2022国赛C题解析

【摘要】
数据
读取玻璃文物的基本信息数据设置索引:
问题一
风化与类型、纹饰和颜色的关系
分别读取: 做相关性分析即可: 分析结果: 可视化下就丰富了论文了。
统计规律
做好可视化来描述...
数据
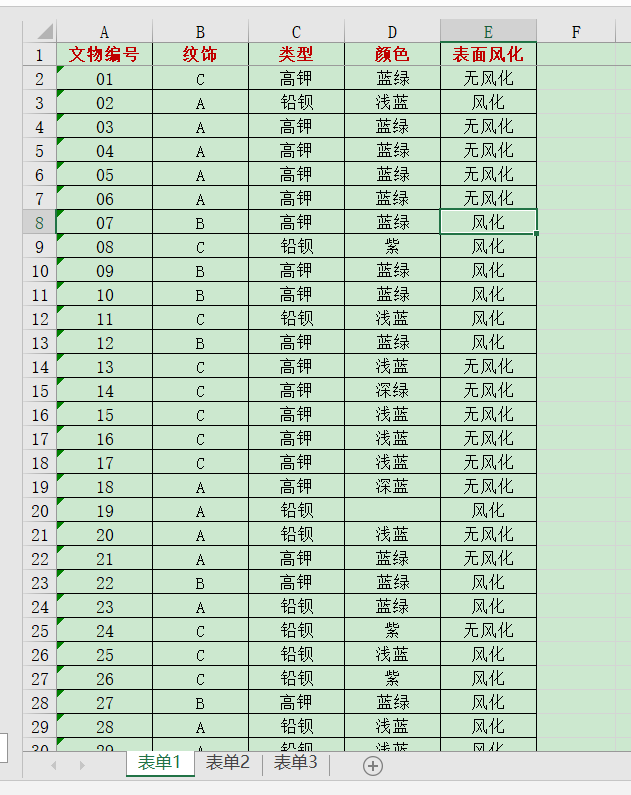
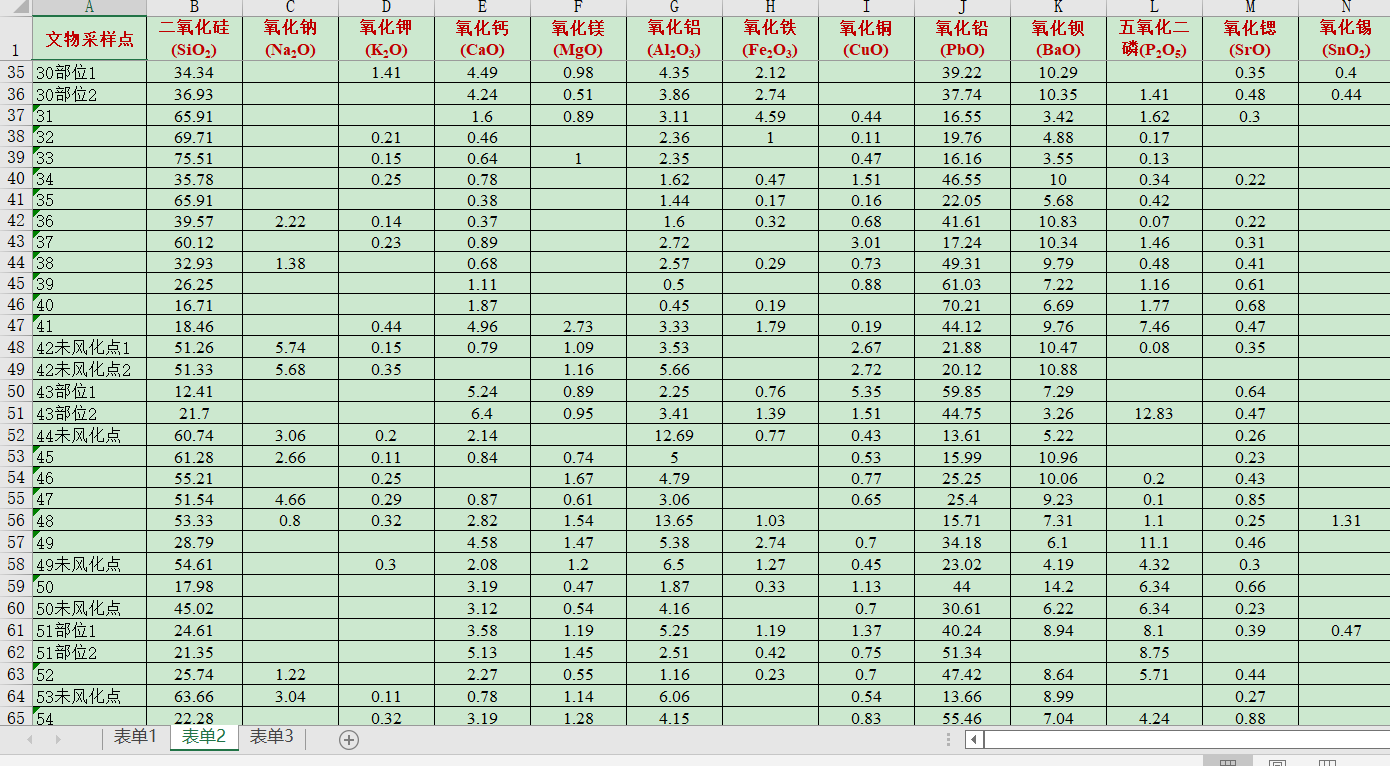
读取玻璃文物的基本信息数据设置索引:
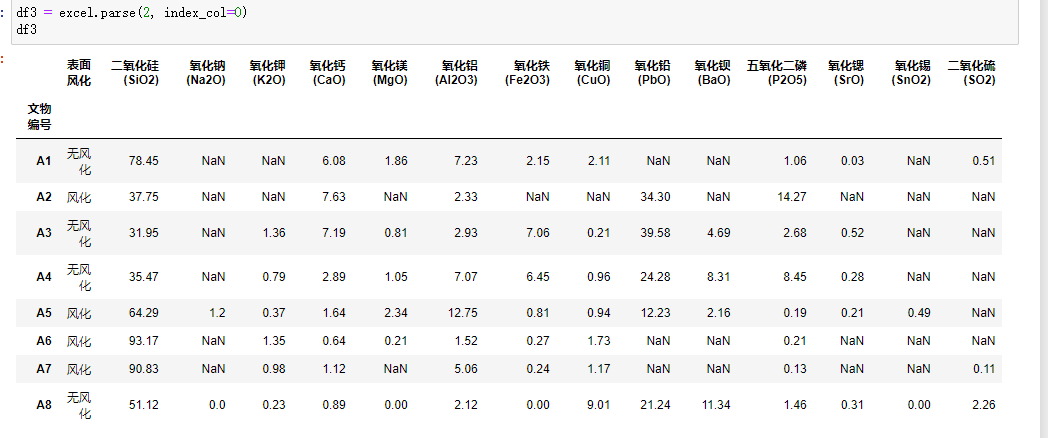
问题一
风化与类型、纹饰和颜色的关系
分别读取:
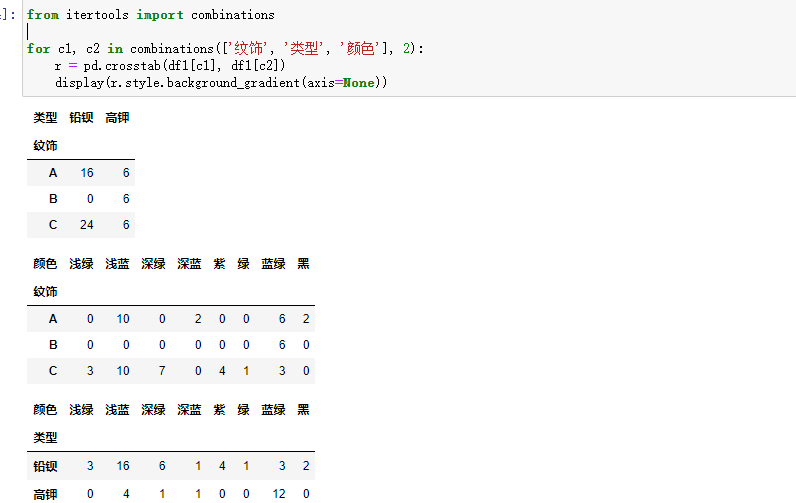
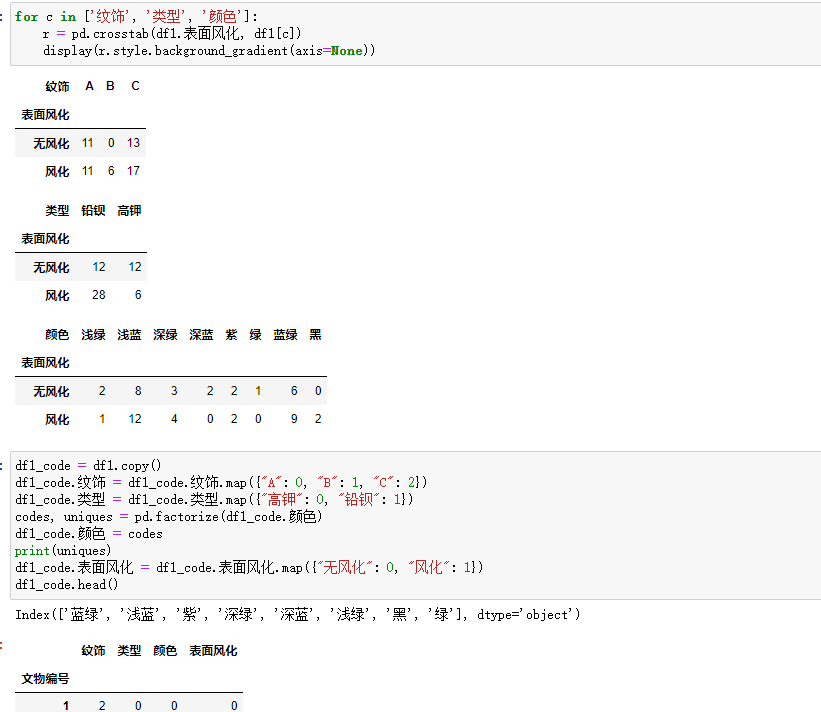
做相关性分析即可:
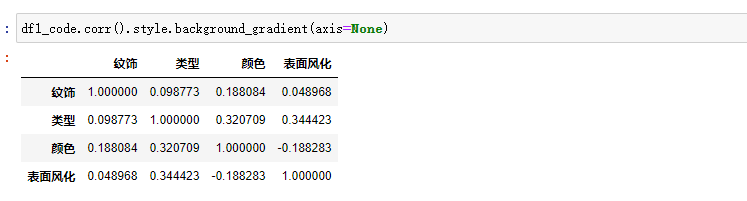
分析结果:

可视化下就丰富了论文了。
统计规律
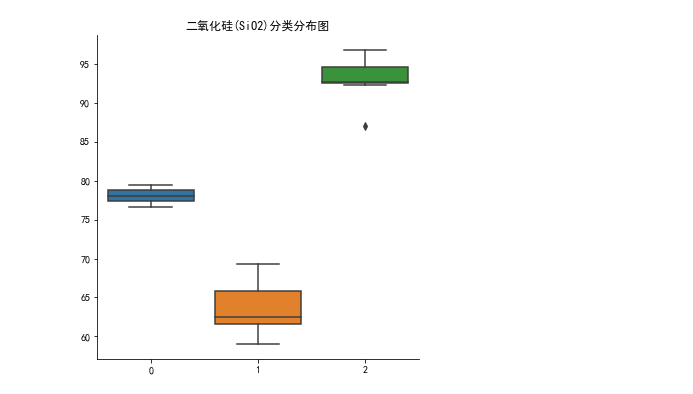
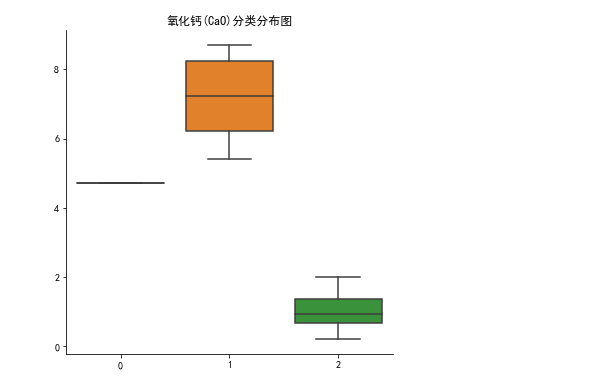
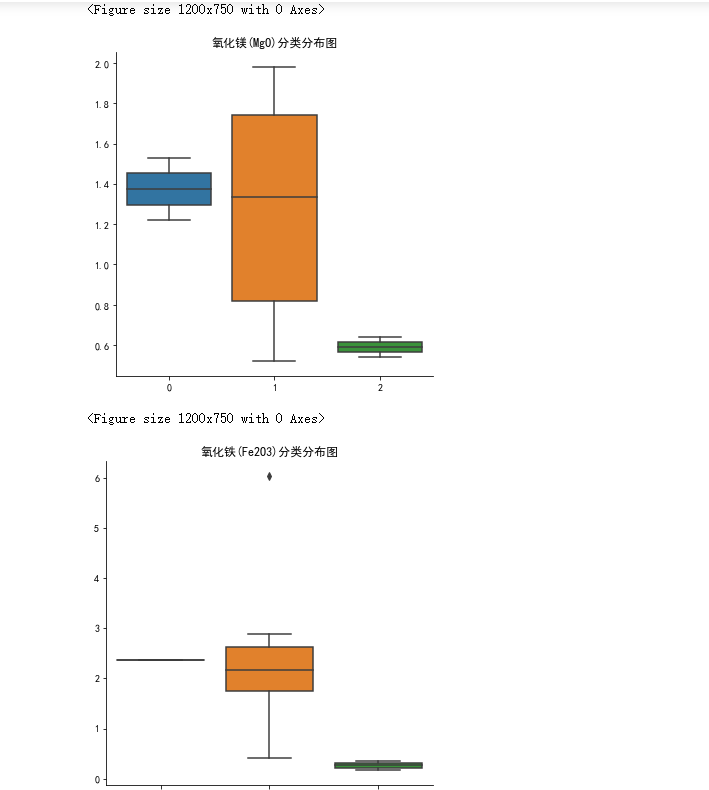
做好可视化来描述统计规律就再好不过了。比如可以用这样的箱型图:
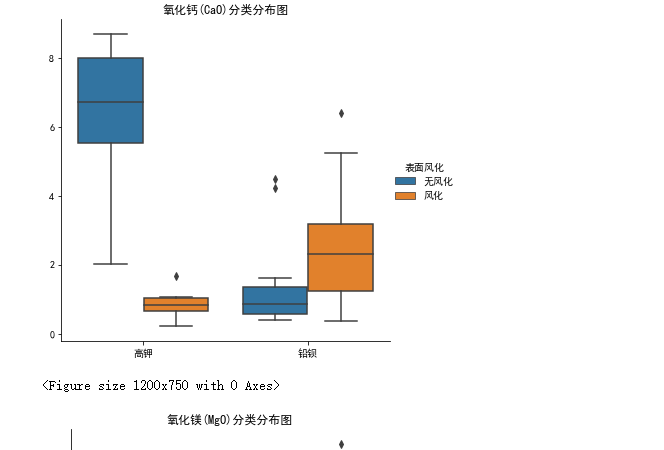
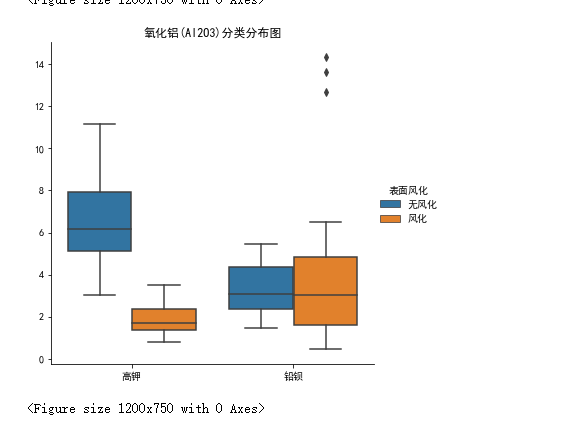
预测其风化前的化学成分含量
输出处理好后,决策树就挺好。这个题需要注意的是,这是化学背景的题,肯定要考虑化学反应,所以最好先预测sio2这个催化剂再预测花絮成分会好一点。
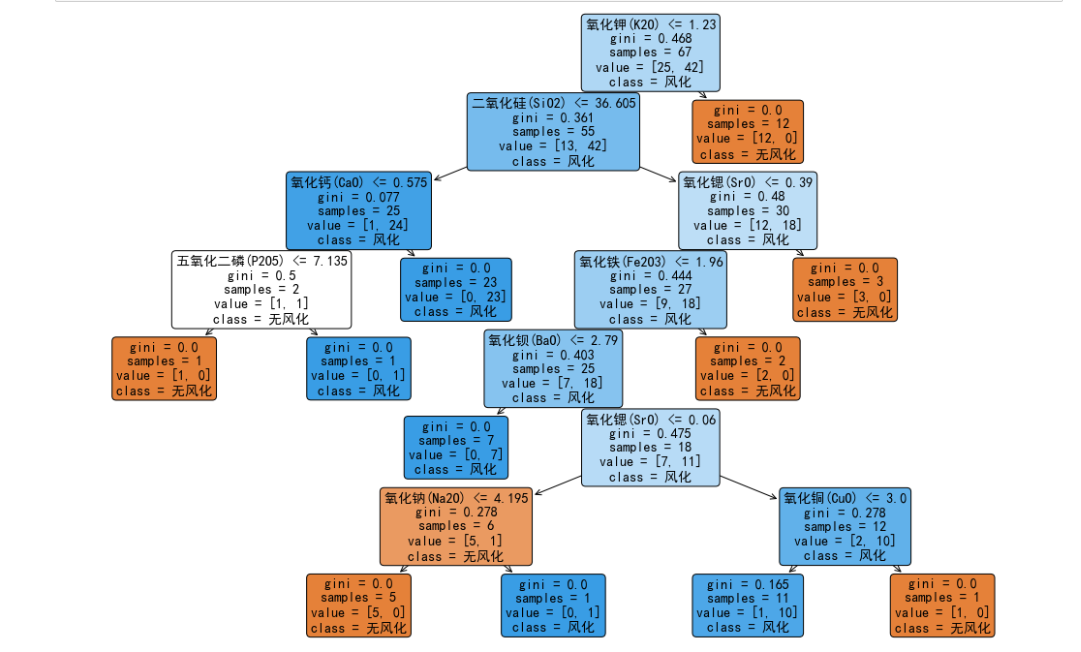
问题二
选择合适的化学成分进行亚类划分
使用层次聚类的方法即可,如果使用kmeans的话需要结合手肘法。最后分为三个亚类。可视化:
其中一个手肘图绘制可以得到如下:
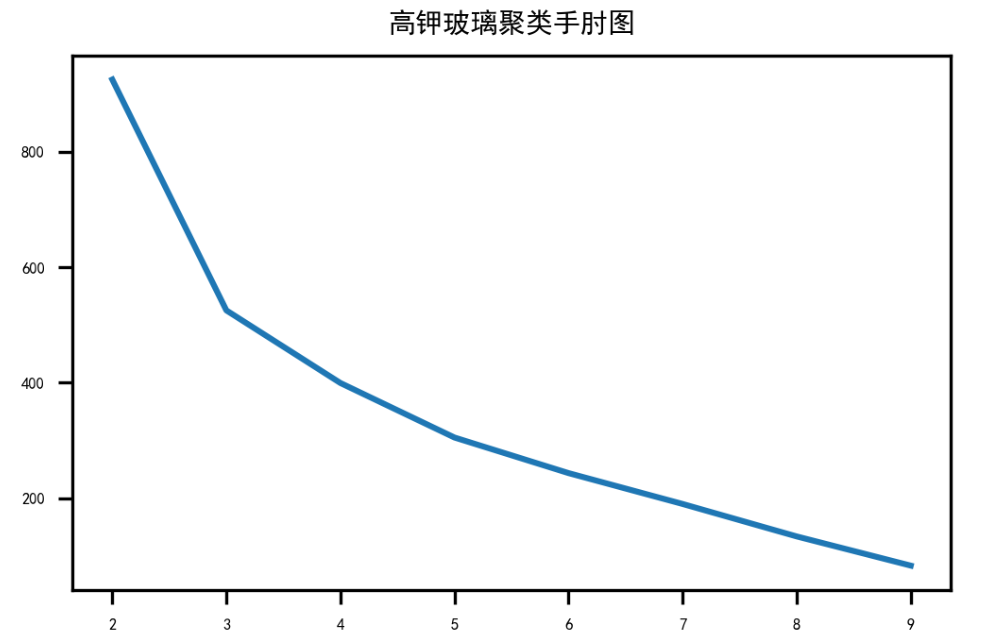
拐点3处为最佳。
问题三
基于问题二的模型带上去就好了。为了增加工作量,增加一些其它算法实践进行对比。
以梯度提升回归算法为例进行实践:
# 梯度提升回归算法
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
gbr_params = {'n_estimators': 1000,
'max_depth': 3,
'min_samples_split': 5,
'learning_rate': 0.01,
'loss': 'ls'}
# 创建梯度提升回归,带入参数
gbr = GradientBoostingRegressor(**gbr_params)
gbr.fit(X_train, y_train) #训练模型
df3["分类结果"] = gbr.predict(X_test) # 1:"高钾", 2:"铅钡
df3

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
得到如下:
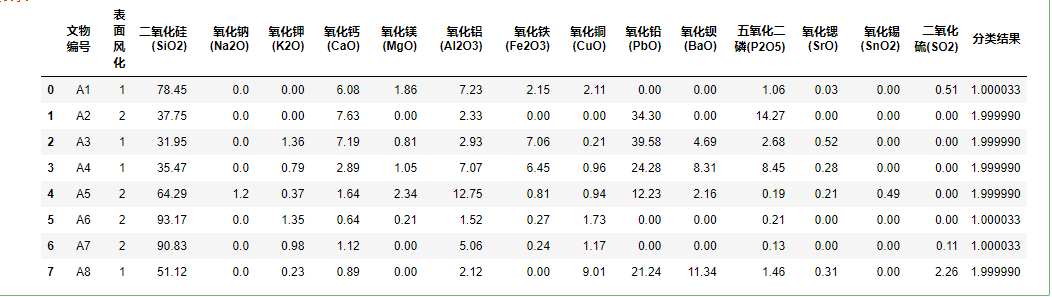
从而得出表单三结果A1 A6 A7为高钾 , 其它为铅钡
问题四
关联性:皮尔斯曼相关性
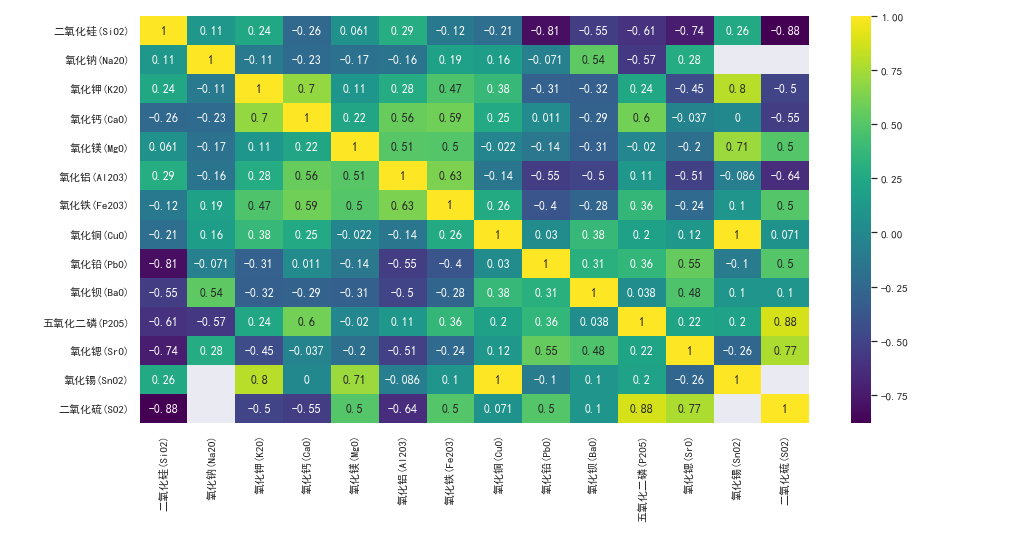
差异性:pandas提取两个类型的数据,做典型相关分析。相关小则差异大,相关大则差异小。直接用SPSS做很方便。
思考:如何处理机器学习的过拟合问题?
难度评价
数据挖掘中,中等题目吧。几乎每个人都能想到一点思路,所以选择它的人很多。做它容易,做好难。
文章来源: chuanchuan.blog.csdn.net,作者:川川菜鸟,版权归原作者所有,如需转载,请联系作者。
原文链接:chuanchuan.blog.csdn.net/article/details/126929454

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)