第02篇:分布式负载均衡


作者: 西魏陶渊明
博客: https://blog.springlearn.cn/
天下代码一大抄, 抄来抄去有提高, 看你会抄不会抄!
一、什么叫负载均衡
什么叫负载均衡, 所谓负载。先可以理解为当流量请求到某一个微服务应用, 则这么微服务应用就承受了负载。
什么叫均衡如下图,浏览器发送了3次请求,后台有2个节点的微服务应用。但是每次都请求在某一台。而另外一台一直空闲没有流量。这种情况就是不均衡的。
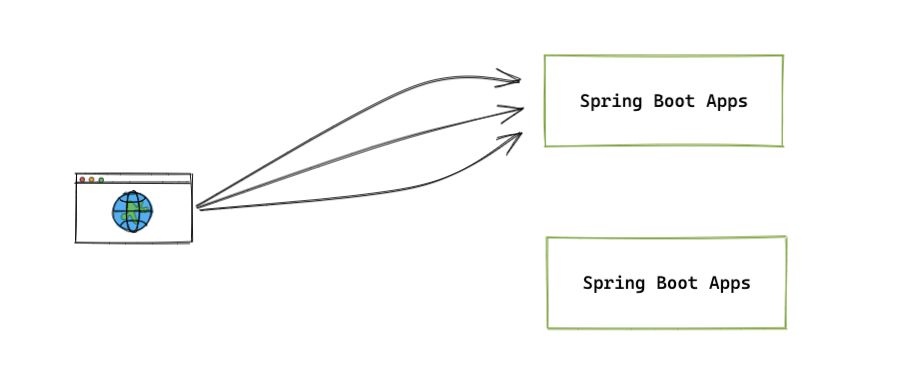
已上图为例,实际情况可能并不一定是一次请求,也可能是一次任务的调用。但是不论实际情况是什么, 负载均衡就是要解决一个事情,就是让流量均衡的分布。防止服务器过载运行产生故障。
二、常见解决思路
所谓负载均衡就是从一个集服务器集合中,找到一个最适合的服务器。去进行操作处理。所以首先我们先定义一个服务器集合。
然后我们再通过常见的算法去进行挑选。
List<String> services;
2.1 随机算法
public static String random(List<String> services) {
Random random = new Random();
String[] addressArr = services.toArray(new String[0]);
// random
return addressArr[random.nextInt(services.size())];
}
- 1
- 2
- 3
- 4
- 5
- 6
2.2 轮训算法
public class RoundBalanceTest {
public static void main(String[] args) {
List<String> services = Arrays.asList("service1", "service2", "service3");
XxlBalanceTest.manyRoute(i -> {
// 请求次数,取模。serviceKey 可以更细粒度的控制轮训
ColorConsole.colorPrintln("轮训负载({}):{}", i, round(services));
});
}
private static final AtomicInteger atomicInteger = new AtomicInteger();
private static String round(List<String> services) {
int count = atomicInteger.get();
if (count >= Integer.MAX_VALUE) {
atomicInteger.set(0);
}
atomicInteger.incrementAndGet();
String[] toArray = services.toArray(new String[0]);
return toArray[count % toArray.length];
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.3 加权算法
加权算法的有很多的变异算法, 可以通过配置的方式,也可以通过某种策略动态的给每台服务器进行加权,从而来提高被轮训到的次数。
这里说两种网上常见的实现。
2.3.1 简单加权算法
一个简单暴力的加权算法,如下图。按照权重,重新构建集合。然后再将集合进行取模轮训即可。即可实现一个最简单
的加权算法。
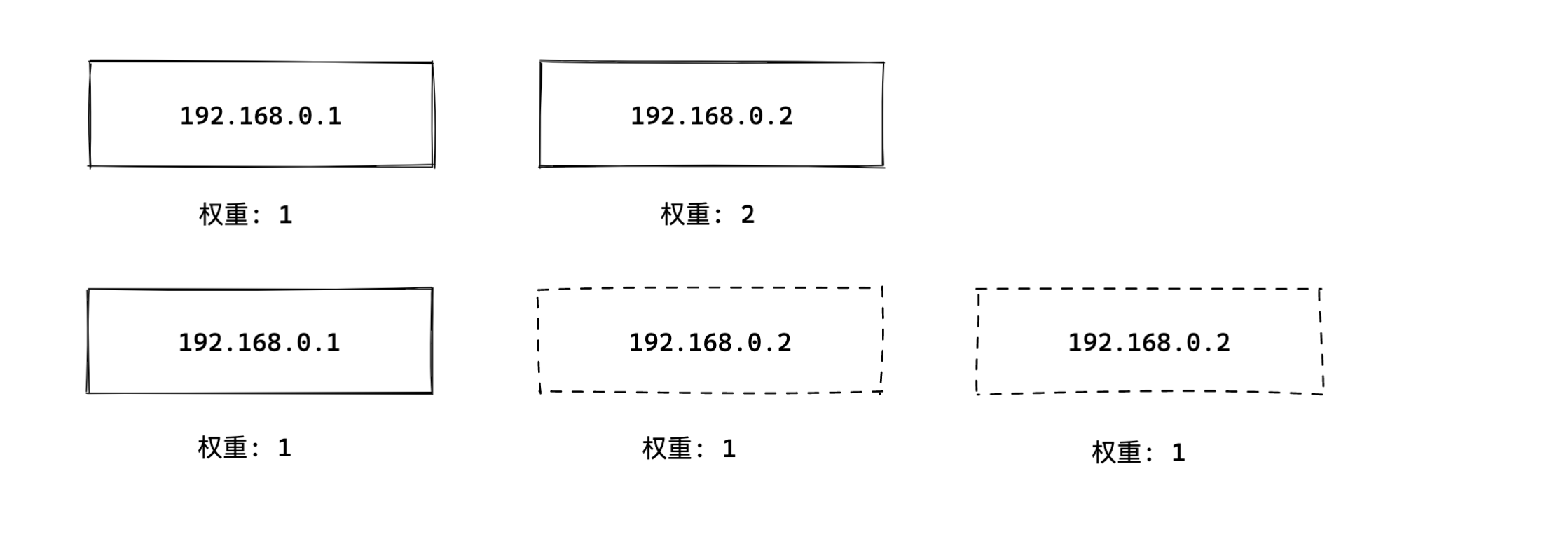
代码实现也是比较简单的,如下代码。
public class WeightBalanceTest {
private static class Server {
private String host;
private Integer port;
public Server(String host, Integer port) {
this.host = host;
this.port = port;
}
@Override
public String toString() {
return "Server{" +
"host='" + host + '\'' +
", port=" + port +
'}';
}
}
private static final AtomicInteger atomicInteger = new AtomicInteger();
public static Server round(List<Server> services) {
int count = atomicInteger.get();
if (count >= Integer.MAX_VALUE) {
atomicInteger.set(0);
}
atomicInteger.incrementAndGet();
Server[] toArray = services.toArray(new Server[0]);
return toArray[count % toArray.length];
}
public static void main(String[] args) {
Map<Server, Integer> confWeight = new HashMap<>();
confWeight.put(new Server("127.0.0.1", 80), 2);
confWeight.put(new Server("127.0.0.1", 81), 3);
confWeight.put(new Server("127.0.0.1", 82), 5);
List<Server> servers = new ArrayList<>();
for (Map.Entry<Server, Integer> entity : confWeight.entrySet()) {
Server server = entity.getKey();
Integer weight = entity.getValue();
for (int i = 0; i < weight; i++) {
servers.add(server);
}
}
Loops.loop(10, i -> {
ColorConsole.colorPrintln("第{}次,权重轮训{}", i, round(servers));
});
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
第0次,权重轮训Server{host='127.0.0.1', port=80}
第1次,权重轮训Server{host='127.0.0.1', port=80}
第2次,权重轮训Server{host='127.0.0.1', port=82}
第3次,权重轮训Server{host='127.0.0.1', port=82}
第4次,权重轮训Server{host='127.0.0.1', port=82}
第5次,权重轮训Server{host='127.0.0.1', port=82}
第6次,权重轮训Server{host='127.0.0.1', port=82}
第7次,权重轮训Server{host='127.0.0.1', port=81}
第8次,权重轮训Server{host='127.0.0.1', port=81}
第9次,权重轮训Server{host='127.0.0.1', port=81}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
但这样还是不均匀的, 相同的ip可能被连续的访问到其实就没有做到负载均衡。
2.3.2 平滑加权算法
主要解决上面那种不平滑的方案。这种方案是由nginx提出来的。
算法的数学原理。
- 最大权重,减总权重
- 当前权重加上原权重
如下权重变化。
| 轮数 | 选择前的当前权重 | 选择节点 | 选择后的当前权重 |
|---|---|---|---|
| 1 | {5, 1, 1} | a | {-2, 1, 1} |
| 2 | {3, 2, 2} | a | {-4, 2, 2} |
| 3 | {1, 3, 3} | b | {1, -4, 3} |
| 4 | {6, -3, 4} | a | {-1, -3, 4} |
| 5 | {4, -2, 5} | c | {4, -2, -2} |
| 6 | {9, -1, -1} | a | {2, -1, -1} |
| 7 | {7, 0, 0} | a | {0, 0, 0} |
下面我们通过代码来实现。
- 首先我们定义出服务器模型,
weight是初始配置的权重,currentWeight是计算后的权重。 - 初始值
weight = currentWeight
@Data
@AllArgsConstructor
@ToString
@EqualsAndHashCode
private static class Server {
private String host;
private Integer port;
// 初始化权重
private Integer weight;
// 计算后的当前权重
private Integer currentWeight;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
然后我们根据算法的核心点来选择节点。这里我们先不考虑性能只说思路,有了思路在自己来优化代码。
- line(3-6) 首先获取总权重
- line(8-14) 然后获取当前最大权重的节点
- line(16-21) 重新计算权重(
主要使用算法的思想)- 当前最大权重节点,重新计算权重。当前权重 = 当前权重 - 总权重 + 原始权重
- 其他节点,重新计算权重。当前权重 = 当前权重 + 原始权重
public static Server selectServer(List<Server> servers) {
// 获取总权重
Integer totalWeight = 0;
for (Server server : servers) {
totalWeight += server.getWeight();
}
// 根据权重从小到大排序
List<Server> sortByCurrentWeight = servers.stream().sorted(Comparator.comparing(Server::getCurrentWeight))
.collect(Collectors.toList());
// 集合反转,从大到小排序
Collections.reverse(sortByCurrentWeight);
// 当前最大权重
Server maxWeightServer = sortByCurrentWeight.get(0);
// 重新计算权重
for (Server server : servers) {
if (server.equals(maxWeightServer)) {
server.setCurrentWeight(server.getCurrentWeight() - totalWeight);
}
server.setCurrentWeight(server.getCurrentWeight() + server.getWeight());
}
return maxWeightServer;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
可以看到非常的平滑均匀,每个ip都会被分散。
第0次,平滑权重轮训WeightBalanceTest2.Server(host=127,0,0,1, port=8080, weight=4, currentWeight=1)
第1次,平滑权重轮训WeightBalanceTest2.Server(host=127,0,0,1, port=8081, weight=2, currentWeight=-1)
第2次,平滑权重轮训WeightBalanceTest2.Server(host=127,0,0,1, port=8080, weight=4, currentWeight=2)
第3次,平滑权重轮训WeightBalanceTest2.Server(host=127,0,0,1, port=8082, weight=1, currentWeight=-2)
第4次,平滑权重轮训WeightBalanceTest2.Server(host=127,0,0,1, port=8080, weight=4, currentWeight=3)
第5次,平滑权重轮训WeightBalanceTest2.Server(host=127,0,0,1, port=8081, weight=2, currentWeight=0)
第6次,平滑权重轮训WeightBalanceTest2.Server(host=127,0,0,1, port=8080, weight=4, currentWeight=4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
三、举例子

好了前面,我们把常见的负载均衡算法都介绍完了,当然实际中的还有很多变异的算法,但是核心思想基本都是以上的思想。下面我们来
看看常见的开源框架中都使用了那些算法吧。
具体算法如何实现不主要研究,只要知道其中的思想即可。如果开发中要使用,在去借鉴就好。
3.1 xxljob
xxl内置了5种负载机制在 LoadBalance 可以找到,其中默认是轮训算法。前两种就不说了,就是上面我们提的。还有其他三种
- XxlRpcLoadBalanceLRUStrategy
- LRU,即:最近最少使用淘汰算法(Least Recently Used)
- 利用迭代器进行轮训: lruItem.entrySet().iterator().next().getKey().并且最长时间没有被用到的会被删除。
- XxlRpcLoadBalanceLFUStrategy
- LFU,即:最不经常使用淘汰算法(Least Frequently Used)。
- 使用次数最少的会优先被选中
- XxlRpcLoadBalanceConsistentHashStrategy
- 一致性Hash算法 Hash一致性
- 思路: 将每个节点进行hash,每个地址虚拟5个节点,然后放到TreeMap里面进行排序。
- 每次对serviceKey进行hash然后获取TreeMap中距离hash最近的一个节点
- 每个serviceKey对应的服务是唯一的
public enum LoadBalance {
RANDOM(new XxlRpcLoadBalanceRandomStrategy()),
ROUND(new XxlRpcLoadBalanceRoundStrategy()),
LRU(new XxlRpcLoadBalanceLRUStrategy()),
LFU(new XxlRpcLoadBalanceLFUStrategy()),
CONSISTENT_HASH(new XxlRpcLoadBalanceConsistentHashStrategy());
}
public abstract class XxlRpcLoadBalance {
// serviceKey 是job的服务名拼接,addressSet是一共能选的机器
public abstract String route(String serviceKey, TreeSet<String> addressSet);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.2 Ribbon
Ribbon 是 SpringCloud体系下一个核心的负载均衡组件。
public interface ILoadBalancer {
// 添加服务器列表
public void addServers(List<Server> newServers);
// 选择可用的服务
public Server chooseServer(Object key);
// 标记服务下线
public void markServerDown(Server server);
// 当前活跃的服务
public List<Server> getReachableServers();
// 当前所有的服务
public List<Server> getAllServers();
}
public interface IRule{
// 真正来做选择的接口
public Server choose(Object key);
public void setLoadBalancer(ILoadBalancer lb);
public ILoadBalancer getLoadBalancer();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
| 序号 | 实现类 | 负载均衡策略 |
|---|---|---|
| 1 | RoundRobinRule | 按照线性轮询策略,即按照一定的顺序依次选取服务实例 |
| 2 | RandomRule | 随机选取一个服务实例 |
| 3 | RetryRule | 按照 RoundRobinRule(轮询)的策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试(重试时获取服务的策略还是 RoundRobinRule 中定义的策略),如果超过指定时间依然没获取到服务实例则返回 null 。 |
| 4 | WeightedResponseTimeRule | WeightedResponseTimeRule 是 RoundRobinRule 的一个子类,它对 RoundRobinRule 的功能进行了扩展。 根据平均响应时间,来计算所有服务实例的权重,响应时间越短的服务实例权重越高,被选中的概率越大。刚启动时,如果统计信息不足,则使用线性轮询策略,等信息足够时,再切换到 WeightedResponseTimeRule。 |
| 5 | BestAvailableRule | 继承自 ClientConfigEnabledRoundRobinRule。先过滤点故障或失效的服务实例,然后再选择并发量最小的服务实例。 |
| 6 | AvailabilityFilteringRule | 先过滤掉故障或失效的服务实例,然后再选择并发量较小的服务实例。 |
| 7 | ZoneAvoidanceRule | 默认的负载均衡策略,综合判断服务所在区域(zone)的性能和服务(server)的可用性,来选择服务实例。在没有区域的环境下,该策略与轮询(RandomRule)策略类似。 |
3.3 dubbo
dubbo 负载均衡接口
@SPI(RandomLoadBalance.NAME)
public interface LoadBalance {
@Adaptive("loadbalance")
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}
- 1
- 2
- 3
- 4
- 5

可以看到常用的算法都提供了,可能具体的实现方式可能不一样。
| 序号 | 实现类 | 负载均衡策略 |
|---|---|---|
| 1 | RandomLoadBalance | 随机算法 |
| 2 | RoundRobinLoadBalance | 加权轮训 |
| 3 | LeastActiveLoadBalance | 当前最少调用的服务先被选中 |
| 4 | ConsistentHashLoadBalance | 一致性hash算法 |
四、总结
- xxl的负载均衡是无状态的
- Ribbon和dubbo有些策略是有状态的,比如会记录服务当前的活跃次数和耗时将这些也算入到权重
无状态设计具有通用性比较简答。而有状态设计虽然不能通用,但是会充分考虑到服务器的性能进行负载。
假如我们来涉及负载均衡,要采用那种设计呢?
其次我们还有那些场景需要关心呢? 请留下你的评论。
文章来源: springlearn.blog.csdn.net,作者:西魏陶渊明,版权归原作者所有,如需转载,请联系作者。
原文链接:springlearn.blog.csdn.net/article/details/125920478

- 点赞
- 收藏
- 关注作者
评论(0)