Python第二次笔记 容器的相关知识

容器的相关概念
Python中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,如:
是否支持重复元素
是否可以修改
是否有序,等
分为5类,分别是:
列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
列表
列表内的每一个数据,称之为元素
以 [] 作为标识
列表内每一个元素之间用, 逗号隔开
# 列表
name_list = ["itheima","itcast","python"]
# print(name_list)
# print(type(name_list))
# print(name_list[0])
# print(name_list[1])
# print(name_list[2])
# 1.1 查找某元素在列表中的下标
index = name_list.index("itheima")
print(index)
# 1.2 如果被查找的元素不存在,程序会出现错误
# index = name_list.index("itheim")
# print(index)
# 1.3 修改元素的值
name_list[0] = "chuanzhijiaoyu"
print(f"{name_list}")
# 1.4 在指定的位置插入元素
name_list.insert(1,"best")
print(f"{name_list}")
# 1.5 在列表中进行追加
name_list.append("黑马程序员")
print(f"{name_list}")
# 1.6 追加一批元素
mylist2 = [1,2,3]
name_list.extend(mylist2)
print(f"{name_list}")
# 1.7 指定元素的删除
name_list.pop(0)
print(f"{name_list}")
# 1.8 根据元素的值进行删除列表元素 -- 从前面到后面遍历,删除第一个元素
name_list.remove("python")
print(f"{name_list}")
# 1.9 清空列表
mylist = [1,2,3,4]
mylist.clear()
print(f"{mylist}")
# 2.0 统计列表中有多少元素
count = name_list.count("best")
print(count)
# 2.1 统计列表中有多少个元素
list_count = len(name_list)
print(list_count)
经过上述对列表的学习,可以总结出列表有如下特点:
可以容纳多个元素(上限为2**63-1、9223372036854775807个)
可以容纳不同类型的元素(混装)
数据是有序存储的(有下标序号)
允许重复数据存在
可以修改(增加或删除元素等)
元组
当我们需要在程序内封装数据,又不希望封装的数据被篡改,那么元组就非常合适了
元组相较于列表来说,不可以被更改内容,但是如果元组中的元素有列表,这个列表是可以被更改的。
# 定义元组
t1 = (1,2,3)
print(t1)
print(type(t1))
# 定义单个元素的元组
t1 = ("Hello",)
print(t1)
print(type(t1))
# 元组的嵌套
t1 = ((1,2,3),(4,5,6))
print(t1)
# 通过下标搜索取出值
num = t1[1][2]
print(num)
# index 找出下标
t6 = ("传智教育","黑马程序员","python")
num = t6.index("python")
print(num)
# count
t6 = ("传智教育","黑马程序员","python","黑马程序员","黑马程序员","黑马程序员")
num = t6.count("黑马程序员")
print(num)
# len
t6 = ("传智教育","黑马程序员","python","黑马程序员","黑马程序员","黑马程序员")
num = len(t6)
print(num)
# while遍历
index = 0
while index < len(t6):
print(t6[index])
index+=1;
# for循环遍历
for ele in t6:
print(ele)
# 元组是不可以被修改的,但是元组里嵌套的列表是可以修改的
num_list = (1,2,3,[4,5,6])
num_list[3][2] = 10
print(num_list)
元组的注意事项:
不可修改内容(可以修改内部list的内部元素)
元组的特点:
和list基本相同(有序、任意数量元素、允许重复元素),唯一不同在于不可修改。
支持for循环
字符串
尽管字符串看起来并不像:列表、元组那样,一看就是存放了许多数据的容器。但不可否认的是,字符串同样也是数据容器的一员。
字符串是字符的容器,一个字符串可以存放任意数量的字符。
字符串是不支持修改的
# 字符串
my_str = "itheima and itcast"
# 通过下标索引取值
value = my_str[2]
print(value)
# 字符串是不支持修改操作的,
# 查找idnex
index = my_str.index("and")
print(f"{index}");
# replace 旧的字符串不会被改变。只会改变新的字符串
new_my_str = my_str.replace("it","黑马")
print(f"将字符串{my_str}替换为{new_my_str}")
# split方法
my_str = "hello python itheima itcast"
my_list = my_str.split(" ")
print(f"{my_list}")
print(f"{type(my_list)}")
# strip
my_str = "hello python itheima itcast"
new_my_str = my_str.strip("")
print(f"{new_my_str}")
my_str = "111222333131hello python itheima itcast3131"
new_my_str = my_str.strip("123")
print(f"{new_my_str}")
# 统计字符串中某元素出现的次数
my_str = "hello python itheima itcast"
count = my_str.count("it")
print(f"{count}")
# 统计字符串的长度
num = len(my_str)
print(num)
序列
序列支持切片,即:列表、元组、字符串,均支持进行切片操作
切片:从一个序列中,取出一个子序列
演示对序列进行切片操作
第一个参数是开始位置,第二个参数是结束位置(不包含最后一个),第三个参数是步长,默认步长是1,这个就是连续的
# 演示对序列进行切片操作
# 第一个参数是开始位置,第二个参数是结束位置(不包含最后一个),第三个参数是步长,默认步长是1,这个就是连续的
# list
my_list = [0,1,2,3,4,5,6]
result = my_list[1:4:1]
print(result)
# tuple
my_tuple = (0,1,2,3,4,5,6)
result = my_tuple[:]
print(result)
# str
my_str = "012345678"
result = my_str[::2]
print(result)
# str -1步长 将字符串反转
my_str = "012345678"
result = my_str[::-1]
print(result)
# list -1 步长
my_list = [0,1,2,3,4,5,6]
result = my_list[3:1:-1]
print(result)
# tuple -2 步长
my_tuple = (0,1,2,3,4,5,6)
result = my_tuple[::-2]
print(result)
集合
不允许有重复的元素
# 不允许有重复的元素
# 集合是无顺序的 下标是不可以能访问的
my_set = {"传智教育","黑马程序员","itheima","传智教育","黑马程序员","itheima","传智教育","黑马程序员","itheima"}
my_set_empty = set()
print(my_set)
print(my_set_empty)
print(type(my_set))
# 添加新元素
my_set.add("python")
print(my_set)
# 移除元素
my_set.remove("python")
print(my_set)
# 随即取出一个元素
ele = my_set.pop()
print(ele)
print(my_set)
# 清空集合
my_s = {"传智教育","黑马程序员","itheima"}
print(my_s)
my_s.clear()
print(my_s)
# 取出两个集合的差集 集合一和集合二是不改变的,结果是一个新的集合,结果是集合一中有的,集合二中没有的。
set1 = {1,2,3}
set2 = {1,4,5}
set3 = set1.difference(set2)
print(set1)
print(set2)
print(set3)
# 2个集合合并为一个集合
set1 = {1,2,3}
set2 = {1,4,5}
set3 = set1.union(set2)
print(set1)
print(set2)
print(set3)
# 统计集合元素的数量
num = len(set1)
print(num)
# 集合的遍历 集合不支持下标索引
for x in set1:
print(x)
字典
字典通过一个关键信息找到另一个详细信息 key- value
key是不可以被重复的 – 字典是不支持下标检索的
# 字典 通过一个关键信息找到另一个详细信息 key- value
# key是不可以被重复的 -- 字典是不支持下标检索的
# 定义字典
my_dict1 = {
"杨彤彤":99,
"林俊杰":88,
"周杰伦":77,
}
my_dict2 = {}
print(my_dict1)
print(my_dict2)
# 从字典中基于key获取到value值
score = my_dict1["杨彤彤"]
print(score)
# 字典的嵌套
scores = {
"杨彤彤":{
"语文":99,
"政治1":11,
"历史":55
},
"周杰伦": {
"语文": 99,
"政治1": 11,
"历史": 55
},
"张子怡": {
"语文": 99,
"政治1": 11,
"历史": 55
},
}
print(scores)
# 周杰伦的语文信息
zz = scores["周杰伦"]["语文"]
print(
zz
)
# 新增/更新元素
my_dict1 = {
"杨彤彤":99,
"林俊杰":88,
"周杰伦":77,
}
my_dict1["张子怡"] = 66
print(my_dict1)
my_dict1["周杰伦"] = 33
print(my_dict1)
# 删除
score = my_dict1.pop("周杰伦")
print(score)
print(my_dict1)
# 获取字典的全部key
keys = my_dict1.keys()
print(keys)
# 字典的遍历 -- 方式一
for key in keys:
print(f"字典的key是{key}")
print(f"字典的value是{my_dict1[key]}")
# 字典的遍历 -- 方式二
for key in my_dict1:
print(f"字典的key是{key}")
print(f"字典的value是{my_dict1[key]}")
# 统计字典的元素数量
num = len(my_dict1)
print(num)
总结

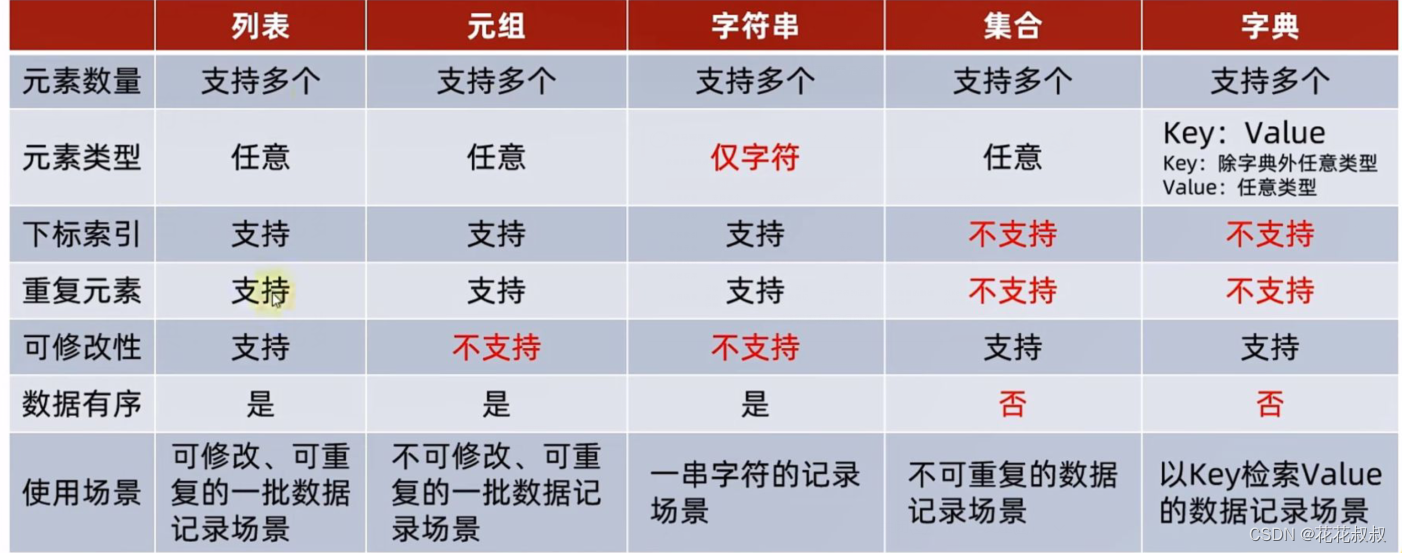
容器的通用操作
# 通用功能
my_list = [1,2,3,4,5]
my_tuple = (1,2,3,4,5)
my_str = "abcdefg"
my_set = {1,2,3,4,5,6}
my_dict = {
"key1":1,
"key2": 2,
"key3": 3,
"key4": 4,
"key5": 5,
}
# len 元素个数
len = len(my_list)
print(len)
# max 找到最大的元素
max = max(my_list)
print(max)
# min 找到最小的元素
min = min(my_list)
print(min)
文章来源: blog.csdn.net,作者:花花叔叔,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_52077949/article/details/126879532

- 点赞
- 收藏
- 关注作者
评论(0)