机器学习(三十):过采样和欠采样技术

【摘要】
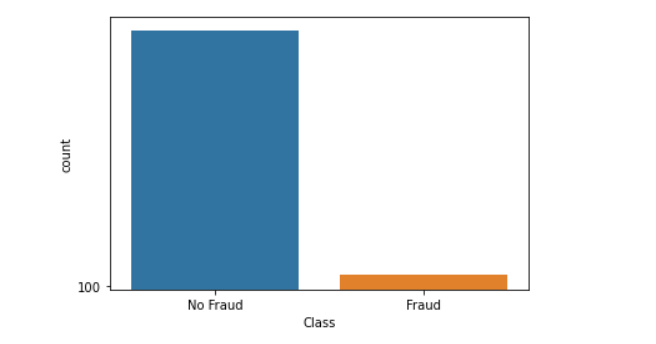
当我们的训练数据的类别分布严重偏斜时,我们面临的分类不平衡问题。不平衡可能影响我们的机器学习算法的一种方式是当我们的算法完全忽略少数类时。这是一个问题的原因是因为少数类通常是我们最感兴趣的类。例如,在构建...
当我们的训练数据的类别分布严重偏斜时,我们面临的分类不平衡问题。不平衡可能影响我们的机器学习算法的一种方式是当我们的算法完全忽略少数类时。这是一个问题的原因是因为少数类通常是我们最感兴趣的类。例如,在构建分类器以根据各种观察对欺诈性和非欺诈性交易进行分类时,数据可能有更多的非欺诈性交易。如果我们的欺诈交易数量与非欺诈交易数量相等,那将是非常令人担忧的。
文章来源: chuanchuan.blog.csdn.net,作者:川川菜鸟,版权归原作者所有,如需转载,请联系作者。
原文链接:chuanchuan.blog.csdn.net/article/details/127030141

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)