Vertica的那些事

近期数字化转型在业界提的很火热,数字经济规划作为单独篇章出现在了最新的十四五规划中,足以说明国家对数字经济的重视。那么对于我们数据人来说,这无疑是一个非常好的“风口”,可以让我们大展身手。
那么对于做数据工作,特别是处理海量数据,有一款趁手的数据计算引擎,无疑是非常重要的。那么对于海量数据处理,今天给大家聊一聊Vertica这款数据库。
1. Vertica是谁
Vertica是一款真正列存储的MPP架构的数据库,他支持PB级别的数据处理。
提到Vertica,我们必须得聊聊他的作者Michael Stonebraker,因对现代数据库系统底层的概念与实践所做出的基础性贡献而获得2014年图灵奖,VMware的创始人Diane Greene(戴安·格林)是他的学生!2004年Stonebraker基于C-Store创办了Vertica,也就是今天我们要说的这款数据库。

一款无 Master MPP数据库
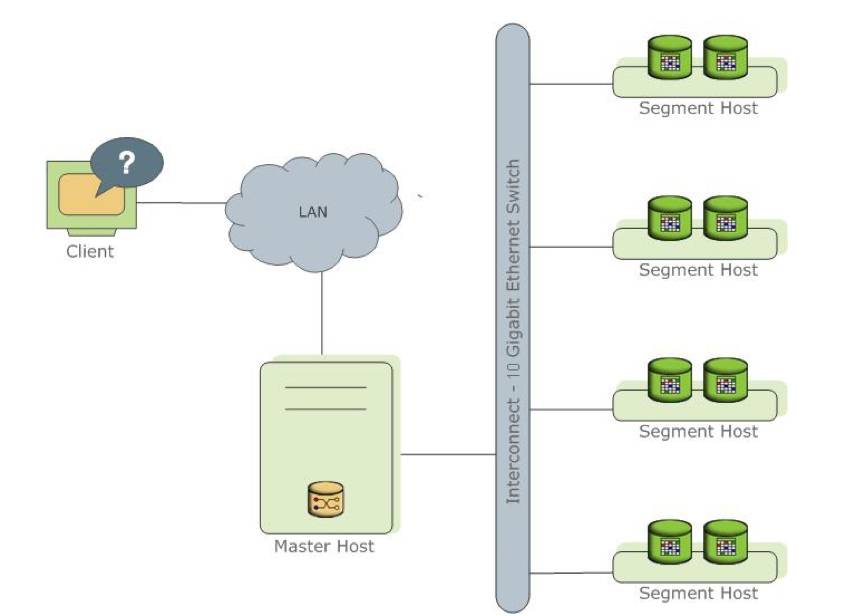
Vertica数据库属于无Master的MPP架构,所有节点均可访问使用,当然其也提供了负载均衡,以保障节点的合理使用。
什么意思?

一句话解释: 就是说Vertica的所有节点都可以作为连接访问节点,同时也作为计算存储节点,这样就不会存在还要去考虑Master节点的高可用。比如,现在业内的GreenPlum属于有Master节点的数据库。
下图对比:
::: hljs-center
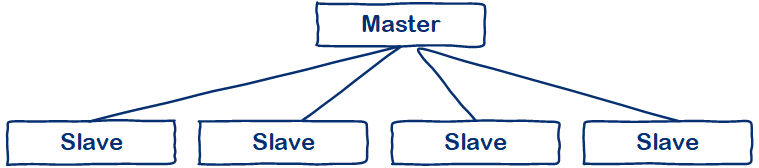
Master/Slave架构
:::
::: hljs-center
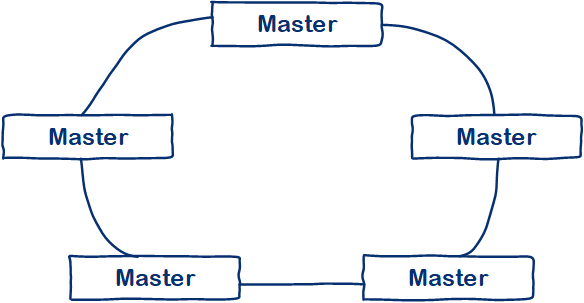
多主架构
:::
列式存储数据库
Vertica是一款列式存储数据库,列式存储的好处在哪呢?
比如我们查询一个表table1,table1有100列,写一个SQL语句查询出col1,col2,col3,col4四列数据:
select col1,col2,col3,col4 from table1 ;
如果是行式关系型数据库,比如Oracle,那么他会扫描每一行所有列数据,然后取出col1,col2,col3,col4。那么对于列存储的Vertica,只需要扫描col1,col2,col3,col4这四列的每一行即可,减少了和剩余96列的数据进行IO操作,能不快吗?
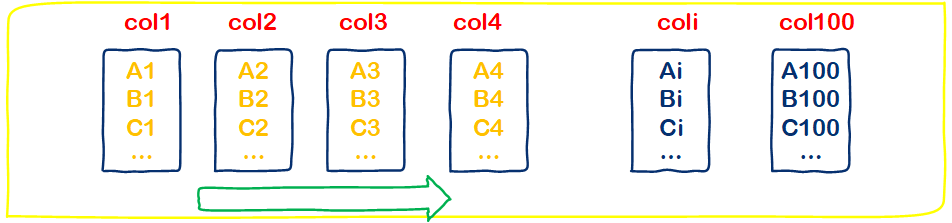
::: hljs-center
行式查询
:::
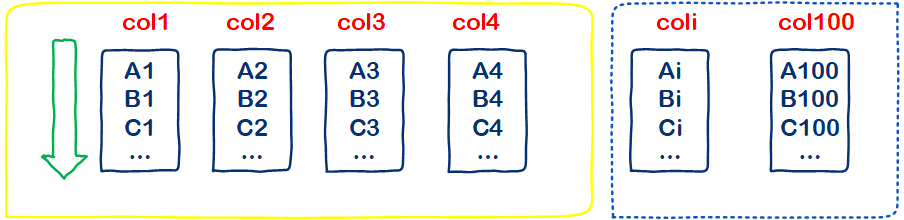
::: hljs-center
列式查询
:::
而且列存储还有一个好处就是可以根据不同列数据类型不同,采取不同的压缩方式,减少存储的同时,提升IO性能,能不快吗?
2. Vertica能干什么?
从上面我们讲的Vertica数据库的特点可以看出,Vertica非常适合于OLAP场景,特别是对于我们常说的“大宽表”,查询性能异常强悍!
::: hljs-center
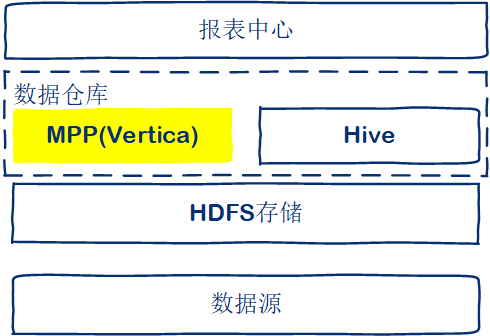
Vertica 作为数据仓库
:::
- 所以,可以将Vertica替换为你现在的Hive作为数据仓库的计算引擎,效率可以提升百倍以上。
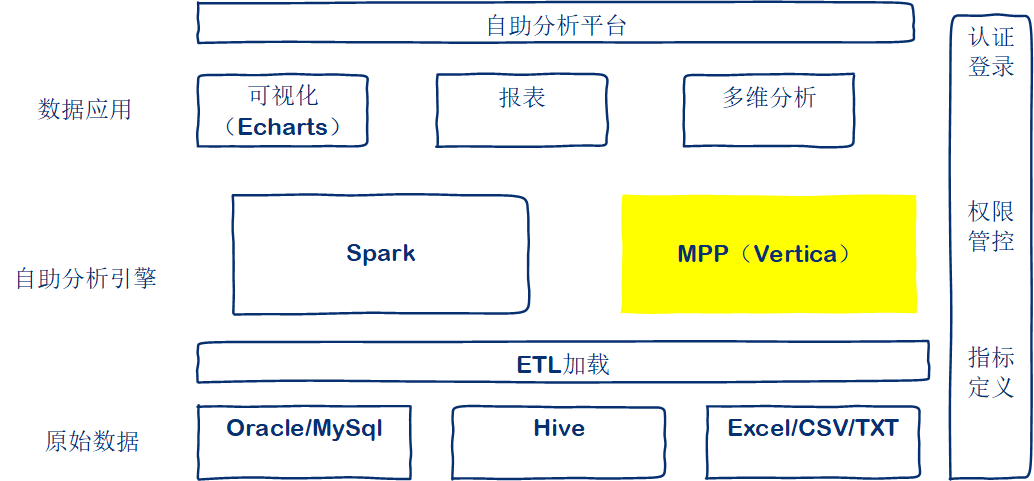
- Vertica 还可以作为你的资助分析引擎,替换现有的Spark即席查询,效率可以提升几十倍。
3. Vertica与其他OLAP引擎的差异
本文选取了与Vertica同宗的GreenPlum,还有目前市面上比较火的Clickhouse和Kylin作为对比,分析一下Vertica与它们的差异在哪?
Greenplum
简介
Greenplum也是典型的MPP架构,将数据平均分布到系统的所有节点服务器上,所以节点存储每张表或表分区的部分行,所有数据加载和查询都是自动在各个节点服务器上并行运行,并且该架构支持扩展到上万个节点。但是Greenplum有独立的Master。
产品特性
- Greenplum数据库通过将数据分布到多个节点上来实现规模数据的存储
- 支持行存储和列存储格式
- 应用生态丰富,利用Greenplum外部表技术,映射Hadoop集群中的HDFS、HIVE、HBASE 等多种格式数据,使用标准SQL访问
Clickhouse
简介
Clickhouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值,这被称为“矢量化查询执行”,它有利于降低实际的数据处理开销。
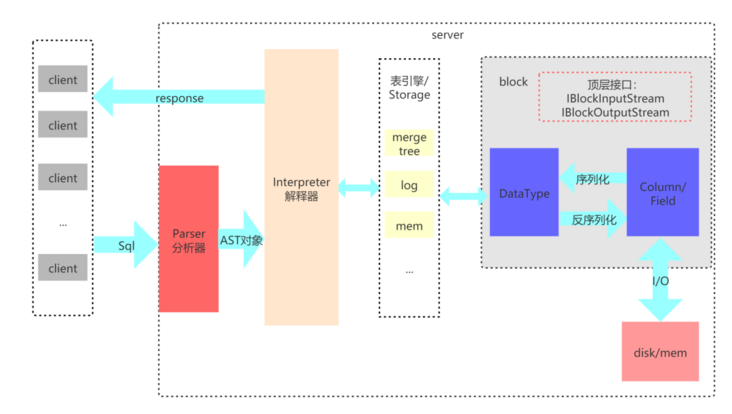
产品特性
- 支持SQL查询,但是比起GreenPlum还不完备
- 列式存储与数据压缩
- 向量化执行引擎,这是Clickhouse单表查询快的原因,极力的去“压榨硬件资源”
- 多样化的表引擎,我理解的这一点与Vertica的建不同的projection有异曲同工之初
- 多主架构,就是前面介绍Vertica的一样,每个节点都可以是Master
Kylin
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
值得一提的是,Kylin是国人主导的Apache顶级项目,爆赞!
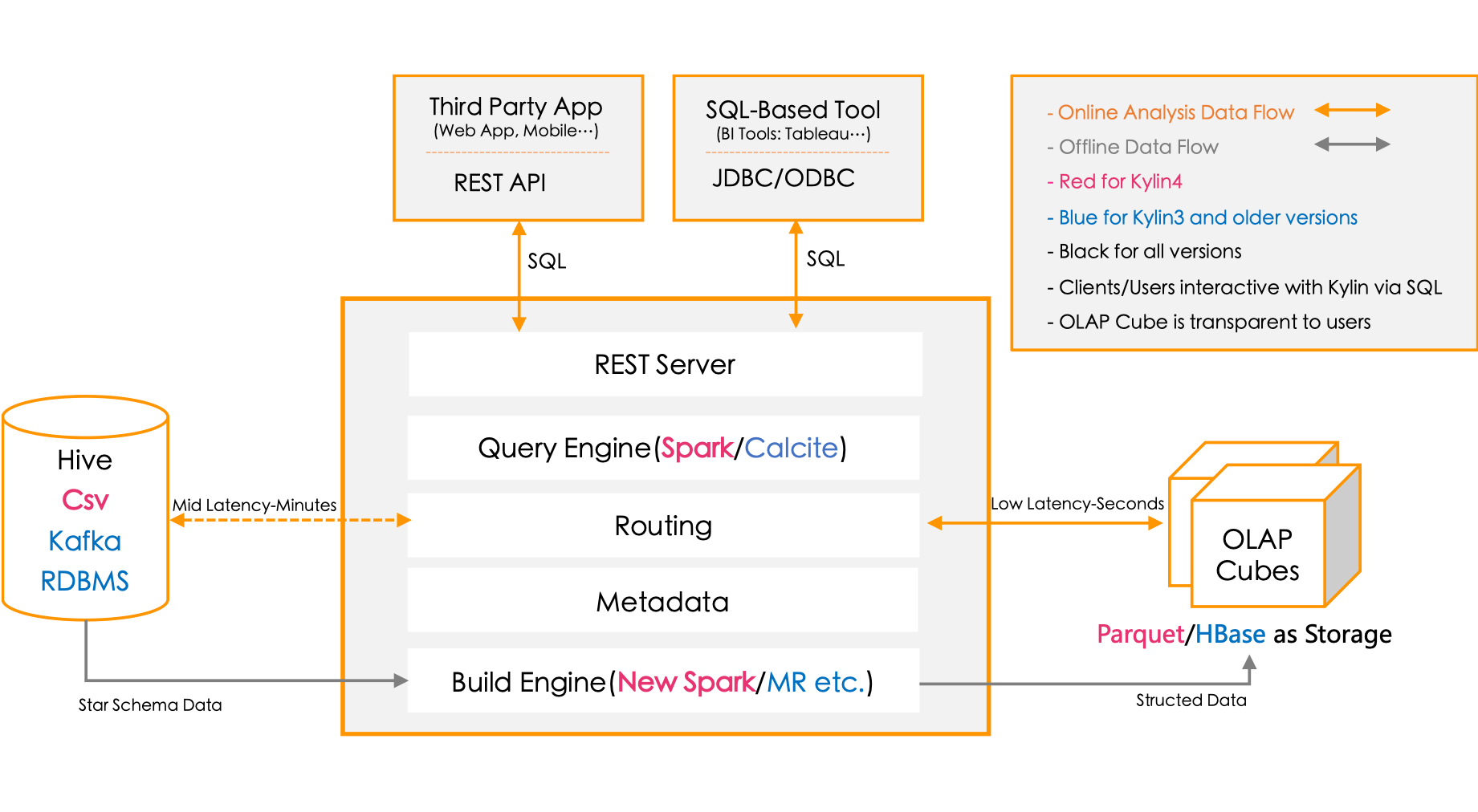
产品特性
- 作为一个分析型数据仓库(也是 OLAP 引擎),Kylin 为 Hadoop 提供标准 SQL 支持大部分查询功能
- 用户能够在 Kylin 里为百亿以上数据集定义数据模型并构建多维立方体(MOLAP Cube)
- Kylin 可以在数据产生时进行实时处理,用户可以在秒级延迟下进行实时数据的多维分析。
Kylin 可以说是与市面上流行的 OLAP 引擎走了一条完全不同的道路,Kylin 在如何快速求得预计算结果,以及优化查询解析使得更多的查询能用上预计算结果方面在优化,而像Greenplum,Clickhouse则着重于优化查询数据的过程环节。
Vertica
同上面三种计算引擎对比,首先它和Clickhouse一样,属于多主架构,每个节点都可以是Master,避免了单节点故障,事实上Vertica只要集群有一半以上节点存活,集群即处于可用状态。另外,Vertica的底层和Greenplum一样都是基于postgreSQL,SQL支持功能强大,多表关联,窗口函数完全不在话下。Vertica的周边生态已经足够完善,支持和HDFS数据无缝对接,支持和Spark,kafka,R,BI工具等,其本身也封装了一些机器学习的函数。
以前做机器学习,一般得用Python,掉一些包,才能实现,比如线性回归:
import pandas as pd from sklearn
import linear_model
import matplotlib.pyplot as plt # 读入CSV数据
csv_data = pd.read_csv('E:\pycode\data\md0301.csv').dropna() #过滤空值
print(csv_data.shape)
print(csv_data.all)
# 建立线性回归模型
regr = linear_model.LinearRegression()
# 拟合
regr.fit(csv_data['m_motor_rotate'].values.reshape(-1, 1), csv_data['vehicle_speed']) # 注意此处.reshape(-1, 1),因为X是一维的!
#得到线性回归公式的系数y=ax+b
a=regr.coef_ print(len(a))
b=regr.intercept_ print(b)
print(regr.score(csv_data['m_motor_rotate'].values.reshape(-1, 1), csv_data['vehicle_speed'])) # 1.真实的点 plt.scatter(csv_data['m_motor_rotate'], csv_data['vehicle_speed'], color='black’)
# 2.拟合的直线
plt.plot(csv_data['m_motor_rotate'], regr.predict(csv_data['m_motor_rotate'].values.reshape(-1,1)), color='red', linewidth=1) plt.show()
现在使用Vertica,调用函数LINEAR_REG一样可以实现。
可以说从数据实时接入,到数据处理,到数据分析,算法挖掘以及可视化应用,一站式服务。
4. Vertica应用展望
笔者是从2015年第一次接触Vertica,当时是Vertica7.X,不得不说,这几年Vertica发展了大的变化,特别是以前Eon模式之前,Vertica的元数据管理做的不是很理想,元数据经常会很大;Eon以前,特别是集群节点不建议无线扩展。
Vertica目前在国内还是很小众,在网上搜资料你会发现都不多,不过目前还好,17年以前,那真是只有官方文档了,笔者也是当时开始写了一些列Vertica使用相关的博客。对Vertica的发展也提几点自己的心得。
灾备
笔者在17年的时候还碰到过一次很意外的异常,当时联系了原厂工程师还是无法解决,只能重新建了一个新库,还好历史数据在Hive中存的有。
后来考虑了备份机制,备份了元数据和表的物理文件,这是一种通用的备份机制,针对任何数据库都适合。建议Vertica可以出一些灾备的方案,能够将备份文件移到另外节点数不一致的集群中也能快速的恢复。
HTAP
目前流批一体化是数据处理的大趋势,各种技术方案都有,对于数据库来说,能够支持HTAP也许是解决这一问题的关键,希望可以考虑这方面的规划,毕竟市场上有大把的需求,老板都希望用更少的人员(资源)去管理更多的业务(赚钱)。
生态
其实“酒香也怕巷子深”,Vertica是个好东西,但是社区这块做的不太好,很少见到相关技术活动。一方面由于Vertica是不开源的,但是Oracle也是不开源的,现在资料随手一搜就能找到。只有生态建立起来了,用户才会考虑去用,毕竟每个架构师都不希望自己使用的技术栈完全处于“盲区”。
笔者之前写过一些Vertica的笔记和视频直播,这里也分享给大家。
Vertica的那些事-笔记下载
Vertica实战系列-基础篇-视频直播
Vertica实战系列-进阶篇-视频直播
文章来源: dataclub.blog.csdn.net,作者:数据社,版权归原作者所有,如需转载,请联系作者。
原文链接:dataclub.blog.csdn.net/article/details/122328090

- 点赞
- 收藏
- 关注作者
评论(0)