Spark的这些事<三>——spark常用的Transformations 和Actions

Transformations
map,filter
spark最长用的两个Transformations:map,filter,下面就来介绍一下这两个。
先看下面这张图:
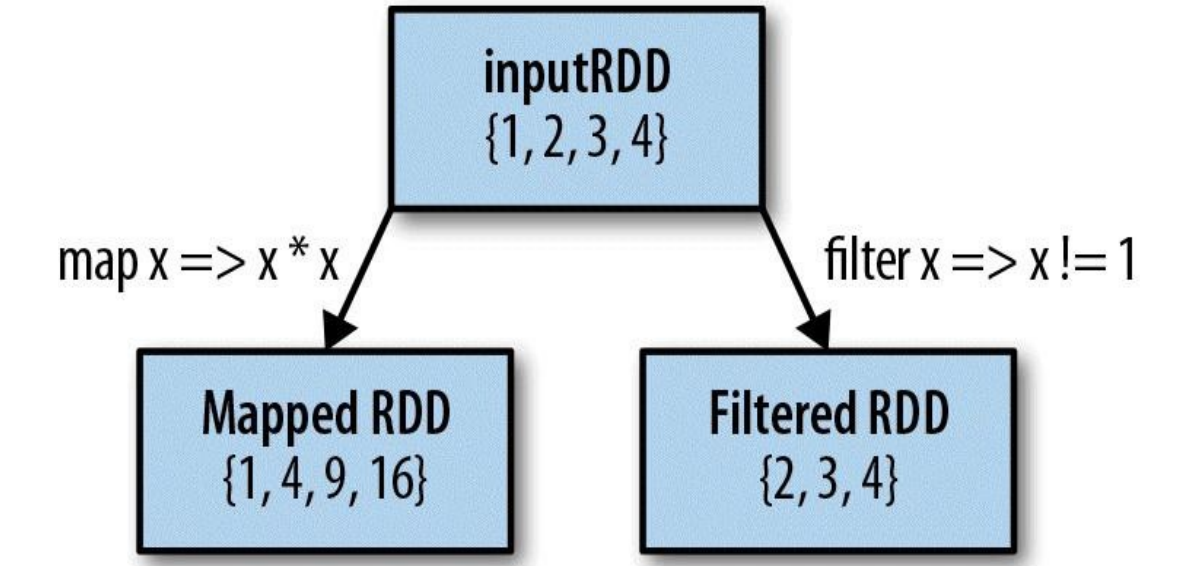
从上图中可以清洗的看到 map和filter都是做的什么工作,那我们就代码演示一下。
val input = sc.parallelize(List(1,2,3,4))
val result1 = input.map(x=>x*x)
val result2 = input.filter(x=>x!=1)
print(result1.collect().mkString(","))
print("\n")
print(result2.collect().mkString(","))
print("\n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
执行结果如下:
16/08/17 18:48:31 INFO DAGScheduler: ResultStage 0 (collect at Map.scala:17) finished in 0.093 s
16/08/17 18:48:31 INFO DAGScheduler: Job 0 finished: collect at Map.scala:17, took 0.268871 s
1,4,9,16
........
16/08/17 18:48:31 INFO DAGScheduler: ResultStage 1 (collect at Map.scala:19) finished in 0.000 s
16/08/17 18:48:31 INFO DAGScheduler: Job 1 finished: collect at Map.scala:19, took 0.018291 s
2,3,4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
再回头看下上面那张图,是不是明白什么意思了!
flatMap
另外一个常用的就是flatMap,输入一串字符,分割出每个字符
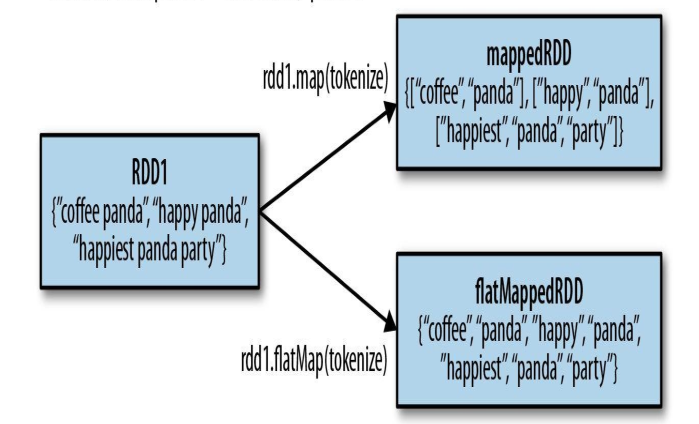
来用代码实践一下:
val lines = sc.parallelize(List("hello world","hi"))
val words = lines.flatMap (lines=>lines.split(" "))
print(words.first())
print("\n")
- 1
- 2
- 3
- 4
执行结果:
16/08/17 19:23:24 INFO DAGScheduler: Job 2 finished: first at Map.scala:24, took 0.016987 s
hello
16/08/17 19:23:24 INFO SparkContext: Invoking stop() from shutdown hook
- 1
- 2
- 3
分隔符如果改一下的话:
val words = lines.flatMap (lines=>lines.split(","))
- 1
结果会怎样呢?
16/08/17 19:33:14 INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool
hello world
16/08/17 19:33:14 INFO SparkContext: Invoking stop() from shutdown hook
- 1
- 2
- 3
和想象的一样吧~
distinct,distinct,intersection,subtract
还有几个比较常用的:distinct,distinct,intersection,subtract
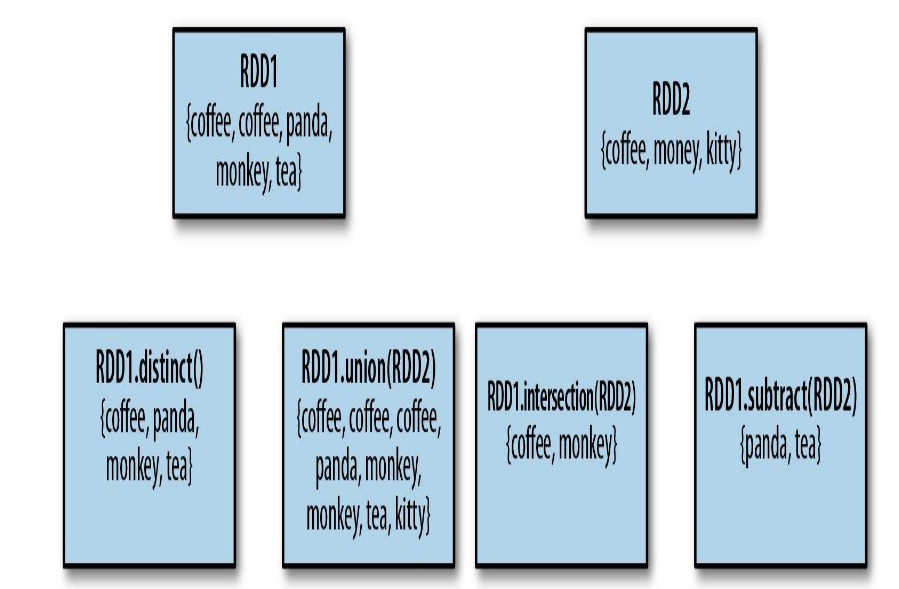
来看看代码实践:
val rdd1 = sc.parallelize(List("coffee","coffee","panda","monkey","tea"))
val rdd2 = sc.parallelize(List("coffee","monkey","kitty"))
rdd1.distinct().take(100).foreach(println)
- 1
- 2
- 3
- 4
结果:
16/08/17 19:52:29 INFO DAGScheduler: ResultStage 4 (take at Map.scala:30) finished in 0.047 s
16/08/17 19:52:29 INFO TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool
16/08/17 19:52:29 INFO DAGScheduler: Job 3 finished: take at Map.scala:30, took 0.152405 s
monkey
coffee
panda
tea
16/08/17 19:52:29 INFO SparkContext: Starting job: take at Map.scala:32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
代码:
rdd1.union(rdd2).take(100).foreach(println)
- 1
结果:
6/08/17 19:52:29 INFO DAGScheduler: Job 5 finished: take at Map.scala:32, took 0.011825 s
coffee
coffee
panda
monkey
tea
coffee
monkey
kitty
16/08/17 19:52:30 INFO SparkContext: Starting job: take at Map.scala:34
16/08/17 19:52:30 INFO DAGScheduler: Registering RDD 11 (intersection at Map.scala:34)
16/08/17 19:52:30 INFO DAGScheduler: Registering RDD 12 (intersection at Map.scala:34)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
代码:
rdd1.intersection(rdd2).take(100).foreach(println)
- 1
结果:
16/08/17 19:52:30 INFO TaskSetManager: Finished task 0.0 in stage 9.0 (TID 9) in 31 ms on localhost (1/1)
16/08/17 19:52:30 INFO TaskSchedulerImpl: Removed TaskSet 9.0, whose tasks have all completed, from pool
16/08/17 19:52:30 INFO DAGScheduler: ResultStage 9 (take at Map.scala:34) finished in 0.031 s
16/08/17 19:52:30 INFO DAGScheduler: Job 6 finished: take at Map.scala:34, took 0.060785 s
monkey
coffee
16/08/17 19:52:30 INFO SparkContext: Starting job: take at Map.scala:36
- 1
- 2
- 3
- 4
- 5
- 6
- 7
代码:
rdd1.subtract(rdd2).take(100).foreach(println)
- 1
结果:
16/08/17 19:52:30 INFO DAGScheduler: Job 6 finished: take at Map.scala:34, took 0.060785 s
monkey
coffee
16/08/17 19:52:30 INFO SparkContext: Starting job: take at Map.scala:36
- 1
- 2
- 3
- 4
再看看上面的图,很容易理解吧
Actions
常用的Transformations就介绍到这里,下面介绍下常用的Action:
reduce,countByValue,takeOrdered,takeSample,aggregate
首先看一下:reduce
val rdd5 = sc.parallelize(List(1,2,3,4))
print("reduce action:"+rdd5.reduce((x,y)=>x+y)+"\n")
- 1
- 2
16/08/18 11:51:16 INFO DAGScheduler: Job 15 finished: reduce at Function.scala:55, took 0.012698 s
reduce action:10
16/08/18 11:51:16 INFO SparkContext: Starting job: aggregate at Function.scala:57
- 1
- 2
- 3
countByValue
print(rdd1.countByValue() + "\n")
- 1
16/08/18 11:51:16 INFO DAGScheduler: Job 11 finished: countByValue at Function.scala:48, took 0.031726 s
Map(monkey -> 1, coffee -> 2, panda -> 1, tea -> 1)
16/08/18 11:51:16 INFO SparkContext: Starting job: takeOrdered at Function.scala:50
- 1
- 2
- 3
takeOrdered
rdd1.takeOrdered(10).take(100).foreach(println)
- 1
16/08/18 11:51:16 INFO DAGScheduler: Job 12 finished: takeOrdered at Function.scala:50, took 0.026160 s
coffee
coffee
monkey
panda
tea
16/08/18 11:51:16 INFO SparkContext: Starting job: takeSample at Function.scala:52
- 1
- 2
- 3
- 4
- 5
- 6
- 7
aggregate
这个要重点介绍一下:
Spark文档中aggregate函数定义如下
def aggregate[U](zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)(implicit arg0: ClassTag[U]): U
Aggregate the elements of each partition, and then the results for all the partitions, using given combine functions and a neutral “zero value”. This function can return a different result type, U, than the type of this RDD, T. Thus, we need one operation for merging a T into an U and one operation for merging two U’s, as in scala.TraversableOnce. Both of these functions are allowed to modify and return their first argument instead of creating a new U to avoid memory allocation.seqOp操作会聚合各分区中的元素,然后combOp操作把所有分区的聚合结果再次聚合,两个操作的初始值都是zeroValue. seqOp的操作是遍历分区中的所有元素(T),第一个T跟zeroValue做操作,结果再作为与第二个T做操作的zeroValue,直到遍历完整个分区。combOp操作是把各分区聚合的结果,再聚合。aggregate函数返回一个跟RDD不同类型的值。因此,需要一个操作seqOp来把分区中的元素T合并成一个U,另外一个操作combOp把所有U聚合。
val rdd5 = sc.parallelize(List(1,2,3,4))
val rdd6 = rdd5.aggregate((0, 0)) ((x, y) =>(x._1 + y, x._2+1), (x, y) =>(x._1 + y._1, x._2 + y._2))
print ("aggregate action : " + rdd6 + "\n" )
- 1
- 2
- 3
我们看一下结果:
16/08/18 11:51:16 INFO DAGScheduler: Job 16 finished: aggregate at Function.scala:57, took 0.011686 s
aggregate action : (10,4)
16/08/18 11:51:16 INFO SparkContext: Invoking stop() from shutdown hook
- 1
- 2
- 3
我们可以根据以上执行的例子来理解aggregate 用法:
- 第一步:将rdd5中的元素与初始值遍历进行聚合操作
- 第二步:将初始值加1进行遍历聚合
- 第三步:将结果进行聚合
- 根据本次的RDD 背部实现如下:
- 第一步:其实是0+1
- 1+2
- 3+3
- 6+4
- 然后执行:0+1
- 1+1
- 2+1
- 3+1
- 此时返回(10,4)
- 本次执行是一个节点,如果在集群中的话,多个节点,会先把数据打到不同的分区上,比如(1,2) (3,4)
- 得到的结果就会是(3,2) (7,2)
- 然后进行第二步combine就得到 (10,4)
这样你应该能理解aggregate这个函数了吧
以上就是对常用的Transformations 和Actions介绍,对于初学者来说,动手代码实践各个函数,才是明白其功能最好的方法。
PS :源码
Spark的这些事系列文章:
Spark的这些事<一>——Windows下spark开发环境搭建
Spark的这些事<二>——几个概念
Spark的这些事<三>——spark常用的Transformations 和Actions
Spark的这些事<四>——SparkSQL功能测试结果
文章来源: dataclub.blog.csdn.net,作者:数据社,版权归原作者所有,如需转载,请联系作者。
原文链接:dataclub.blog.csdn.net/article/details/52233646

- 点赞
- 收藏
- 关注作者
评论(0)