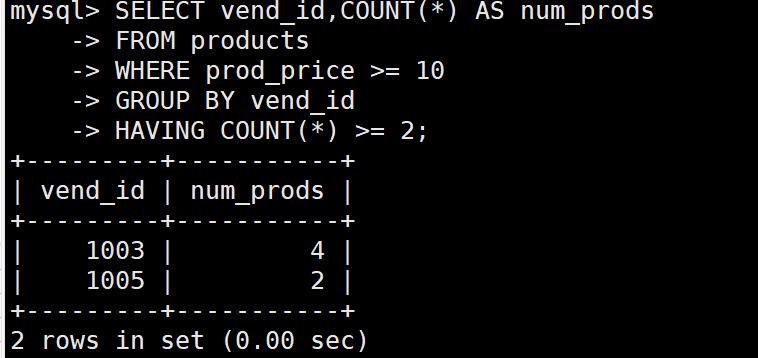
例: 列出具有2个以上,价格为10以上的产品的供应商
SELECT vend_id,COUNT(*) AS num_prods
FROM products
WHERE prod_price >= 10
GROUP BY vend_id
HAVING COUNT(*) >= 2;
分组和排序
虽然GROUP BY和ORDER BY 经常完成相同的工作,但是他们是非常不同的。
| ORDER BY | GROUP BY |
|---|---|
| 排序产生的输出 | 分组行。但输出可能不是分组的顺序。 |
| 任意列都可以使用,甚至非选择的列也可以使用 | 只可能使用选择列或表达式列,而且必须使用每个选择列表达式 |
| 不一定需要 | 如果与聚集函数一起使用列,则必须使用 |
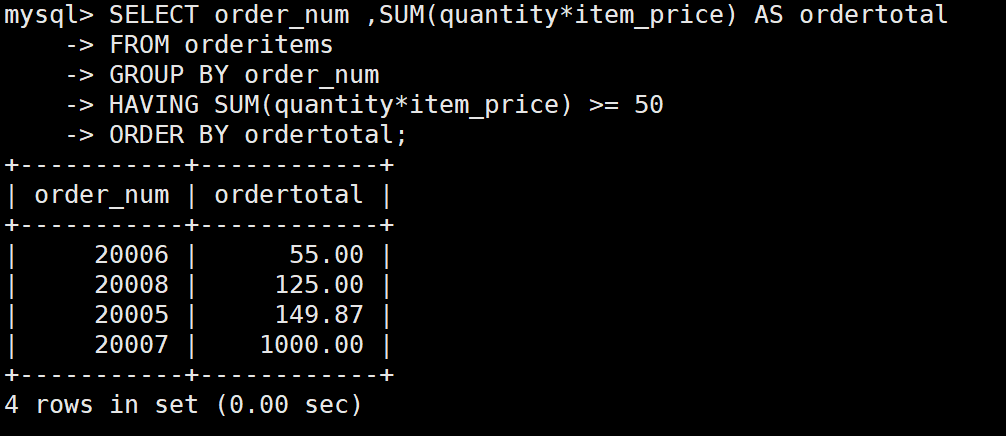
SELECT order_num ,SUM(quantity*item_price) AS ordertotal
FROM orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price) >= 50
ORDER BY ordertotal;
SELECT子句顺序
SELECT 子句及其顺序
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表中选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
使用子查询
子查询
:warning:版本要求:MySQL4.1引入了对子查询的支持,所以要想使用本章描述的mysql必须使用4.1更高的版本。
利用子查询进行过滤
例:列出订购物品TNT2的所有客户的客户信息。
SELECT cust_name , cust_contact
FROM customers
WHERE cust_id IN (SELECT cust_id
FROM orders
WHERE order_num IN (SELECT order_num
FROM orderitems
WHERE prod_id = 'TNT2') );
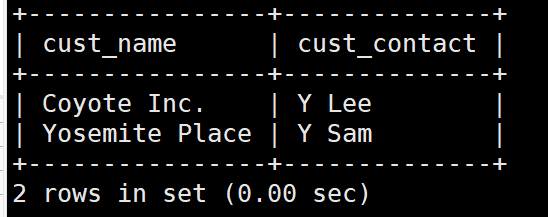
虽然子查询一般与IN操作符结合使用,但也可以用于测试等于(=),不等于(<>)
作为计算字段使用子查询
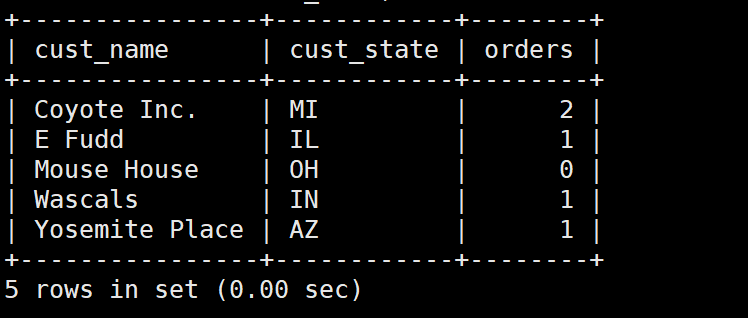
例:显示customers表中每个客户的订单总数
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM orders
WHERE orders.cust_id = customers.cust_id) AS orders
FROM customers
ORDER BY cust_name;
联结表
联结
SQL强大的功能之一就是可以在数据检索查询的执行中联结。
关系表
我们设计两个表,一个供应商表,一个商品表,供应商表的主键标识就是商品表的外键。
这样关系数据可以有效的存储和方便的处理,他的可伸缩性是要远远好于非关系数据库。
可伸缩性
能够不断适应增加的工作量而不失败,设计良好的数据库或应用程序称之为可伸缩性好。
为什么使用联结
就像上面说的,你把数据分解到多个数据表这是有代价的,如果你想要的数据在多个数据表中你要怎么办呢?
:right_anger_bubble:答案就是使用联结。
创建联结
SELECT vend_name ,prod_name,prod_price
FROM vendors,products
WHERE vendors.vend_id = products.vend_id
ORDER BY vend_name,prod_name;
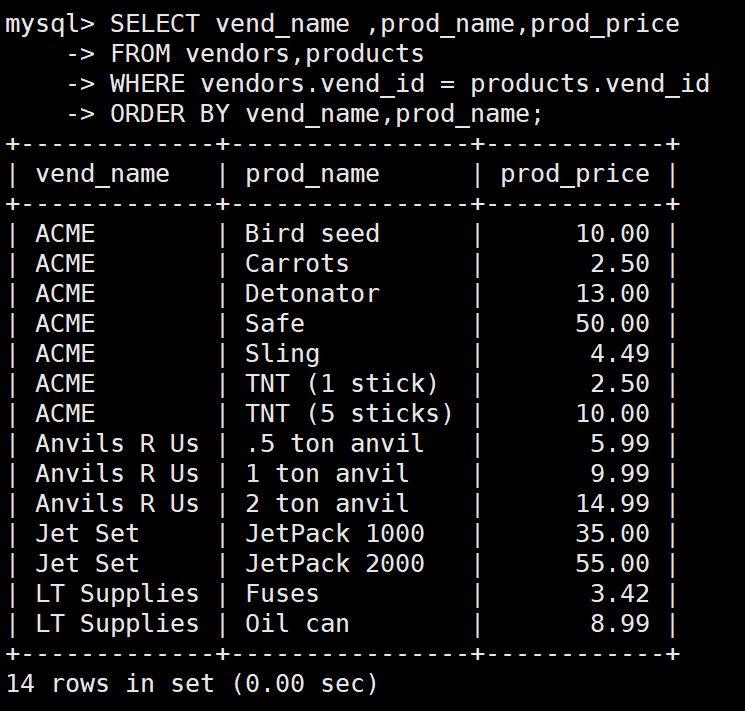
:panda_face:这里要完全限定列名,不然MySQL可处理不了这种充满二义性的WHERE语句。
WHERE子句的重要性
在联结两个表的时候。实际是将第一个表的每一行,与第二个表的每一行配对,WHERE子句作为过滤条件,他只包含哪些匹配给定条件的行。没有WHERE子句,返回的信息将是特别特别多的呀。
笛卡尔积
由于没有连接条件的表关系返回的结果为笛卡尔积。检索出的行的数目
内部联结
目前为止的所有连接都是等值连接,他是基于两个表之间的相等测试。这种连接称为内部联结。其实,这种连接是原有另外一种写法 的。(这种写法可以明确指定连接的类型)
SELECT vend_name ,prod_name ,prod_price
FROM vendors INNER JOIN products
ON vendors.vend_id = products.vend_id;
连接多个表
SELECT prod_name ,vend_name ,prod_price ,quantity
FROM orderitems ,products, vendors
WHERE products.vend_id = vendors.vend_id
AND orderitems.prod_id = products.prod_id
AND order_num = 20005;
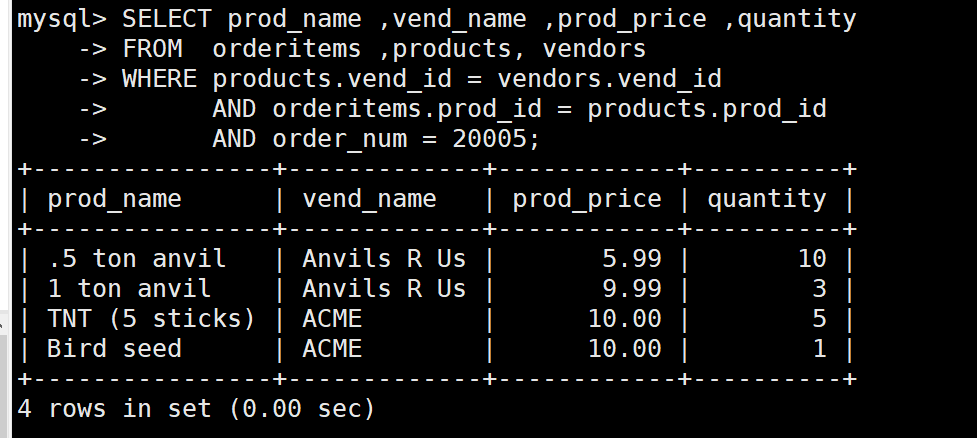
:closed_umbrella:mysql处理联结表是特别浪费性能的,所以我们要仔细,不要联结不必要的表。联结的表越多,性能的下降越厉害。
我们可以把之前的一个SELECT拿出来搞一个一题多解。
SELECT cust_name , cust_contact
FROM customers
WHERE cust_id IN (SELECT cust_id
FROM orders
WHERE order_num IN (SELECT order_num
FROM orderitems
WHERE prod_id = 'TNT2') );
我们试试联结的方法
SELECT cust_name , cust_contact
FROM customers , orders, orderitems
WHERE customers.cust_id = orders.cust_id
AND orderitems.order_num = orders.order_num
AND prod_id = 'TNT2';
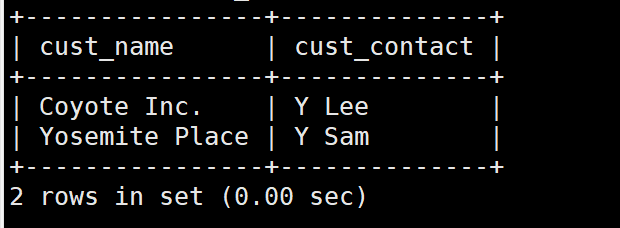
创建高级联结
使用表别名
:ice_cream: 这是我们之前使用到的表别名的例子
SELECT Concat(RTrim(vend_name),'(',RTrim(vend_country),')') AS vend_title
FROM vendors
ORDER BY vend_name;
别名除了用于列名和计算字段之外,SQL还允许给表名起列名。主要两个原有、
- 缩短SQL语句
- 允许在单条SELECT语句中多次使用相同的表
那么我们就来试一试这个别名
SELECT cust_name,cust_contact
FROM customers AS c ,orders AS o ,orderitems AS oi
WHERE c.cust_id = o.cust_id
AND oi.order_num = o.order_num
AND prod_id = 'TNT2';
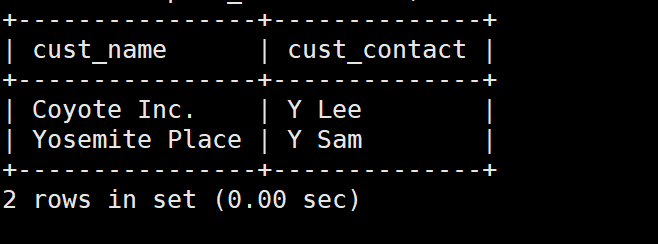
使用不同类型的联结
直到现在,我们使用的都是内部联结或者等值联结的简单联结,下面我们要继续向前通关了呀。
自联结
例:你发现某物品存在问题,因此想知道生产该物品的供应商生产的其他物品是否也有这些问题。
SELECT p1.prod_id , p2.prod_name
FROM products AS p1,products AS p2
WHERE p1.vend_id = p2.vend_id
AND p2.prod_id = 'DTNTR';
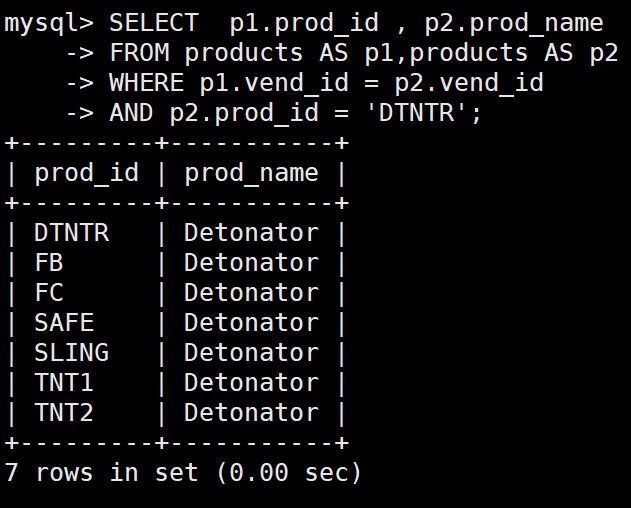
:ice_skate:使用别名,我们就可以用自联结而不是子查询。有时候会快的多。
自然联结
迄今为止,我们建立的每一个内部联结都是自然联结,很可能我们永远都不会用到不是自然联结的内部联结。
外部联结
联结包含哪些在相关表中没有关联行的行,这种类型的联结称为外部联结。
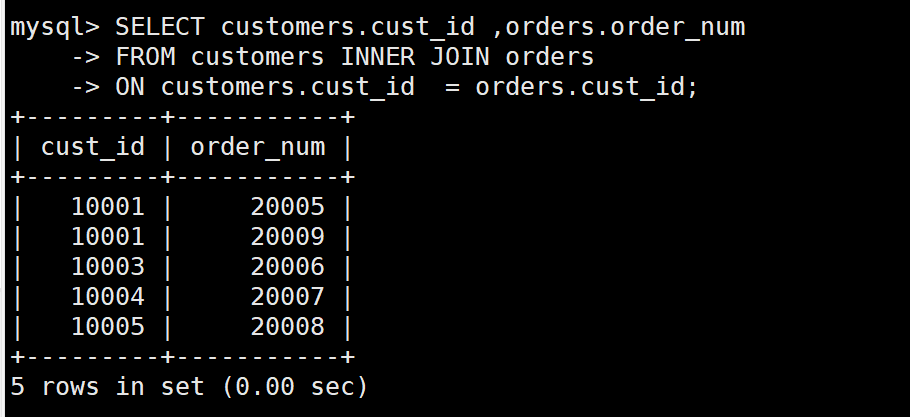
:taco: 例:内部联结:
SELECT customers.cust_id ,orders.order_num
FROM customers INNER JOIN orders
ON customers.cust_id = orders.cust_id;
:eagle:例:外部联结:
SELECT customers.cust_id ,orders.order_num
FROM customers LEFT OUTER JOIN orders
ON customers.cust_id = orders.cust_id;
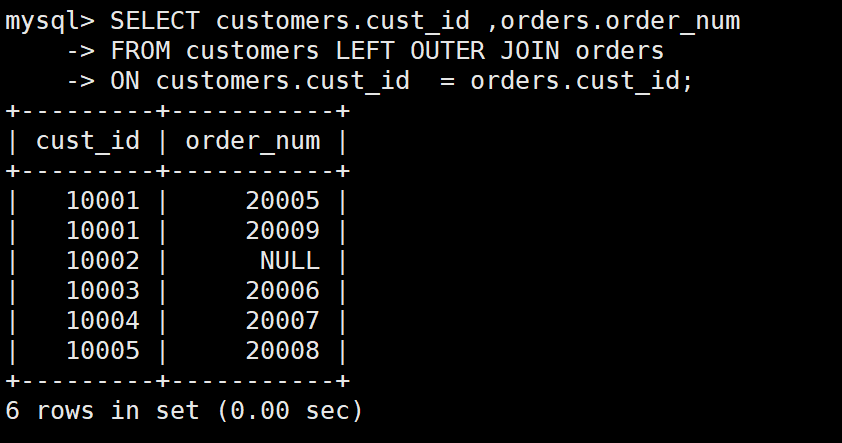
那个10002对应的null就很能说明问题,因为你是left联结,所以左边表是要包含全部内容的,所以就会有10002对应的null这样一个信息,因为你左联结了,所以左边表的所有行都要出现。
:umbrella:mysql不支持一个*=的操作符,这在其他的dbms里是十分受欢迎的。
使用带聚集函数的联结
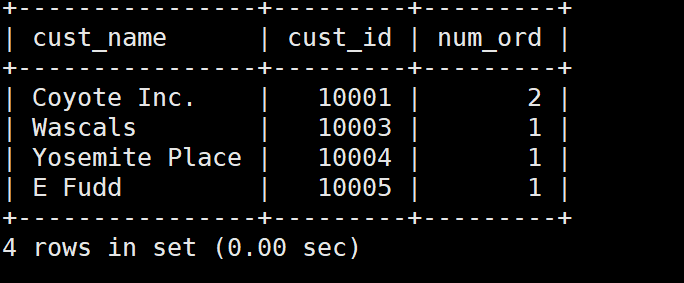
例: 检索所有客户以及每个客户所下的订单数
SELECT customers.cust_name,
customers.cust_id,
COUNT(orders.order_num) AS num_ord
FROM customers INNER JOIN orders
ON customers.cust_id = orders.cust_id
GROUP BY customers.cust_id;
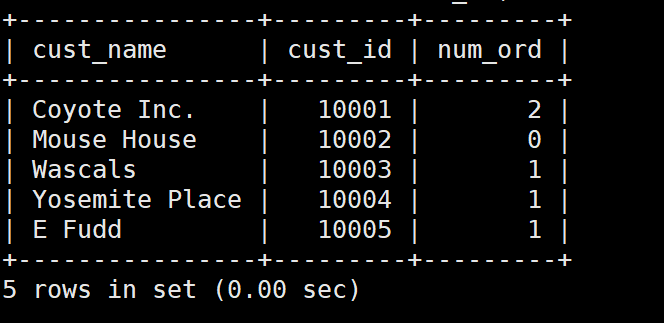
:incoming_envelope:下面我们用一用这个左连接,把那些没有下单的客户也揪出来
SELECT customers.cust_name,
customers.cust_id,
COUNT(orders.order_num) AS num_ord
FROM customers LEFT OUTER JOIN orders
ON customers.cust_id = orders.cust_id
GROUP BY customers.cust_id;
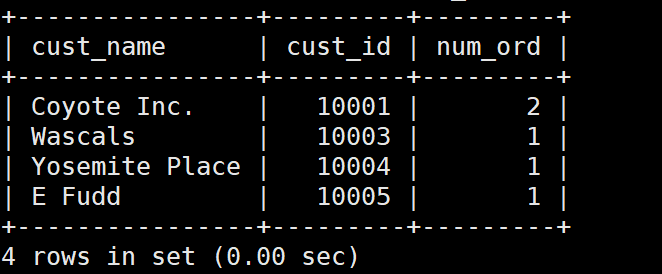
例:检索所有客户及每个客户所下的订单数
SELECT customers.cust_name,
customers.cust_id,
COUNT(orders.order_num) AS num_ord
FROM customers INNER JOIN orders
ON customers.cust_id = orders.cust_id
GROUP BY customers.cust_id;
组合查询
组合查询
MySQL也允许执行多个查询(多条SELECT语句),并将结果作为单个查询结果集返回。这些组合查询通常称为并或复合查询。
创建组合查询
可以使用union操作符来组合数条SQL查询。利用union,可给出多条SELECT语句,将他们的结果组合成单个结果集。
使用union
union的使用其实是很简单的,所需要你做的就是给出每条SELECT语句,在各条语句之间放上关键字union。
:ice_cream:你比如说你像找价格小于等于5的所有物品,还想找供应商是1001和1002生产的所有物品,当然你写两个SELECT语句必然能解决这一问题,但是那就不是一个结果集了呀,所以你可以使用union。
SELECT vend_id ,prod_id,prod_price
FROM products
WHERE prod_price <= 5
UNION
SELECT vend_id ,prod_id,prod_price
FROM products
WHERE vend_id IN (1001,1002);
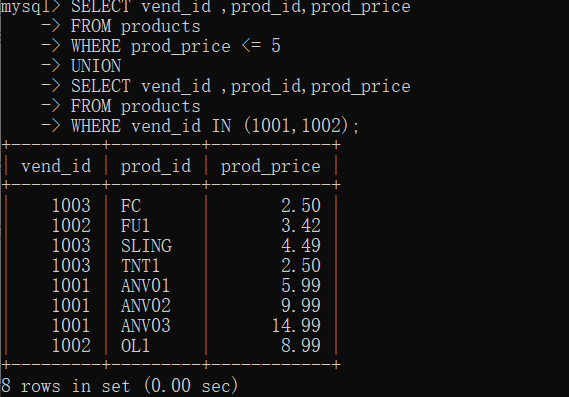
呐。union的使用是不是很简单呢。
当然上面这个例子我们使用WHERE子句加or也是可以完成这个任务的。但是对于更加复杂的过滤条件,或者从多个表中检索数据的情形,使用union可能会使处理更简单。
union规则
union的使用虽然是很简单的,但是还是有一些需要注意的地方
- union必须由两条或两条以上的SELECT语句组成,语句之间用union关键词分隔。
- union中每个查询必须包含相同的列,表达式或聚集函数(不过每个列不需要以相同的次序出现)
- 列数据的类型必须兼容:类型不必完全相同,但是必须是DBMS可以隐含转换的类型。
包含或取消重复的行
union是有一个默认行为的,就是虽然 是两个SELECT语句但是对于重复的行,它是会自动去除掉的。
既然是默认行为就能改变,我们使用union all 关键词就可以返回所有匹配行。
对组合查询结果排序
union只需要在最后的一条select语句上写order by。就可以对整个结果集进行排序。
全文本搜索

- 点赞
- 收藏
- 关注作者
评论(0)