关于数据治理的实践与思考

如今的云音乐已经成为一款大众产品,用户每天来云音乐听歌、看评论、逛社区,这个过程中沉淀下来了海量用户数据。平台现在每天收集处理的用户日志已经达到千亿级别,整个集群处理加工使用的数据总量达到了200PB。解决这么大规模下数据存储、处理、使用中的技术问题,作为一名数据开发首先是感到兴奋,但另一方面更多的数据意味着花费更大硬件支出去做计算、存储。如何发挥数据的价值,证明这笔钱花得值,同时降本增效最大化数据使用的ROI,是我们一直以来思考并且努力去解决的问题。
从我们调研大量类似发展阶段公司的经验来看,在这个时期推动数据治理,是一条被证明可行并能带来巨大价值的道路。
那么什么是数据治理?实际上数据治理的范畴相当广泛,按照Google对于数据治理的定义,它包含了数据生命周期(从获取、使用到处置)内对其进行管理的所有原则性方法。涵盖确保数据安全、私有、准确、可用和易用所执行的所有操作,包括必须采取的行动、必须遵循的流程以及在整个数据生命周期中为其提供支持的技术。
这么一看好像我们做的很多事情都可以往这个框子里装。但同时数据治理有那么多的方向可以做,又可以从什么点入手?下面的篇幅中,我分享一些云音乐数据团队过去在数据建设中做的工作,以及近期在做数据治理方面的思路和进展,最后会整理总结下在现阶段我们眼中的数据治理体系是什么样的?
1
前期一些工作
在前面几年的工作中云音乐数据团队在数仓建设方面主要经历了几个阶段:
1.1 完善公共层建模及建立相应的设计、研发规范。
通过“任督计划”,团队重点完成了几件事情:编写整理了《云音乐数据仓库建模规范》,并在该规范基础上与杭研共建了“easyDesign”数仓模型设计系统。同时也对云音乐的数据主题域、主题域之间关系进行了系统性的梳理输出,完善了覆盖全业务的总线矩阵。以上工作的开展让云音乐的数据资产沉淀开始变得有方向,在后面的大半年内,完成了关于人、物、场景等实体的大量数据公共层建设。
1.2 数据链路治理
在完善自身的开发设计规范之外,我们总结用户使用中反馈的问题,也把一部分精力投入到上下游数据链路的治理中。其中碰到比较突出的问题是埋点质量,我们在20年初开始做了第一个埋点治理的项目,主要的目标是希望通过标准的流程和对应的平台工具把埋点的设计、开发、测试这个过程规范起来,做好事前、事中、事后的管理。音乐相关团队和杭研经过碰撞共建,讨论制定埋点流程、规范并完成系统化,埋点管理平台“EasyTracker”面世。在此基础上,数仓的小伙伴又花了大约半年的时间,把原有几千个埋点做了迁移,基本实现了埋点格式的标准化以及埋点流程的规范和可管理。
1.3 推动自助取数,发挥数据生产力
杭州研究院汪院之前提出要做到人人用数据,天天看数据。我们重点去思考了怎么解决数据最后一公里问题。在工具层面,有数很快给出了EasyFetch(自助取数)的原型,后面的一段时间两边同学基本上是背靠背在解决各个问题,优化体验。经过几轮迭代下来,EasyFetch在功能性和易用性方面均能满足业务的诉求。而我们重点思考的是怎么样把工具的价值发挥到最大,这中间的核心还是数据,要有好用的适合自助取数分析的数据模型。通过大量的贴近业务线的应用层关键数据模型建设,以及开展的以下几件事情:
明确每个指标、口径,并明确其使用方法;
加入数据首页,对每个数据模块进行使用场景介绍;
前前后后约30+场线上线下培训,针对每条业务线的运营、策划成立自助取数POPO运维群,甚至一对一解决问题。
基本上做到自助取数的业务全覆盖,整个2020年通过EasyFetch完成的自助取数超过15万次,内部用户400多人,最大日活超过100人。
2
数据治理三件事
前期几方面的工作下来可以说解决了阶段性的问题,进入21年云音乐启动了IPO,整个21年分析师团队和数据开发花了大量时间产出各类投资人关注的数据、指标、报告。同时业务方在更大的业务目标牵引下,有了更多、更精细化的运营动作,随之而来的又是大量的分析、取数需求,更多的数据模型建设需求,还有更快速的响应时效要求。
2021年12月云音乐顺利上市,团队很好的完成了IPO数据项目。下个阶段,如何做得更好?数据建设、数据治理最终是要服务于业务发展目标。下个阶段团队核心的目标是要能支持业务挖掘增量、运营存量,实现更精细化的运营。所以在数据的生产端,我们提出了要建立数据的精益生产体系,为业务提供统一、易用、准确、稳定的数据仓库的目标。

在已有数据建设的基础上要实现这个目标,有赖于开展更有效、体系化的数据治理,其中我们把质量治理、资产化、降本增效作为22年工作的重点目标。通过吸收已有的数据治理方法论(如DAMA)和业内公司的一些好的实践经验,展开了大量工作。
2.1 质量治理
很多人会问,你们做了这么久的数仓为什么还在抓质量问题?数据建模的设计、开发标准化是不是已经解决了这个问题?我的回答是:魔鬼在细节。就像每个汽车生产企业,对于车辆的生产过程,基本上也是标准化的,但丰田的质量就要比发明标准化流水线的福特更好。核心还在于对生产过程更细致的拆解和更有效的管理。所以质量管理是一个永无止境的问题,针对现阶段的目标,我们重点从制定质量标准、强化规范执行、优化平台工具几方面去开展工作。
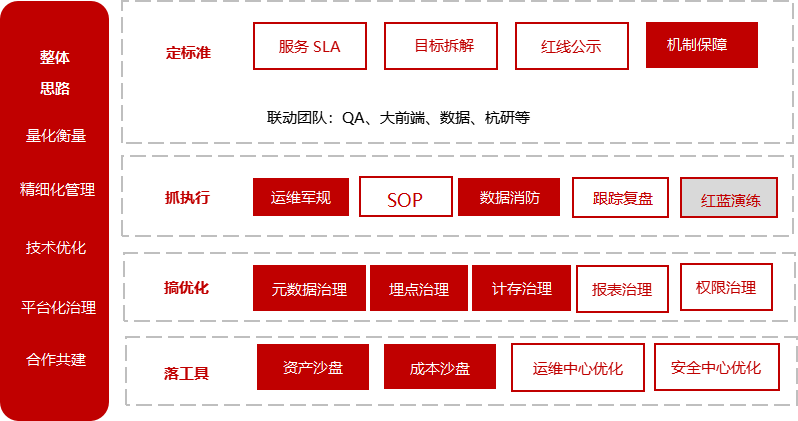
上图是我们针对质量稳定性拆解需要做的事情,而每一个工作又可以细化出一个专项甚至几个。
以元数据中心为例:作为定义数据的数据,元数据帮助我们更好的理解和刻画数据本身以及反应数据与数据的准确关系,是数据治理的基础。另一方面,元数据本身也是一种数据,也存在缺失、不准确等等问题,也需要治理。在云音乐的数据治理工作中,我们把元数据梳理及可获取列为优先的工作开展。

上面的表格列了具体的分类细项和我们推动解决的一些问题,中间和有数一起花了一个季度的时间,通过双周迭代的方式最终做到元数据可获取,完整性准确性达到了我们治理的要求,也为我们后续的数据治理打下了一个坚实的基础。
再以执行侧的任务运维为例,生产环境的稳定性和安全对每个数据团队来说都是头等大事。曾经有一份统计,工业化生产过程中大部分安全问题来自于人,具体到杜邦的数据是96%。作为技术人员我们总是期望开发更好的工具去规避风险,而往往忽视了人的能动性。这并不是说把质量、安全这件事情简单转化为对人的考核。当一个人不知道应该做什么事情去达成目标时,他也没法为这件事情负责。团队前期花了非常多的时间去整理值班运维手册,把信息同步、问题告警、原因分析、问题升级、记录&复盘等等环节做成了SOP,同时制定了最重要的两条军规,(1)生产无小事”——再小的生产问题都要重视。(2)“哪里来的问题回到哪里去”——有始有终,最终处理结论一定要同步到问题开始的地方。一段时间下来执行效果显著,今年上半年,整体任务破线率下降了60%,另一个重要的指标,线上修复时长降低了80%,这代表数据问题得到了更快速的处置。其他每个细项的工作,限于篇幅不再一一展开介绍,有机会单独整理分享。
2.2 资产化
数据资产化的前提是数据成为生产要素,核心是要在生产中被使用且带来价值,对于数仓建设来说就要解决可用、易用问题,同时要解决数据与业务价值关联性的问题。而这些问题是否解决了,解决的程度如何需要有明确的标准来衡量。虽然我们每天在与各种指标打交道,但对于自身数据建设,我们在量化评估指标体系这件事情上思考是不足的。如何准确快速地回答“你们的数仓建得怎么样?”这类问题经常困扰我们,如果把它当做一道证明题去回答,可能需要从几个方面阐述:首先介绍下我们数仓整体的设计规范是什么样的,从业务过程梳理到标准业务总线矩阵输出,再到具体模型的设计遵循哪些原则和范式。然后可能会贴一张大图,阐述下基本的分层,业务线的划分等等。或者再补充下我们已经建了多少个表,事实表有多少,维表有多少等等。或者再从价值层面做补充,通过一些show case去证明数据的magic power。
实际情况是提问的人可能并没有那么耐心花一个小时去听,然后还需要自己去判断得出结论。对于最终用户来说什么样的设计规范和生产流程真的是他们最关心的吗?显然不是。所以最近的一段时间我们反思了过去的一些不成功经验,也吸收了很多业内好的实践,提出了新的用户视角的标准来衡量数据仓库建设的现状。即“三度模型”,从建设进度、资产健康度、业务价值度这几方面制定了量化的目标来定义建设水平,并且从这些目标出发制定了数据资产化的整体规划。

在完成上述目标的过程中,团队也逐步摸索总结出一套工作的方法论(如上图),从制定相应的标准,到通过流程和工具完善治理能力,再到与相关方建立渠道持续运营,三板斧下来,拿到结果变得可以预期。经过一段时间持续的沟通(安利)和讨论,各业务团队的用户逐渐对这套标准建立了共识。
少了长篇大论做证明题,而是定期把各项达成共识的指标透明化出来,结合结果做分析输出,沟通成本变低了!对用户来说,交付结果更可追踪可预期,对数据团队来说工作的努力、拿到的结果也更容易从数据层面来体现。
就以资产复用率为例,经过大半年的模型重构,以及对老模型的逐步下线(累计下线2.4万张表),我们的数据资产复用率从30%,直接提升到55%,这表示我们的数据使用效率上得到了接近一倍的提升,同时这个数据与业内工作进行比较也看到目前云音乐数据资产整体的复用率在一个比较健康的水平,未来半年内我们也有信心可以提升到比较先进的水平。
2.3 降本增效
近期大环境的影响让很多公司感受到“寒气”,在业务面临多重压力,“降本增效”显得尤为重要:通过降本增效提升企业生存耐力,为未来更快增长积蓄潜力,成为一种战略手段。云音乐数据团队的降本增效工作大致是从三个方面展开:
(1)成本
首先要算清大帐,关于这一点要感谢有数的同学,虽然每个月的账单都让人看得心惊肉跳,但是整体的收费情况,每个服务类目的支出以及对应的变更日志都列的非常清楚。使得我们可以把精力花在盘点各个服务水位上。有了总的和分类目的支出,以及各服务的水位整体情况,基本上可以对大帐有个清晰的概念,如下表(音乐离线集群部分盘点):
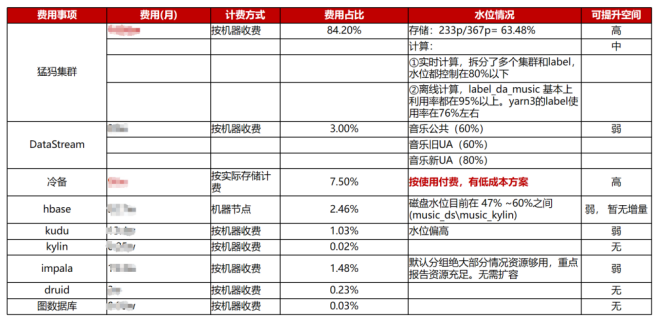
有了成本大图,需要进一步把成本下钻拆解到业务线、团队以及个人,拆解的过程中也碰到一些诸如任务归属责任人不清楚,血缘数据缺失等等问题,更进一步证明了元数据在数据治理中的重要性,好在我们和有数的同学花了一个季度的时间终于把元数据的问题搞定,做到了可用并且可视化。
(2)计划
这里简单列一下我们整体的计划大纲,确定了几个重点:1.前面介绍到的先搞定元数据,让治理结果有数可依,治理过程精准把控。2.优先解决占成本大头的存储和计算的优化问题。
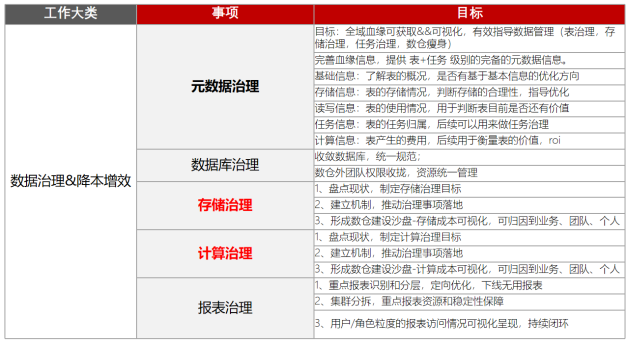
除了大纲确定具体方向和专项目标以外,具体到推进过程中我们从正反两个思路去解决一个一个问题:正推,阵地战,对于那些可以通过元数据的扫描梳理出治理目标,推进相对容易,可以按照迭代推进,逐步拿到结果。反推,攻坚战,很多资源消耗产出链路是正常的,对应着正常的下游报表和功能。但经过多年的迭代,很多数据和功能已经不看了或者有更好的替代,需要去从最终的使用情况盘点和推进解决,这个过程中需要依赖数据,也要有重点地搞。甚至,在沟通中还需要那么一点战斗精神...
(3)优化
作为码农团队,降本增效只靠运动式大扫除短期内能拿到确定性结果,长期做肯定不行,技术优化还是第一生产力。举个例子,音乐业务优化结果比较显著的一块是通过和有数合作的Spark3+Z-order+Zstd改造优化拿到的。Spark3发布以来团队一直在关注AQE等重要特性,希望通过优化大量的SQL执行计划,提高整体集群Spark作业的性能和稳定性。而杭研的同学在Spark方面有大量深入的研究,经过调研除了AQE,也推荐我们通过引入Z-order提升文件压缩率,从而提升整体的存储资源效率。上半年经过多轮迭代、测试以及任务改造,我们完成了:
hive任务升级spark3.1,升级任务266个,升级任务消耗资源占比95%,优化之后的执行耗时降低60%以上,优化之后计算资源费用减少60%;
spark2升级spark3,完成631个spark2任务的升级,升级任务消耗资源占比90%,优化之后资源节省28.71%,性能提升52.07%;
spark3.1+zorder+gzip专项治理:升级优化170个,节省存储占比68%,节省日均存储55T,折合存储成本798.3W/Y。
计算资源方面,经过一系列的升级动作,集群的稳定性在较长的一段时间内保持稳定,给后续的基线530项目(核心产出提前到每天5:30)提供了较好的保障。
存储方面,日增趋势放缓,由原来的日增170T,下降到日增50T(有一部分来自生命周期管理效果)。
3
一些体系化思考
近期一段时间的数据治理工作坐下来,简单总结下我们所做的事情,大概可以以一张图来简单概括:
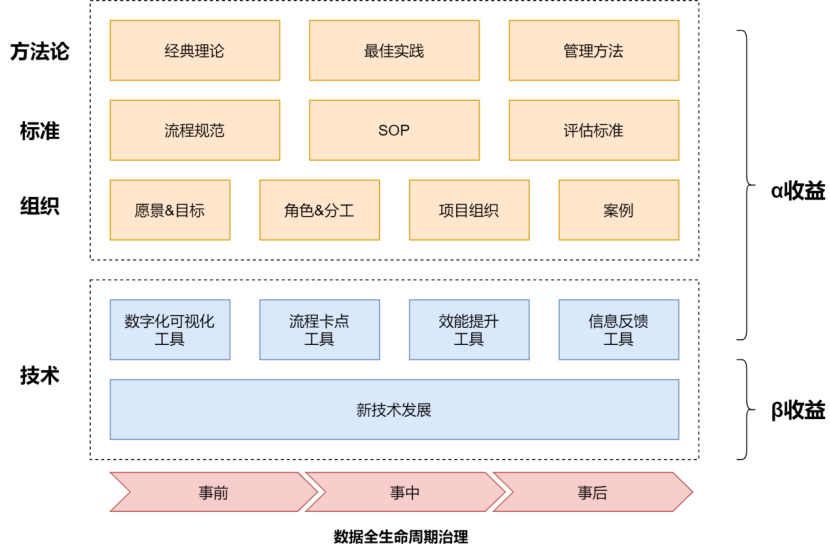
(1)方法论:没有理论指导的实践是盲目的,数仓建模、数据治理,都已经沉淀了较为成熟的理论体系,无论是熟知的DAMA数据管理知识体系,还是业内各团队的专家对于数据治理的总结思考都为我们提供了非常好的理论和方法指引。
另一方面这些方法本质上是工具箱,不同团队的发展阶段、业务诉求不同,对应的数据治理方向和目标也就不同,必然对应着使用不同的工具去解决问题。
(2)标准:我们现阶段在云音乐做的数据全生命周期治理,相应的标准化是贯穿在事前、事中、事后全过程的。事前建立共识、明确的可量化的目标,最好签字画押。比如我们的质量稳定性SLA标准、数据资产三度评估标准、资源水位量化评估标准等,事中要细化每一个执行环节制定标准动作,包括流程的建立,以及在每个节点上的SOP(比如我们的运维军规、研发红线),做到执行者有章可循。事后也要结合事前的目标,用评估标准来衡量完成的质量和进度,开始下一个循环。
(3)组织:数据治理一定是服务于业务的愿景和战略,并不是一个脱离具体环境的万金油任务,数据治理解决什么问题需要被明确定义。在云音乐,业务发展进入成熟期,精细化运营对取数看数质量、易用性等诉求以及整体降本增效的大背景促使我们提出了质量、资产化、降本增效三方面的目标。
关于执行以及角色分工,我们认为数据治理应该是一个融入生产过程,全员参与的事情。不建议通过增加新的独立岗位,或者设立委员会的方式去推动数据治理的落地,而是通过明确职责分工,落实主体责任来进行。另外,为了防止数据团队既当裁判员又当运动员,整个体系增加对抗性来保持稳定运行,我们在很多治理过程是通过与兄弟团队合作来完成。比如在质量稳定性目标中,虽然sla标准整体由数据团队来牵头,但过程的考核监督、报告、复盘是由QA团队来完成。
(4)技术:对于平台化工具,我们坚持的观点是先有具体问题,再有对应流程规范、最后才是工具。我们虽然有平台开发小组,整体工作并没有追求大而全,更多还是以实用为主,无用的轮子也少很多。
以上可以认为是数据治理中我们可以拿到的α收益,但有时新技术的创新、演进可能超出我们的想象,所以拿到新技术发展的β收益,要求我们必须保持对新技术的跟踪同时经常与杭研公技团队做技术交流。这是一件必须要坚持做的事情,过去的工作中带给我们非常大的收益,这里也感谢有数团队对我们的支持。
进群方式:请加微信(微信号:dataclub_bigdata),回复:加群,通过审核会拉你进群。

(备注:行业-职位-城市)
公众号推送规则变了
点击上方公众号名片,收藏公众号,不错过精彩内容推送!






文章来源: dataclub.blog.csdn.net,作者:数据社,版权归原作者所有,如需转载,请联系作者。
原文链接:dataclub.blog.csdn.net/article/details/127020260

- 点赞
- 收藏
- 关注作者
评论(0)