【每日一读】CoRGi: Content-Rich Graph Neural Networks with Attention


简介
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力💪
【每日一读】每天浅读一篇论文,了解专业前沿知识,培养阅读习惯(阅读记录 仅供参考)
论文简介
原文链接:https://dl.acm.org/doi/10.1145/3534678.3539306
会议:KDD '22: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (CCF A类)
年度:2022年8月14日
ABSTRACT
目标域的图形表示通常将其投影到一组实体(节点)及其关系(边)
然而,这样的预测往往会遗漏重要而丰富的信息
例如,在缺失值插补中使用的图形表示中,表示为节点的项目可能包含丰富的文本信息
然而,当使用图神经网络 (GNN) 处理图时,这些信息要么被忽略,要么被汇总为用于初始化 GNN 的单个向量表示
为了解决这个问题,我们提出了 CoRGi,这是一种 GNN,它在邻居的上下文中考虑节点内的丰富数据
这是通过为 CoRGi 的消息传递赋予每个节点内容的个性化注意机制来实现的
通过这种方式,CoRGi 为项目内容中出现的单词分配用户项目特定的注意力分数
我们在两个边缘值预测任务上评估 CoRGi,并表明 CoRGi 在对现有方法进行边缘值预测方面做得更好,尤其是在图的稀疏区域上
1 INTRODUCTION
图神经网络(GNN)在深度学习和最近的推荐应用中取得了巨大成功[56]
GNN 允许我们对复杂的图结构数据进行建模,但输入图的构建通常是对建模域数据的部分、有损投影
例如,书籍推荐任务的图形表示可以将书籍和用户表示为节点,并将有价值的边作为推荐
但是,每本书/节点都包含丰富的半结构化内容,例如结构化为章节、表格等的文本,可以提供有价值的信息,有助于提高推荐的性能
将节点内容合并到 GNN 中的一种常用方法是将其“汇总”为单个向量表示(嵌入),并将该向量用作初始节点嵌入
这通常包括使用编码器模型(例如词袋模型或转换器)从整个句子或文档中计算单个向量表示
然而,鉴于这些向量的大小与原始内容相比相对较小,这样的表示是次优的
这在自然语言处理 (NLP) 中被广泛接受,而不是将输入表示为单个向量/嵌入,而是使用完整输入
例如,编码器-解码器模型在给定模型上下文的整个输入上采用各种形式的注意力机制,而不是将其表示为单个向量
例如,在 NLP 文本摘要 [57] 中,解码器处理输入文本中所有单词的编码表示
以同样的方式,我们需要更好的方法让 GNN 捕获它们消费并旨在表示的图的节点内的内容
大多数现有的 GNN 将任何内容“汇总”为单个向量,并将其用作初始节点状态
为了改进这一点,我们提出了 CoRGi(具有注意力的内容丰富的图形神经网络),这是一种消息传递 GNN [8],它在每个消息传递步骤中结合了对丰富节点内容的注意力机制
这使 CoRGi 能够有效地了解图形的结构和每个节点内的内容。
CoRGi 的一个有趣应用是边缘值插补,例如,在协同过滤中使用 GNN 进行缺失值插补 [56](图 1-左)
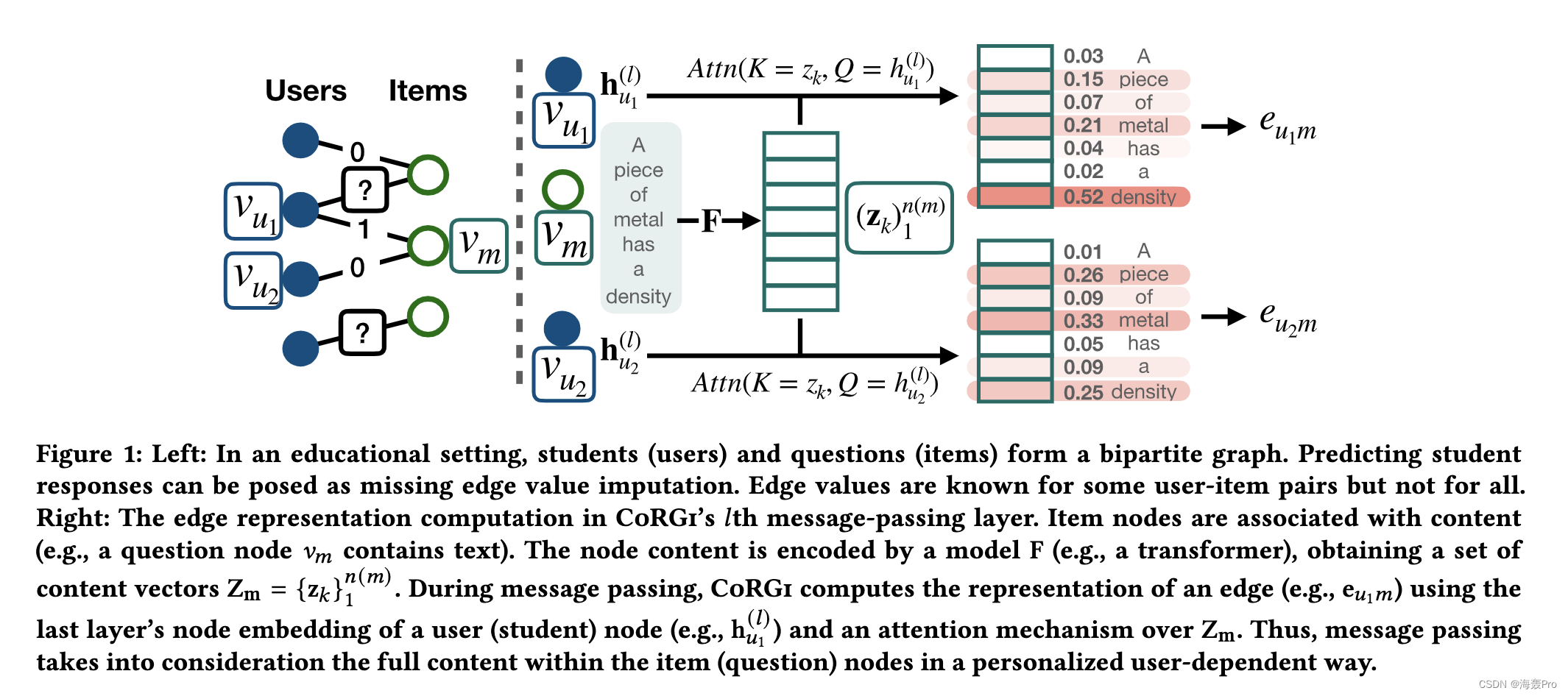
例如,在学生问题答案的数据集中,每个问题都与丰富的文本描述相关联
在这种情况下,基于图形的表示捕获学生和问题(用户响应)之间的丰富交互,但忽略项目中的重要内容(问题的文本描述;图 1 中的文本)
CoRGi 通过一种基于注意力的个性化消息传递方法将两种信息源结合起来,该方法计算项目内容的特定于用户-项目对的表示
此外,与基线相比,CoRGi 实现了更好的性能,特别是在用户项目图的稀疏区域,例如很少回答的问题
我们相信 CoRGi 处理用户响应数据和内容的混合方法在广泛的协同过滤和推荐系统以及 GNN 的其他用途中是有益的
总之,我们的贡献是
- CoRGi:一种消息传递图神经网络,在消息计算过程中结合了对节点内容的注意机制。
- CoRGi 用于用户项目推荐的专业化
- 对两个真实世界数据集的广泛评估显示 CoRGi 比现有方法提高了用户响应预测性能,特别是对于评分很少的项目或内容起关键作用的稀疏图表
2 CORGI ARCHITECTURE
3 RELATED WORK
CoRGi 是 GNN 和机器学习模型的交叉点,用于缺失值插补,强调了在评估部分(第 4 节)中用作基线的相关工作
缺失值插补是用预测值填充先前未知条目的任务
对于两个异构组,即用户和项目,任务通常简化为矩阵完成 [1],使用大量协同过滤和矩阵分解方法 [4, 19, 23, 26, 28, 39] 和基于深度学习的方法 [41, 48, 55] 多年来研究
深度矩阵分解 (DMF) [54] 通过多层感知器 (MLP) 提供此信息,直接使用输入矩阵。对变分自动编码器 (VAE) [17] 的扩展,部分 VAE 模型 (PVAE) [25] 是一种基于编码器-解码器的方法,用于估算缺失值
相比之下,CoRGi 通过消息传递中的注意力以特定于用户项目的方式利用额外的内容信息
在过去的几年中,人们尝试对图进行建模 [9、32、44]
- Kipf 和 Welling [18] 提出了学习节点潜在表示的图卷积网络 (GCN),以及其他方法 [5, 21, 29, 40]
- GraphSAGE [11] 扩展了 GCN,允许模型在图的一部分上进行训练,从而实现归纳学习
- 提出了跳跃知识(JK)网络[53]和图同构网络(GIN)[52],通过对不同层的表示及其先前的表示采用新的聚合方案来提高 GNN 的表示能力
- 对于推荐系统,图卷积矩阵完成 (GC-MC) [2] 是 GCN 的一种变体,它明确使用边缘标签作为输入来建模消息,与其他方法相比,GC-MC 采用单层消息传递,并且标签被赋予了单独的消息传递通道
- GRAPE [56] 在 GCN 上使用边缘嵌入,因为在推荐系统中,边缘属性携带关键信息,例如边缘标签,因此需要更加强调。并采用应用于所有消息传递层的边缘丢失。
- LightGCN [12] 设计了一个 GCN 框架,简化或省略了不利于推荐的构造,例如特征变换和非线性激活,并且更加强调邻域聚合
与之前在推荐系统中提出的 GNN(例如 LightGCN [12])相比,CoRGi 利用节点的丰富内容信息来对投影到图的目标域进行建模
与利用节点内容信息的现有 GNN 模型相比,CoRGi 在 GNN 的消息传递中对节点内容采用注意力机制,并计算用于更新边缘嵌入的用户项目特定注意力
在 NLP 中,(self-)attention 用于关联给定序列 [22, 30, 46] 的单词或单词标记
许多 GNN 模型 [7, 13, 15],其中图形注意网络 (GAT) [47] 是一个流行的例子,使用注意机制来允许目标节点区分来自源节点的多个消息的权重以进行聚合
我们注意到 CoRGi 与 GAT-like 模型正交
尽管 CoRGi 使用了注意力,但它是在每个节点内的内容上,而不是每个节点的邻居(如在 GAT 中)
在未来的工作中,可以将 CoRGi 机制嵌入到类似 GAT 的 GNN 公式中。
4 EVALUATION
评估 CoRGi
- 首先,我们专注于一个合成数据集,该数据集说明了与现有方法相比,注意力机制如何考虑可用节点内容
- 然后,我们专注于两个真实世界的推荐数据集,表明 CoRGi 在大量强大的基线上有所改进
模型配置
我们使用 𝐿 = 3 CoRGi 与节点嵌入和边缘嵌入基数 C (𝑙,ℎ) 和 C (𝑙,𝑒) , ∀𝑙 ∈ {1, . . . , 𝐿} 设置为 64,以及公式中预测读出层的大小。 8 设置为 256。我们将节点嵌入初始化为随机值,并分配训练标签值以初始化边缘嵌入。 我们使用均值池进行聚合(即等式 2 的 Agg 函数)。 对于非线性激活,我们使用 LeakyReLU 进行注意力系数计算(方程式 6、7),其斜率为 0.2,与 GAT 中一样,其余部分使用 ReLU。
训练配置
对于所有实验,我们使用 Adam [16] 和 0.001 的学习率使用反向传播 [37] 训练 CoRGi 和基线方法。我们对验证损失采用提前停止,训练集、测试集和验证集以 8:1:1 的比例拆分
我们对二进制值使用二进制交叉熵损失 (BCE),对序数值使用均方误差 (MSE)
我们在消息传递层、预测 MLP 以及边缘上应用 dropout,相对于验证集性能,选择率从 {0.1, 0.3, 0.5, 0.7} 中选择
对于基线,参数设置如下:
- 1)当比较模型的设置与 CoRGi 的设置重叠时,例如消息传递层数或学习率,我们使用与 CoRGi 相同的配置
- 2)对于比较模型特有的参数设置,我们按照原论文中公开的设置
- 3)当原始设置不适用于所使用的数据集或我们的训练环境时,我们选择具有最佳验证性能的那些。
5 CONCLUSION
我们提出了 CoRGi,这是一种 GNN,它在消息传递机制中使用注意力紧密集成节点内容
使用节点内容(例如文本)允许我们在建模域中捕获丰富的信息,同时利用数据的结构化形式。这在图的稀疏区域中尤为明显。
将来,人们可能会研究文本与项目和用户节点相关联的文本增强图
CoRGi 可以自然地在此设置上运行,因为个性化注意机制考虑了方向性,并且从用户到项目浮动的消息可能不同于从项目浮动到用户
此外,另一个潜在的未来方向是处理文本之外的内容元数据:例如,图像。
最后,我们希望 CoRGi 为社区提供灵感,以更仔细地研究将数据“投影”到适当的基于机器学习的表示中的方式
虽然图是通用结构,但它们仍然是目标域的有损投影,并且通常可以获得额外的(元)数据。在现实世界问题中考虑这种丰富的(元)数据模式的定制方法有机会提高预测性能并提供有形的用户价值。
读后总结
mark一下
关注点:CoRGi 使用了注意力,但它是在每个节点内的内容上,而不是每个节点的邻居(如在 GAT 中)
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

文章来源: haihong.blog.csdn.net,作者:海轰Pro,版权归原作者所有,如需转载,请联系作者。
原文链接:haihong.blog.csdn.net/article/details/126986046

- 点赞
- 收藏
- 关注作者
评论(0)