几种常见的Kafka集群监控工具「送书」

本文选自电子工业出版社的新书《kafka进阶》,推荐一下。
送书规则:文末留言,精选精彩留言,对留言点赞最多的4位包邮送书一本~
截止时间:2022.06.20 8:00
一个功能健全的kafka集群可以处理相当大的数据量,由于消息系统是很多大型应用的基石,因此broker集群在性能上的缺陷,都会引起整个应用栈的各种问题。
Kafka的度量指标主要有以下三类:
1.Kafka服务器(Kafka)指标
2.生产者指标
3.消费者指标
另外,由于Kafka的状态靠Zookeeper来维护,对于Zookeeper性能的监控也成为了整个Kafka监控计划中一个必不可少的组成部分。
Kafka的监控指标
Broker度量指标
Kafka的服务端度量指标是为了监控broker,也是整个消息系统的核心。因为所有消息都通过kafka broker传递,然后被消费,所以对于broker集群上出现的问题的监控和告警就尤为重要。broker性能指标有以下三类:
Kafka本身的指标
主机层面的指标
JVM垃圾回收指标
UnderReplicatedPartitions |
在一个运行健康的集群中,处于同步状态的副本数(ISR)应该与总副本数(简称AR:Assigned Repllicas)完全相等,如果分区的副本远远落后于leader,那这个follower将被ISR池删除,随之而来的是IsrShrinksPerSec(可理解为isr的缩水情况,后面会讲)的增加。由于kafka的高可用性必须通过副本来满足,所有有必要重点关注这个指标,让它长期处于大于0的状态。 |
IsrShrinksPerSec IsrExpandsPerSec |
任意一个分区的处于同步状态的副本数(ISR)应该保持稳定,只有一种例外,就是当你扩展broker节点或者删除某个partition的时候。为了保证高可用性,健康的kafka集群必须要保证最小ISR数,以防在某个partiton的leader挂掉时它的follower可以接管。如果IsrShrinksPerSec(ISR缩水) 增加了,但并没有随之而来的IsrExpandsPerSec(ISR扩展)的增加,就将引起重视并人工介入。 |
ActiveControllerCount |
controller的职责是维护partition leader的列表,当遇到这个值等于0且持续了一小段时间(<1秒)的时候,必须发出明确的告警。 |
OfflinePartitionsCount |
这个指标报告了没有活跃leader的partition数。 |
LeaderElectionRateAndTimeMs |
leader选举的频率(每秒钟多少次)和集群中无leader状态的时长(以毫秒为单位) |
UncleanLeaderElectionsPerSec |
这个指标如果存在的话很糟糕,这说明kafka集群在寻找partition leader节点上出现了故障 |
TotalTimeMs |
这个指标是由4个其他指标的总和构成的: lqueue:处于请求队列中的等待时间 llocal:leader节点处理的时间 lremote:等待follower节点响应的时间 lresponse:发送响应的时间 |
BytesInPerSec BytesOutPerSec |
Kafka的吞吐量 |
生产者度量指标
Response rate |
响应的速率是指数据从producer发送到broker的速率 |
Request rate |
请求的速率是指数据从producer发送到broker的速率 |
Request latency avg |
平均请求延迟 |
Outgoing byte rate |
Producer的网络吞吐量 |
IO wait time ns avg |
Producer的I/O等待的时间 |
消费者度量指标
ConsumerLag MaxLag |
指consumer当前的日志偏移量相对生产者的日志偏移量 |
BytesPerSec |
消费者的网络吞吐量 |
MessagesPerSec |
消息的消费速度 |
ZooKeeperCommitsPerSec |
当zookeeper处于高写负载的时候,将会遇到成为性能瓶颈,从而导致从kafka管道抓取数据变得缓慢。随着时间推移跟踪这个指标,可以帮助定位到zookeeper的性能问题,如果发现有大量发往zookeeper的commit请求,你需要考虑的是,要不对zookeeper集群进行扩展。 |
MinFetchRate |
消费者最小拉取的速率 |
通过官方网站的说明(http://kafka.apache.org/documentation/#monitoring),可以查看Kafka提供的所有的监控指标参数。在这里只是列出了部分主要的参数指标。
使用Kafka客户端监控工具
Kafka常用的客户端管理、监控工具,主要有以下几种:
Kafka Manager
Kafka Tool
KafkaOffsetMonitor
JConsole
其中,前三个工具都是专门用于Kafka集群的管理与监控;而JConsole(Java Monitoring and Management Console),是一种基于JMX的可视化监视、管理工具,安装好了JDK以后,Java就为我们提供了JConsole的客户端工具。利用它我们也可以监控Kafka的各项指标。
这里我们简单介绍一下JMX。JMX的全称为Java Management Extensions。可以管理、监控正在运行中的Java程序。常用于管理线程,内存,日志Level,服务重启,系统环境等。而Kafka底层也是基于Java的,所以我们也就可以使用JMX的标准来管理和监控运行中的Kafka了。
下面我们分别介绍它们的使用方法。
Kafka Manager
Kafka Manager的Github地址是https://github.com/yahoo/kafka-manager。这款监控框架的好处在于监控内容相对丰富,既能够实现broker级常见的JMX监控(比如出入站流量监控),也能对consumer消费进度进行监控(比如lag等)。另外用户还能在页面上直接对集群进行管理,比如分区重分配或创建topic——当然这是一把双刃剑,好在kafka manager自己提供了只读机制,允许用户禁掉这些管理功能。
这里我们使用的版本是:kafka-manager-2.0.0.2.zip。安装和配置非常简单,按照下面的步骤配置Kafka Manager:
(1)首先,需要在启动Kafka集群的命令脚本中,增加JMX的相关参数。否则无法使用客户端工具管理和监控Kafka集群。这里我们以kafka101主机上运行的broker 0和broker 1为例,来为大家演示。进入kafka安装目录下的bin目录
cd /root/training/kafka_2.11-2.4.0/bin/
(2)修改kafka-run-class.sh文件,找到“JMX setting”的位置(第176行)。增加JMX Server的配置信息。如图7.1所示。
-Djava.rmi.server.hostname=kafka101

图7.1 修改Kafka Manager的JMX Setting
注意:
由于在kafka101主机上将会启动两个broker,为了方便可以在命令终端中使用export命令设置JMX的端口地址;也可以像下面这样把JMX的端口写到kafka-server-start.sh脚本中,如图7.2所示,修改第30行。
export JMX_PORT="9999"

图7.2 设置JMX的端口
(3)启动Kafka Broker 0
export JMX_PORT="9990"
bin/kafka-server-start.sh config/server.properties &
(4)重新开启一个命令行终端,启动Kafka Broker 1
export JMX_PORT="9991"
bin/kafka-server-start.sh config/server1.properties &
(5)将Kafka Manager的压缩包解压至/root/training目录
unzip kafka-manager-2.0.0.2.zip -d ~/training/
(6)进入Kafka Manager的conf目录,并修改application.conf文件
#这里我们指定ZooKeeper集群的地址
kafka-manager.zkhosts="kafka101:2181,kafka102:2181,kafka103:2181"
#将下面的这一行注释掉
#kafka-manager.zkhosts=${?ZK_HOSTS}
(7)采用nohup的方式启动Kafka Manager
nohup bin/kafka-manager &
也可以像下面这样启动Kafka Manager的时候,指定相关参数:
nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8080 &
(8)启动成功后,将输出如下的日志信息,如图7.3所示:
图7.3 启动Kafka Manager
可以看到,Kafka Manager将运行在9000端口上。
(9)通过浏览器访问9000端口,可以打开Kafka Manager的Web控制台,如图7.4所示:
图7.4 Kafka Manager的Web控制台
(10)选择“Cluster”-->“Add Cluster”,添加一个新的Kafka集群。勾选“Enable JMX Polling”,并点击“Save”。如图7.5所示:
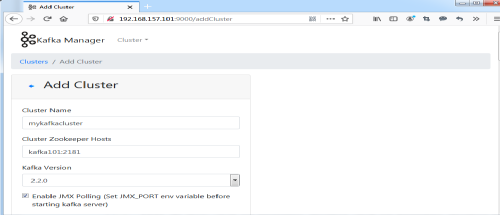
图7.5 添加Kafka集群
(11)添加成功后,点击“Go to Cluster View”,跳转到Kafka 集群的首页,如图7.6所示:
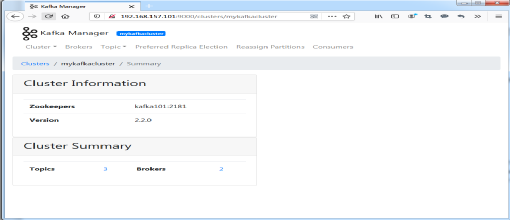
图7.6 Kafka集群首页
在这里,可以看到当前的Kafka集群中共存在2个Broker,即:broker 0和broker 1;还有3个Topics。
(12)点击Brokers的数字“2”,跳转到Broker的监控页面上。在这里就可以实时监控Kafka集群Broker的相关信息了。如Kafka集群的吞吐量(Bytes in /sec、Bytes out /sec)等等,如图7.7所示:
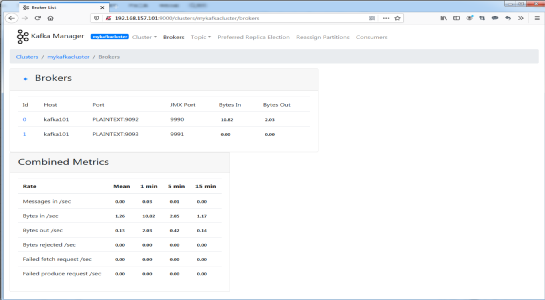
图7.7 监控Kafka Broker
(13)图7.8所示,展示了Kafka集群Topic的监控信息。
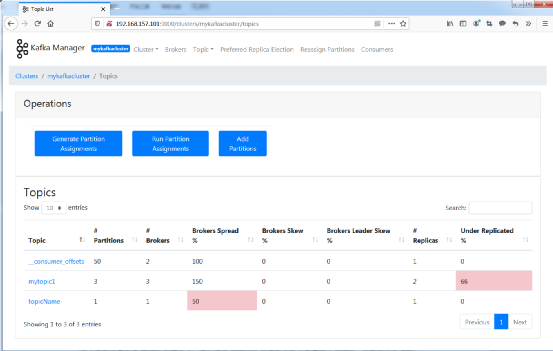
图7.8 监控Kafka Topic
Kafka Tool
Kafka Tool是用于管理和使用Apache Kafka集群的图形应用程序。它提供了一种直观的界面风格,可让用户快速查看Kafka集群中的对象以及集群主题中存储的消息。它包含面向开发人员和管理员的功能,一些关键功能如下:
快速查看所有Kafka集群,包括其broker,主题和消费者
查看分区中消息的内容并添加新消息
查看消费者的偏移量,包括Apache Storm中的spout消费者
以良好的格式显示JSON和XML消息
添加和删除主题以及其他管理功能
将单个消息从您的分区保存到本地硬盘驱动器
编写自己的插件,使您可以查看自定义数据格式
Kafka工具可在Windows,Linux和Mac OS上运行
从Kafka Tool的官方网站(https://www.kafkatool.com/download.html)上,直接下载Kafka Tool。这里我们直接下载Kafka Tool 2.0.8的版本。如下图7.9所示:
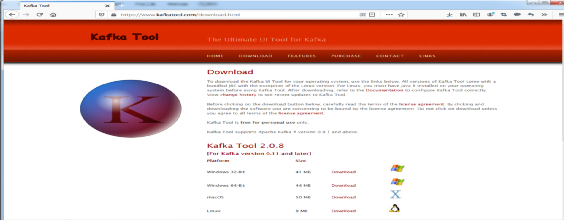
图7.9 下载Kafka Tool
下载完成后,直接安装启动即可。图7.10展示了启动的初始界面。
图7.10 Kafka Tool的启动界面
添加一个Kafka Cluster集群,并测试。如图7.11所示:
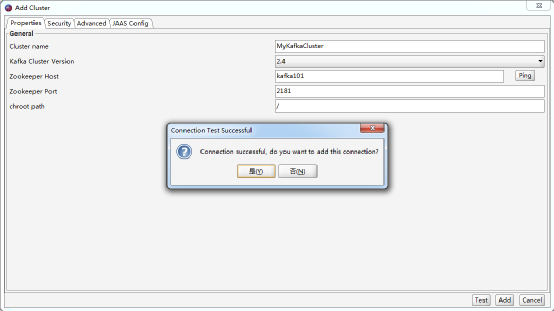
图7.11 添加Kafka集群
点击“是”,进入Kafka集群的首界面。如图7.12所示:
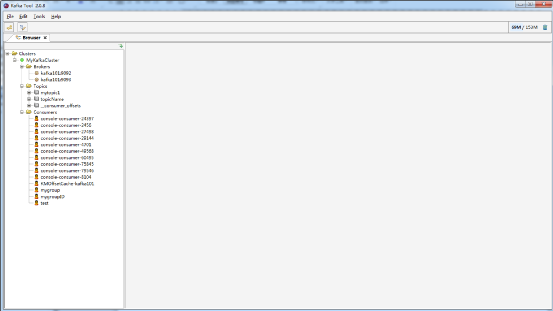
图7.12 Kafka集群的首界面
在这里可以看到Kafka集群中的Broker信息、Topics的信息以及Consumers消费者的信息。
现在我们使用Kafka Tool来创建一个新的Topic。
(1)选择“Browsers”中集群的“Topics”节点,并在右边的界面上点击 按钮,添加一个新的Topic。
按钮,添加一个新的Topic。
(2)输入Topic的名字、分区数、以及每个分区的副本数。这里我们新创建的Topic名称是mytopic2,它由两个分区组成,并且每个分区的副本数为。如图7.13所示。
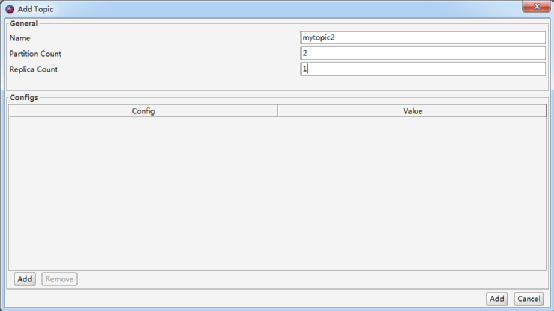
图7.13 Add Topic
(3)点击“Add”,将成功创建Topic,如图7.14所示。
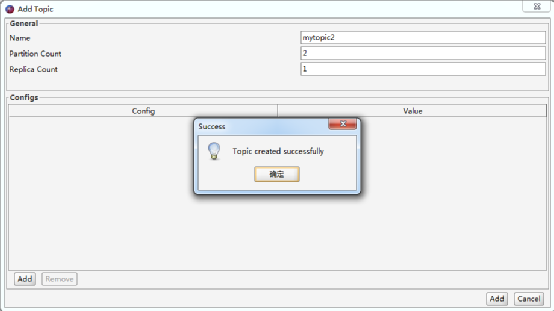
图7.14 成功创建Topic
(4)现在我们使用Kafka Tool来接收mytopic2上的消息数据。选择刚刚创建好的mytopic2的主题,并在右边的窗口中选择“Data”的页面,如图7.15所示。
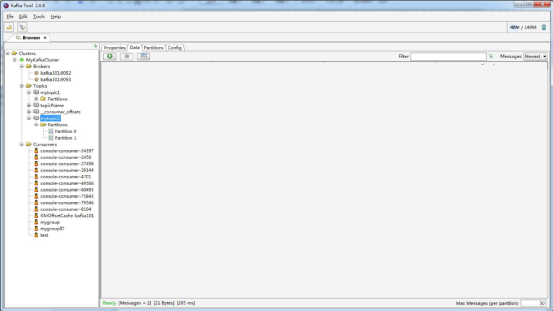
图7.15 通过Kakfa Tool接收数据
(5)启动一个Kafka Producer的命令行终端,并发送一些消息。如图7.16所示:
bin/kafka-console-producer.sh --broker-list kafka101:9092 --topic mytopic2

图7.16 通过命令行发送数据
(6)在Kafka Tool上,点击 接收消息。这里就可以看到刚才我们在Kafka Producer命令行上发送的消息。如图7.17所示:
接收消息。这里就可以看到刚才我们在Kafka Producer命令行上发送的消息。如图7.17所示:
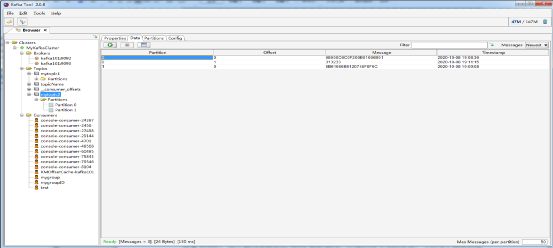
图7.17 在Kafka Tool上接收数据
(7)这里的数据格式默认是“Byte Array”,我们可以在Properties的设置里面将其修改为String,并点击“Update”,如图7.18所示:

图7.18 修改Topic的数据格式
(8)回到Data页面,这时候数据将按照正确的格式显示,如图7.19所示:

图7.19 显示正确的数据
KafkaOffsetMonitor
KafkaOffsetMonitor是一个基于Web界面的管理平台,可以用来实时监控Kafka服务的Consumer以及它们所在的Partition中的Offset,我们可以浏览当前的消费者组,并且每个Topic的所有Partition的消费情况都可以进行实时的监控。KafkaOffsetMonitor可以从github上下载,地址是:https://github.com/quantifind/KafkaOffsetMonitor 。这里我们使用的是KafkaOffsetMonitor-assembly-0.2.0.jar
KafkaOffsetMonitor的安装启动比较简单。我们可以直接在kafka101的主机上执行下面的指令:
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk kafka101:2181 \
--port 8089 \
--refresh 10.seconds \
--retain 1.days
其中:
lcom.quantifind.kafka.offsetapp.OffsetGetterWeb是运行Web监控的类
--zk用于指定ZooKeeper的地址
--port是Web运行端口
--refresh和--retain用于指定页面数据刷新的时间以及保留数据的时间值
打开浏览器访问8089端口,就可以打开KafkaOffsetMonitor的首页面,如图7.20所示。
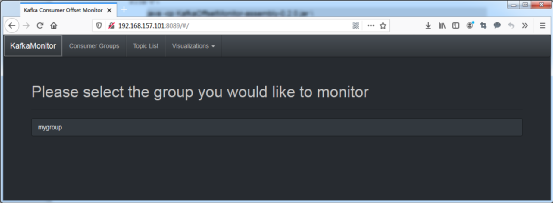
图7.20 KafkaOffsetMonitor首页
选择“Topic List”,就可以监控某个具体的Topic信息了,如图7.21所示。

图7.21 通过KafkaOffsetMonitor监控Topic
JConsole
JConsole(Java Monitoring and Management Console),一种基于JMX的可视化监视、管理工具,从Java 5开始引入。JConsole是用Java写的GUI程序,用来监控VM,并可监控远程的VM,非常易用,而且功能非常强。命令行里打 jconsole,就可以直接启动了。
这里我们方便,我们直接在Window上启动JConsole。在CMD创建中直接输入JConsole,如图7.22所示。
图7.22 启动JConsole
JConsole的启动界面如图7.23所示。
图7.23 JConsole的启动界面
由于在前面配置Kafka Manager的时候,我们已经启用了broker 0和broker 1的JMX配置,所以这里可以直接通过JConsole连接到broker 0或者broker 1上。我们以broker 0 为例。选择“远程进程”,并输入broker 0的JMX地址,点击“连接”,如图7.24所示。
kafka101:9990
图7.24 通过JConsole连接broker 0
选择“不安全的连接”,进入JConsole监控的主界面,如图7.25和图7.26所示。
图7.25 不安全的连接
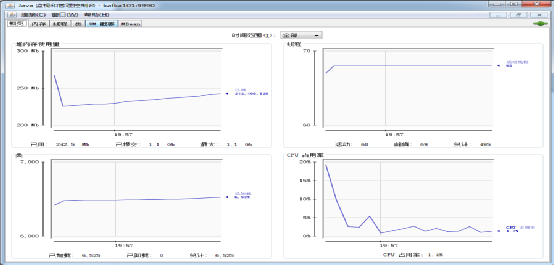
图7.26 JConsole的主页面
JConsole提供六个选项卡显示应用信息:
(1)概览选项卡:提供内存使用的概述、运行的线程数量、创建的对象数量以及CPU使用情况。
(2)内存选项卡:显示使用的内存数量。可以选择要监视的内存类型(堆、非堆或池)组合。
(3)线程选项卡:显示线程数量和每个线程的详细信息。
(4)类选项卡:显示加载的对象数量的信息。
(5)VM 概要选项卡:提供运行应用的JVM概要。
(6)MBean选项卡:显示有关应用的托管bean的信息。
这里我们选择“MBean选项卡”,就可以看到Kakfa相关的MBean信息,如图7.27所示。
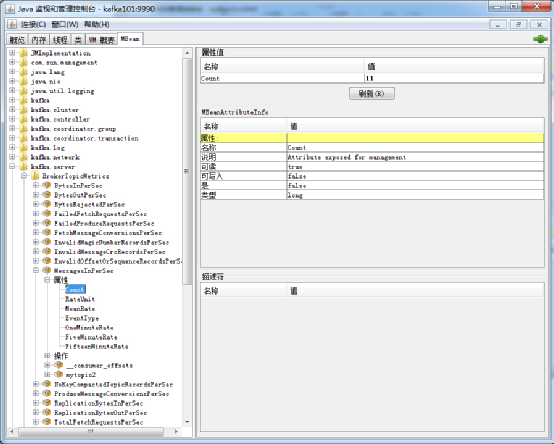
图7.27 通过JConsole监控Kafka
以上图监控的参数“MessagesInPerSec”为例,它表示的是Kafka集群消息的速率。关于所有的Kafka监控的MBean信息,可以参考官方网站上的说明,地址是:http://kafka.apache.org/documentation/#monitoring
监控ZooKeeper
前面提到,整个Kafka的状态靠Zookeeper来维护,对于Zookeeper性能的监控也成为了整个Kafka监控计划中一个必不可少的组成部分。在典型的Kafka集群中, Kafka通过Zookeeper管理集群配置,例如:选举Leader,以及在Consumer Group发生变化时进行Rebalance;生产者Producer将消息发布到broker,Consumer从broker订阅并消费消息。这些操作都离不开ZooKeeper。所以在Kafka集群的管理监控中,ZooKeeper的监控也就成为了非常重要的一部分。
由于ZooKeeper本身也是由Java开发的应用程序,我们当然也可以前面提到的JMX的方式进行监控,例如使用JConsole。图7.28展示了通过JConsole监控ZooKeeper MBean的监控信息。
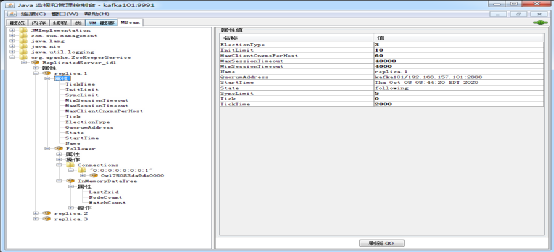
图7.28 通过JConsole监控ZooKeeper
这里我们也可以使用另一个客户端工具ZooInspector监控ZooKeeper。图7.29展示了它的主界面。
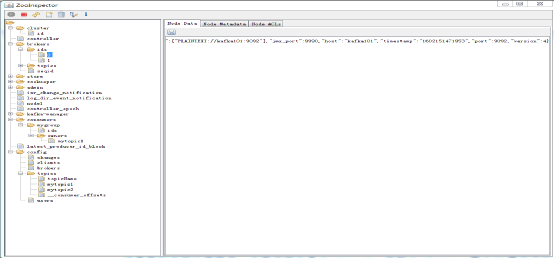
图7.29 通过ZooInspector监控ZooKeeper
本文选自电子工业出版社的《kafka进阶》一书,略有修改,经出版社授权刊登于此。

本书基于作者多年的教学与实践进行编写,重点介绍Kafka消息系统的核心原理与架构,内容涉及开发、运维、管理与架构。全书共11章,第1章,介绍Kafka体系架构基础,包括消息系统的基本知识、Kafka的体系架构与ZooKeeper;第2章,介绍Kafka的环境部署,以及基本的应用程序开发;第3章,介绍Kafka的生产者及其运行机制,包括生产者的创建和执行过程、生产者的消息发送模式和生产者的高级特性等;第4章,介绍Kafka的消费者及其运行机制,包括消费者的消费模式、消费者组与消费者、消费者的偏移量与提交及消费者的高级特性等;第5章,介绍Kafka服务器端的核心原理,包括主题与分区、消息的持久性与传输保障、Kafka配额与日志的管理;第6章,介绍Kafka的流处理引擎Kafka Stream;第7章,介绍使用不同的工具监控Kafka,包括Kafka Manager、Kafka Tool、KafkaOffsetMonitor和JConsole;第8章至第11章,介绍Kafka与外部系统的集成,包括集成Flink、集成Storm、集成Spark和集成Flume。

长按以识别二维码,加入大数据微信号群~
公众号推送规则变了
点击上方公众号名片,收藏公众号,不错过精彩内容推送!

往期推荐
文章来源: dataclub.blog.csdn.net,作者:数据社,版权归原作者所有,如需转载,请联系作者。
原文链接:dataclub.blog.csdn.net/article/details/125353865

- 点赞
- 收藏
- 关注作者
评论(0)