浅谈用户行为分析

关于用户行为分析,很多互联网公司都有相关的需求,虽然业务不同,但是关于用户行为分析的方法和技术实现都是基本相同的。在此分享一下自己的一些心得。
一. 简介
用户行为分析主要关心的指标可以概括如下:哪个用户在什么时候做了什么操作在哪里做了什么操作,为什么要做这些操作,通过什么方式,用了多长时间等问题,总结出来就是WHO,WHEN,WHERE,WHAT,WHY以及HOW,HOW TIME。
二.基础数据
根据以上5个W和2H,我们来讨论下们如何实现。
WHO,首先需要x获取登陆用户个人的信息。用户名称,角色等
WHEN,获取用户访问页面每个模块的时间,开始时间,结束时间等
WHAT,获取用户登陆页面后都做了什么操作,点击了哪些页面以及模块等
WHY,分析用户点击这些模块的目的是什么
HOW,用户通过什么方式访问的系统,web,APP,小程序等
HOW TIME,用户访问每个模块,浏览某个页面多长时间等
以上都是我们要获取的数据,获取到相关数据我们才能接着分析用户的行为。
三.技术实现
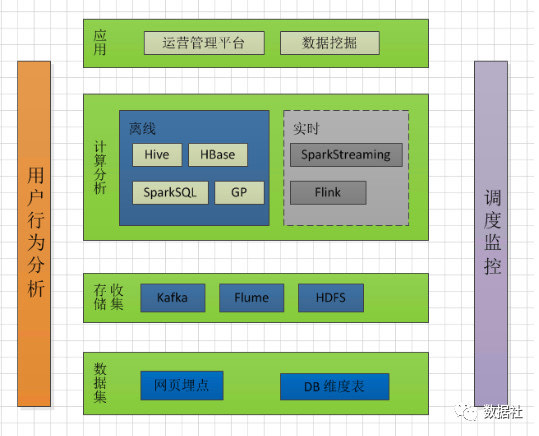
有了上面的思路,下面我们来说下实现的相关技术问题,如何落地用户行为分析。
a).首先是获取用户行为数据,目前比较多的方法有两种,一种是埋点,一种是无埋点(即全埋点)。先说下两种方式,第一埋点,埋点能够针对特定的页面位置获取用户的访问数据,能够更加精确的获取用户的访问动作等信息,没有其他杂乱数据,我们需要什么数据,就在页面对应的位置埋点就行。第二是插无埋点,第一次听说这个技术是当时看到GrowingIO提出来的,这种技术其实是全埋点,也就是,你从登陆访问的所有信息都会被收集到,数据很多。
b).获取到的用户的访问日志数据,是否就能用了呢?不行,这样收集到的数据很不规范,日志很乱,所以此时需要后端和前端定义好数据的保存格式,也就是保存哪些字段内容,需要把埋点数据按照约定的格式统一封装,以便于存储分析。
c).数据封装好后如何存储呢,我们知道对于互联网公司来说,用户的访问日志是非常大的,所以需要用户大数据存储技术,比如存储到HDFS上就是一个不错的选择。用户的访问日志都是实时产生的,如何落地到HDFS上呢?第一,埋点数据可以先落到磁盘,然后通过FLUME监听对应的磁盘目录,进行转发到HDFS,推荐使用kafka channel。第二,可以将用户访问的数据转发的一个特定的端口,使用FLUME监听对应的端口号,进行转发落地到HDFS。(期间,需要给FLUME足够的资源,注意进行心跳监控)。数据落地HDFS后,离线可以使用Hive SQL或者Spark SQL 进行分析。
对于离线分析,上述步骤,可以获取数据分析,对于个别实时需求,计算时则不需要进行落地HDFS,直接利用Storm,Spark Streaming,Flink等计算引擎消费Flume中转的kafka数据即可。
文章来源: dataclub.blog.csdn.net,作者:数据社,版权归原作者所有,如需转载,请联系作者。
原文链接:dataclub.blog.csdn.net/article/details/103160775

- 点赞
- 收藏
- 关注作者
评论(0)