SQL索引性能优化


作者: 西魏陶渊明 博客: https://blog.springlearn.cn/ (opens new window)
西魏陶渊明
莫笑少年江湖梦,谁不少年梦江湖
# 建表
-
// 建表
-
CREATE TABLE IF NOT EXISTS staffs(
-
id INT PRIMARY KEY AUTO_INCREMENT,
-
name VARCHAR(24) NOT NULL DEFAULT "" COMMENT'姓名',
-
age INT NOT NULL DEFAULT 0 COMMENT'年龄',
-
pos VARCHAR(20) NOT NULL DEFAULT "" COMMENT'职位',
-
add_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职事件'
-
) CHARSET utf8 COMMENT'员工记录表';
-
-
// 插入数据
-
INSERT INTO `test`.`staffs` (`name`, `age`, `pos`, `add_time`) VALUES ('z3', 22, 'manager', now());
-
INSERT INTO `test`.`staffs` (`name`, `age`, `pos`, `add_time`) VALUES ('July', 23, 'dev', now());
-
INSERT INTO `test`.`staffs` (`name`, `age`, `pos`, `add_time`) VALUES ('2000', 23, 'dev', now());
-
-
// 建立复合索引(即一个索引包含多个字段)
-
ALTER TABLE staffs ADD INDEX idx_staffs_nameAgePos(name, age, pos);

# 优化一、全部用到索引
# 1. 介绍
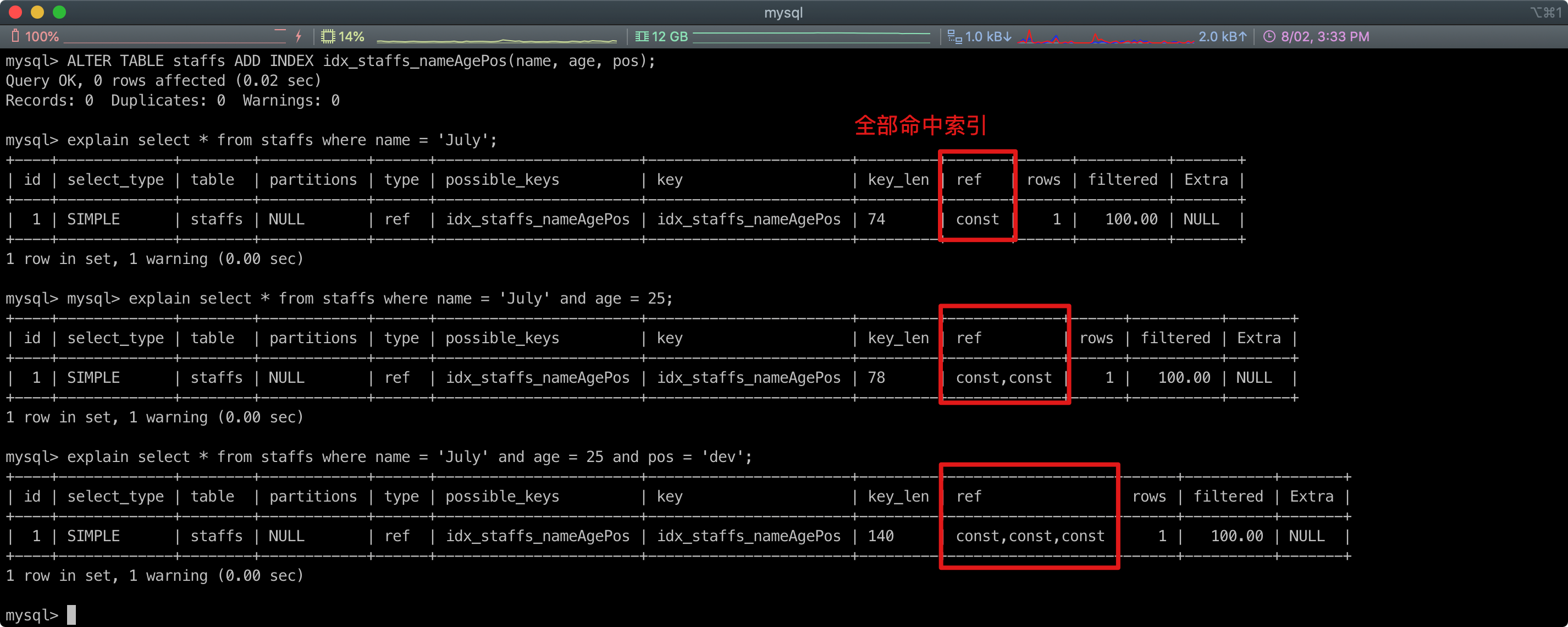
建立的复合索引包含了几个字段,查询的时候最好能全部用到,而且严格按照索引顺序,这样查询效率是最高的。(最理想情况,具体情况具体分析)
# 2. SQL案例
# 优化二、最左前缀法则
# 1. 介绍
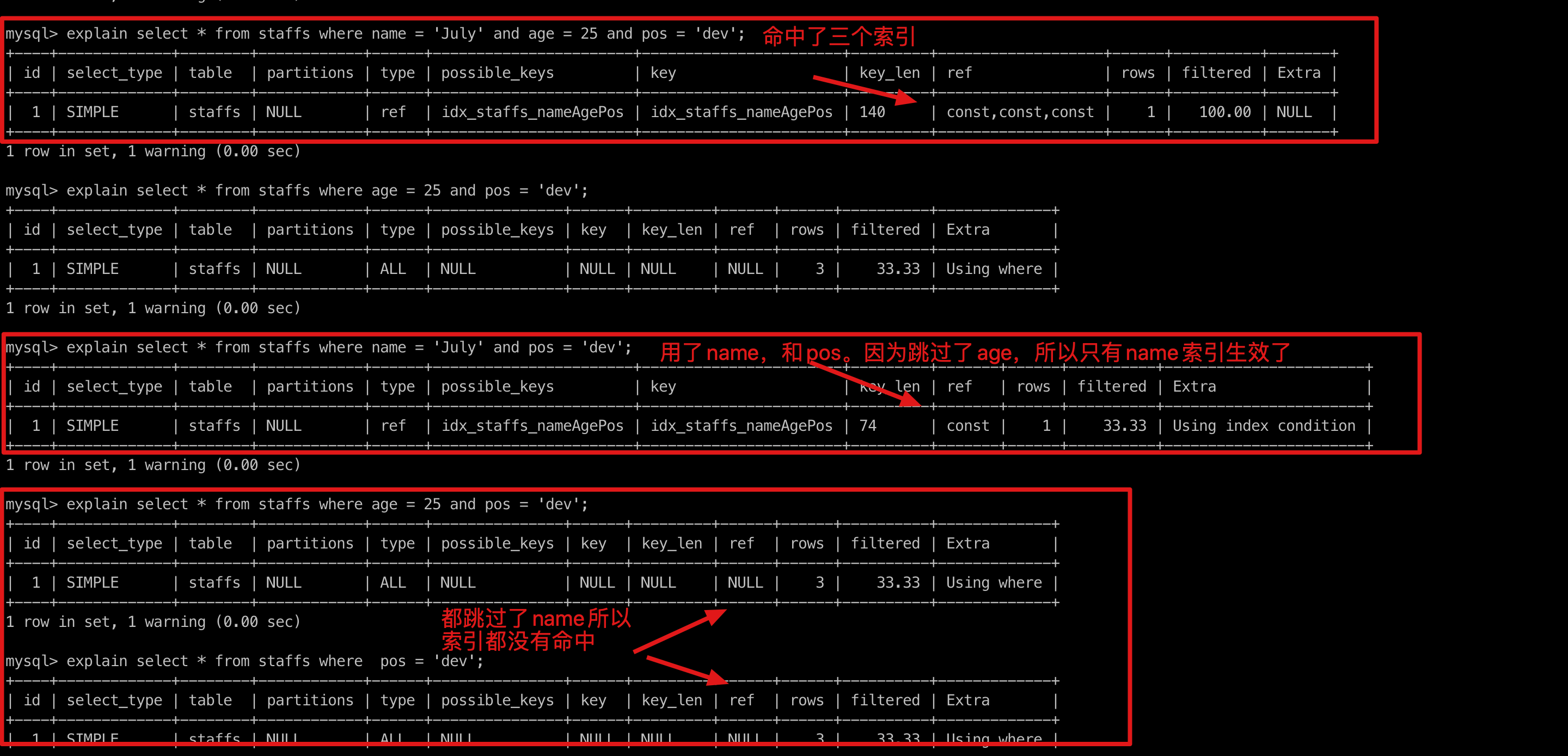
如果建立的是复合索引,索引的顺序要按照建立时的顺序,即从左到右,如:a->b->c(和 B+树的数据结构有关)
# 2. 无效索引举例
如果用了a和c,那么a索引有效,c无效,因为中间跳过了b
如果用了b和c,那么b索引和c索引都无效,因为跳过了a
如果只用了c,那么也会无效,因为跳过了a和b
# 优化三、不要对索引做以下处理
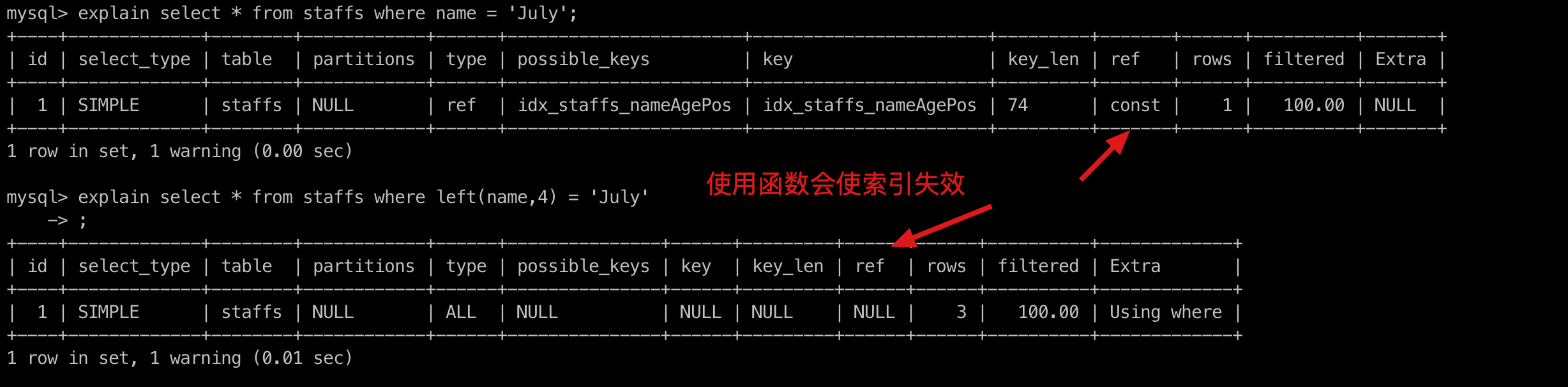
# 1. 以下用法会导致索引失效
- 计算,如:+、-、*、/、!=、<>、is null、is not null、or
- 函数,如:sum()、round()等等
- 手动/自动类型转换,如:id = "1",本来是数字,给写成字符串了
# 优化四、索引不要放在范围查询右边
# 1. 举例
比如复合索引:a->b->c,当 where a="" and b>10 and 3="",这时候只能用到 a 和 b,c 用不到索引,因为在范围之后索引都失效(和 B+树结构有关)
因为b使用了范围,所以右边的索引c就失效了

# 优化五、减少 select * 的使用
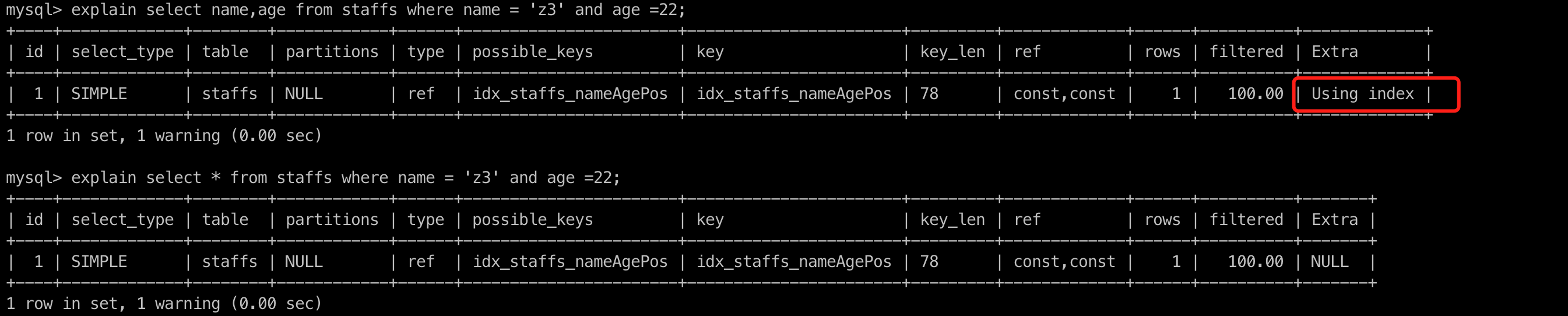
# 1. 使用覆盖索引
即:select 查询字段和 where 中使用的索引字段一致。
# 优化六、like 模糊搜索
# 1. 失效情况
like "%张三%" like "%张三"
# 2. 解决方案
使用复合索引,即 like 字段是 select 的查询字段,如:select name from table where name like "%张三%" 使用 like "张三%"
使用 like "张三%"
# 优化七、order by 优化
当查询语句中使用 order by 进行排序时,如果没有使用索引进行排序,会出现 filesort 文件内排序,这种情况在数据量大或者并发高的时候,会有性能问题,需要优化。
# 1. filesort 出现的情况举例
- order by 字段不是索引字段
- order by 字段是索引字段,但是 select 中没有使用覆盖索引,如:
select * from staffs order by age asc; - order by 中同时存在 ASC 升序排序和 DESC 降序排序,如:
select a, b from staffs order by a desc, b asc; - order by 多个字段排序时,不是按照索引顺序进行 order by,即不是按照最左前缀法则,如:
select a, b from staffs order by b asc, a asc;
# 2. 索引层面解决方法
- 使用主键索引排序
- 按照最左前缀法则,并且使用覆盖索引排序,多个字段排序时,保持排序方向一致
- 在 SQL 语句中强制指定使用某索引,force index(索引名字)
- 不在数据库中排序,在代码层面排序
# 3. order by 排序算法
双路排序
Mysql4.1 之前是使用双路排序,字面的意思就是两次扫描磁盘,最终得到数据,读取行指针和 ORDER BY 列,对他们进行排序,然后扫描已经排好序的列表,按照列表中的值重新从列表中读取对数据输出。也就是从磁盘读取排序字段,在 buffer 进行排序,再从磁盘读取其他字段。
文件的磁盘 IO 非常耗时的,所以在 Mysql4.1 之后,出现了第二种算法,就是单路排序。
从磁盘读取查询需要的所有列,按照 orderby 列在 buffer 对它们进行排序,然后扫描排序后的列表进行输出, 它的效率更快一些,避免了第二次读取数据,并且把随机 IO 变成顺序 IO,但是它会使用更多的空间, 因为它把每一行都保存在内存中了。
当我们无可避免要使用排序时,索引层面没法在优化的时候又该怎么办呢?尽可能让 MySQL 选择使用第二种单路算法来进行排序。这样可以减少大量的随机 IO 操作,很大幅度地提高排序工作的效率。下面看看单路排序优化需要注意的点
单路排序优化点
增大 max_length_for_sort_data
在 MySQL 中,决定使用"双路排序"算法还是"单路排序"算法是通过参数 maxlength_for sort_data 来决定的。当所有返回字段的最大长度小于这个参数值时,MySQL 就会选择"单路排序"算法,反之,则选择"多路排序"算法。所以,如果有充足的内存让 MySQL 存放须要返回的非排序字段,就可以加大这个参数的值来让 MySQL 选择使用"单路排序"算法。
去掉不必要的返回字段,避免select *
当内存不是很充裕时,不能简单地通过强行加大上面的参数来强迫 MySQL 去使用"单路排序"算法,否则可能会造成 MySQL 不得不将数据分成很多段,然后进行排序,这样可能会得不偿失。此时就须要去掉不必要的返回字段,让返回结果长度适应 max_length_for_sort_data 参数的限制。
增大 sort_buffer_size 参数设置
这个值如果过小的话,再加上你一次返回的条数过多,那么很可能就会分很多次进行排序,然后最后将每次的排序结果再串联起来,这样就会更慢,增大 sort_buffer_size 并不是为了让 MySQL 选择"单路排序"算法,而是为了让 MySQL 尽量减少在排序过程中对须要排序的数据进行分段,因为分段会造成 MySQL 不得不使用临时表来进行交换排序。
但是sort_buffer_size 不是越大越好:
- Sort_Buffer_Size 是一个 connection 级参数,在每个 connection 第一次需要使用这个 buffer 的时候,一次性分配设置的内存。
- Sort_Buffer_Size 并不是越大越好,由于是 connection 级的参数,过大的设置和高并发可能会耗尽系统内存资源。
- 据说 Sort_Buffer_Size 超过 2M 的时候,就会使用 mmap() 而不是 malloc() 来进行内存分配,导致效率降低。
# 优化八、group by
其原理也是先排序后分组,其优化方式可参考order by。where高于having,能写在where限定的条件就不要去having限定了。
文章来源: springlearn.blog.csdn.net,作者:西魏陶渊明,版权归原作者所有,如需转载,请联系作者。
原文链接:springlearn.blog.csdn.net/article/details/125857964

- 点赞
- 收藏
- 关注作者
评论(0)